
Частая головная боль разработчиков – обработка сотен файлов разных форматов и типов по единому принципу. Но этот процесс можно автоматизировать. Configuration Driven Development позволяет создать единый интерфейс с конфигурациями для каждого источника данных.
В нашей команде мы таким образом реализовали проект по обработке списков опросов. Здесь пригодились лямбда-функции, мощные библиотеки и облачные сервисы. Так что делюсь наработками.
Что мы получили в работу
Заказчик ведет аналитику опросов среди сотрудников своих клиентов. Нам достался проект по обработке списков будущих респондентов. Это десятки, иногда сотни строчек.
Исторически процесс происходил так:
- Специалист на стороне заказчика получал от клиента файл inbound в формате csv или xls с новым списком опрошенных людей.
- Открывал мастер-файл с обработанными списками. Для некоторых клиентов такой файл содержал более 70 000 строк!
- Копировал данные из inbound- в мастер-файл, фильтровал их, форматировал, применял формулы и сохранял изменения. Для схожих файлов Excel это уже трудно.
- Далее — сохранение данных в MS Access и outbound-файле для экспорта в следующую систему.
Вот как это выглядит:
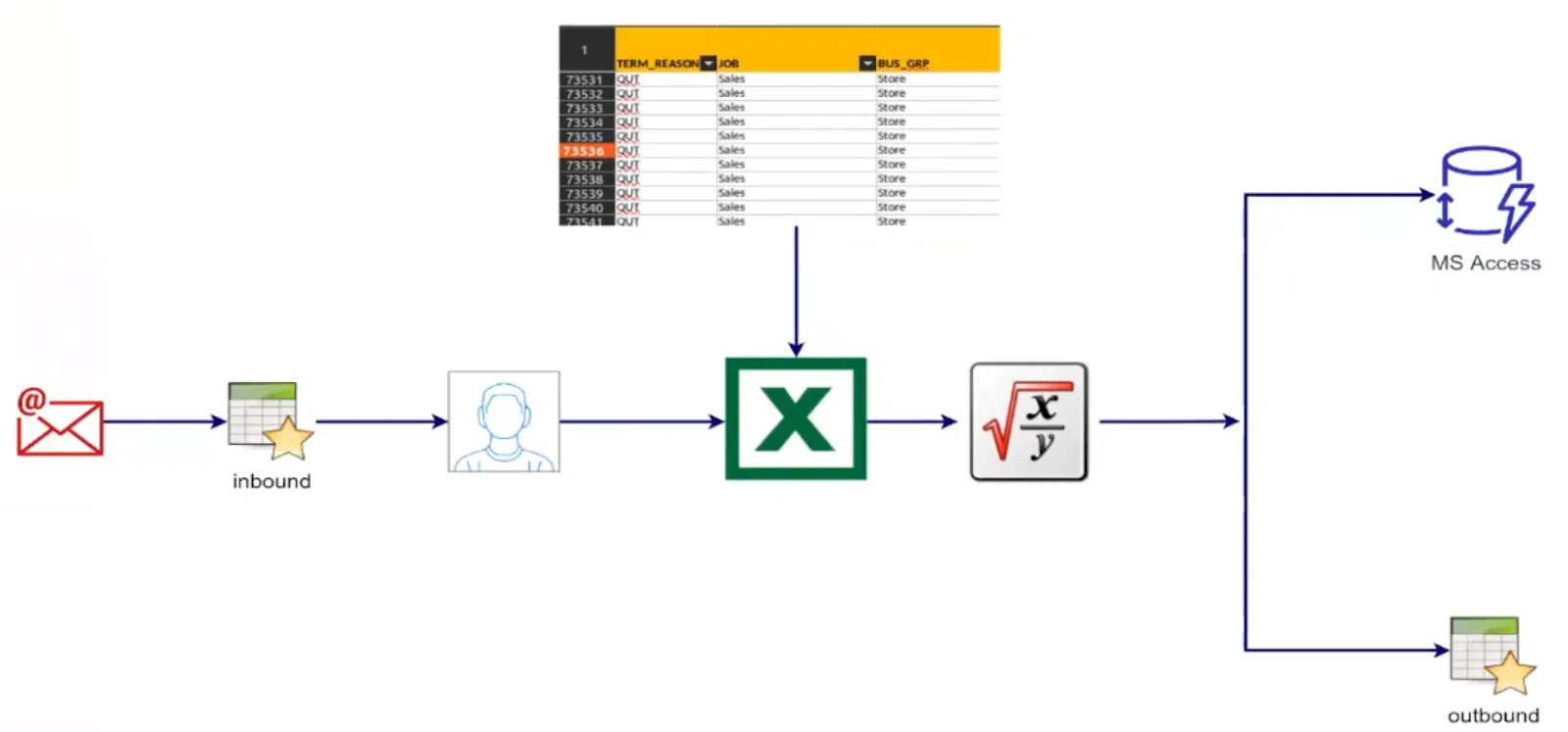
Думаю, в какой-то момент терпеть эти «адские муки» стало бы невозможно. Перед нами стояла задача автоматизировать обработку всех данных.
Технологический стек
- pandas – мощная библиотека для работы с данными в Python.
- MySQL – выбрали именно эту реляционную базу данных как наиболее удобную для поставленных задач.
- AWS и лямбда-функции – на них построено приложение, ведь у нас обрабатываются события.
- Terraform и Liquibase – нужны для деплоя.
Обработка данных
Мы разработали флоу, для пользователя все выглядит просто: он загружает inbound-файл в S3 bucket и получает отчет в SNS topic. Из него можно узнать, какие данные отфильтровались как невалидные и почему. Также можно увидеть обработанные данные и ссылки на эти файлы. Под капотом для этого у EventBridge формируется событие, которое становится в очередь в SQS. Из этой очереди ее обрабатывает лямбда-функция. Она фильтрует данные, выполняет преобразования и сохраняет результаты в базу данных и в S3 bucket.
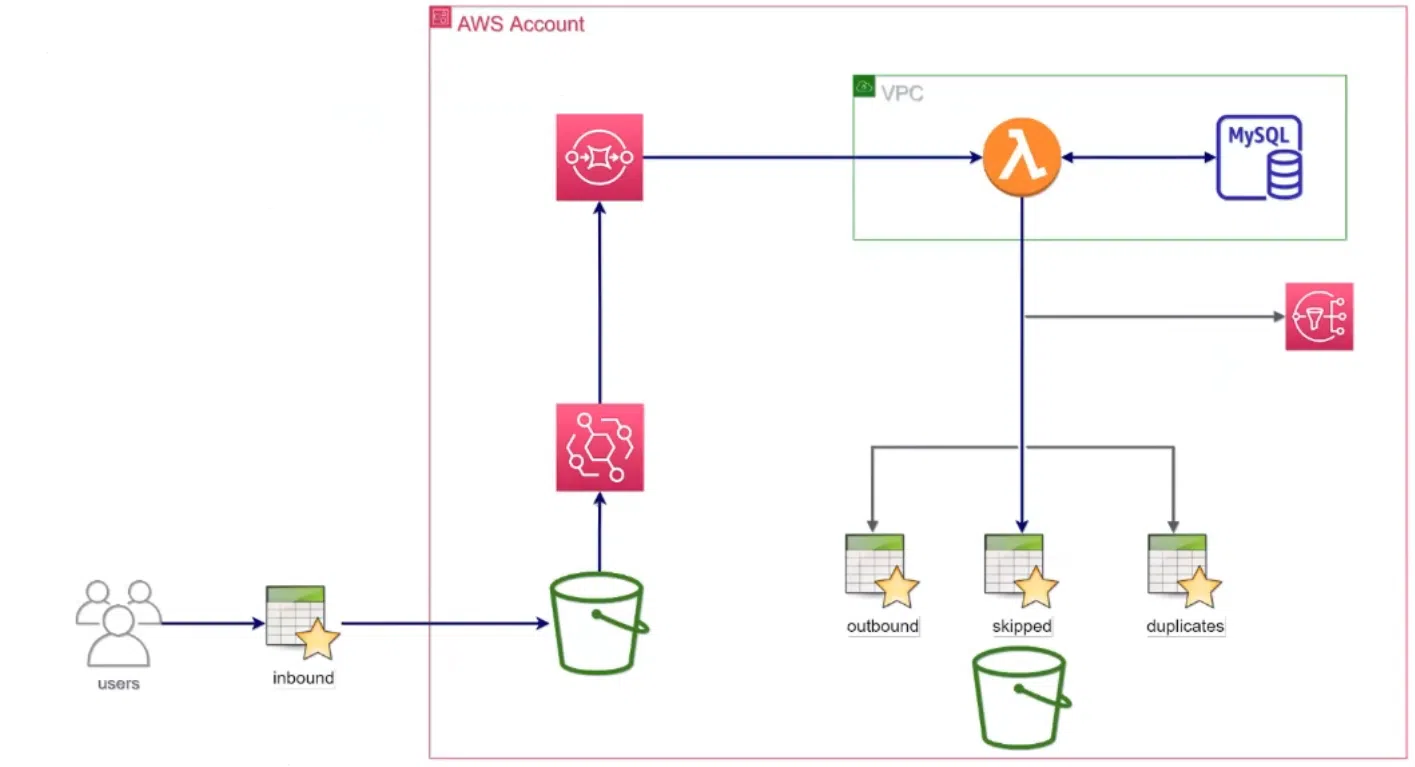
Процесс достаточно тривиален. Прежде всего, нужно валидировать строки входного кода и генерировать новые поля. К примеру, даты и уникальный идентификатор. Также необходимо вычислять «демографические функции» (они же – демо-функции) на основе имеющихся полей. Определяя интервьюеров, учитывайте их отпуска. А для клиентов и их сотрудников из Квебека следует назначать интервьюеров, владеющих французским.
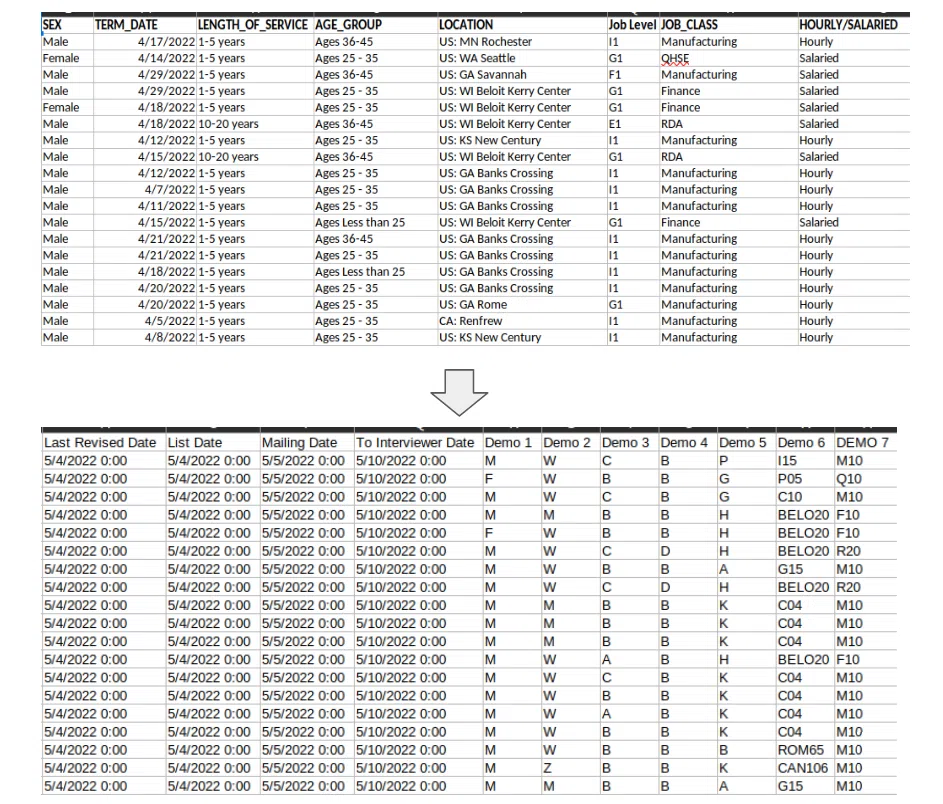
Основные челленджи
Это то, за что я и полюбил этот проект. Хочу поделиться с вами наиболее показательными челленджами.
Основной вызов заключался в том, что у клиентов не было одинаковой структуры данных и их форматов. А клиентов было около 200 и у каждого по 10-50 демофункций. Требовался единый процесс, но с разными правилами. Решить эту проблему удалось на основе конфигураций. При создании конфигурации для нового клиента добавляем только несколько файлов в JSON и YAML. Ни одной новой строки кода! Да, лямбда-функция получается слишком большой. Но она одна, ее легко поддерживать.
Следующая сложность – появление особых кейсов, которые даже при этой гибкости тяжело хендлить. Здесь мы настроили динамичный выбор класса клиентов.
Со временем система росла, добавились еще три флоу. Они позволяют изменить уже обработанные данные. Чтобы не переписывать конфигурации для каждого флоу, мы ввели теги. Теперь из базовой конфигурации можно выделить подмножество конфигураций, необходимых для определенного флоу.
Не могу не упомянуть Mail Merge. Эта функция позволяет генерировать письма сотрудникам – приглашение пройти опрос. Речь идет о настоящих бумажных письмах! Детальнее о внедрении этого функционала расскажу дальше.
Валидация
В ходе процессинга данных следует убедиться, что при их преобразовании нет риска завалить систему. Так что мы внедрили несколько валидаторов. Сначала по присущим конфигурациям конкретного клиента мы стараемся считать данные в pandas DataFrame. Это может быть xls, csv с разными сепараторами, разное количество хедеров и т.д. Если удается, валидируем колонки в соответствии со схемой. Это позволяет убедиться, есть ли все поля. При положительном ответе можно переходить к валидации данных.

Прежде всего, валидируем identity-поля, которые формируют уникальность данных. Это может быть комбинация по фамилии, имени и дате увольнения сотрудника. Если данные в строках и полях валидны, проверяем уникальность этих записей в скопе файла и в скопе всех исторических данных клиента. Все неуникальные данные отфильтровываем до дубликатов, а остальные снова валидируем по схеме.
На выходе есть три фрейма: валидные и невалидные данные, дубликаты. Существующие данные мы процессируем и сохраняем дальше. Другие же сохраняются до S3 в файлы, чтобы клиент мог все проверить и исправить ошибки.
Конфигурации для клиента
Большое количество конфигураций для каждого клиента можно назвать фишкой этого проекта. На нулевом уровне мы создали описание клиента в YAML-файле и ссылку для него на разные виды. Это конфигурация ETL-процесса, схема валидации, вспомогательные маппинги, таблица в базе, identity-поля и методы загрузки из файла. Я расскажу поподробнее о двух видах конфигурации.
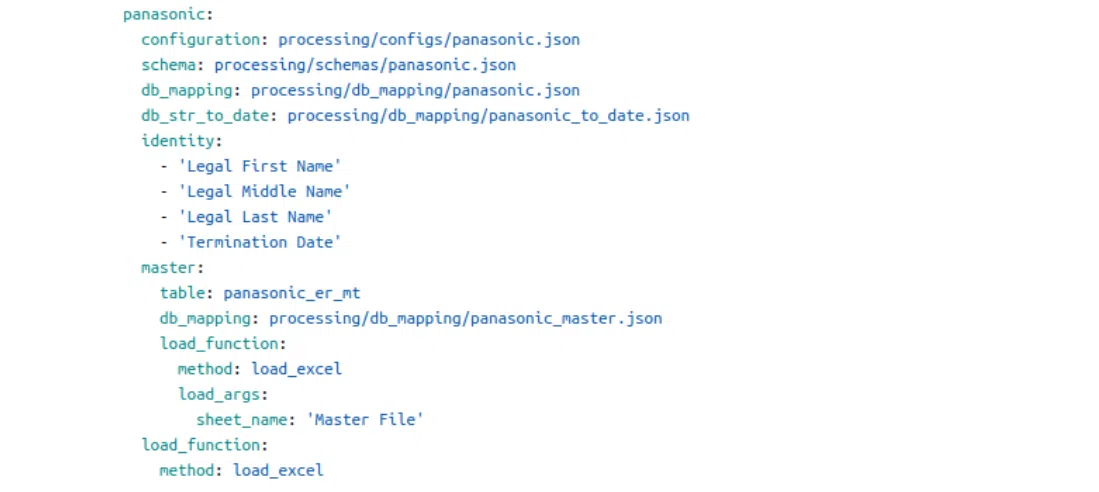
Конфигурация: валидация по схеме
Схема представляет собой совокупность описаний полей для файла inbound. Если мы не доверяем выбору типа данных pandas, есть возможность явно указать тип для этих полей. Также можно добавить разные предикаты. К примеру, обозначить, является ли поле обязательным и провалидировать его регулярным выражением. А еще можно добавить много бизнес-валидаторов.
В примере ниже есть такие имплементированные валидаторы, здесь мы ничем не ограничены. Поэтому все, в чем нуждается бизнес, можно воплотить как функцию. Она будет давать ответ, являются ли данные валидными.

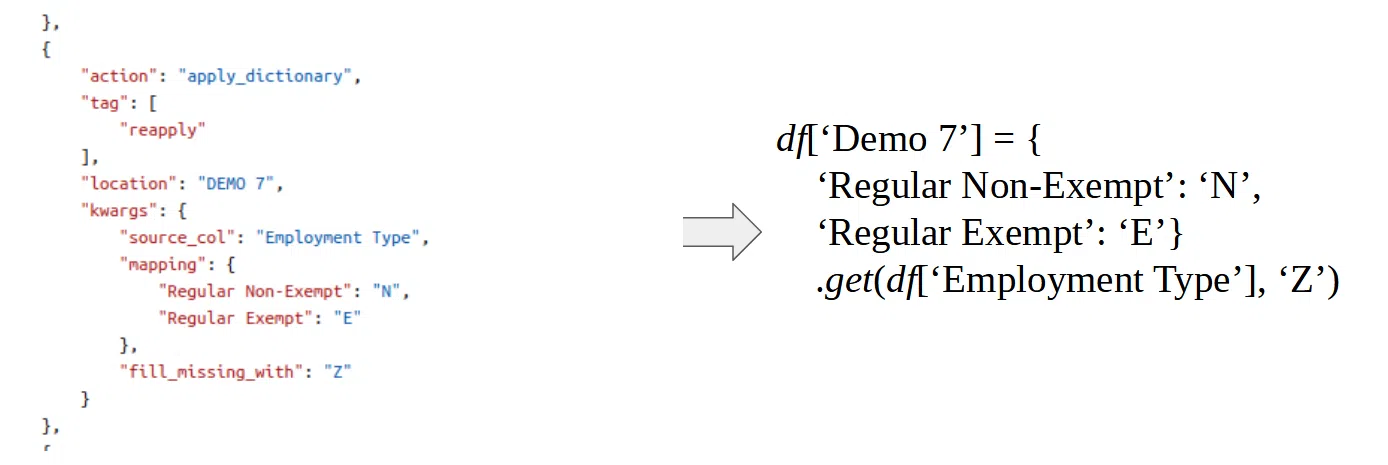
Под капотом эта красивая и компактная конфигурация трансформируется в код, аналогичный псевдокоду (справа на иллюстрации). Это позволяет эффективно валидировать данные. Для невалидных данных можно указать, в каких колонках необходимо проверить те или иные поля и исправить ошибки.
Конфигурация: обработка данных
По существу это массив преобразований, выполняемых над Data Frames. Эти преобразования – набор функций, скомпонованных в несколько пакетов для обработки текста, чисел, дата-фреймов и т.д. Все пакеты мы подробно документировали. Если клиенту понадобится еще одна форма обработки, можно добавить сколь угодно новые функции. Весь процесс напоминает сборник конструктора: берем готовые функции, определенным образом комбинируем их и получаем нужную конфигурацию:
Подготовка к переписке
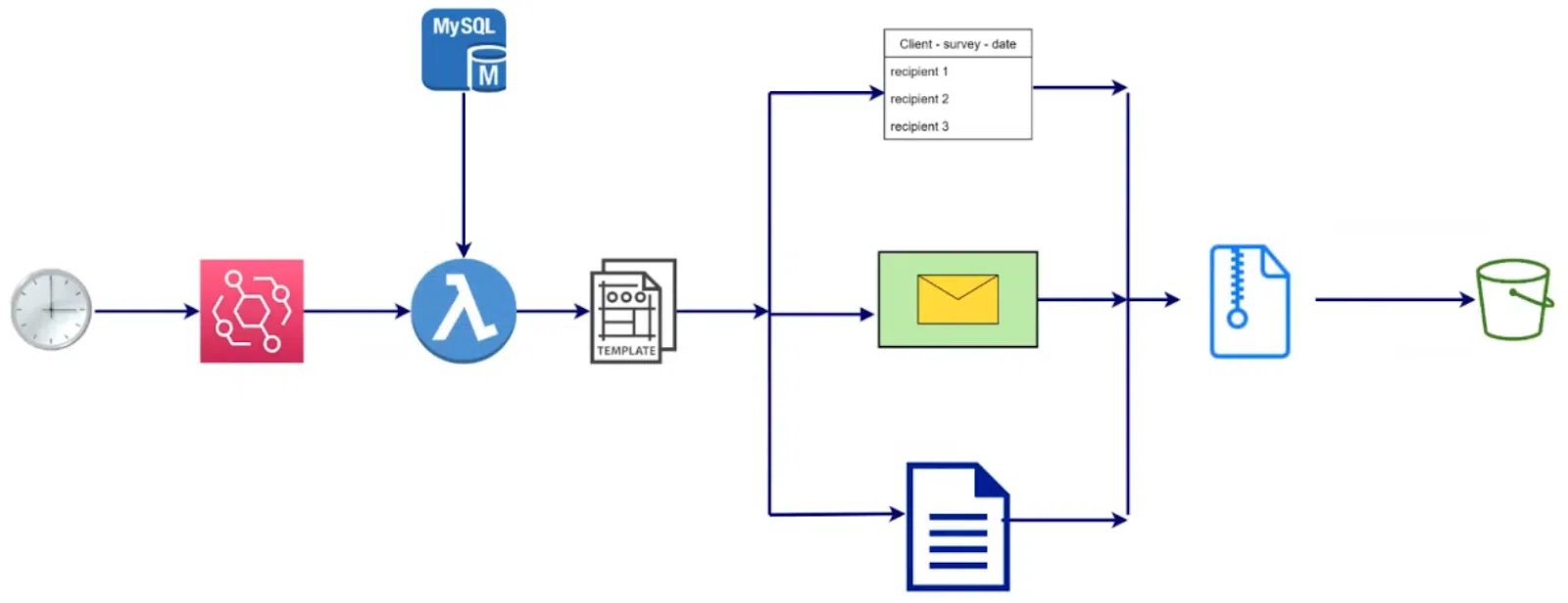
Еще одна интересная задача – обработка бумажных листов. Этот функционал предусмотрен примерно для половины клиентов. Здесь мы создали отдельную лямбда-функцию. Она стартует утром каждый рабочий день. Для этого в EventBridge формируется событие, которое триггерит лямбда-функцию, чтобы запросила БД. Для каждого клиента проходит проверка: есть ли сотрудники, которые должны получить письмо. Эта выборка отправляется на Microsoft Mail Merge template. Мы получаем документы с заполненными данными. Таких шаблонов можно создавать множество, и обычно используются три:
- Список людей, которые должны получить приглашение на опрос.
- Конверт для каждого человека из этого списка.
- Письмо-приглашение.
Затем эти документы упаковываются в единый архив для клиента и размещаются в соответствующем хранилище. Отдельный специалист открывает архивы, распечатывает нужные письма, вкладывает их в конверты и передает почтовому сервису.
Интеграционные тесты
Чтобы убедиться в надежности системы мы используем юнит-тесты. Все новые функции, которые добавлялись в систему, были покрыты тестами. Мы запускали их при каждом билде.
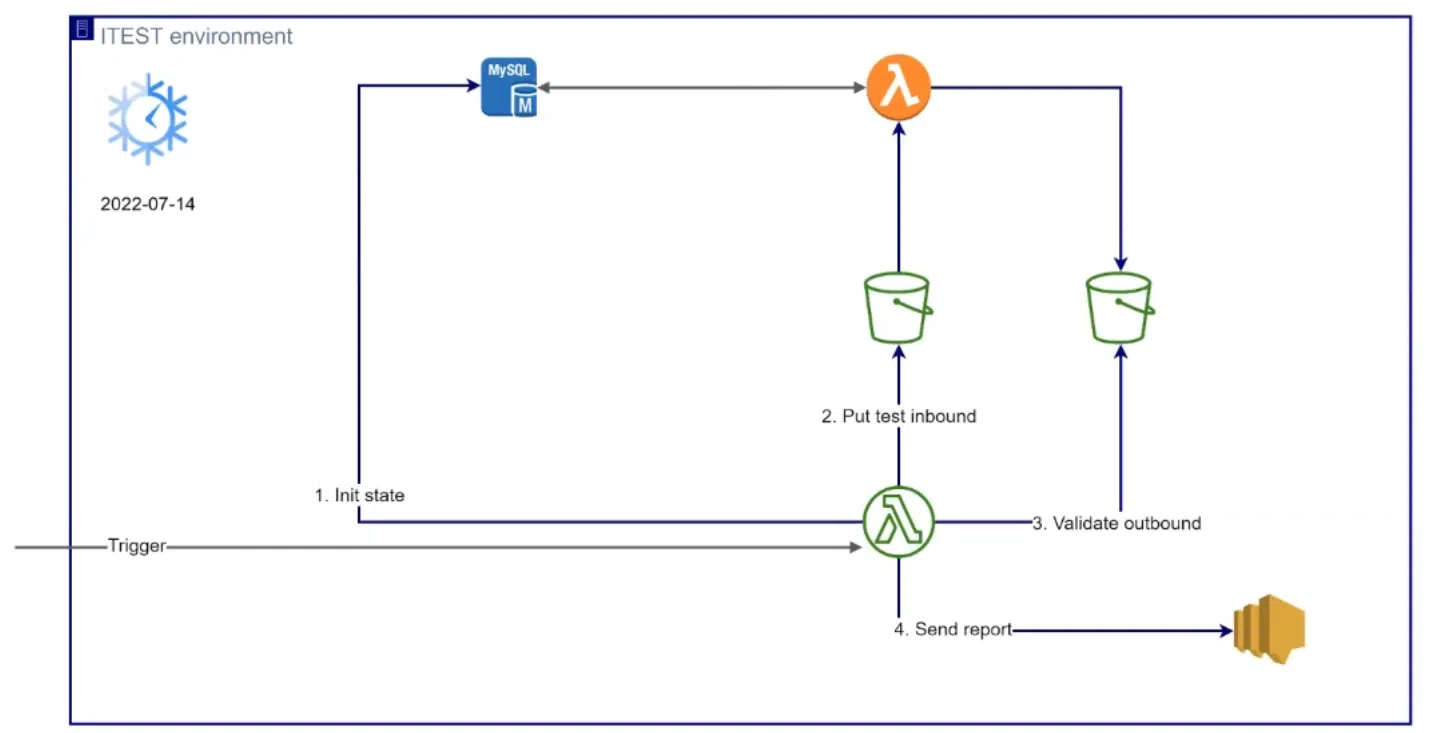
Также при билде на девелопменте проверяем взаимодействие всех компонентов на iTEST environment. Хочу отметить здесь маленькую хитрость. Наша функция не stateless, то есть она зависит от состояния базы и текущей даты. Поэтому мы наделили лямбду «суперсвойством».
Используя определенную переменную, для тестовых целей можно задать текущее время на сервере. Так удается проверить результат по указанной дате. Деплоим специальную функцию для интеграционного тестирования по пайплайну. Далее эта функция инициирует состояние в базе, загружает inbound-файлы, ожидает outbound-файлы и сверяет их с эталонными ответами. Результат будет в виде репорта к SNS topic:
Построение CI/CD
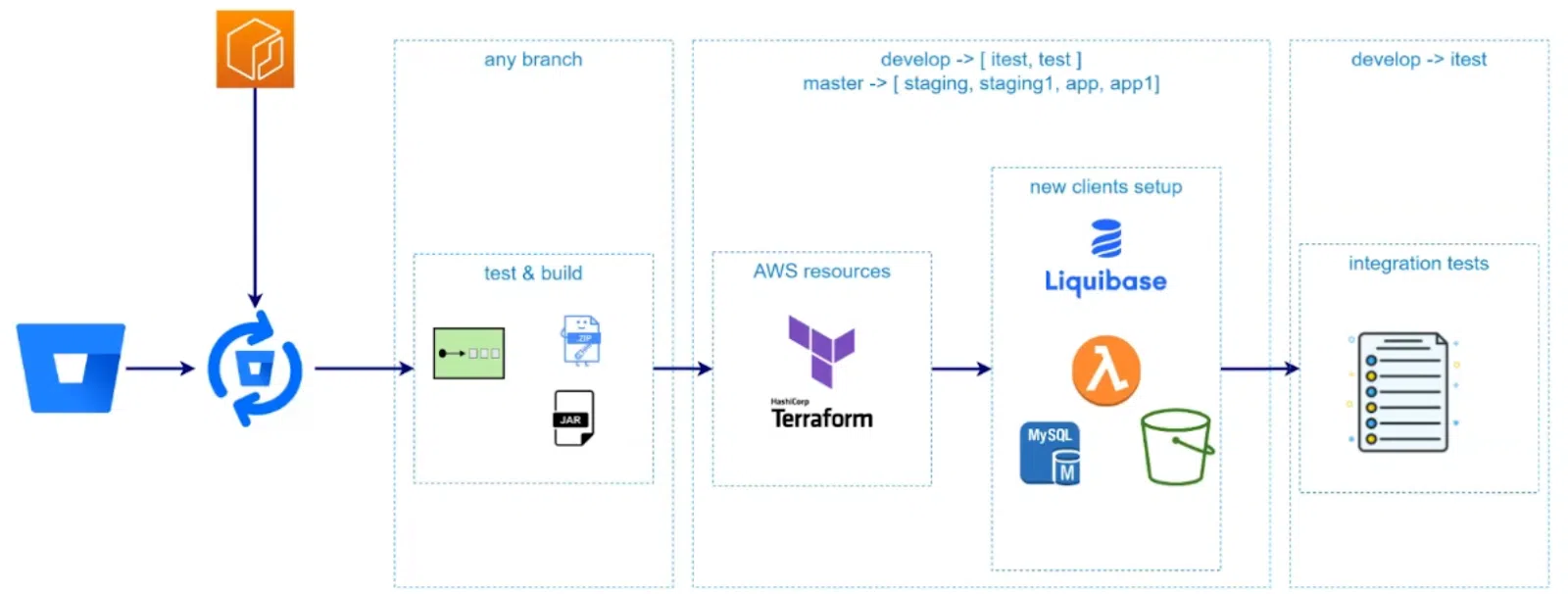
На этом проекте я дополнительно взял на себя роль DevOps и настраивал процессы CI/CD. Построил все на Bitbucket Pipelines. Основным инструментом управления ресурсами избрал Terraform.
Здесь тоже не обошлось без челленджей. Например, когда у нас есть сервер приложения, то при старте сервера обычно происходит инициализация ресурсов. Но ведь у нас serverless-решения. Поэтому пригодится вновь лямбда-функцию. Она создает в S3 bucket необходимую структуру директории и таблицы в БД. При этом функция деплоится из пайплайна и оттуда вызывается:
Польза от внедрения автоматизации очевидна
Мы завершили работу над этим проектом и все передали клиенту. Решение получилось довольно простое, качественно задокументированное. К тому же, я провел несколько knowledge transfer сессий, что полезно для всей команды. В настоящее время заказчик самостоятельно поддерживает и развивает проект. Следовательно, у его специалистов не возникает трудностей, скажем, с заменой картенгов или создание за день двух-трех конфигураций.
И главное – все это в итоге реально экономит время. То, что раньше занимало 40 минут, теперь выполняется за 40 секунд ! Крутой результат, не правда ли?🙂
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.




Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: