Искусственный интеллект определяет ваш уровень английского с точностью 96%: как это работает

Команда машинного обучения в школе английского Skyeng на основе текстов из уроков, действий пользователей и речей учеников и учителей решает ряд ML-задач. Среди них — автоматизированная оценка уровня владения языком.
На конференции Conversations 2021 Lead Machine Learning Engineer в Skyeng Роман Смирнов рассказал, как они с командой построили систему, которая может послушать, как вы разговариваете и определить ваше знание английского.
Далее со слов Романа Смирнова
__________
Чтобы машина могла определить уровень владения языком, она должна:
- распознать речь (ASR-система);
- оценить ее по неким параметрам.
Параметры для определения уровня английского это лексика, грамматика и беглость речи. Все три записываются в функцию, которая лежит в основе системы Skyeng.
Уровень знания языка = f (лексика, грамматика, беглость речи)
Теперь разберем подробнее этапы.
Как работает распознавание языка в системе Skyeng
Задача распознавания речи уже реализована в готовых нейронках, и для новых систем их обычно берут и модифицируют под себя. Skyeng — не исключение.
Команда машинного обучения проанализировала имеющиеся модели и выбрала такую, которая бы подходила под следующие ограничения:
- ограничение по мощности сервера;
- работа в режиме реального времени;
- возможность обрабатывать не только короткие фразы, но и длинные аудио — даже часовые уроки.

Lead Machine Learning Engineer в Skyeng Роман Смирнов / Conversations 2021
При этом система должна была не только переводить аудио в текст, но и распознать, насколько чисто говорит ученик — то есть смогут ли его понять носители английского.
Оптимально подошла модель на фреймворке wav2vec 2.0. Это трансформер, который работает со звуком. Он принимает на вход сырое аудио и распознает его. При этом wav2vec 2.0 не включает в себя языковую модель — то есть не идентифицирует распознаваемые звуки как язык. Чтобы улучшить точность распознавания речи, трансформер используют вместе с текстовыми декодерами.
Skyeng для этой задачи использовал языковую модель KenLM. Если модель находит несуществующее слово, она заменяет его на наиболее подходящее из уроков школы или ранее используемые слова в монологе ученика.

Как KenLM подбирает вероятно сказанное слово
Команда школы работала с моделью wav2vec 2.0, обученной на датасете Common Voice. Это набор записей с обычных микрофонов (телефонов, ноутбуков) — таких, какие потенциально будут использовать ученики Skyeng.
Подготовка данных для распознавания
Особенность датасета Common Voice — все записи там не превышают 15 секунд. В Skyeng же были записи гораздо длиннее. Чтобы модель могла с ними работать, команда разработала свой алгоритм для адаптивного поиска разделения файлов на фрагменты:
- Алгоритм ищет паузы продолжительностью 1,5 секунды и выше.
- Алгоритм разрезает запись по паузе, пока не получатся фрагменты меньше 15 секунд.
Важно! Склеивать полученные фрагменты обратно нельзя — это приводит к появлению лишних символов на стыке и запутывает модель.
Кроме того, Skyeng вырезает из аудио «пустоты» — например, моменты, когда человек задумался и молчал. Для такой предобработки были написаны несколько расширений для Python на языке RUST — это позволило ускорить процесс предобработки в 40 раз.
Также нужно было разделить всю речь ученика на русскую и английскую. Для этого взяли готовую модель на архитектуре 1D convolution + LSTM и обучили ее на все том же датасете Common Voice. Точность такой модели достигла 86%.
Обработка распознанных текстов
Чтобы перевести перечень слов в читабельный текст, Skyeng использовал готовую модель BERT для английского языка и собственную модель для русского. Обе модели делят слова на предложения и расставляют пунктуацию. С текстом в таком виде уже можно работать и оценивать его по трем параметрам, указанным в начале:
- Лексика. Оценивается, как часто используемые слова используют носители и в каком возрасте добавляют их в свой лексикон. Также определяется, насколько эти слова академические и насколько разнообразна речь.
- Грамматика. Парсер извлекает и определяет более 400 грамматических конструкций английского языка.
- Беглость речи. Измеряется соотношением плотности и скорости речи.
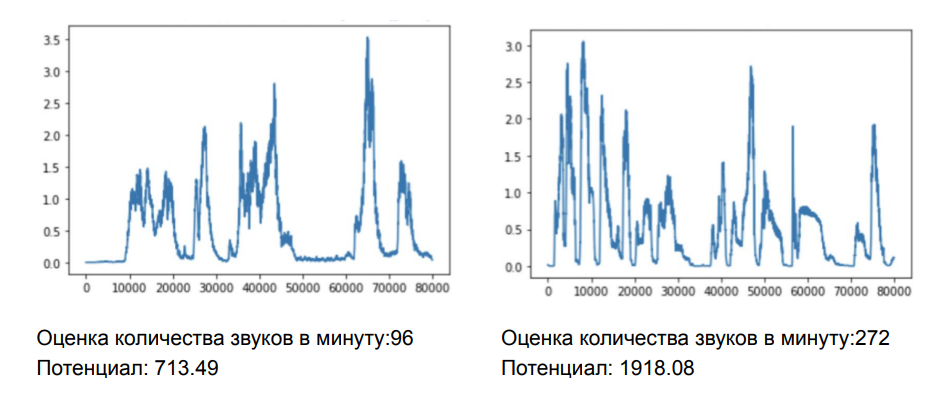
Отдельно оценивается произношение. Команда машинного обучения Skyeng главной задачей ставила определить, сможет ли понять ученика англоговорящий человек.
Для этого снова использовали датасет Common Voice — во всех его записях говорят носители языка. Модель wav2vec 2.0 считывает датасет побуквенно. Это дает возможность побуквенно оценить, как произносится то или иное слово. Затем остается сравнить с этой оценкой произношение ученика.
Этот подход дает возможность определить уровень от Beginner до Advanced с точностью до 96%.
Вот как это выглядит в тестовом режиме:

Система еще не запущена и в данный момент обучается на дополнительных записях людей с дефектами речи, чтобы работать еще эффективнее.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: