Когда имеешь дело с данными, постоянно приходится сортировать их по какому-либо критерию. Иногда это сделать довольно просто, например, когда нужно отсортировать список фамилий по алфавиту, но иногда эта задача не представляется тривиальной. Например, когда имеешь дело с Big Data. В этом случае имеет значение не только сам факт сортировки, но и метод, который был избран для данной цели. Правильно выбранный алгоритм может значительно быстрее справляться с заданием. Давайте посмотрим, какие основные способы сортировки существуют и как они реализуются в программном коде Python.
Содержание:
1. Пузырьковый метод сортировки
2. Шейкерная сортировка
3. Сортировка «расческой»
4. Сортировка выбором
5. Пирамидальная сортировка данных
6. Сортировка слиянием
7. Быстрая сортировка или сортировка Хоара
8. Оценка сложности
Заключение
Суть этого популярного метода состоит в том, чтобы сравнивать элементы массива попарно. Если один из элементов меньше другого, мы меняем их местами. Далее — сравниваем следующую пару элементов массива и, руководствуясь той же логикой, меняем их местами если это необходимо. И так далее, до конца списка.
После первого прохода самое большое число сдвинется в конец списка и можно выполнять второй проход, чтобы найти предпоследнее число. Количество итераций будет соответствовать числу элементов минус один. Таким образом, самые большие числа оказываются, например, справа, а самые маленькие — слева в ряду значений.
На языке Python реализация данного алгоритма будет выглядеть следующим образом:
spisok = [11, 56, 42, 12, 22, -3, 37] # сортируемый массив
def buble_sortirovka(massiv):
last_element = len(massiv) — 1
for x in range(0, last_element):
for y in range(0, last_element):
if massiv[y] > massiv[y + 1]: # условие перестановки элементов
massiv[y], massiv[y + 1] = massiv[y + 1], massiv[y] # перестановка элементов
print(massiv)
return massiv
print("OLD SPISOK", spisok)
noviyspisok = buble_sortirovka(spisok).copy()
print("NEW SPISOK", noviyspisok)
После выполнения алгоритма можем наблюдать все этапы итерации пузырькового метода:
OLD SPISOK [11, 56, 42, 12, 22, -3, 37] [11, 42, 56, 12, 22, -3, 37] [11, 42, 12, 56, 22, -3, 37] [11, 42, 12, 22, 56, -3, 37] [11, 42, 12, 22, -3, 56, 37] [11, 42, 12, 22, -3, 37, 56] [11, 12, 42, 22, -3, 37, 56] [11, 12, 22, 42, -3, 37, 56] [11, 12, 22, -3, 42, 37, 56] [11, 12, 22, -3, 37, 42, 56] [11, 12, -3, 22, 37, 42, 56] [11, -3, 12, 22, 37, 42, 56] [-3, 11, 12, 22, 37, 42, 56] NEW SPISOK [-3, 11, 12, 22, 37, 42, 56]
Данный тип сортировки представляет собой улучшенный вариант пузырькового способа упорядочивания данных. Он является двунаправленным и потому еще называется метод сортировки коктейлем. Принцип данного способа состоит в том, что мы делаем проход сначала в одну сторону массива, сравнивая и сортируя по очереди соседние два числа массива. Когда мы дошли до конца массива, наиболее крупное число оказывается в правой его части.
В пузырьковом методе мы возвращались в начало массива и повторяли все заново. В этом методе мы не возвращаемся, а идем влево, попарно сравнивая соседние элементы. Результатом прохода в левую сторону станет минимальное число, которое «вытолкнется» на начало массива. Затем мы снова начинаем движение вправо, сортируя и «выталкивая» предпоследнее число результирующего массива. Дойдя до конца, снова меняем направление сортировки и продолжаем выполнять действия до тех пор, пока массив не будет обработан.
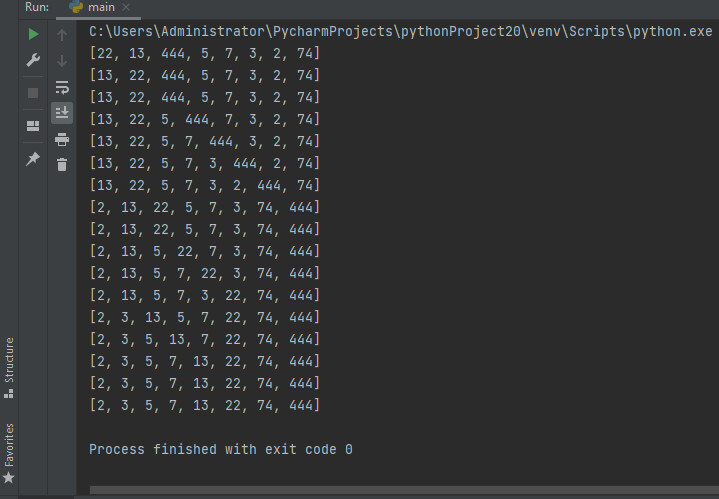
array = [22, 13, 444, 5, 7, 3, 2, 74]
left = 0
right = len(array) — 1
while left <= right:
for i in range(left, right, +1):
print(array)
if array[i] > array[i + 1]:
array[i], array[i + 1] = array[i + 1], array[i]
right -= 1
for i in range(right, left, -1):
if array[i — 1] > array[i]:
array[i], array[i — 1] = array[i — 1], array[i]
left += 1
print(array)
Алгоритм сортировки расческой был разработан Влодзимежом Добосевичем в 1980 году. По большому счету, это — еще одна разновидность пузырьковой сортировки.
При пузырьковом алгоритме сравниваются постоянно два элемента. В сортировке расческой эти элементы берутся не соседними, а как бы по краям «расчески» — первый и последний. Расстояние между сравниваемыми элементами наибольшее из возможных, то есть, это максимальный размер расчески. Теперь уменьшаем «расческу» на единицу и начинаем сравнивать элементы находящиеся ближе: первый и предпоследний, второй и последний.
Снова уменьшаем расстояние между сравниваемыми элементами, на этот раз сравниваем первый и перед предпоследним, второй и предпоследний, третий и последний. Дальнейшие итерации мы проводим постепенно уменьшая размер «расчески», то есть уменьшая расстояние между сравниваемыми элементами.
Первую длину «расчески», то есть расстояние между сравниваемыми элементами следует выбирать с учетом специального коэффициента — 1,247. В начале сортировки расстояние между числами равно размеру массива деленного на это число (разумеется, деление целочисленное). Затем, отсортировав массив с этим шагом, мы снова делим шаг на это число и выполняем новую итерацию. Продолжаем выполнять действия до тех пор, пока разность индексов не достигнет единицы. В этом случае массив доупорядочивается обычным пузырьковым методом.
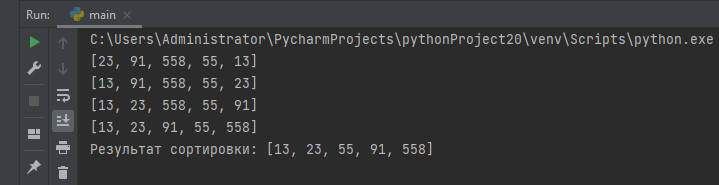
massiv = [23, 91, 558, 55, 13]
def comb(massiv):
step = int(len(massiv)/1.247)
swap = 1
while step > 1 or swap > 0:
swap = 0
i = 0
while i + step < len(massiv):
if massiv[i] > massiv[i+step]:
massiv[i], massiv[i+step] = massiv[i+step], massiv[i]
swap += 1
i = i + 1
if step > 1:
step = int(step / 1.247)
print(massiv)
print(massiv)
comb(massiv)
print('Результат сортировки:', massiv)
Алгоритм сортировки выбором заключается в том, что мы делим список на две части — сортированный и несортированный. После этого мы находим минимальное значение во второй части и передвигаем это значение в начало массива.
Далее снова делим массив на две части — отсортированную и не сортированную, после чего снова в неотсортированной части ищем минимальное значение и сдвигаем его на место второго элемента первой части. Повторяем итерации до тех пор, пока не отсортируем весь массив. При первой итерации сортировки первая часть считается пустой, а вторая содержит весь список. Реализуем данный алгоритм в Python:
def selection_sort(massiv):
for num in range(len(massiv)):
min_value = num
for item in range(num, len(massiv)):
if massiv[min_value] > massiv[item]:
min_value = item
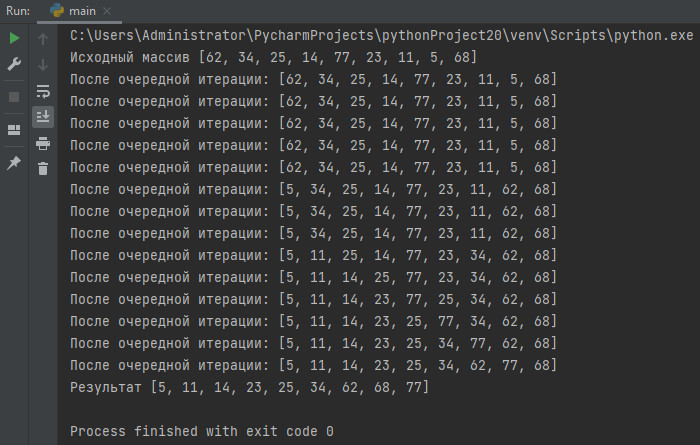
print("После очередной итерации:", massiv)
massiv[num], massiv[min_value] = massiv[min_value], massiv[num]
return (massiv)
massiv = [62, 34, 25, 14, 77, 23, 11, 5, 68]
print("Исходный массив", massiv)
resultat = selection_sort(massiv)
print("Результат", resultat)
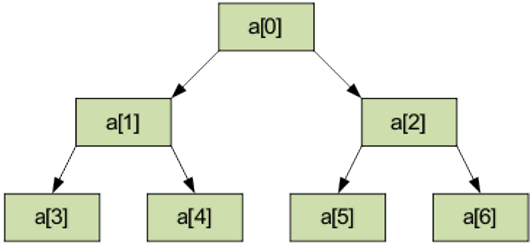
Способ сортировки получил свое название по той причине, что его алгоритм основан на схеме, напоминающей пирамиду. Если быть точным, это даже не пирамида, а так называемое бинарное дерево, узлы которого подчиняются нескольким правилам.
Каждый узел имеет пару узлов-потомков, причем значение числа в узле должно быть выше, чем у потомков. Когда бинарное дерево построено, начинается сортировка. Ее начинают делать с узлов низшего уровня. Берут тройку узлов и перемещают самые большие числа наверх.
После того, как будет выполнена сортировка низших уровней, выполняют аналогичным образом сортировку для узлов на уровень выше. Число, попавшее в вершину пирамиды, записывают в новый массив. Такую сортировку иногда еще называют «сортировка кучей».
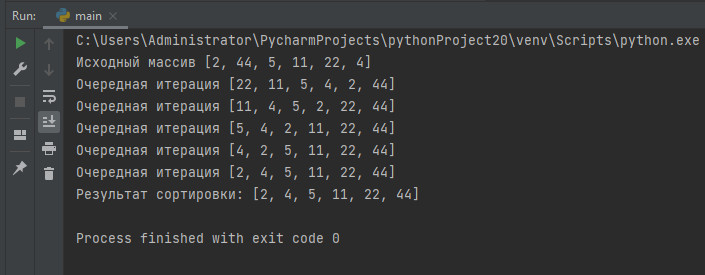
array = [2, 44, 5, 11, 22, 4]
print("Исходный массив", array)
def heapify(array, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and array[i] < array[l]:
largest = l
if r < n and array[largest] < array[r]:
largest = r
if largest != i:
array[i], array[largest] = array[largest], array[i]
heapify(array, n, largest)
def heapSort(array):
n = len(array)
for i in range(n // 2, -1, -1):
heapify(array, n, i)
for i in range(n — 1, 0, -1):
array[i], array[0] = array[0], array[i]
heapify(array, i, 0)
print("Очередная итерация", array)
return array
noviyspisok = heapSort(array).copy()
print('Результат сортировки:', noviyspisok)
Данный метод является рекурсивным, так как повторяется для частей массива. Сортировка слиянием происходит в несколько этапов. Исходный массив делится на два подмассива, после чего каждый из этих подмассивов сортируется отдельно. Затем оба отсортированных подмассива объединяются в один, сравнивая по одному числу.
Вот как это выглядит на практике. Предположим, у нас есть массив: [4, 8, 6, 2, 1, 7, 5, 3]. Делим его на две части [4, 8, 6, 2] и [1, 7, 5, 3]. Первую часть будем сортировать, разбив снова на две части: [4, 8] и [6, 2]. Сортируем левую часть – числа остались на своих местах — [4, 8]. Сортируем правую часть — [2, 6]. Объединяем их в единую часть.
Смотрим на первые цифры – два меньше четырех, значит, записываем ее в массив [2,…]. Снова сравниваем первые цифры – четыре меньше шести, поэтому дописываем в массив [2, 4..]. И снова сравниваем оставшиеся первые числа — шесть меньше восьми, стало быть дописываем шесть — [2, 4, 6..]. И последний элемента массива: [2, 4, 6, 8]. Переходим ко второй части массива и также делим его на [1, 7] и [5, 3]. Сортируем обе части и соединяем их. Получается [1, 3, 5, 7]. Теперь нужно объединить два отсортированных массива [2, 4, 6, 8] и [1, 3, 5, 7].
Смотрим по крайним левым цифрам: 1 < 2, записываем единицу как первый элемент результирующего массива. Теперь сравниваем по первым цифрам оставшихся массивов [., 3, 5, 7] и [2, 4, 6, 8]. 3 >2, значит второй элемент результирующего массива будет два. Снова смотрим на то, что осталось и нужно отсортировать. Имеем [., 3, 5, 7] и [.., 4, 6, 8].
Сравниваем первые цифры – 3 < 4, значит, следующий элемент результирующего массива – тройка. Следующая итерация сравнения [., .., 5, 7] и [.., 4, 6, 8] дает нам четыре. Затем [., .., 5, 7] и [.., .., 6, 8] получаем пятерку, шестерку, семерку и восьмерку. И наш отсортированный массив выглядит как [1, 2, 3, 4, 5, 6, 7, 8].
Реализуем этот рекурсивный алгоритм на языке Python:
A = [1, 3, 444, 55, 66, 45]
def merge_sort(A):
if len(A) == 1 or len(A) == 0:
return A
L, R = A[:len(A) // 2], A[len(A) // 2:]
merge_sort(L)
merge_sort(R)
n = m = k = 0
C = [0] * (len(L) + len(R))
while n < len(L) and m < len(R):
if L[n] <= R[m]:
C[k] = L[n]
n += 1
else:
C[k] = R[m]
m += 1
k += 1
while n < len(L):
C[k] = L[n]
n += 1
k += 1
while m < len(R):
C[k] = R[m]
m += 1
k += 1
for i in range(len(A)):
A[i] = C[i]
return A
print('Исходный массив:', A)
noviyspisok = merge_sort(A).copy()
print('Результат сортировки:', noviyspisok)
После запуска имеем на выходе отсортированный массив:
Исходный массив: [1, 3, 444, 55, 66, 45] Результат сортировки: [1, 3, 45, 55, 66, 444]
Массив делится на две части относительно опорного элемента. В одну часть помещаются все элементы, величина которых меньше значения опорного элемента, а в правую часть — элементы со значением больше опорного.
Наиболее удачным для сортировки считается разбиение массива на примерно одинаковое количество элементов. Если длина одной из частей превышает один элемент, то ее рекурсивно сортируем, повторно применяя алгоритм на каждом из отрезков.
import random
a = [9, 5, 111, 115, 112, 43, 65, -98, 543, 687, 4, 7, 8, 3, -8]
def quick_sort(a):
if len(a) > 1:
x = a[random.randint(0, len(a)-1)] # случайное пороговое значение (для разделения на малые и большие)
low = [u for u in a if u < x]
eq = [u for u in a if u == x]
hi = [u for u in a if u > x]
a = quick_sort(low) + eq + quick_sort(hi)
return a
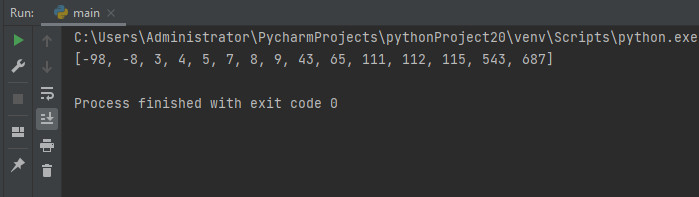
a = quick_sort(a)
print(a)
Мы рассмотрели наиболее популярные алгоритмы сортировки данных. Чтобы правильно выбрать тот или иной способ, необходимо учитывать сильные и слабые стороны того или иного метода сортировки, а также учитывать сложность.
Для оценки сложности алгоритма в программировании используется заглавная буква О (ее еще называют О-нотация). Если оценочная сложность указана как O(f(n)), это означает, что время работы алгоритма (либо объём занимаемой памяти) с увеличением параметра n, характеризующего количество входной информации алгоритма, будет возрастать не быстрее, чем f(n) умноженная на некоторую константу.
Сложность сортировки пузырьковым методом составляет O(n2). На практике данный метод почти не используется, вместо него применяются более эффективные алгоритмы сортировки данных.
Сортировка выбором для массива из n элементов имеет время выполнения в худшем, среднем и лучшем случае O(n2), предполагая что сравнения делаются за постоянное время.
При использовании метода сортировки расческой сложность алгоритма равняется O(n*log2n).
Пирамидальная сортировка имеет доказанную оценку худшего случая, она равна O(n). По причине сложности, алгоритм сортировки эффективен только для больших значений n. Метод пирамидальной сортировки неустойчив, он не поддается распараллеливанию. Пирамидальная сортировка плохо задействует кеширование и подкачку памяти (при одном шаге выборку приходится делать хаотично по всей длине массива).
Сортировка слиянием удобна для работы в параллельном режиме, распределяя задачи между процессорами. Сортировка устойчивая (сохраняет порядок равных элементов), но требует дополнительной памяти под объем входных данных. Скорость работы с «почти упорядоченными» массивами такая же низкая, как и при работе с хаотичными массивами.
Быстрый метод сортировки по Хоару считается одним из самых быстрых алгоритмов упорядочивания данных. Он позволяет реализовывать распараллеливание задач (упорядочивание выделенных подмассивов в параллельно выполняющихся подпроцессах). Данный алгоритм неустойчив.
Сегодня мы рассказали про основные алгоритмы сортировки данных. Большинство других алгоритмов, которые можно встретить, обычно являются различными модификациями описанных методов, рассмотренных выше. Соответственно, их достоинства и недостатки вытекают из исходной реализации данного процесса.
И напоследок мы рекомендуем вам посмотреть несколько видео, наглядно демонстрирующие алгоритмы сортировки:
Быстрый метод сортировки:
Пузырьковый метод сортировки:
Сортировка расческой:
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}