Редакция Highload разобралась, что такое парсеры и зачем они нужны, для каких целей они используются и каковы их особенности. Кроме универсальных решений-фреймворков для программного парсинга, мы рассмотрим также специализированные решения (например, для SEO-задач).
Содержание:
1. Что такое парсер?
2. Преимущества использования парсеров
3. Какие задачи решают парсеры?
3.1. Наполнение интернет-магазина
3.2. Самопарсинг
3.3. Beautiful Soup
3.4. Поиск резюме
3.5. Сбор контактной информации
3.6. Парсинг в соцсетях
4. Виды парсеров
4.1. Облачные парсеры
4.2. Десктопные парсеры
4.3. Браузерные расширения
4.4. Собственные программы
5. Насколько законно выполнять парсинг данных?
6. Парсеры для SEO-специалистов
6.1. Netpeak Spider
6.2. Netpeak Checker
6.3. Screaming Frog SEO Spider
6.4. ComparseR
6.5. Xenu’s Link Sleuth
6.6. A-Parser
6.7. Key Collector
7. Парсеры/скрейперы для социальных сетей
7.1. Segmento Target
7.2. Dexi.io
7.3. OutWit Hub
7.4. Zyte
7.5. Parsehub
8. Как подобрать парсер/скрейпер
9. Заключение
Парсер — это программный инструмент, который автоматически собирает информацию с заданных веб-ресурсов для последующего анализа и использования.
Он позволяет решать разнообразные задачи, в том числе для интернет-маркетинга, SEO, наполнения и продвижения сайтов, анализа тенденций и настроений. Когда нужно обрабатывать миллионы записей, парсер сделает это быстро и эффективно, избавив вас от долгой и нудной работы вручную.
Парсеры значительно повышают производительность получения и анализа данных. Это достигается за счет следующих их преимуществ:
Парсеры дают возможность решать множество задач по сбору и обработке информации, в том числе следующих:
В данной статье мы рассмотрим примеры решения некоторых из этих задач.
Если нет возможности автоматически перенести список товаров с веб-сайта поставщика на свой веб-сайт, можно сделать это самостоятельно с помощью парсера, указав нужные критерии и запустив автоматический процесс сбора. Это, например, наименования продуктов, их фотографии или изображения, описания, цены и т.д.
Вам не приходится обрабатывать сотни страниц вручную. К тому же, парсер может выполнять свои задачи по расписанию, чтобы обновлять информацию. Безусловно, он существенно ускоряет и упрощает работу.
Парсер CatalogLoader позволяет парсить контент по категориям. Структуру категорий можно настраивать под свои запросы, также можно извлекать разные виды информации по категориям. При этом можно не только настраивать, но и самостоятельно создавать параметры, выгружать данные в различные форматы и собирать информацию из нескольких источников на один сайт.
Ресурс Xmldatafeed дает возможность скачивать базы информации о компаниях различных сфер бизнеса, анализировать цены ваших конкурентов и их ассортимент. Если нужная вам компания не найдена, можно отправить запрос на ее добавление.
Самопарсинг — это парсинг собственных интернет-ресурсов. С его помощью можно проверять целостность контента и работоспособность сайта, например, определять, где отсутствуют изображения, не работают ссылки или есть несоответствие между каталогом товаров в базе данных и на веб-сайте.
Сервис PR-CY позволяет проводить SEO-проверку, мониторить сайт и проверять позиции. Также в число его инструментов входят проверка ключевых слов конкурентов, отслеживание посещаемости, проверка текста на уникальность и многие другие инструменты.
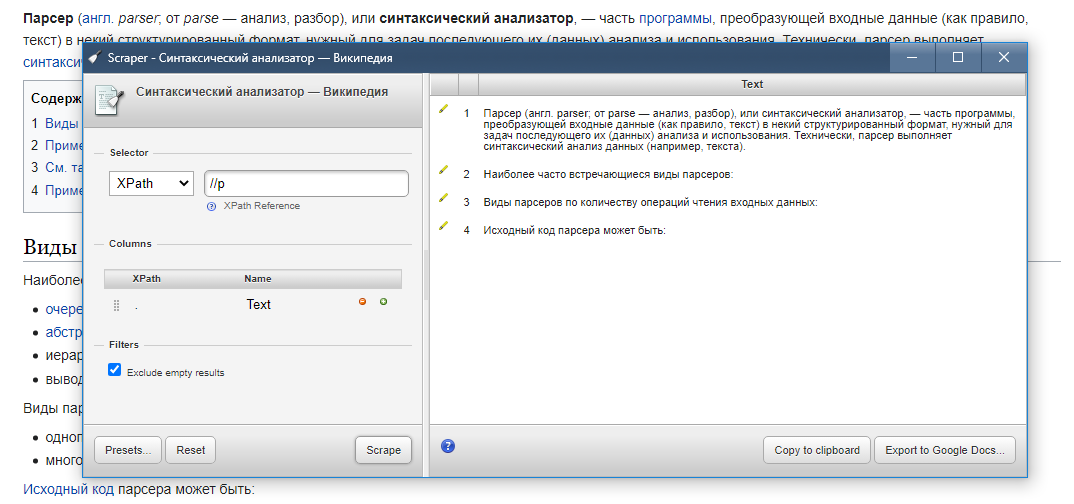
С помощью расширения Scraper можно анализировать страницу с использованием JQuery или XPath:
Beautiful Soup — это популярная библиотека Python для извлечения данных из файлов в формате HTML и XML. С помощью этой библиотеки можно писать собственные парсеры.
Допустим, нам нужно получить с главной страницы сайта Highload заголовки статей из категории «Мнение». Для их получения откроем исходный код страницы. Ниже приведено сокращенное представление блока каждой статьи.
<div class="lenta-item">
<span class="cat-label">
<a href="https://highload.today/category/mnenie/">Мнение</a>
</span> -
<span class="meta-datetime" style="display: contents;">24 часа назад</span>
<span class="flag-post editorial-post"><span>Editorial</span></span>
<a href="https://highload.today/rugajte-kompanii-hvalite-razrabotchikov-i-ne-stesnyajtes-nabrasyvat-na-ventilyator-kak-ajtishniku-stat-zvezdoj-sotssetej/">
<h2>«Ругайте компании, хвалите разработчиков и не стесняйтесь набрасывать на вентилятор»: как айтишнику стать звездой соцсетей</h2>
</a>
...
</div>
Блоки находятся в элементах div класса lenta-item. Нам нужны заголовки тех блоков, в которых есть ссылка с текстом «Мнение».
Предположим, мы создали виртуальную среду bs4_venv и активировали ее.
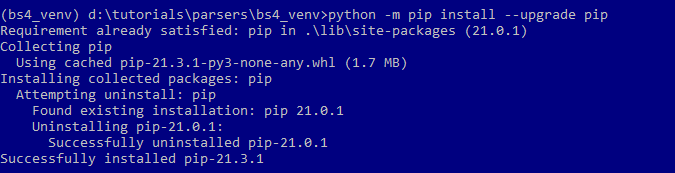
Обновим pip-командой среду разработки:
python -m pip install --upgrade pip
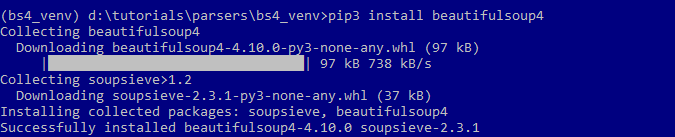
Установим Beautiful Soup:
pip3 install beautifulsoup4
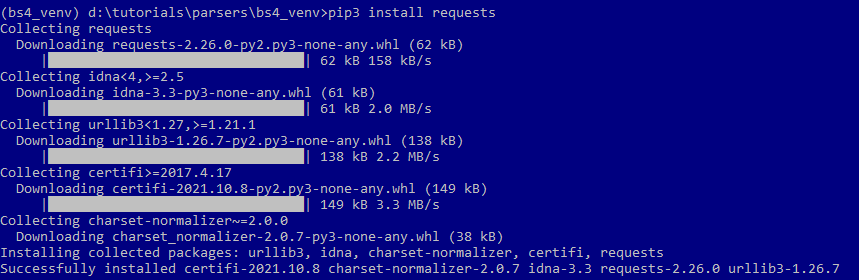
Для получения HTML-страниц нам понадобится модуль Requests:
pip install requests
Теперь можно перейти к написанию кода. Приведенный ниже парсер выводит текст всех заголовков статей нужной нам категории.
from bs4 import BeautifulSoup
import requests
# Укажем страницу для сбора данных
url = 'https://highload.today'
# Получим ее содержимое
page = requests.get(url)
# Объявим список заголовков
titles = []
# Продолжим, если содержимое получено
if page.status_code == 200:
# Создадим объект класса BeautifulSoup для анализа HTML
soup = BeautifulSoup(page.text, "html.parser")
# Найдем код всех блоков: все div класса lenta-item
allBlocks = soup.findAll('div', class_='lenta-item')
# Проанализируем каждый из них
for block in allBlocks:
# Получим метку категории:
# span класса cat-label, в котором есть ссылка с текстом "Мнение"
span = block.find('span', class_='cat-label')
if span is not None:
cat = span.find('a').text
if cat == 'Мнение':
# Если это блок из категории "Мнение" -
# получим текст заголовка 2-го уровня в текущем блоке
title = block.find('h2').text
titles.append(title.strip())
for i in range(len(titles)):
print(i + 1, titles[i])
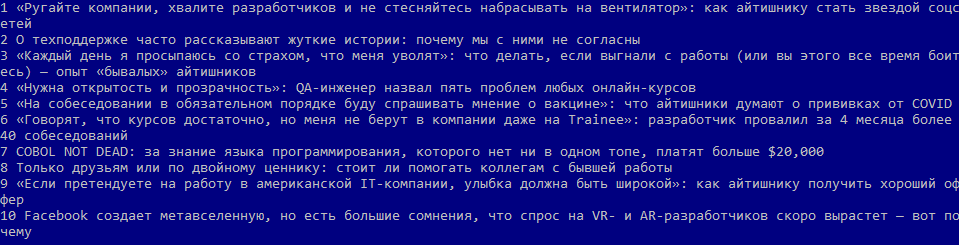
Запустив этот скрипт на исполнение, получим список заголовков:
Парсер очень пригодится, если вам нужно подобрать сотрудника в соответствии с требованиями к вакансии или наоборот — подобрать работу для соискателя. Для этого можно воспользоваться, например, сервисом Sovren. С его помощью можно проанализировать резюме и получить контактные данные, должность и некоторые другие сведения о кандидатах.
Есть множество открытых сайтов и каталогов, в которых можно найти контактные данные различных компаний и физических лиц. Эти данные легко поддаются анализу. Парсеры могут добыть для вас такую информацию. Но помните, что при этом необходимо соблюдать закон о защите персональных данных и убедиться, что сбор информации с сайта не запрещен.
Облачный сервис Diggernaut позволяет создать парсер в соответствии с вашими требованиями и сохранить его в облаке в нескольких форматах на ваш выбор. Этот парсер может выполнять разнообразные задачи, в том числе собирать открытую контактную информацию.
В социальных сетях можно отслеживать настроения пользователей, их отношение к торговой марке, проводить выявление рыночных тенденций, В частности, такие возможности дает сервис Octoparse. Он анализирует данные из Facebook, Twitter, Instagram, YouTube, Weibo и т. д. При этом во внимание принимаются публикации, хэштеги, даты, подписчики, адреса изображений и многие другие данные.
В зависимости от поставленной задачи вы можете воспользоваться онлайн-парсером, установить локальное приложение или расширение для браузера. Если же задача требует особого подхода, закажите приложение под собственные требования или разработайте его своими силами.
Если вы используете облачный парсер, вам не нужно ничего устанавливать на свой компьютер и нагружать его работой. Все делается в облаке, а вы скачиваете результат в нужном вам формате.
80legs — это облачный сервис парсинга, позволяющий пользоваться готовыми приложениями, а также создавать собственные парсеры. Также есть возможность задать спецификации данных, которые необходимо собрать, и воспользоваться функцией поиска по всему интернету. А сервис Datafiniti позволяет получать мгновенный доступ к данным в интернете, минуя парсинг.
Облачный сервис Import.io позволяет превратить любой веб-сайт в структурированные, практически применимые данные. Когда парсер открывает нужный вам URL-адрес в своем интерфейсе, вы «показываете» ему интересующие вас элементы, щелкая на них, а он учится извлекать их в набор данных. После завершения обучения парсер может обрабатывать множество различных веб-страниц по расписанию, создавая крупные наборы данных, готовые к преобразованию, анализу и интеграции в ваши приложения и внутренние системы.
Webhose.io — это тоже облачный сервис. Он преобразует неструктурированный контент из интернета в потоки данных, пригодные для распознавания компьютером, и вы можете принимать эти потоки по требованию. Вы получаете упорядоченные и структурированные веб-данные, независимо от сферы, из которой они взяты, будь то электронная коммерция, новости, darknet, обсуждения, блоги и т.д.
Это standalone-программы, которые устанавливаются на компьютер. Сферы их применения разнообразны.
Screaming Frog — это кроулер веб-сайтов, который позволяет оптимизировать SEO. Он получает данные с сайта и анализирует их на наличие известных проблем SEO.
ComparseR не является типичным парсером, он проводит анализ индексации сайта.
Netpeak Spider — инструмент для поиска ошибок внутренней оптимизации, извлечения данных с веб-сайтов, автоматического SEO-аудита со множеством возможностей.
ParserOK — надстройка для Excel, которая позволяет собирать информацию, анализировать ее, а также обрабатывать данные и выводить их в форматах XLS и CSV.
Выше мы уже упоминали расширение Scraper.
Для Google Chrome доступен также парсер Parsers, который извлекает данные из HTML-страниц и дает возможность экспортировать их в файл XLS, XLSX, CSV, JSON или XML.
Woocommerce Spy позволяет извлекать данные о продуктах с сайтов на базе WooCommerce и экспортировать их в формат CSV.
OutWit Hub автоматически собирает и упорядочивает данные и медиа из онлайн-источников.
Если вам нужен специализированный парсер, его можно разработать самостоятельно или заказать.
Для разработки парсеров уже существует множество библиотек для различных языков программирования, например такие:
| Язык программирования | Библиотеки для парсинга |
| Python | BeautifulSoup Grab и другие библиотеки от lorien |
| JavaScript | Apify SDK |
| Java | Jsoup |
| C# | csQuery Fizzler (надстройка к HtmlAgilityPack, позволяющая пользоваться селекторами CSS) |
| Go | GoQuery |
Конечно же, есть парсеры и для других языков: PHP, Ruby, C++ и т.д.
Также существуют инструменты, предоставляющие API, как, например, Spinn3r. С помощью этих API можно анализировать данные из новостей, блогов, социальных сетей.
Вкратце, сбор информации считается законным, если одновременно соблюдаются эти условия: данные публичны, не уникальны и не защищены авторским правом.
Поэтому, если вы собираете и обрабатываете данные, которые и так находятся в открытом доступе, если их использование не запрещено оператором персональных данных и вы не используете их для рассылок или рекламы с таргетингом, то ваши действия, скорее всего, законны.
Netpeak Spider — десктопный инструмент для повседневного аудита SEO, быстрой проверки на наличие ошибок, комплексного анализа и скрейпинга веб-сайтов.
Кроулер находит битые ссылки и отсутствующие изображения, повторяющийся контент: страницы, тексты, заголовки и теги meta description, заголовки H1. Эти проблемы можно найти всего за несколько щелчков мышью.
Встроенный скрейпер Netpeak Spider позволяет использовать до 100 условий и четыре типа поиска (вхождение текста, регулярные выражения, XPath, CSS). Вы можете выделять из текста адреса электронной почты, телефонные номера и т.п.
Netpeak Checker — десктопный инструмент для скрейпинга страниц результатов поиска и сбора данных с топовых SEO-сервисов для пакетного анализа и сравнения веб-сайтов.
С его помощью вы можете получить метрики по странице из самых надежных инструментов, поисковиков и баз данных, в том числе Serpstat, SimilarWeb, Moz, Ahrefs, Majestic, SEMrush, Alexa, LinkPad, Google Safe Browsing.
Кроме того, Netpeak Checker позволяет мгновенно анализировать трафик конкурентов и находить потенциальных доноров ссылок.
Screaming Frog SEO Spider — это кроулер веб-сайтов, который позволяет улучшить SEO своего сайта, извлекая данные и проверяя их на наличие распространенных проблем SEO.
Вы можете загрузить и проанализировать 500 URL-адресов бесплатно или приобрести лицензию, чтобы получить доступ к расширенным функциям. Анализ результатов проводится в режиме реального времени.
С помощью Screaming Frog SEO Spider можно находить битые ссылки, проверять перенаправления, анализировать заголовки страниц и метаданные, находить повторяющийся контент, извлекать данные с помощью XPath, просматривать URL-адреса заблокированные файлом robots.txt и директивами сервера, создавать XML-карты сайтов, планировать расписание проверок, пользоваться многими другими полезными функциями.
ComparseR — десктопная программа, которая позволяет изучить индексацию сайта. Она анализирует весь ваш сайт, а потом получает самые важные сведения о каждой странице.
Программа обнаруживает внутренние перенаправления, ошибки 404, повторения title, страницы, индексация которых запрещена, и многие другие технические ошибки. Благодаря использованию регулярных выражений можно настроить сканирование и анализ в соответствии со своими требованиями.
ComparseR распознает капчу с помощью нескольких сервисов, поэтому вы можете быть уверены, что его работа не прервется. Кроме этого, ComparseR дает возможность узнать, какие страницы проиндексированы в ведущих поисковых системах.
Программа Xenu’s Link Sleuth проверяет веб-сайты на наличие битых ссылок. Производится проверка обычных ссылок, изображений, фреймов, плагинов, фоновых изображений, карт локальных изображений, таблиц стилей, сценариев и апплетов Java applets.
Программа выводит постоянно обновляемый список URL-адресов, который можно сортировать по различным критериям. Отчет можно создать в любой момент.
A-Parser — многоцелевой парсер, позволяющий анализировать результаты поисковой выдачи в различных поисковиках, определять позицию сайта по ключевым словам, анализировать поисковые подсказки, статистику показов, количество обратных ссылок, собирать ключевые слова, проверять, нет ли сайта в черных списках, распознавать капчу и выполнять многие другие задачи.
Key Collector — программа для составления семантического ядра и составления отчетов по продуктивным запросам. Она позволяет автоматически собирать данные (> 30 источников данных и > 50 параметров статистики).
Мощная система фильтрации дает возможность выбрать самые эффективные запросы.
Segmento Target позволяет собирать из социальных сетей целевую аудиторию для рекламы.
Сервис позволяет находить активную аудиторию, собирать комментарии, комбинировать аудитории, находить владельцев сообществ для продаж B2B, чистить аудиторию от ботов и неактивных пользователей и отслеживать новичков в группах.
Dexi.io — это веб-приложение для автоматизации извлечения данных.
Для работы с ним требуется некоторые навыки программирования, можно интегрировать сторонние сервисы для распознавания капчи, хранения в облаке, анализа текста. Также возможна интеграция с AWS, Google Drive, Google Sheets и т.п.
Оно позволяет отслеживать запасы и цены большого количества SKU, подключать данные к панелям управления, работающим в режиме реального времени, и использовать их для расширенной аналитики продукта.
OutWit Hub отличается простым пользовательским интерфейсом и сложными функциями скрейпинга и распознавания структур данных. Сначала OutWit Hub было дополнением Firefox, а затем развилось в отдельную десктопную программу.
Для ее использования не требуется опыт программирования, и вы можете с легкостью извлекать и экспортировать ссылки, адреса электронной почты, новости в формате RSS и таблицы данных в файлы Excel, CSV, HTML или базы данных SQL.
Также в OutWit Hub есть функция быстрого скрейпинга, которая быстро получает данные из указанного вами списка URL-адресов.
Zyte — это облачная платформа кроулинга, которая позволяет масштабировать кроулеры и предоставляет интеллектуальный менеджер загрузок для обхода контрмер против ботов, готовые сервисы для скрейпинга и наборы данных.
Платформа включает в себя четыре инструмента. Scrapy Cloud предназначен для развертывания и запуска кроулеров на базе языка Python; Portia — это программное обеспечение с открытым исходным кодом для извлечения данных без необходимости в кодировании; Splash — инструмент с открытым исходным кодом для рендеринга JavaScript для извлечения данных из веб-страниц, на которых используется JavaScript; Crawlera — это инструмент, позволяющий избежать блокировки.
Parsehub — это десктопный скрейпер с открытым исходным кодом. Он поддерживает Windows, macOS и Linux. Графический интерфейс позволяет выбирать и извлекать данные со страниц, использующих JavaScript и Ajax. Данные можно собирать из вложенных комментариев, карт, изображений, календарей и даже всплывающих сообщений.
Кроме того, у Parsehub есть расширение для браузера для мгновенного запуска заданий скрейпинга. Данные можно экспортировать в формат Excel, JSON или с помощью API.
Этот список контрольных вопросов поможет вам определить, какой парсер или скрейпер вам подходит:
В вашем распоряжении множество инструментов для парсинга. Они позволяют выполнять самые разнообразные задачи: собирать данные о товарах, контактные данные, отслеживать тенденции на рынке, проводить SEO-оптимизацию. В зависимости от объема данных, который вам нужно обрабатывать, вы можете выбрать либо мощное платное решение, либо вам подойдет бесплатный инструмент (или даже пробная версия). В любом случае эти инструменты на сегодня развиты достаточно, чтобы вы смогли выбрать именно тот, который отвечает вашим требованиям.
Прилагаем видео, которое показывает, как можно быстро и просто написать свой собственный простой парсер на базе языка Python (даже если вы знаете этот язык весьма поверхностно):
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}