Редакция highload.today разобралась, что такое библиотека Scikit Learn для Python (она же sklearn), каковы ее особенности и требования к работе. У этой библиотеки много фич, которые работают из коробки, а также обширная документация. Такое сочетание полезно тем, кто заинтересовался машинным обучением и не знает, с чего начать.
Содержание:
1. Коротко о машинном обучении
2. Что такое Scikit Learn
3. История появления
4. Установка библиотеки
5. Наборы данных
6. Предварительная обработка данных
7. Выбор и работа с моделью
8. Вместо заключения
Машинное обучение (Machine Learning — ML) входит в набор методов искусственного интеллекта и основано на анализе данных и выявлении закономерностей внутри них.
Сравните два подхода к решению задачи:
В первом случае для решения нужно использовать заранее определенный набор правил (или алгоритмов). Во втором случае правила (закономерности, зависимости) выявляются и формулируются после анализа множества наборов исходных данных и / или сопоставления с готовыми ответами (образцами решения задачи).
Проще говоря, ключевой принцип машинного обучения — поиск закономерностей (правил) на основе исходных данных
Обучение с учителем
Обучение без учителя
В следующих разделах мы будем рассматривать разные задачи из этих двух категорий на примере библиотеки Scikit Learn.
Библиотека scikit learn, которую еще называют sklearn python, не зря настолько популярна: она бесплатная и в то же время достаточно мощная. Она построена на базе других популярных Python-библиотек — NumPy, SciPy и matplotlib.
У этой библиотеки, как и многих других Python-пакетов исходный код полностью открыт. Scikit learn можно бесплатно использовать даже в коммерческих целях. А распространяется она под лицензией BSD.
Библиотека scikit learn подходит для решения таких задач машинного обучения:
О каждой из этих задач мы расскажем ниже в следующих разделах.
Отправной точкой стала библиотека Scipy. В 2007 году Давид Курнапо в качестве проекта для Google Summer of Code попытался реализовать надстройку над популярной Python-библиотекой Scipy для научных и прикладных инженерных вычислений. Через год работу над этим проектом продолжил Мэтью Бручер.
Еще через пару лет над scikit learn работала целая команда — Фабиан Педрегоса, Гаэль Вароко, Александр Грэмфор и Венсан Мишель из французского Национального института исследований в области информатики и автоматики (INRIA). Первый релиз библиотеки вышел 1 февраля 2010 года. Разработчики по-прежнему продолжают выпускать новые релизы sklearn python, а проект оброс поклонниками и контрибьюторами по всему миру.
Вместе с другой открытой ML-библиотекой Tensorflow они стали безоговорочными лидерами в open source сегменте. Под влиянием экосистем этих двух проектов изменился и сам Python. Таким образом этот язык переживает новую волну популярности, подхватив тренды на автоматизацию и искусственный интеллект.
Часто ее устанавливают так же, как и другие Python-пакеты — из командной строки.
Предполагается, что у вас уже установлены Python 2.7 или выше, а также библиотеки NumPY (1.8.2 и выше) и SciPY (0.13.3 и выше).
Вариант 1: pip install scikit-learn
Вариант 2: conda install -c conda-forge scikit-learn
Для хранения наборов данных scikit learn в основном использует массивы в формате numpy.array (как вы понимаете — из библиотеки NymPy) и разреженные матрицы в формате scipy.sparse (из библиотеки SciPy). Кроме того, scikit learn поддерживает формат хранения DataFrame из библиотеки Pandas.
Откуда, собственно, берутся эти наборы данных?
Библиотека имеет функции, позволяющие считывать данные из внешних файлов в форматах txt, csv, json и так далее. Например:
import pandas as pd
loaded_data = pd.read_csv('dataset.csv', sep='\t')
loaded_data.head(3)
house_price | surface | rooms_in_house | floor_in_house | total_house_floors | agency | address | latitude | longitude | location |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 10000 | 47.0 | 1 | 8 | 10 | False | Липецк, улица Белянского, 12 | 52.606946 | 39.501812 |
| 1 | 16000 | 54.0 | 2 | 10 | 10 | False | Липецк, ул. Валентины Терешковой, 29А | 52.613101 | 39.574841 |
| 2 | 20000 | 50.0 | 1 | 9 | 16 | False | Липецк, ул. Космонавтов, 3А | 52.616725 | 39.580666 |
В ознакомительных целях достаточно использовать наборы данных, которые поставляются вместе с библиотекой и работают, что называется, из коробки. Это открытые общеизвестные данные, например:
Эти наборы данных имеют умеренные объемы, которых, тем не менее, достаточно для полноценного изучения принципов работы библиотеки.
Например, для подсчета цен на недвижимость в Бостоне библиотека должна загрузить эти данные с помощью встроенной функции sklearn.datasets.load_boston (). В выборке 506 объектов и 13 признаков:
>>> from sklearn.datasets import load_boston >>> x, y = load_boston(return_X_y=True) >>> x.shape, y.shape ((506, 13), (506,))
Для загрузки данных по винам нужно использовать функцию sklearn.datasets.load_wine (). В выборке 178 объектов и 13 признаков.
>>> from sklearn.datasets import load_wine >>> x, y = load_wine(return_X_y=True) >>> x.shape, y.shape ((178, 13), (178,)) >>> np.unique(y) array([0, 1, 2])
Часто бывает недостаточно просто загрузить данные. Перед передачей в модель они должны пройти специальную обработку. Каким образом будут обработаны данные, зависит от особенностей модели. В библиотеке scikit learn за предварительную обработку данных обычно отвечают классы из пакета preprocessing.
Такие алгоритмы машинного обучения, как Метод k-средних и Метод главных компонент (про них мы расскажем далее), лучше работают, когда исходные данные имеют нормальное распределение. В этом случае под стандартизацией будем понимать соответствующее преобразование исходных данных.
Часто это приравнивание стандартного отклонения к единице и/или приравнивание среднего значения последовательности числовых данных к нулю. От такого преобразования «смысл» этих значений не меняется, но меняется, скажем так, способ их отображения в пространстве модели.
Для примера возьмем вот такой исходный массив:
>>> import numpy as np
>>> x = np.array([[0.1, 1.0, 22.8],
... [0.5, 5.0, 41.2],
... [1.2, 12.0, 2.8],
... [0.8, 8.0, 14.0]])
>>> x
array([[ 0.1, 1. , 22.8],
[ 0.5, 5. , 41.2],
[ 1.2, 12. , 2.8],
[ 0.8, 8. , 14. ]])
Добьемся, чтобы среднее значение каждого элемента столбца было равно нулю. Используем класс sklearn.preprocessing.StandardScaler:
>>> from sklearn.preprocessing import StandardScaler
>>> scaler = StandardScaler()
>>> scaled_x = scaler.fit_transform(x)
>>> scaler.scale_array([ 0.40311289, 4.03112887, 14.04421589])
>>> scaler.mean_array([ 0.65, 6.5 , 20.2 ])
>>> scaler.var_array([1.6250e-01, 1.6250e+01, 1.9724e+02])
>>> scaled_x
array([[-1.36438208, -1.36438208, 0.18512959],
[-0.3721042 , -0.3721042 , 1.4952775 ],
[ 1.36438208, 1.36438208, -1.23894421],
[ 0.3721042 , 0.3721042 , -0.44146288]])
>>> scaled_x.mean().round(decimals=4)
0.0
>>> scaled_x.mean(axis=0)
array([ 1.66533454e-16, -1.38777878e-17, 1.52655666e-16])
>>> scaled_x.std(axis=0)
array([1., 1., 1.])
>>> scaler.inverse_transform(scaled_x)
array([[ 0.1, 1. , 22.8],
[ 0.5, 5. , 41.2],
[ 1.2, 12. , 2.8],
[ 0.8, 8. , 14. ]])
Это преобразование, которое меняет диапазоны значений (в данном случае — признаков), но распределение оставляет неизменным.
Разберемся на примере: есть три человека, известны их рост, зарплата и вес.
Разница между величинами в диапазонах для веса и зарплаты очень велика. Некоторые алгоритмы машинного обучения, видя такие отличия, по умолчанию делают вывод, что важнее признак с большими значениями и широким диапазоном. Но часто это не так. Поэтому мы по возможности приводим эти значения к единому масштабу.
from sklearn.preprocessing import Normalizer
# данные о людях (рост, зарплата, вес)
data = [[178, 500000, 58],
[130, 5000, 110],
[190, 100000000, 90]]
scaler = Normalizer().fit(data)
normalized_data = scaler.transform(data)
print('После нормализации:')
normalized_data[:3] # теперь нет гигантской разницы в значениях признаков
После нормализации получим:
array([[3.55999975e-04, 9.99999930e-01, 1.15999992e-04],
[2.59849331e-02, 9.99420504e-01, 2.19872511e-02],
[1.90000000e-06, 1.00000000e+00, 9.00000000e-07]])
Выбор модели определяется типом задачи, которую необходимо решить. Для решения каждого такого типа задач существует свой набор алгоритмов машинного обучения.
Многие ML-алгоритмы реализованы в библиотеке scikit learn в виде набора классов, отвечающих за ту или иную модель обучения. У каждого класса есть свои методы, которые нужно вызывать, чтобы регулировать параметры алгоритма и процесс обучения.
Перед началом обучения нужно сформировать (и при необходимости провести их предварительную обработку) исходные данные и настроить параметры алгоритма обучения модели. Настройка параметров, как мы выясним далее, для каждого алгоритма индивидуальна. Но у каждой модели (точнее у класса, реализующего ее) есть метод fit. Он принимает в качестве аргументов те самые исходные данные.
В начале статьи мы упоминали два ключевых подхода к обучению модели. Проиллюстрируем их ключевое различие на примере простого кода.
X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) # обучающая выборка Y = np.dot(X, np.array([1, 2])) + 3 # выборка с образцами решений … настройка параметров алгоритма обучения <модель>.fit (X, Y)
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]]) # есть только обучающая выборка
… настройка параметров алгоритма обучения
<модель>.fit (X)
Обратите внимание, что в первом случае fit мы вызываем для обеих выборок (для обучающей и тестовой).
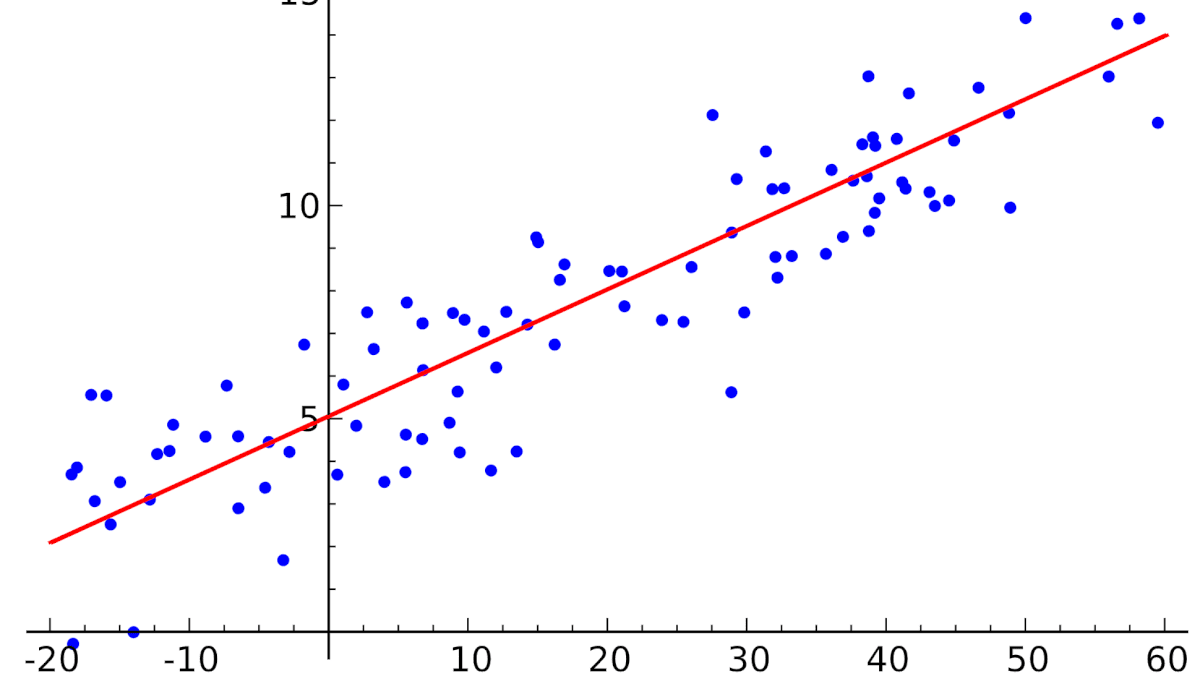
С термином «регрессия» в машинном обучении связано множество алгоритмов для моделирования и прогнозирования количественных соотношений между входными и выходными данными. На практике это сводится к подбору функции, которая лучше показывает зависимость выходных данных от входных.
Например, предположив, что размер зарплаты сотрудника зависит от его опыта работы и уровня образования, можно формализовать эти данные и определить математическую зависимость.
В scikit learn реализованы такие методы регрессии, как:
В машинном обучении под задачей линейной регрессии понимают подбор функции вида
y = kx + b
Одно из достоинств линейной регрессии — наглядность и простота интерпретации результатов.
import numpy as np from sklearn.linear_model import LinearRegression x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1)) y = np.array([5, 20, 14, 32, 22, 38]) #создание модели и настройка параметров алгоритма обучения model = LinearRegression(normalize=True) #обучение модели model.fit(x, y)
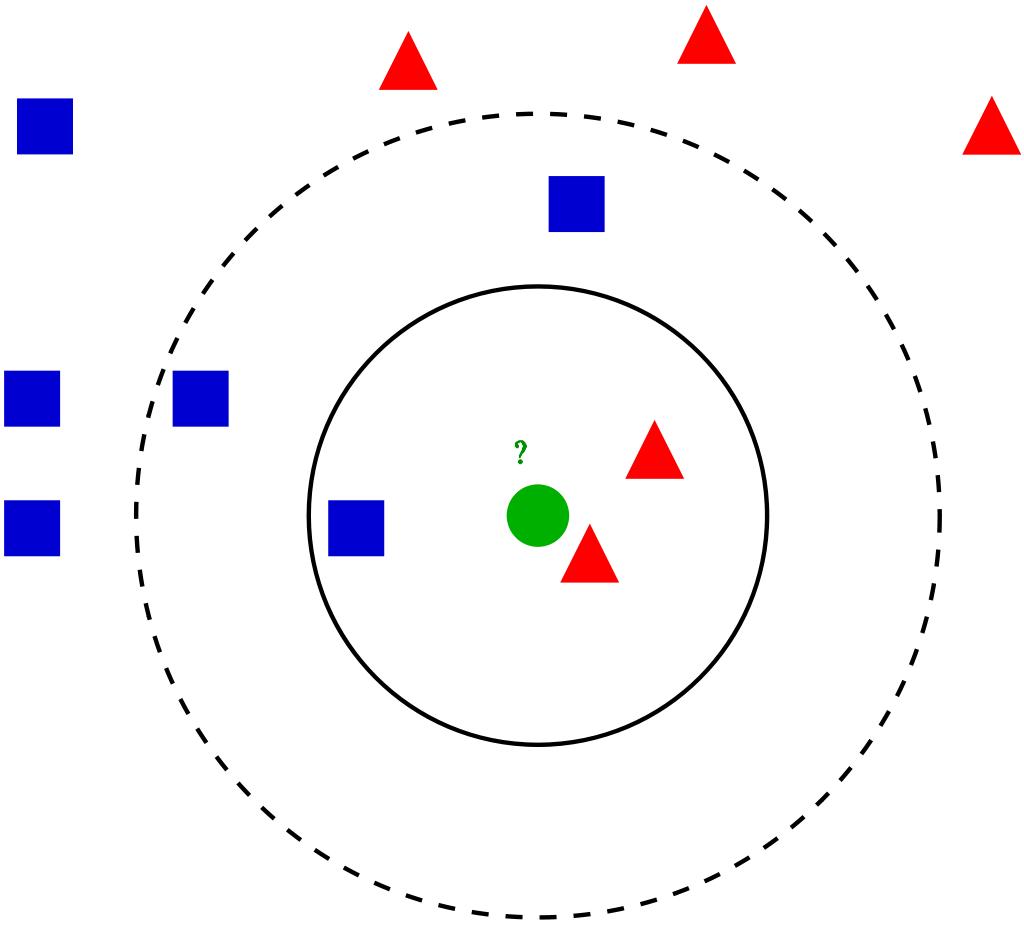
С термином «классификация» связано множество алгоритмов для отнесения объектов к тому или иному классу на основе заданных признаков. Классы также заранее известны и определены.
В scikit learn реализованы такие методы классификации, как:
k-ближайших соседей,Метод анализирует расстояния между выбранным неизвестным объектом и другими объектами (их классы уже известны). В итоге выбранному объекту присваивается класс преобладающего количества k ближайших соседей с одинаковым классом
from sklearn import datasets from sklearn import neighbors iris = datasets.load_iris() # создание и настройка классификатора knn = neighbors.KNeighborsClassifier(n_neighbors = 5) #5 — количество соседей #обучение модели knn.fit(iris.data, iris.target)
Данные внутри ML-модели имеют количественную характеристику под названием размерность. Размерность зависит от количества признаков, введенных в модель. Если там много избыточных или неинформативных признаков, эффективность работы модели будет падать. И даже если все признаки нужные и информативные, начиная с некоторого порогового значения размерности, повышается вероятность переобучения модели. В этом случае алгоритмы модели будут обрабатывать слишком много данных и работать чересчур медленно.
Поэтому необходимость в грамотном уменьшении размерности с сохранением достаточного количества приоритетных признаков. Такие методы позволяют сохранять приемлемую скорость работы алгоритмов модели. И кроме того:
В иностранной литературе его называют Principal Component Analysis (PCA). Это один из лучших методов уменьшения размерности с минимальной потерей ценной информации. Метод используется в таких популярных направлениях ML, как распознавание изображений, сжатие данных и компьютерное зрение.
Пример работы PCA с датасетом Iris из библиотеки scikit learn. Iris представляет собой набор данных о цветках, содержащий 150 записей.
# Импорт библиотек import numpy as np from sklearn import decomposition from sklearn import datasets # Загрузка данных iris = datasets.load_iris() X = iris.data Применения PCA к датасету Iris # Преобразование данных датасета Iris, уменьшающее размерность до 3 pca = decomposition.PCA(n_components=3) pca.fit(X)
Метод можно применять для разных классов данных — не только для данных с нормальным распределением.
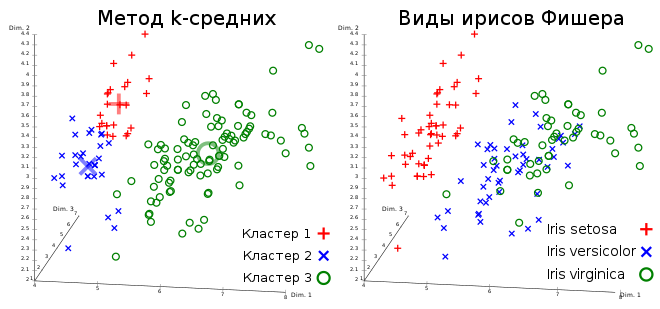
Под кластерным анализом в машинном обучении понимают множество задач группировки объектов по разным наборам признаков и выявление связей между ними. Ключевое отличие алгоритмов кластеризации от алгоритмов классификации в отсутствии заранее определенных классов (то есть образцов решений).
В scikit learn реализованы такие методы кластеризации, как:
k-средних,AP),Алгоритм прост: исходный набор данных разбивается на k кластеров, где k — заранее заданное число. На очередной итерации вычисляется так называемый центр (центроид) для каждого кластера из предыдущей итерации. После этого данные заново разбиваются на кластеры, стягиваясь вокруг новых центров.
Итерационный процесс завершается, когда расположение центров перестает существенно меняться.
from sklearn import cluster, datasets # Загрузка данных iris = datasets.load_iris() # создание трех кластеров k=3 k_means = cluster.KMeans(k) # обучение модели k_means.fit(iris.data)
Часто требуется понять, как будет себя вести модель с другими наборами исходных данных, которые заранее неизвестны. Такая задача называется предсказанием или прогнозом.
В scikit learn за это отвечает метод predict. Он есть у каждого класса, реализующего какую-либо модель обучения.
# новые данные для которых мы хотим получить предсказание
test = np.array([[5, 1], [0, 3], [2, 1], [11, 1], [9, 3], [9, 1]])
# получение предсказания для метода k-средних и нового набора данных
y = kmeans.predict(test)
print('Предсказание: ', y)
Результат работы программы:
Предсказание: [1 1 1 0 0 0]
Библиотека scikit learn достаточно проста в использовании (по сравнению с другими ML-библиотеками). При этом она далеко не универсальна: эта библиотека больше подходит для обучения моделей с учителем, в ней не реализовано обучение по ассоциативным правилам, а также также не реализован механизм обучения с подкреплением.
Продвинутое видео про основы scikit learn с примерами и комментариями:
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}