
Відомий фізик Нільс Бор казав: «Проблеми важливіші за рішення. Останні можуть застаріти, а проблеми лишаються». Я повністю згоден із цим твердженням. Особливо, якщо говорити про моделювання та організацію даних у застосунках. Ця проблема досі з нами.
З одного боку, реляційні бази даних неідеальні для сучасного світу з його безмежним масштабуванням. З іншого — нові NoSQL-моделі теж мають недоліки як мінімум з дублюванням даних. Тому мало не кожен розробник шукає найкращий спосіб організації бази даних. Інколи це завдання можна вирішити, об’єднавши реляційні та нереляційні схеми.
У цій статті я поясню на прикладах, як застосувати NoSQL-підходи в реляційних базах даних і коли це буде доречно. На багатьох теоретичних моментах я не загострюватиму увагу. Адже сподіваюсь, досвідчені читачі розуміють, про що йде мова.
Зміст
1. Особливості реляційних баз даних
2. Проблеми реляційних БД
3. Що таке NoSQL
3.1 Key-Value Store
3.2 Column Family
3.3 Graph Databases
3.4 Document Databases
4. MongoDB на практиці
5. Переваги та недоліки NoSQL
6. Використання JSON в реляційних базах даних
7. Переваги та недоліки JSON в реляційних БД
8. Висновки
Особливості реляційних баз даних
Більшість розробників добре знають концепцію реляційних БД та користуються нею мало не в кожному проєкті. Існуванню цієї моделі ми завдячуємо її основоположнику Едгару Кодду. У 1970 році він випустив статтю A Relational Model of Data for Large Shared Data Banks, де вперше описав концепцію, побудовану на реляційній алгебрі. В той час його ідею, відверто кажучи, не зовсім зрозуміли. Тому згодом Едгар для більш детальної формалізації своєї теорії опублікував 12 правил Кодда.
Що ж робить реляційну БД саме реляційною:
- Схема БД. До неї входять набір таблиць, їх атрибути та відношення між ними. Також тут є Primary Key, Foreign Key тощо. Цю схему важливо знати заздалегідь, тому що без цього неможливо покласти в БД якісь дані.
- Нормальні форми. Якщо зробити базу даних як одну величезну таблицю з усіма даними, то працюватиме це дуже погано. Дані варто розбити на менші таблиці та створити зв’язки між ними. Для цього й існують нормальні форми. На них будуються реляційні БД.
- ACID-транзакції. Осмілюсь сказати, що це найважливіше в описаному типі баз даних. Назва ACID походить від Atomicity (атомарність), Consistency (послідовність), Isolation (відокремленість) та Durability (довговічність). У реляційній системі БД існує транзакційний механізм, в результаті якого набір запитів або набір операцій із БД по закінченню збереже всі ці дані. При цьому лише тоді всі ці дані будуть узгоджені між собою, а доступ до них буде навіть при падінні всієї системи.
Ці принципи допомагають досить добре організувати роботу з базами даних, зробити її простішою та зрозумілішою. Саме тому реляційні бази даних такі популярні.
Проблеми реляційних БД
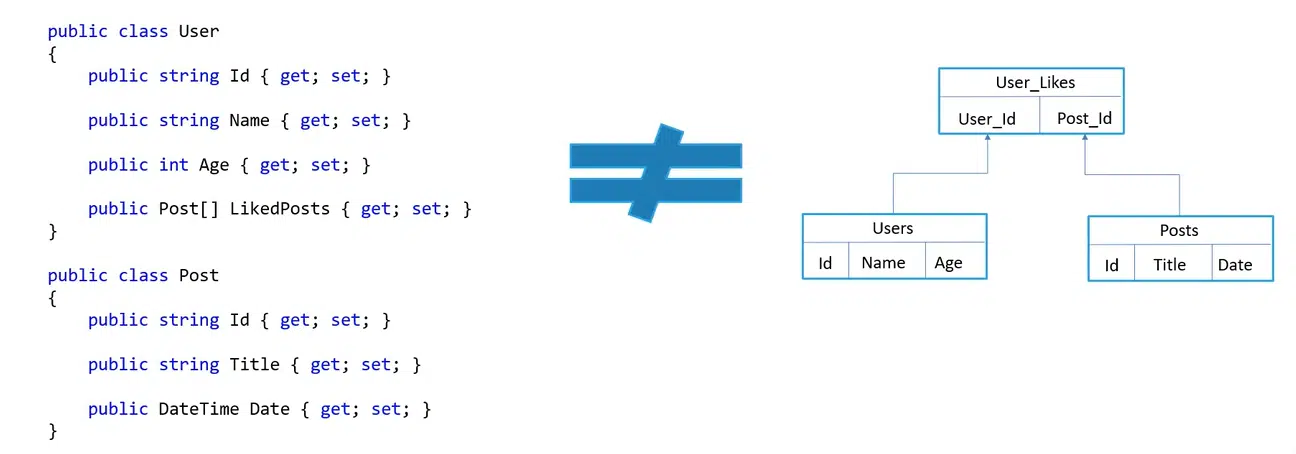
Однак до таких баз даних із часом почали з’являтися питання. Першою незручністю, через яку розробники стали шукати альтернативу, став Object-relational impedance mismatch — невідповідність об’єктно-реляційного імпедансу. Поясню цей термін на прикладі.
Уявіть, що є клас User зі своїми полями, а в ньому — колекція постів, які він, реальний юзер, лайкнув. Проте, якщо почати за описаними правилами будувати схему БД і розміщувати ці дані, вони будуть зберігатися в дещо іншому або взагалі не такому форматі, який є в пам’яті. Через це розробники повинні вигадувати механізми для отримання снапшоту даних, писати query з join, знати відношення між таблицями, повертати відповідність назад після отримання — і все це доставляє чимало клопоту.
Натисніть, щоб роздивитися
Для подолання цієї проблеми були спроби створити об’єктноорієнтовані бази даних. Але ідея не прижилася, адже це були ті ж самі реляційні БД із вбудованим механізмом мапінгу. Справжні проблеми почалися з виходом на нові масштаби: коли чи не у кожному домі з’явився швидкісний інтернет, а великі бізнеси розпочали операційну діяльність по всьому світу. Саме тоді розробники задумалися про горизонтальне масштабування, коли система масштабується завдяки простому додаванню інстансів.
Ідея проста: один реквест повинен оброблюватися однією нодою. Чим більше нод, тим більше реквестів можна виконувати. Проте це не кейс реляційних БД.
Припустимо, в БД є Users та Posts. Ми вирішили масштабувати базу, але можуть виникнути певні питання:
- по-перше, юзери можуть бути на різних нодах;
- по-друге, пости для юзера на одній ноді можуть опинитися на іншій.
Через це для виконання запиту, наприклад, select from users joins post, треба сходити вже на дві ноди. До того ж дані можуть бути розподілені нерівномірно. В результаті швидкість обробки даних падає, а система виходить занадто складною. Тому потрібна була інша альтернатива.
Що таке NoSQL
Як це часто буває, перших успіхів у створенні нового типу БД здобули великі компанії — Google та Amazon. Вони одні з перших вирішили відійти від реляційності та знайти нову парадигму. Протягом 2006-2007 років з’явилися статті Big Table від Google та Dynamo від Amazon про їх хмарні бази даних. Озвучені в публікаціях ідеї не були пов’язані з реляційною теорією. Там не було табличок, зв’язків, джойнів, а головне — розробники цих систем досягли справжнього масштабування.
Цей досвід надихнув багатьох програмістів розвивати подібні ідеї. Так у 2009 році декілька розробників організували мітап на цю тему. До події приєдналися серйозні бренди, серед яких MongoDB, CouchDB та інші. Ініціатори заходу шукали не стільки гасло до нього, а щось на зразок хештегу, аби привернути увагу спільноти в Twitter. Так і виникла назва NoSQL.
Основних моделей декілька, і кожна має свої особливості, переваги та недоліки. Тому трохи розкажу про кожну з них.
Key-Value Store
Це найпростіша NoSQL-парадигма. В сховищі зберігається ключ та value — і все. Немає жодних складних філдів, зв’язків між key-value, немає взагалі нічого. Головна перевага — така структура масштабується безмежно. Її найяскравішим прикладом є Redis, який багато хто використовує як кеш.

Натисніть, щоб роздивитися
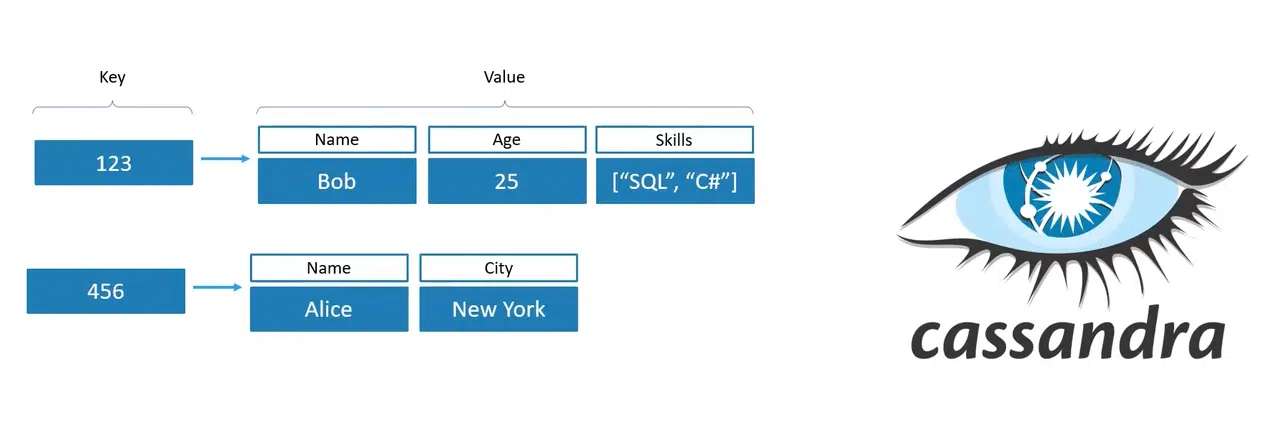
Column Family
Ця модель взяла key-value та посунула її далі. Тут також є key, проте value вже не простий рядок, а набір із власних пар key-value. Тобто це вже система колонок зі значенням, де кожен рядок може мати свої набори. Приклад такої БД — Cassandra.
Натисніть, щоб роздивитися
Graph Databases
Цей варіант дещо екзотичний і базується на концепції графів. Згідно ідеї, зв’язок між даними — це теж певні дані. Побудова таких зв’язків-даних і буде нагадувати граф. Таким чином можна отримати широкі можливості створення ієрархії або заплутаних зв’язків. Так працюють фактично всі соцмережі.
Один юзер пов’язаний з іншим як друг, той у свою чергу підписаний на якусь групу, а перший лайкає якісь пости — і це все приклади зв’язків, які є даними. На цій моделі створено Neo4j. У нього є навіть вельми цікавий синтаксис для написання запитів до такої незвичайної БД.

Натисніть, щоб роздивитися
Document Databases
У багатьох розробників NoSQL асоціюється передусім із Document Databases — документними БД. Їх принцип виглядає таким чином: по якомусь ключу зберігається цілий документ у вигляді набору з key-value-значень безкінечної вкладеності та найнесподіванішої структури, яка тільки може знадобитись. Один із популярних прикладів реалізації цієї парадигми — MongoDB.

Натисніть, щоб роздивитися
MongoDB на практиці
Про MongoDB мені хотілося б розповісти детальніше. Уявімо проєкт, в якому треба побудувати Google Forms із простою функціональністю: юзер може створювати форму з вільним набором полів, будь-якої кількості.
Моя форма «NoSQL vs SQL» проста: поля з радіобаттоном, зі шкалою та із free-text. Однак юзер може створити складну форму. Наприклад, з Personal Information або Employee Details, де є таби: ПІБ, дата народження, досвід роботи, технології тощо.
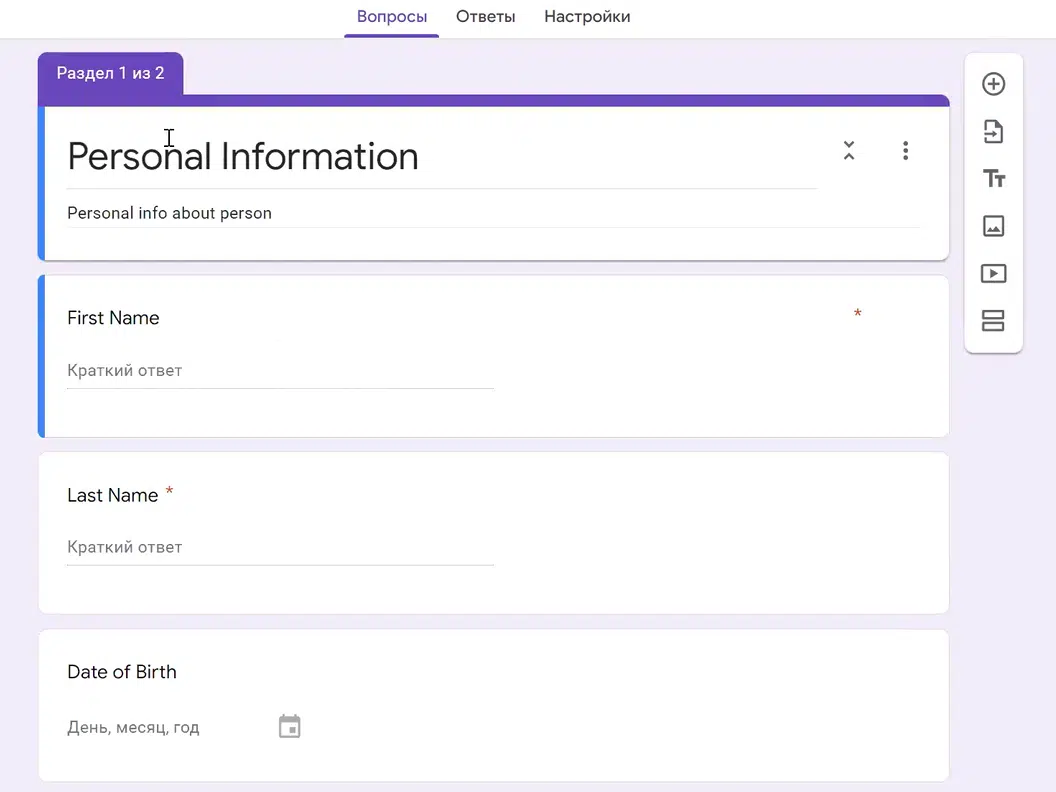
Якби ми вирішували цю задачу в реляційній парадигмі, було б дуже важко створити схему БД. Адже ви не знаєте, скільки філдів буде, які філди будуть створені в майбутньому, як буде розширюватися їх функціонал тощо. Саме тут в нагоді стане MongoDB.
Натисніть, щоб роздивитися
Для вирішення проблеми можна створити form schema, яка описує структуру та можливі дані. Наприклад, у form schema є службові поля: createdDate, description, назва форми. У полі schema буде набір філдів, які описує схема. Наприклад, є філд single-choice із полями name та options. При цьому останній — це масив об’єктів. Також є філд типу range з мітками min та max, з простим числом, та філд free-text із якимось hint.
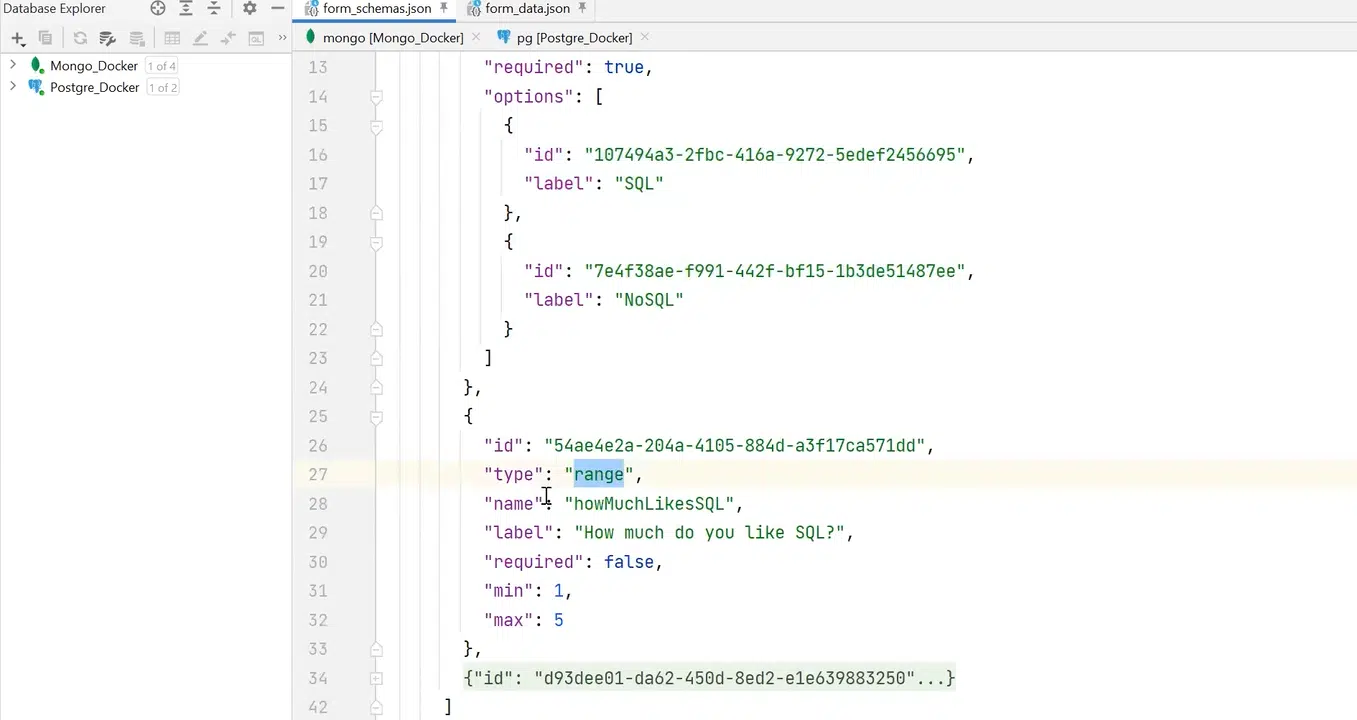
Натисніть, щоб роздивитися
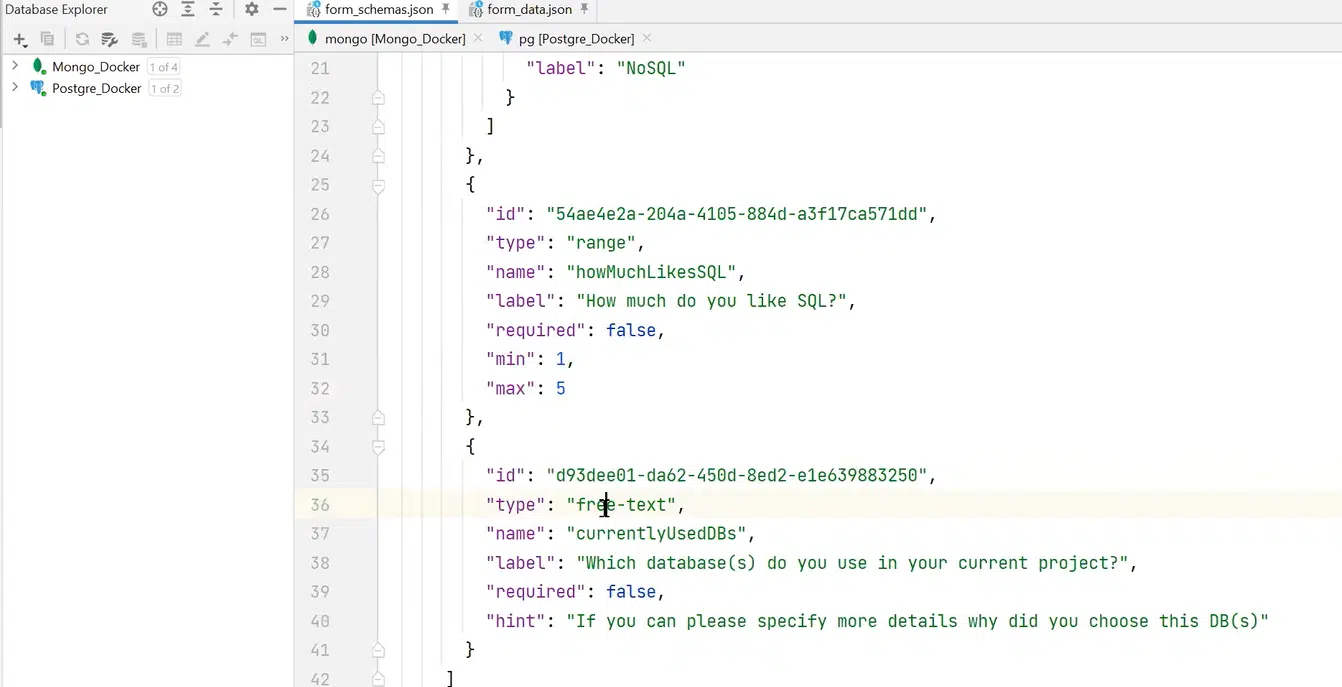
Натисніть, щоб роздивитися
Припустимо, що нам потрібна не така складна форма Employee Details. Можна створити field type з назвою field-group, у якого будуть свої філди — це буде така собі рекурсивна структура. Там може бути free-text, number, date — і так само з другим табом.

Натисніть, щоб роздивитися
Ідеально все це зберігати в JSON, а відповіді — в іншому форматі. Наприклад, у нас є fillDate, інформація про те, що ми заповнили, та поле data, де всі потрібні дані заповнюється відповідно до описаної схеми.
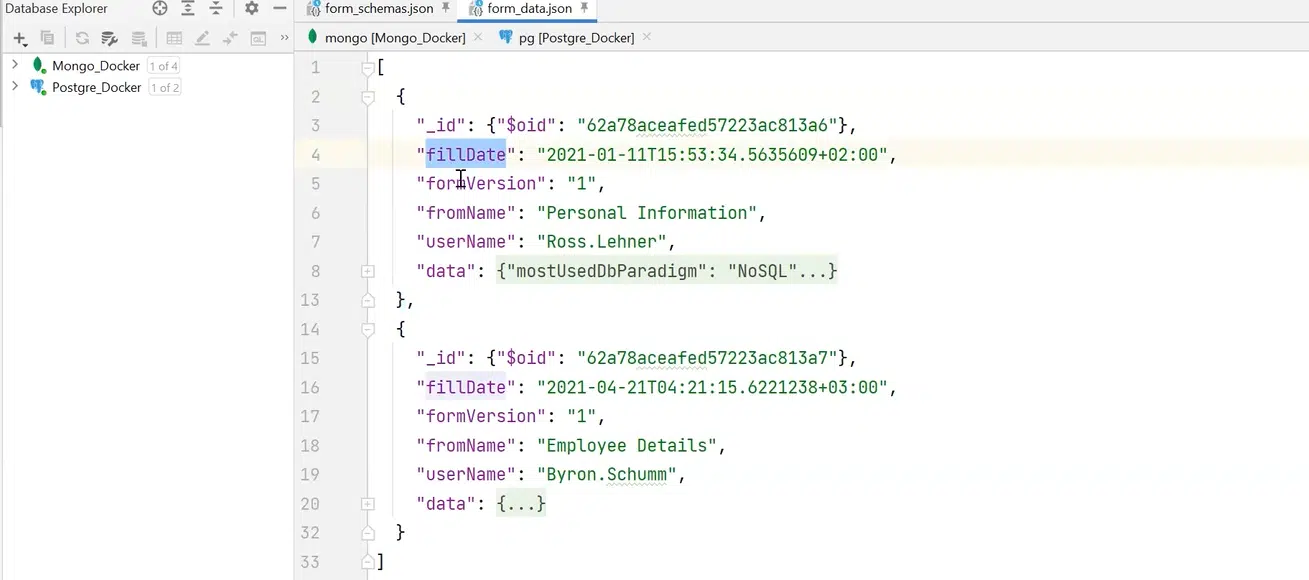
Натисніть, щоб роздивитися
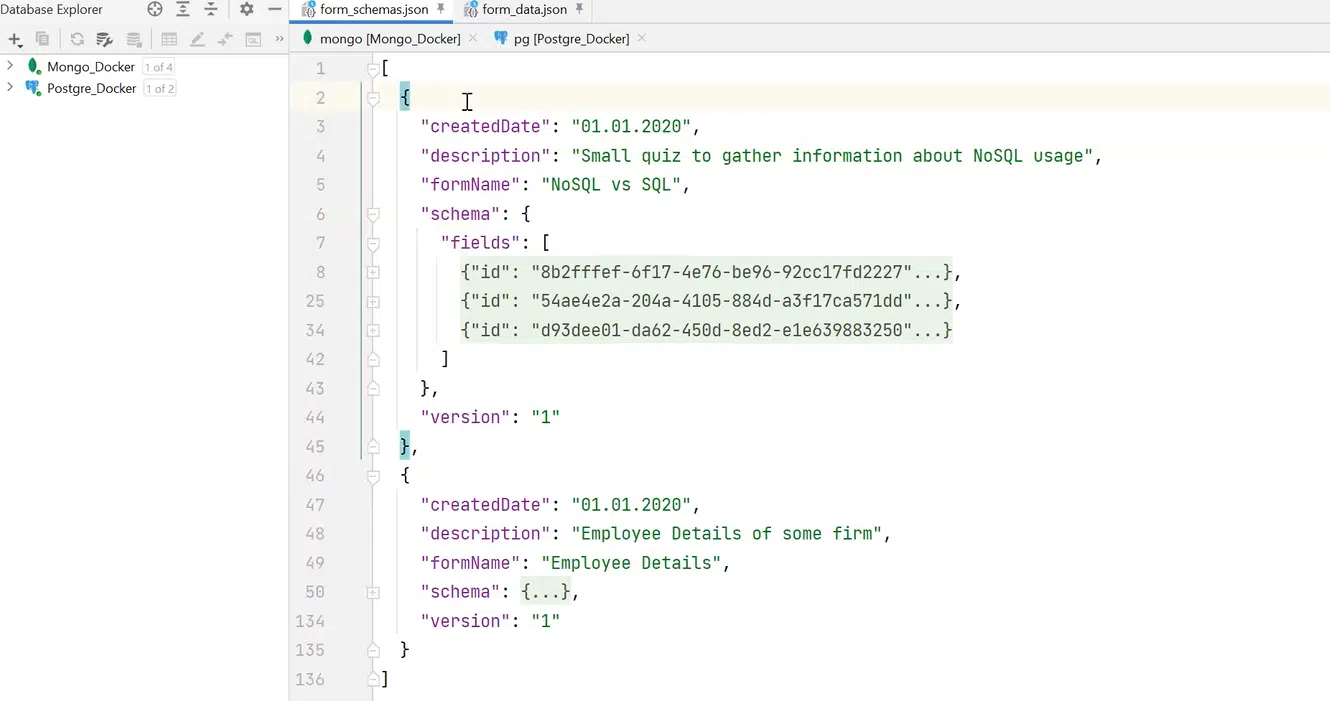
Як це реалізувати в MongoDB? У цій БД є таке поняття як колекції. Якщо порівняти це з реляційним світом, то це таблиці, але з однією дуже важливою відмінністю. В колекції може лежати що завгодно. Наприклад, я створив колекції form_schemas та form_data для одного та другого JSON-файлів відповідно.
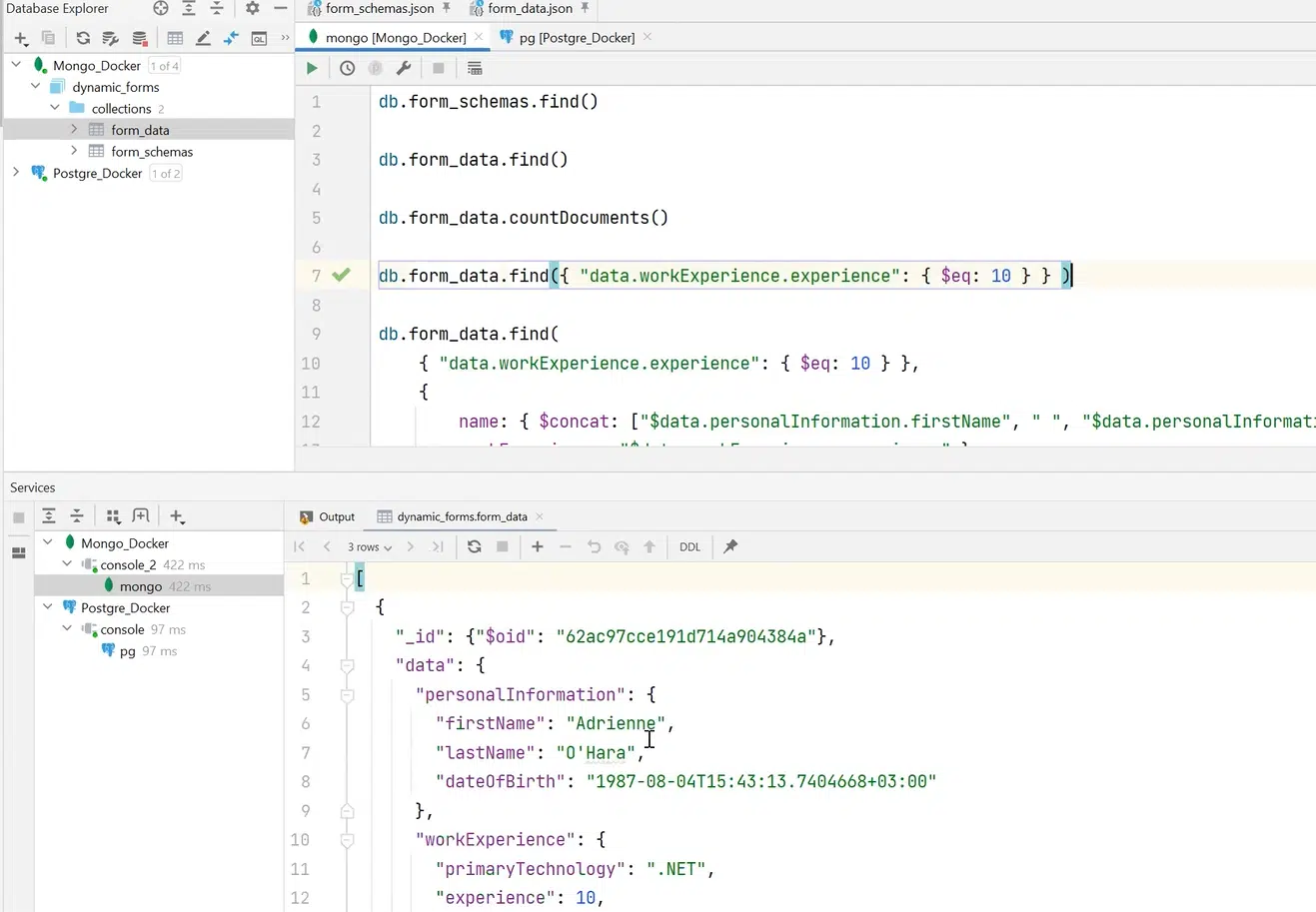
Натисніть, щоб роздивитися
Також за допомогою API та Query-синтаксису в Mongo я можу задати пошук всіх наявних form_schema та отримати список документів. У нашому випадку їх два. Це ті самі визначені вище form_schema.
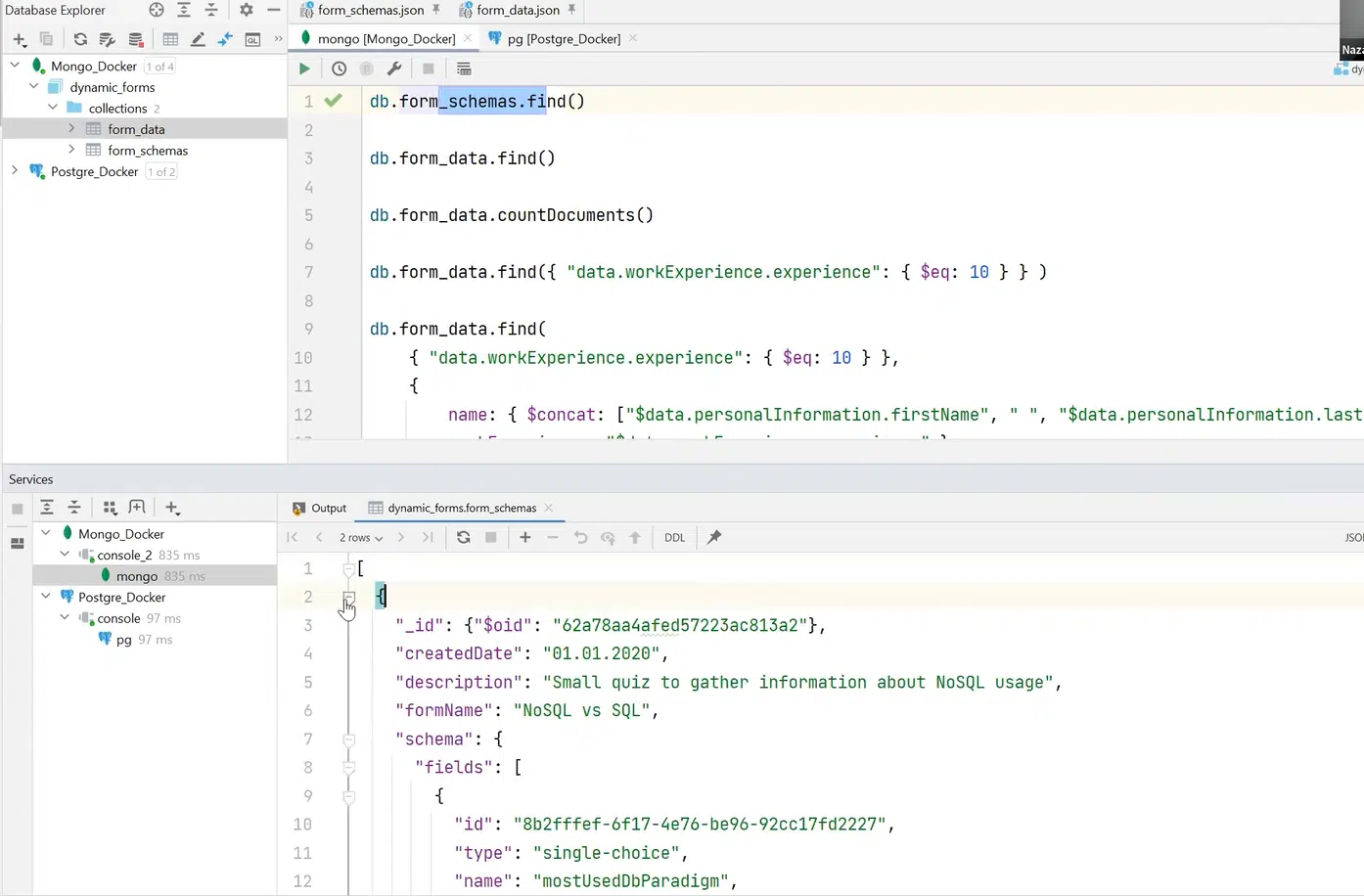
Натисніть, щоб роздивитися
Так само я можу отримати всі form_data та документи, які належать до цієї колекції.
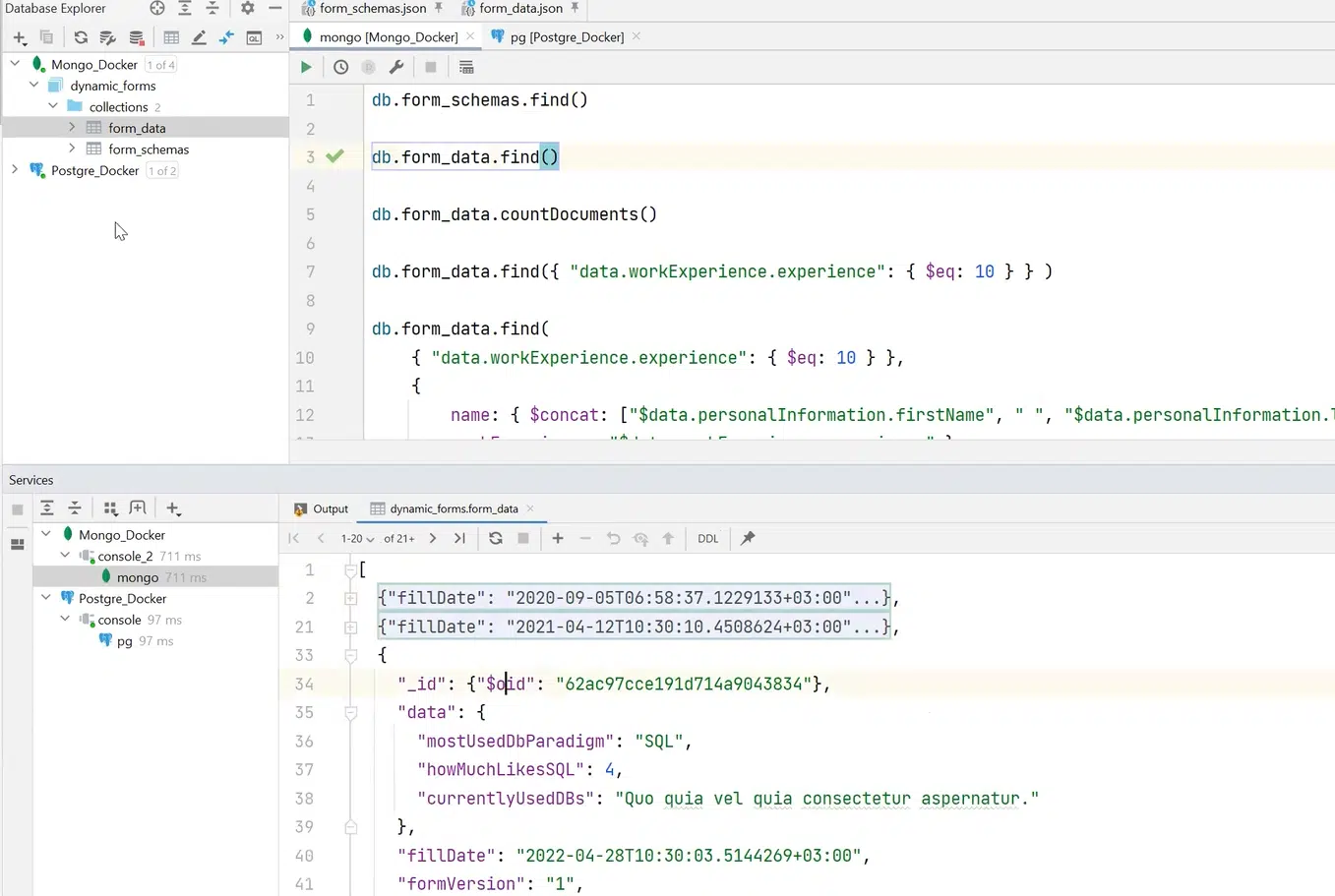
Натисніть, щоб роздивитися
Крім цього, можна створювати й запити. Наприклад, треба вибрати специфічну form_data — лише ті дані, де workExperience 10 років. За допомогою спеціального синтаксису та інструментів MongoDB можна відшукати людей із досвідом 10 років.

Натисніть, щоб роздивитися
Якщо ж ці філди не потрібні, можна розширити запит і зробити вибірку потрібних полів. Наприклад, name та workExperience.
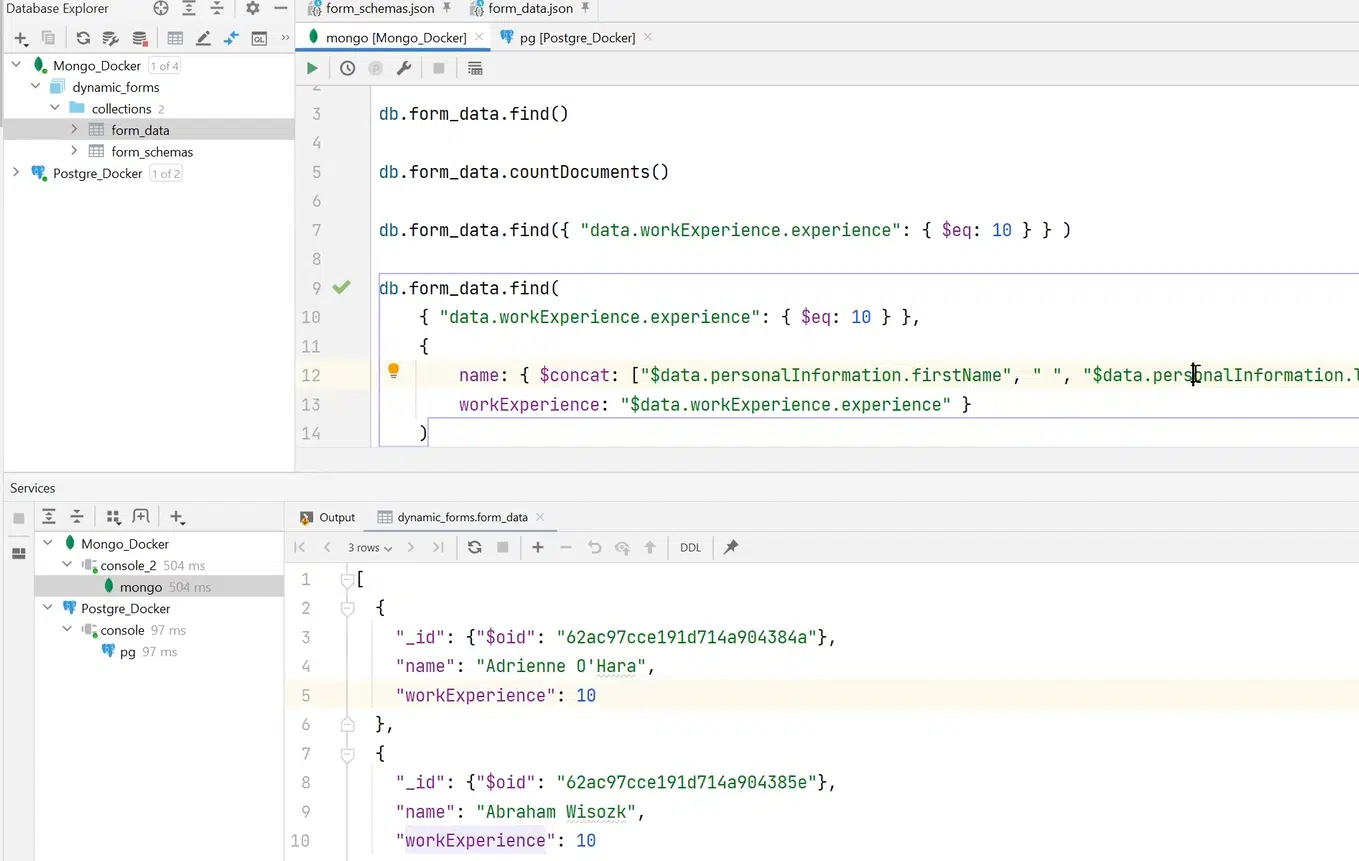
Натисніть, щоб роздивитися
Важливо пам’ятати, що колекції є schemaless. Вам не потрібно інсертити дані, які підпадають під схему. Це може бути рандом. Наприклад, як об’єкт на ілюстрації нижче. Такий запит виконується без проблем:
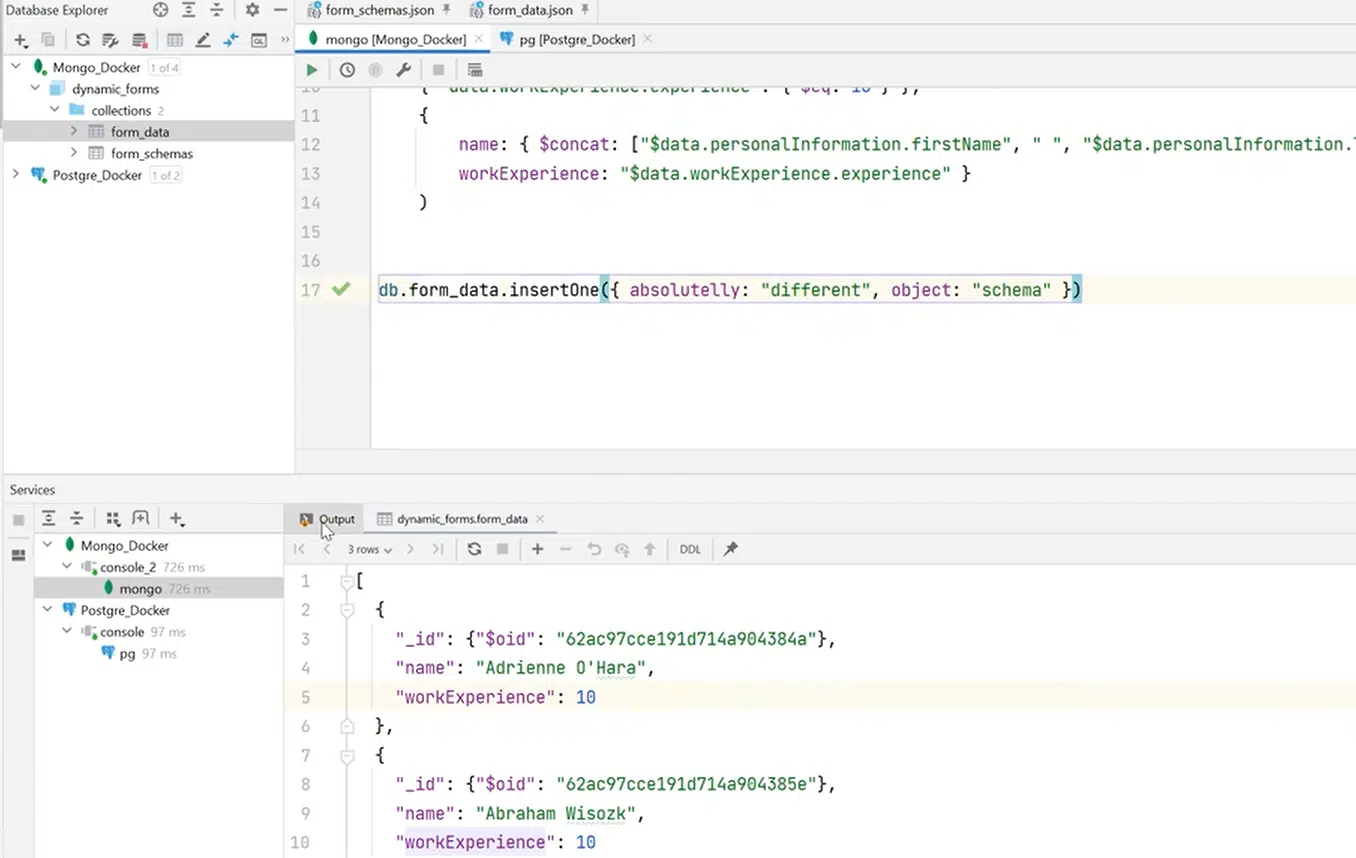
Натисніть, щоб роздивитися
Переваги та недоліки NoSQL
Як і будь-яке інше рішення, нереляційні БД мають позитивні та негативні риси. Якщо узагальнити різні моделі NoSQL, то серед їхніх переваг можна виділити:
- Масштабування. Зазвичай виконується завдяки PartitionKey. Це фрагмент даних, про який відомо, що він лежить в одному місці. В цьому полягає суть горизонтального масштабування. Якщо ми кладемо дані заздалегідь, тому що знаємо PartitionKey, масштабування буде майже безмежним.
- Позбавлення Object-relational impedance mismatch. На прикладах з MongoDB я показав, що дані можуть мати потрібні схему та структуру. Для цього не треба писати складних джойнів або моделювати дані не так, як ви їх використовуєте.
- Schemaless. В одну колекцію можна інсертити об’єкти будь-якої форми так, як вам зручно. Хоча, звичайно, це може бути й недоліком NoSQL.
Як на мене, головні недоліки нереляційних баз даних такі:
- Часткова підтримка транзакцій. Різні парадигми NoSQL та окремі БД частково підтримують концепти ACID, але загалом їх немає. Ними пожертвували задля масштабування системи.
- Відмова від реляційності. Якщо у вас немає джойнів, то у вас з’являється… дублювання даних. Тут важливо розуміти: це норма для подібної системи — не баг, а фіча, як-то кажуть. Тому потрібно моделювати дані таким чином, аби подібна система була настільки ефективною, наскільки це реально.
- Обмежені можливості пошуку по складних критеріях. У NoSQL є find, як я згадував у прикладі. Однак у глобальному концепті масштабування є проблеми. Якщо дані лежать на великій кількості нод, то для пошуку за певним критерієм без Partition, треба обійти буквально всі ноди. Це фактично нівелює масштабування як таке.
Що стосується концептів нереляційних баз даних, тут варто зважати на те, де ви будете використовувати ту чи іншу базу. Адже що добре для одного розробника, не завжди добре для іншого. Це яскраво демонструє використання NoSQL-моделей тими чи іншими компаніями.
Наприклад, на Key-Value Store базується Redis, стандарт для fileload-систем. Column Based зустрічається в продуктах Facebook, Instagram та Netflix — для предикшенів, покращення Machine Learning та фільтрації контенту. На Graph Databases побудований каталог eBay. Document Databases є найбільш поширеним типом NoSQL-баз. З ним можна змоделювати будь-яку структуру даних та CMS.
Використання JSON в реляційних базах даних
Завдяки своїм можливостям масштабування нереляційні БД досить популярні, проте вони не можуть стати ідеальним рішенням. Свого часу розробники замислились: чи можна використати напрацювання зі світу NoSQL та вирішити задачу саме в реляційній формі?
У наведеному нижче прикладі маємо реальні дані в полі data, які заповнює юзер, та схема форми у конкретному документі, а також дані-дублікати: _id, fillDate, formVersion, fromName.
Складається враження, ніби дані можуть існувати у вигляді звичайної таблиці в SQL, адже їхня кількість та якість однакові. Проте, що тоді робити з чудернацьким полем data?
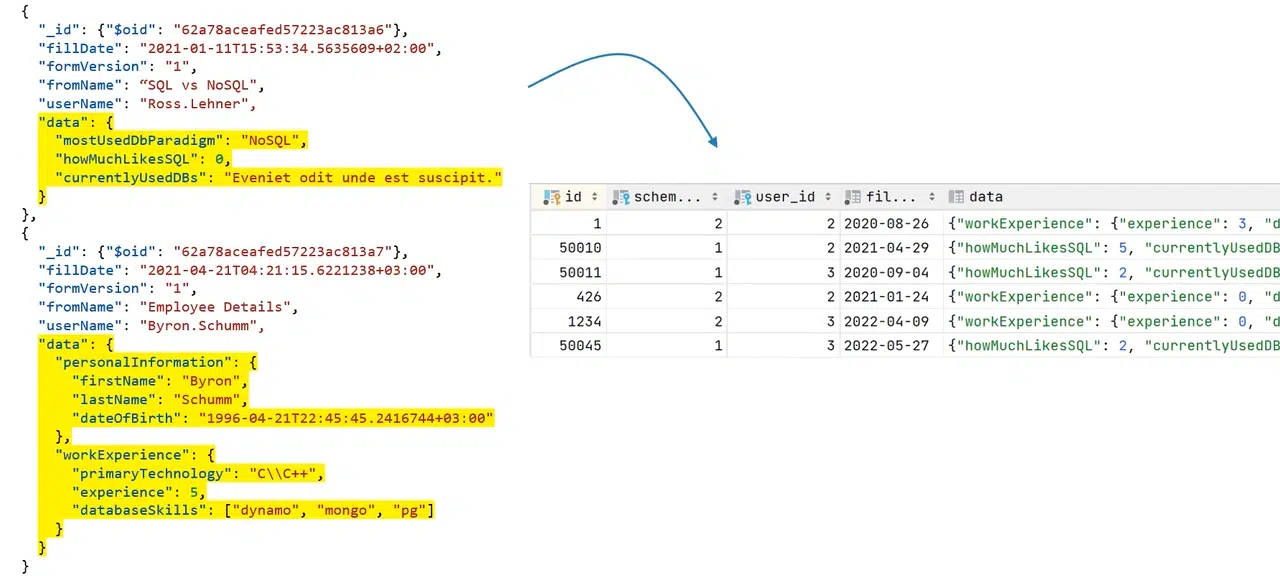
Натисніть, щоб роздивитися
Перше, що спадає на думку — зробити колонку колонку data у SQL, NVARCHAR(MAX). По суті це стрінга, і можна розміщувати все, що заманеться. Проте на Application Layer потрібно було б валідувати, що це JSON. Якщо потрібен пошук, це викликає певні проблеми. Тому сьогодні більшість БД надають спеціальний тип даних або інструменти, які допомагають маніпулювати JSON у самій базі.
Для прикладу я візьму PostgreSQL, де такий тип даних називається jsonb. Він бінарний та підтримує такі ж операції над собою, як і JSON: валідацію формату, гнучкі інструменти пошуку по вкладеним філдам та можливість створення індексу. Давайте розглянемо його можливості на практиці.
У PostgreSQL в мене є три таблиці: users, form_schemas та form_data. Це та ж сама структура, як і в MongoDB. По факту form_schemas — це дефініція форми, а form_data — заповнені користувачем дані.
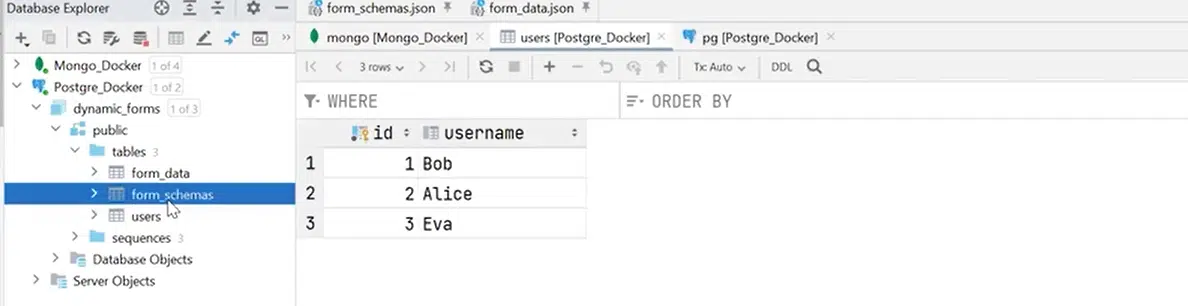
Натисніть, щоб роздивитися
Також можете побачити, що у form_schemas загальні поля розбиті на власні колонки, а schema — це вже JSON.
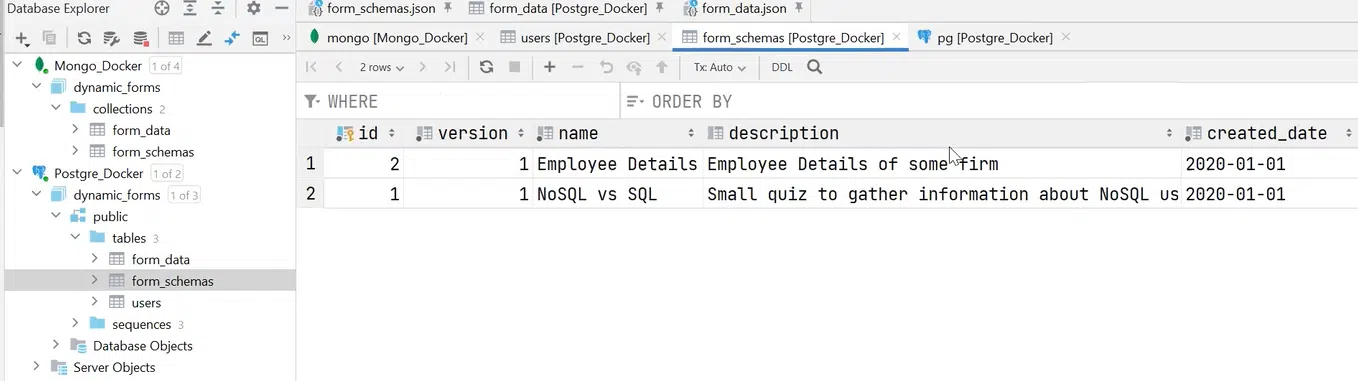
Натисніть, щоб роздивитися
Те ж саме можна сказати і про form_data.
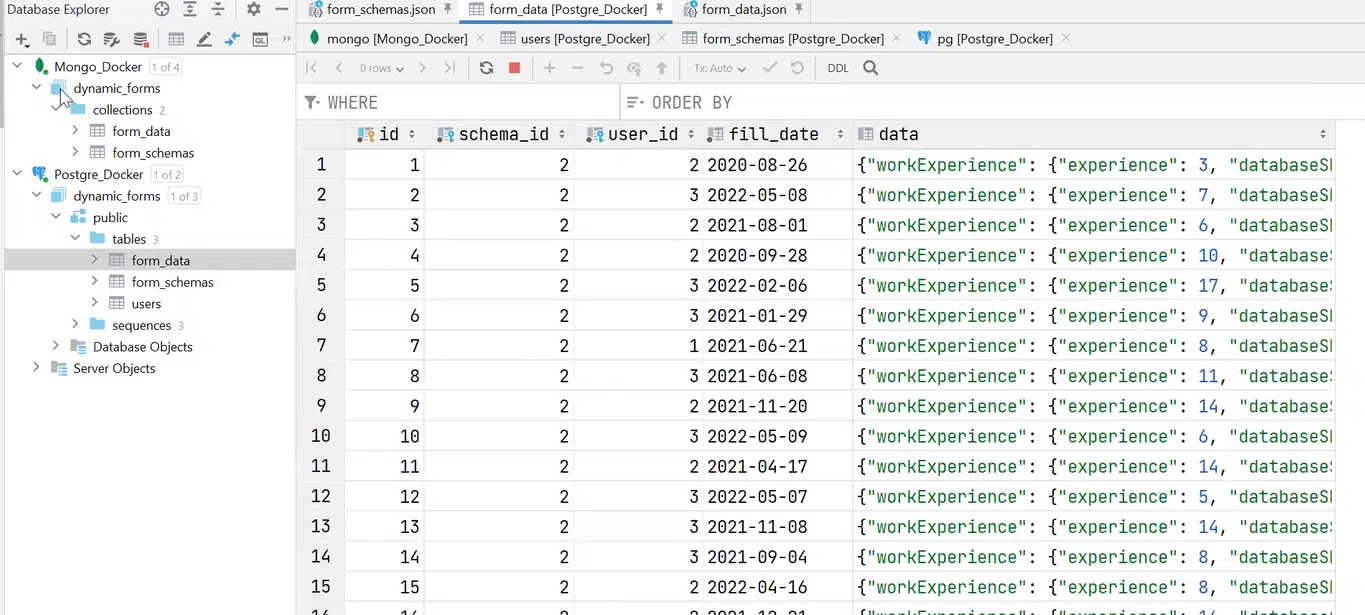
Натисніть, щоб роздивитися
Зверніть увагу: тут є окремі поля та зв’язки — валідні foreign keys. Наприклад, після відкриття визначення таблиці можна знайти data (той самий jsonb), а в foreign keys побачити schema_id (вона вказує, до якої схеми належить jsonb) та user_id (вказує на юзера, який заповнив таблицю). Це все і забезпечує узгодженість даних.
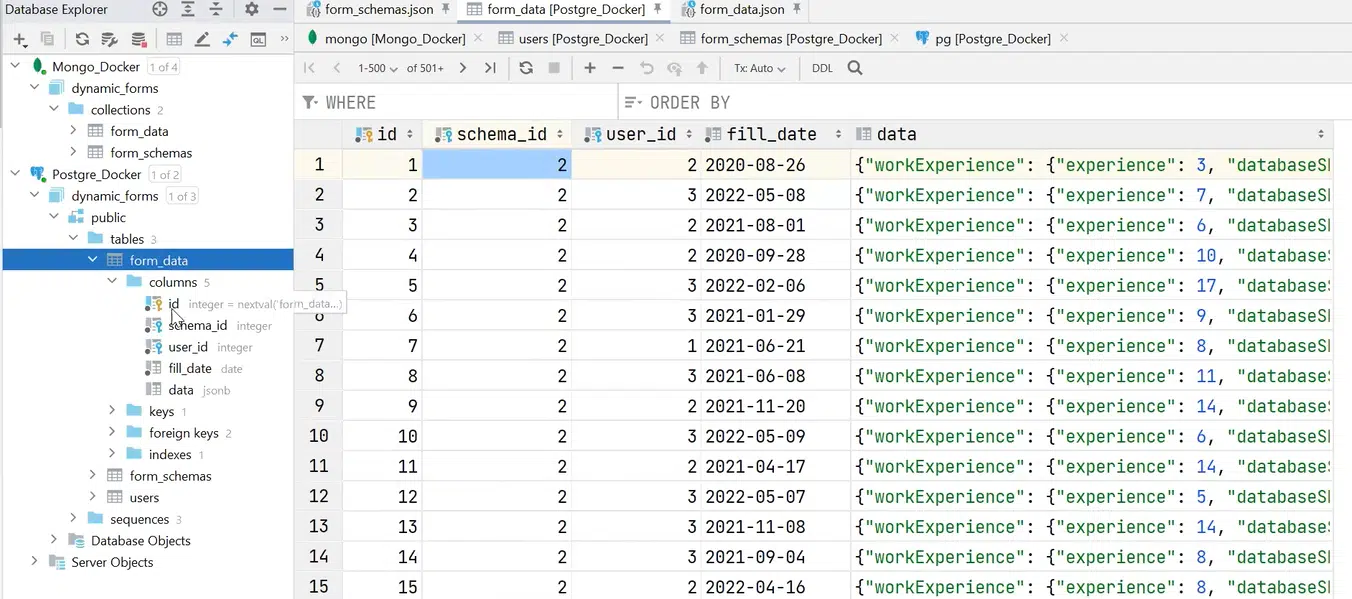
Натисніть, щоб роздивитися
Також це надає інструменти для маніпулювання датою. Передусім варто зрозуміти, що можна витягнути з JSON. Спеціальним синтаксисом зі стрілкою -> можна звертатися до полів будь-якої вкладеності. Різниця між одинарною та подвійною стрілками полягає в тому, що дві — діють як термінальна операція. Тобто ми select робимо, як текст, і це така стрінга.

Натисніть, щоб роздивитися
Можна застосувати і більш короткий синтаксис. Наприклад, щоб достукатися до personalInformation firstName, зробити це коротко й отримати дані з того поля data. До того ж це відбувається дуже швидко, хоча тут 100 тис. запитів:
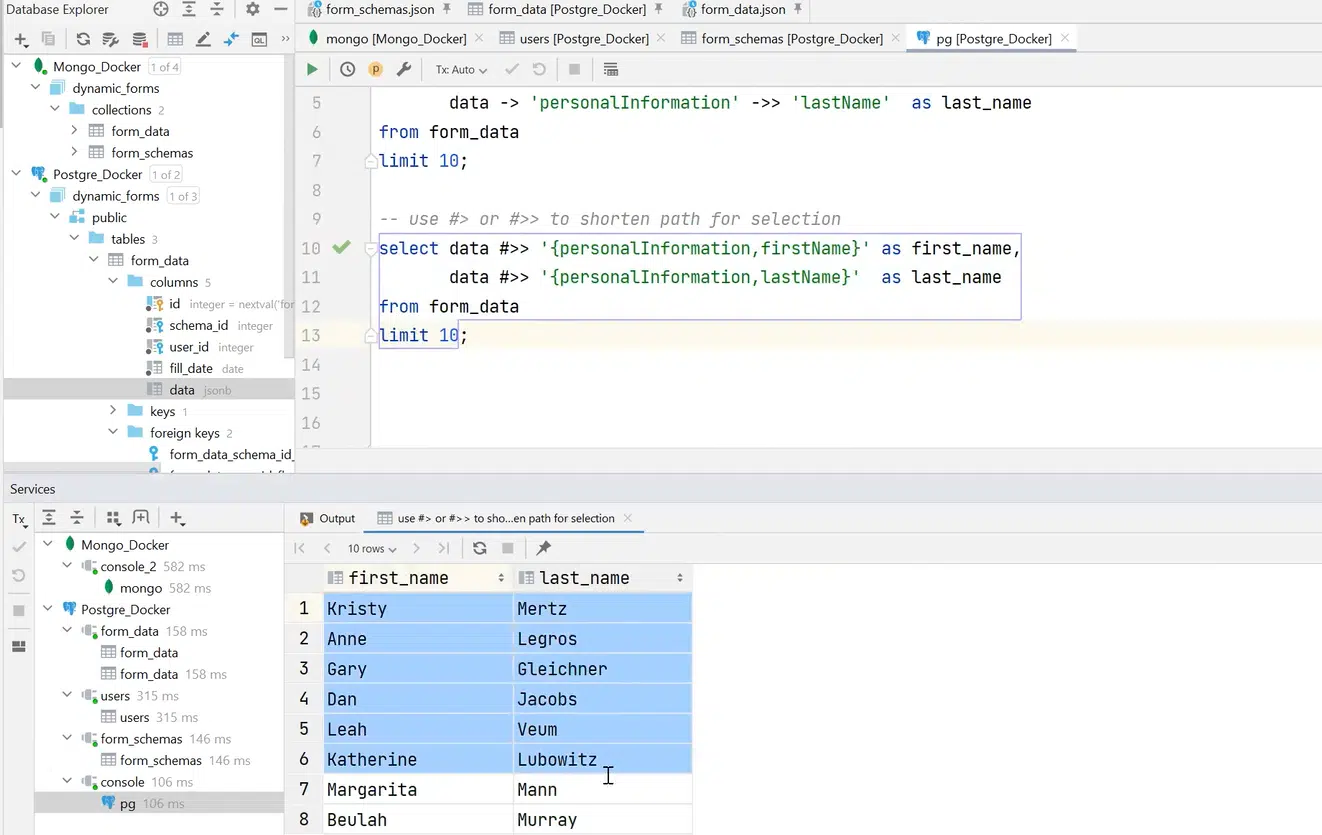
Натисніть, щоб роздивитися
Також можна використовувати цей expression не лише у select, але й у where. Наприклад, нам потрібно вибрати користувачів з workExperience понад 10 років. Оскільки повертається текст, необхідно конвертувати його у вигляді числа, але врешті ми отримаємо всіх юзерів із досвідом роботи більше 10 років.
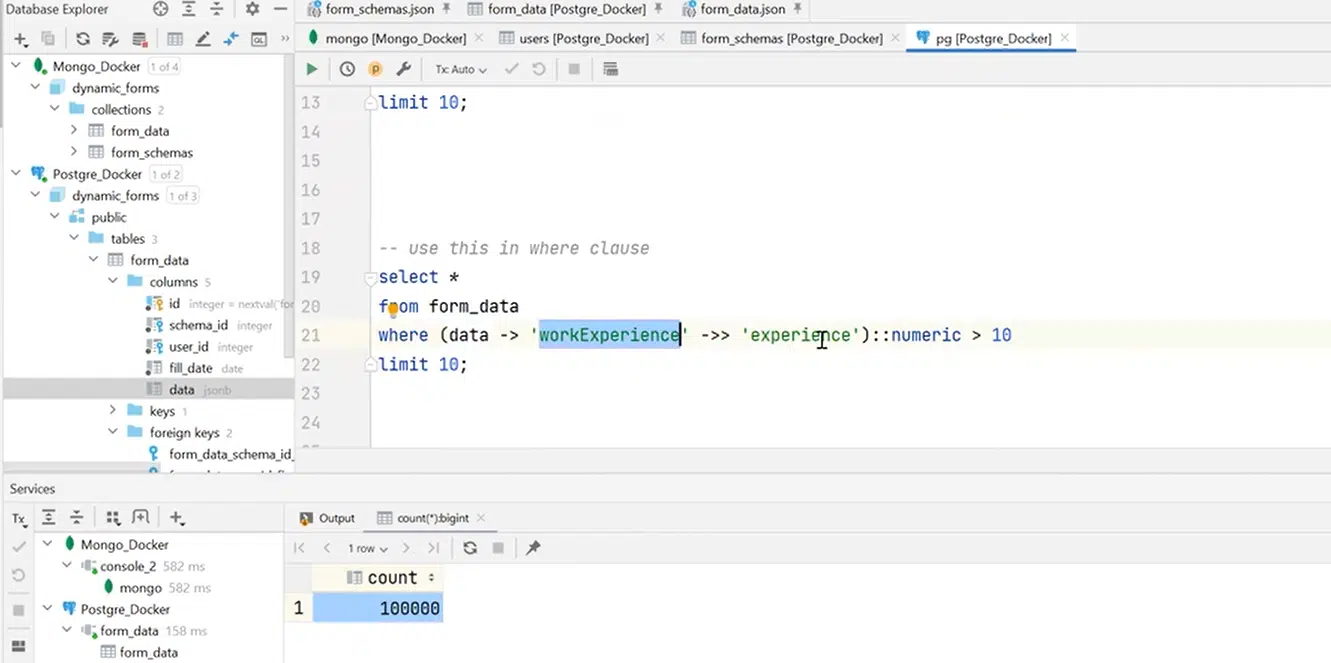
Натисніть, щоб роздивитися
Тепер хочу розповісти про доволі цікавий оператор, який може визначити contains в самих даних, у JSON. Наприклад, у мене є workExperience та databaseSkills, зі знаннями конкретних БД. Я можу написати запит, котрий покаже всіх юзерів, які знають PostgreSQL. Це дуже доречно при пошуку інформації по масиву.
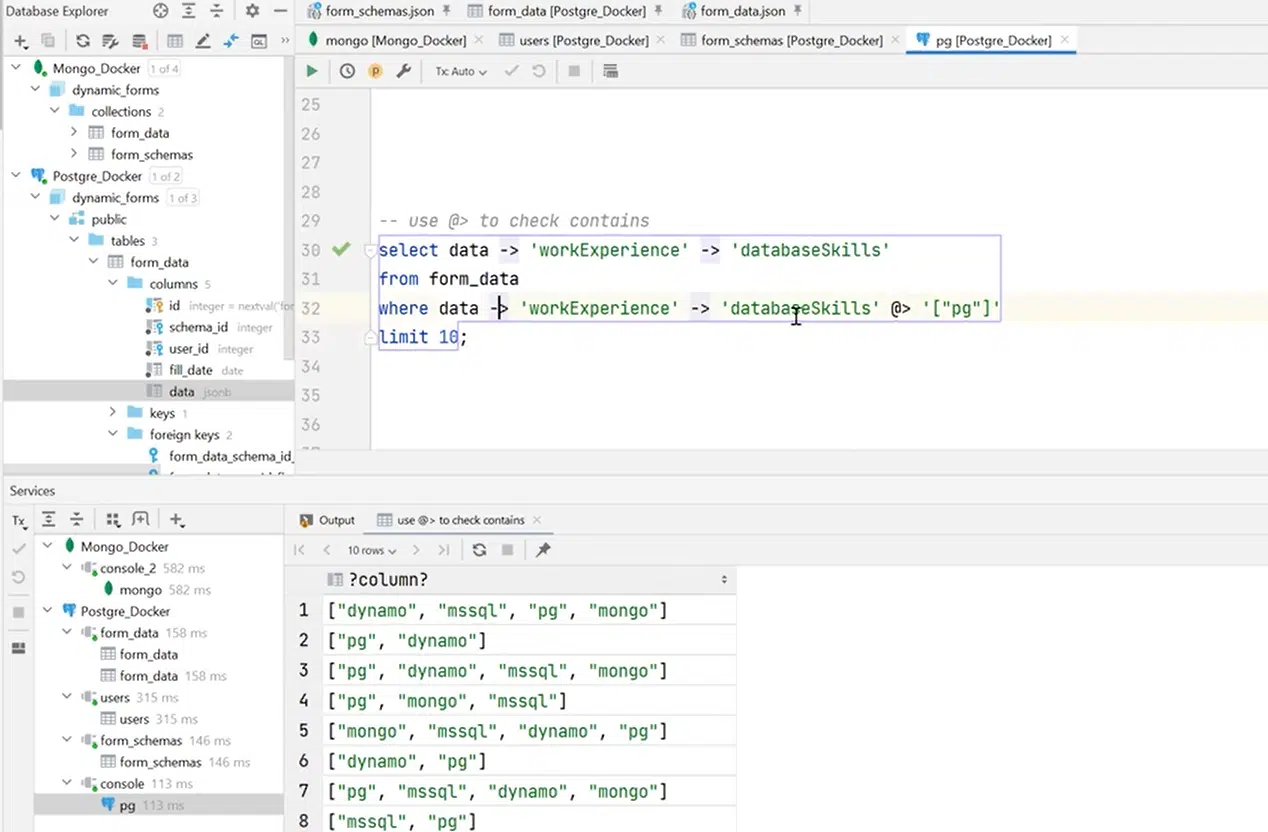
Натисніть, щоб роздивитися
А ще не можу не згадати JSONPath. Це мова запитів до JSON, подібна до аналогічного концепту XMLPath у XML. Тут є стрінга, де ми кажемо, що $ — це root. Далі робимо запит до полів у JSON.
Припустимо, треба вибрати firstName, lastName, databaseSkills у тих юзерів, у яких в databaseSkills більше двох скілів. Якщо ми не хочемо вибирати значення стрілочками, можна звернутися до синтаксису і ввести оператор @@, щоб використати where. А все тому, що jsonb_path_query — це і є наші функції:
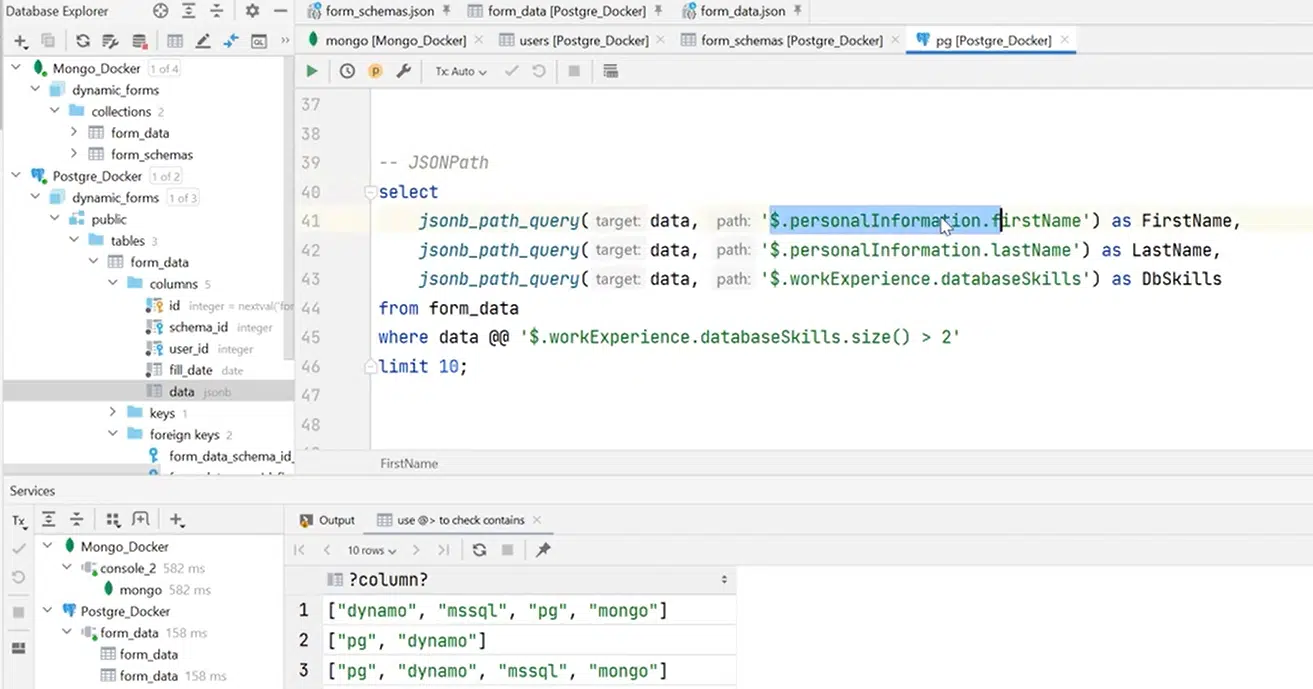
Натисніть, щоб роздивитися
Як бачите, всередині стрінги у мене є функція size. Вона вбудована в специфікацію JSONPath і може видати кількість елементів у масиві. Для цього додано оператор >, більше, ніж якесь число. У нашому випадку — це 2. В результаті саме завдяки цьому PostgreSQL опрацював цю стрінгу, зрозумів, що від нього хочуть, і витягнув потрібні дані.
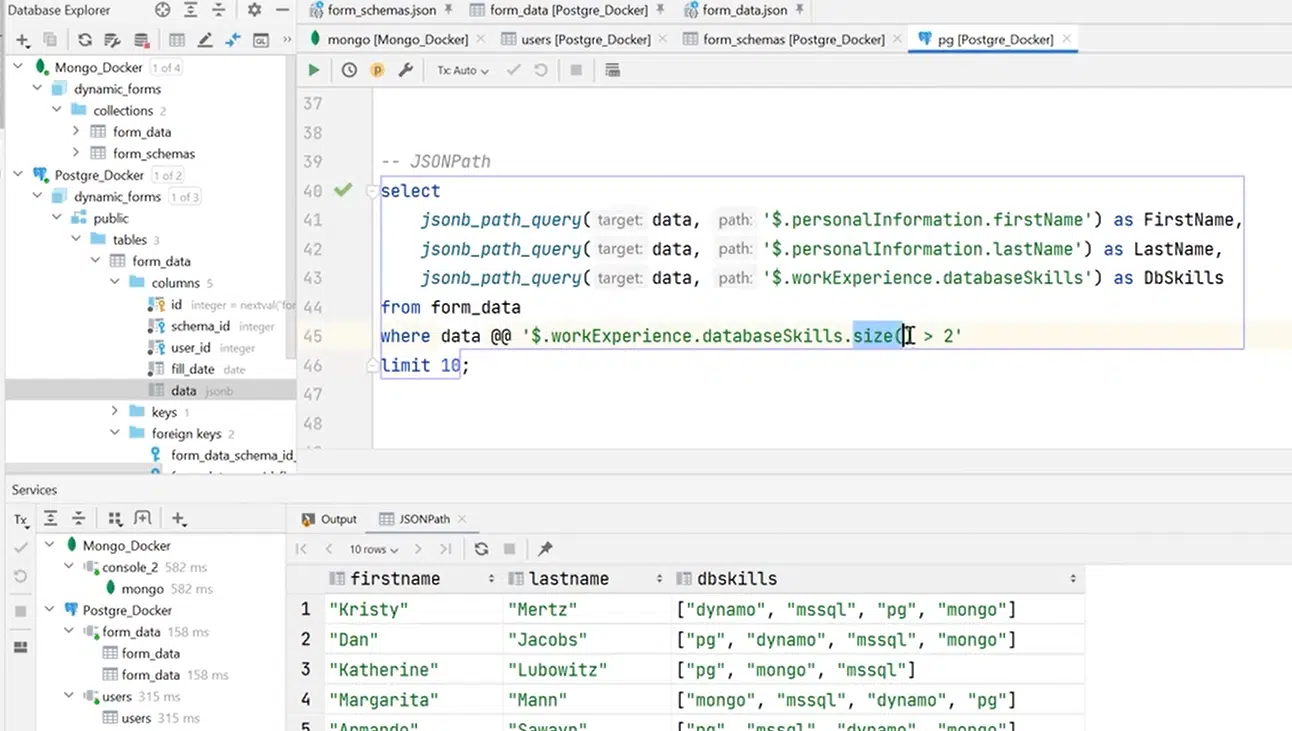
Натисніть, щоб роздивитися
І наостанок — індекси. Їх можна створювати на дані всередині JSON для того, щоб опрацювання запитів до такого файлу проходило швидше.
Наприклад, додаю індекс на workExperience і потім хочу знайти усіх юзерів, у яких цей параметр складає 10 років. Це досить просто, але наголошу: індекс створюється на стрінгу, а не на число. Інакше індекс взагалі не буде опрацьований. Це добре відображається на execution plan. На ілюстрації нижче можете бачити, що PostgreSQL для пошуку юзерів зробив Seq Scan. Це зайняло трохи більше 129 мілісекунд:
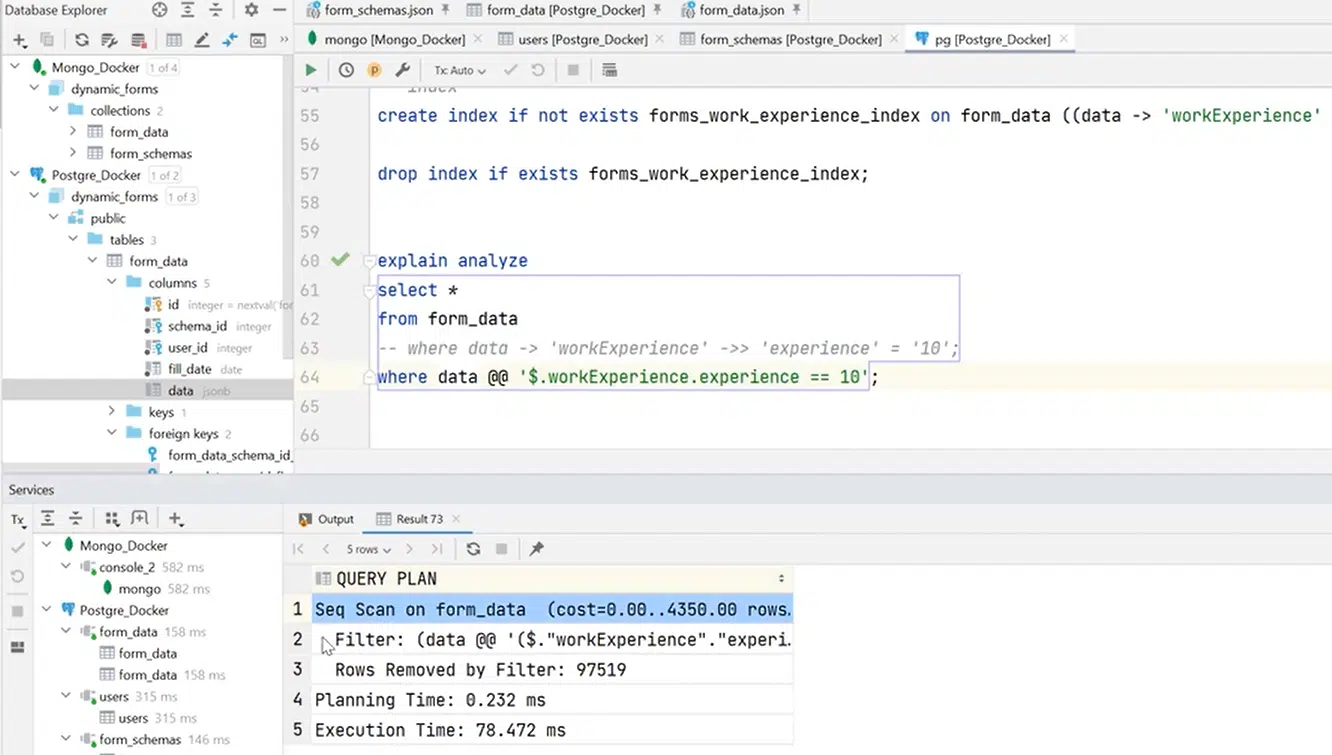
Натисніть, щоб роздивитися
Якщо додати індекс та виконати той же запит, то все пройде як Bitmap Heap Scan — і дані будуть отримані за 9 мілісекунд. Виграш у швидкості більше, ніж у 10 разів!
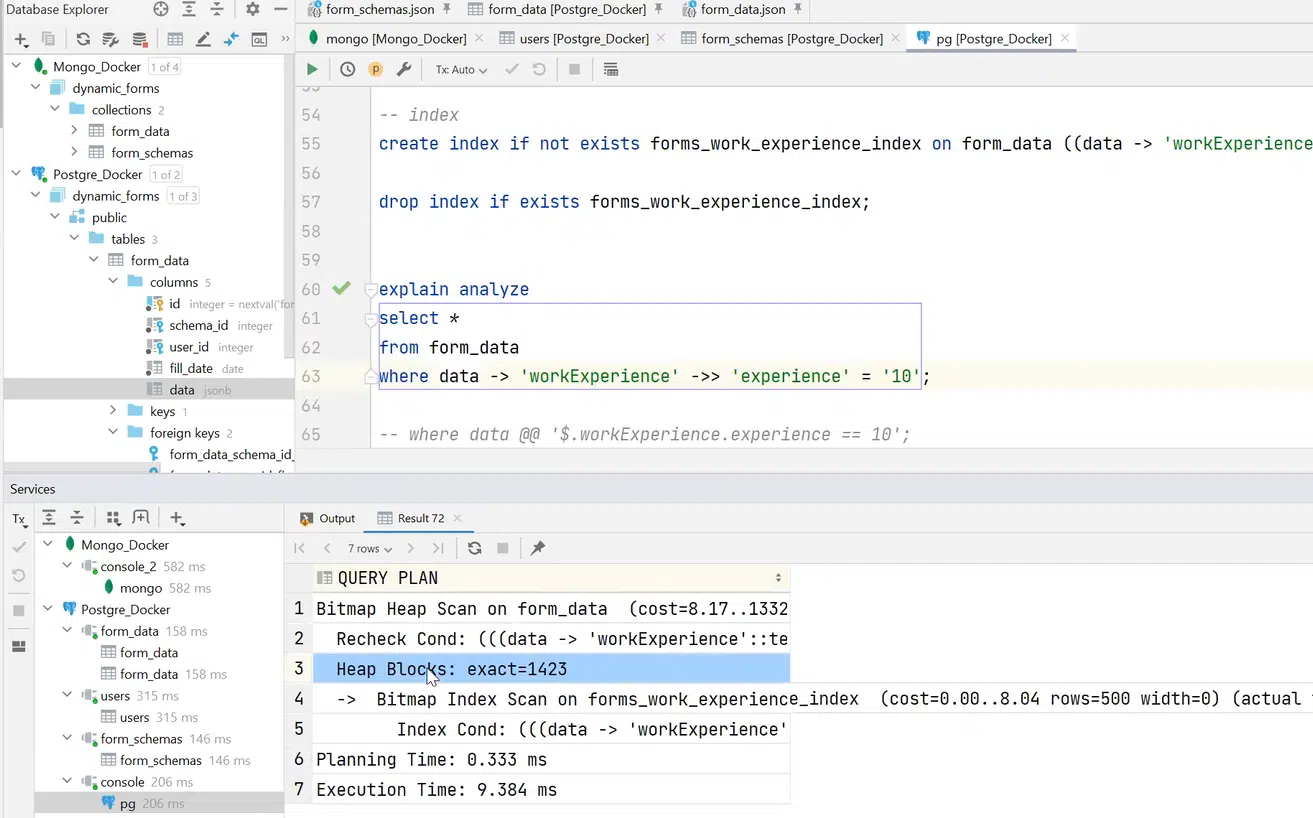
Натисніть, щоб роздивитися
На жаль, це не працює з гарним JSONPath-синтаксисом. Із ним запит буде надходити через Seq Scan за 78 мілісекунд. Тобто покращення є, але вже не таке значне.

Натисніть, щоб роздивитися
Щоб індекс запрацював на такому експрешені, потрібно створити інший тип — на все поле JSON. У PostgreSQL це gin-індекс. Вказані експрешени по факту працюють як Full-Text Search. При їх виконанні запускається Bitmap Heap Scan, а витрати часу складатимуть лише 21 мілісекунду:

Натисніть, щоб роздивитися
І хоча це все я показав на прикладі PostgreSQL, усі великі вендори баз даних так чи інакше підтримують цей підхід. Адже вони бачать попит з боку розробників на адаптацію JSON у деяких кейсах.
Наприклад, у коді нижче наведено синтаксис MsSQL. Тут також є функції OPENJSON та JSON_QUERY з використанням JSONPath. Схожі рішення присутні в MicrosoftSQL та в Oracle.
Переваги та недоліки JSON в реляційних БД
NoSQL-підхід для реляційних баз даних має корисні властивості, серед яких:
- Старий-добрий SQL. Ми можемо не відходити від принципів та методів, до яких звикли в роботі та які нам подобаються.
- «Сумісність» із реляційною моделлю. Можемо робити джойни та селекти, використовувати в Query where та внутрішні JSON-поля.
- Більше інструментів для моделювання даних. Новий підхід дає змогу взяти все найкраще від SQL та NoSQL.
Щодо недоліків використання JSON в описаний спосіб, маємо наступні:
- Зниження ефективності в деяких випадках. Для використання типу даних, подібного до jsonb, і додавання індексу потрібно більше ресурсів. NoSQL-БД, як MongoDB, буде більш продуктивною для такої задачі.
- Не додає масштабування. Головна перевага світу NoSQL не лягає в нову модель — ми залишаємося в реляційній парадигмі. Однак тепер здатні робити в ній трохи більше.
Висновки
Підбиваючи підсумки, скажу, що використання JSON в реляційній моделі буде виправданим у кількох випадках:
- Існуючі проєкти на SQL. Якщо у вашому застосунку з реляційною БД з’являється фіча,яка потребує динамічних даних, NoSQL-методи точно стануть у нагоді.
- Динамічні конструктори будь-чого з урахуванням масштабування. Коли ви не знаєте, якими об’єктами буде оперувати користувач та які зв’язки будуть між ними, спробуйте описанні принципи. Як правило, це ті ж самі форми, робочі флоу та інше з того, що юзер може створювати за допомогою вашого інструменту.
- Оптимізація, коли реляційна модель є проблемою. Інколи розробники можуть так загратися з нормалізацією даних у SQL, що кількість таблиць та зв’язків стане занадто великою. Це може призвести до зупинки деяких операцій із запису або читання. В такому випадку через безліч джойнів не врятують жодні індекси. Тому для денормалізації даних варто звернутися до NoSQL-підходу. Замість мільйонів зв’язків ви матимете форму JSON в одній колонці. При цьому, якщо у вас були фільтрації, вони залишаться завдяки новим функціям та синтаксисам БД.
Існує ще безліч прикладів завдань, які можна вирішувати за таким підходом:
- по-перше, це Metadata Forms — складні динамічні форми;
- по-друге, BPMN Workflows, де всі степи описані в JSON;
- і по-третє, це CMS.
Тут ви забезпечите користувачу застосунку можливість створення будь-якого динамічного контенту. В будь-якому разі завжди пам’ятайте: те, що добре спрацювало для когось, не факт, що підійде у вашому випадку. Уважно розглядайте різні кейси, експериментуйте, і все у вас вдасться.
Цей матеріал – не редакційний, це – особиста думка його автора. Редакція може не поділяти цю думку.













Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: