Веб-скрапинг с помощью библиотеки Playwright
Программист Кевин Сахин, проработавший в сфере парсинга более 10 лет, показал, как создать веб-скрапинг для извлечения данных на основе библиотеки Playwright с помощью Javascript.

javascript web scraping
Playwright — библиотека автоматизации браузера для Node.js, которая обеспечивает надежную, быструю и эффективную автоматизацию при помощи нескольких строк кода. По своим характеристикам она похожа на Selenium и Puppeteer. Простота и мощные возможности автоматизации сделали Playwright идеальным инструментом для парсинга веб-страниц и интеллектуального анализа данных. Библиотека также поддерживает headless-браузеры. Но самое главное — это кроссбраузерная поддержка, чего не может предложить Puppeteer.
В этой статье вы узнаете:
- Возможности Playwright;
- Популярные варианты использования Playwright для парсинга веб-страниц;
- Playwright и другие библиотеки (сравнительная х-ка с Puppeteer и Selenium);
- Плюсы и минусы Playwright.
Что такое headless-браузеры и почему они используются для парсинга веб-страниц?
Headless-браузер — это веб-браузер без графического пользовательского интерфейса. Он нуждается в меньших ресурсах и легко запускается на сервере. Более того, можно создавать множество экземпляров такого браузера одновременно, что очень удобно при парсинге данных сразу с нескольких веб-страниц.
Основная причина, по которой headless-браузеры используются для скрапинга веб-сайтов, заключается в том, что сейчас все больше веб-сайтов создаются с использованием фреймворков одностраничных приложений (SPA), таких как React.js, Vue.js, Angular и других. Если получить такой веб-сайт с помощью обычного HTTP-клиента, то получится пустая HTML-страница, так как она построена с помощью внешнего кода Javascript. Headless-браузеры решают эту проблему.
Начало работы с Playwright
Чтобы освоить работу с библиотекой, ознакомьтесь с руководством и попробуйте написать собственный веб-парсер, который будет собирать финансовые данные с помощью Playwright.
Для начала необходимо создать новый Node.js проект и установить библиотеку Playwright.
nmp init --yes npm i playwright
Создайте index.js файл и напишите первые строки кода.
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: false // setting this to true will not run the UI
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/world-indices');
await page.waitForTimeout(5000); // wait for 5 seconds
await browser.close();
}
main();
В приведенном выше примере можно увидеть новый chrome-экземпляр headless-браузера. Обратите внимание, что для headless установлено значение false (строка 4), поэтому при запуске кода появится всплывающий пользовательский интерфейс. Если для этого параметра установлено значение true, то Playwright будет работать в автономном режиме. Создайте новую страницу в браузере, после чего перейдите на Yahoo. Спустя 5 секунд браузер нужно закрыть.
Зайдите в Yahoo с вашего браузера. Проверьте домашнюю страницу на наличие Yahoo Finance. Допустим, вы создаете финансовое приложение и хотите получить данные фондового рынка. На домашней странице Yahoo можно увидеть, что в заголовке отображаются самые популярные сводные рыночные данные. На этом этапе можно проверить элемент заголовка и узел DOM в инспекторе браузера, показанном ниже.
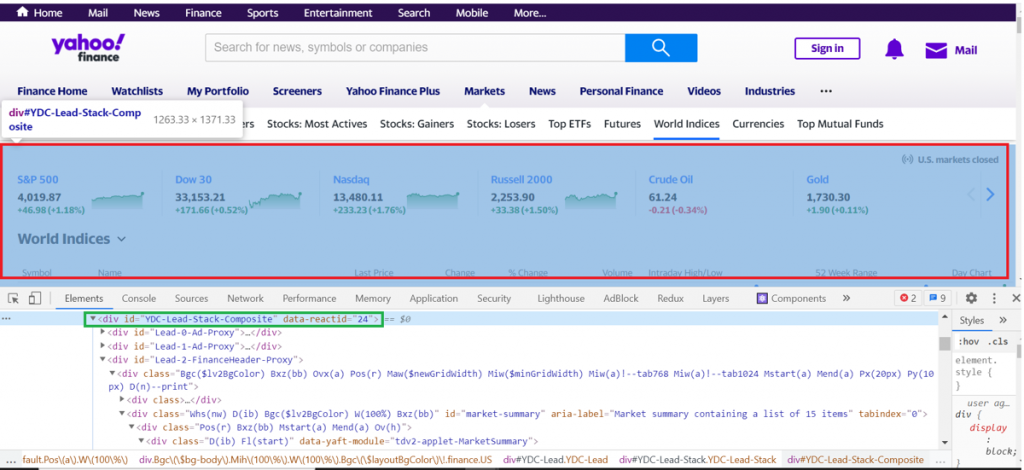
Yahoo
Обратите внимание, что заголовок имеет расширение id=YDC-Lead-Stack-Composite. Можно ориентироваться на этот идентификатор и извлечь из него информацию. Для этого в код следует добавить следующие строки.
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/world-indices');
const market = await page.$eval('#YDC-Lead-Stack-Composite', headerElm => {
const data = [];
const listElms = headerElm.getElementsByTagName('li');
listElms.forEach(elm => {
data.push(elm.innerText.split('\n'));
});
return data;
});
console.log('Market Composites--->>>>', market);
await page.waitForTimeout(5000); // wait
await browser.close();
}
main();
Еще один пример *$eval* блока кода.page.$eval функция требует двух параметров. Первый — идентификатор селектора. В этом сценарии передается идентификатор узла, который нужно захватить. Второй параметр — анонимная функция. В этой функции можно запустить любой клиентский код, который доступен для запуска в браузере.
const market = await page.$eval('#YDC-Lead-Stack-Composite', headerElm => {
const data = [];
const listElms = headerElm.getElementsByTagName('li');
listElms.forEach(elm => {
data.push(elm.innerText.split('\n'));
});
return data;
});
Узнать больше о функции $eval можно в официальной документации.Выделенная часть — это простой клиентский JS-код, который захватывает элементы li в узле заголовка. Здесь следует провести некоторые манипуляции с данными.
Этот код выводит в терминал следующее.

данные
Поздравляем! Вы успешно собрали первые данные.
Извлечение списка элементов с помощью Playwright
Следующий шаг — извлечение списка элементов из таблицы. Сейчас нужно получить наиболее востребованные акции https://finance.yahoo.com/most-active. Ниже представлен скриншот страницы и необходимая вам информация.
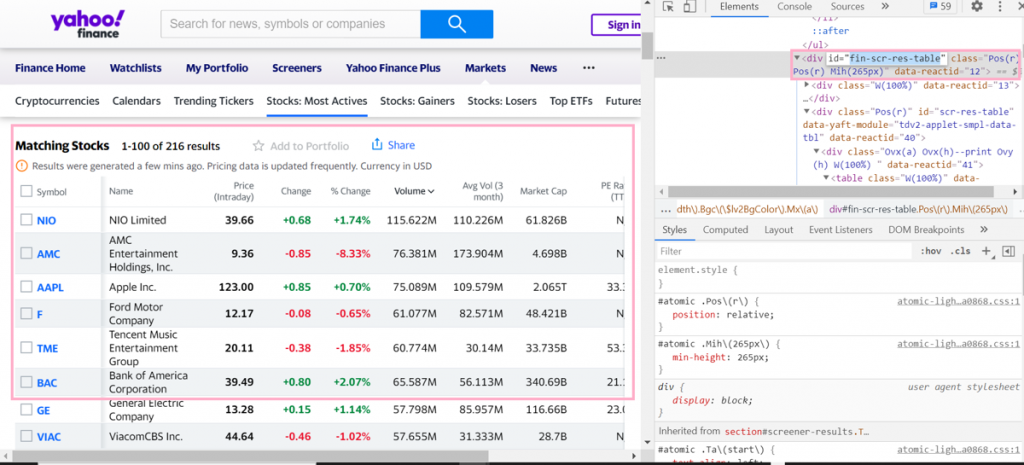
Yahoo
В этом случае интересен идентификатор в атрибуте fin-scr-res-table. Также можете развернуть поиск до элемента таблицы в узле DOM.
Ниже представлен пример, который поможет в данной ситуации.
const playwright = require('playwright');
async function mostActive() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/most-active?count=100');
const mostActive = await page.$eval('#fin-scr-res-table tbody', tableBody => {
let all = []
for (let i = 0, row; row = tableBody.rows[i]; i++) {
let stock = [];
for (let j = 0, col; col = row.cells[j]; j++) {
stock.push(row.cells[j].innerText)
}
all.push(stock)
}
return all;
});
console.log('Most Active', mostActive);
await page.waitForTimeout(30000); // wait
await browser.close();
}
mostActive();
page.$eval действует как свойство querySelector клиентского JavaScript (подробнее о querySelector).
Что делать, если нужно извлечь теги определенного типа (например a, li) на веб-странице?
В таких случаях следует использовать функцию page.$$(selector). Это поможет вернуть все элементы, которые соответствуют определенному селектору на странице.
async function allLists() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage();
await page.goto('https://finance.yahoo.com/');
const allList = await page.$$('li', selected => {
let data = []
selected.forEach((item) => {
data.push(item.innerText)
});
return data;
});
console.log('Most Active', allList);
}
allLists();
Извлечение изображений
Попробуйте извлечь картинку с веб-страницы. В этом примере будет использоваться домашняя страница scrapingbee.com. Взгляните на изображение ниже.
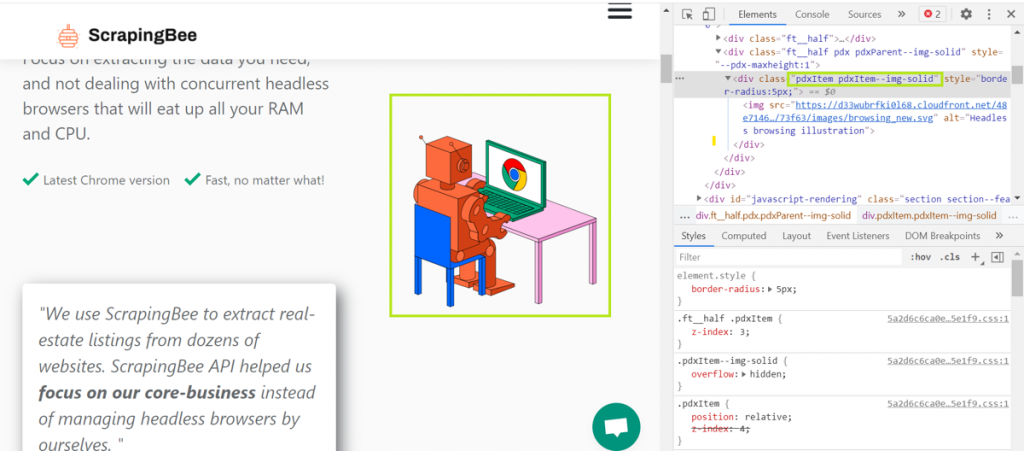
Извлечение изображений
Сначала сосредоточьтесь на узле DOM, который захватывают нужное вам изображение. Чтобы получить картинку, понадобится src. Сделайте HTTP GET запрос к источнику и загрузите картинку. Ниже представлен пример.
const playwright = require('playwright');
const axios = require("axios");
const fs = require("fs");
async function saveImages() {
const browser = await playwright.chromium.launch({
headless: true
});
const page = await browser.newPage();
await page.goto('https://www.scrapingbee.com/');
const url = await page.$eval(".pdxItem.pdxItem--img-solid img", img => img.src);
const response = await axios.get(url);
fs.writeFileSync("scrappy.svg", response.data);
await browser.close();
}
saveImages();
Как видите, сначала следует ориентироваться на интересующий узел DOM. Затем в строке 11 вы получите атрибут src из тега изображения. Далее сделайте запрос GET с помощью axios и сохраните изображение.
Что насчет скриншотов?
Также с помощью Playwright можно сделать скриншот страницы. Библиотека включает page.screenshot метод. Используя его, попробуйте сделать один или несколько снимков экрана веб-страницы.
async function takeScreenShots() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage()
await page.setViewportSize({ width: 1280, height: 800 }); // set screen shot dimention
await page.goto('https://finance.yahoo.com/')
await page.screenshot({ path: 'my_screenshot.png' })
await browser.close()
}
takeScreenShots()
Чтобы ограничить снимок определенной частью экрана, укажите координаты окна просмотра. Вот пример, как это сделать.
const options = {
path: 'clipped_screenshot.png',
fullPage: false,
clip: {
x: 5,
y: 60,
width: 240,
height: 40
}
}
async function takeScreenShots() {
const browser = await playwright.chromium.launch({
headless: true // set this to true
});
const page = await browser.newPage()
await page.setViewportSize({ width: 1280, height: 800 }); // set screen shot dimention
await page.goto('https://finance.yahoo.com/')
await page.screenshot(options)
await browser.close()
}
takeScreenShots()
Координаты x и y начинаются с верхнего левого угла экрана.
Запросы с помощью селекторов выражений XPath
Достаточно простая, но мощная функция Playwright — способность запрашивать элементы DOM с помощью выражений XPath. Выражение XPath — это определенный шаблон, который используется для выбора набора узлов в DOM.
К примеру, нужно получить все навигационные ссылки из блога StackOverflow. Обратите внимание, что необходимо извлечь элемент nav в DOM. Интересующий элемент навигации находится в дереве в следующей иерархии html > body > div > header > nav.
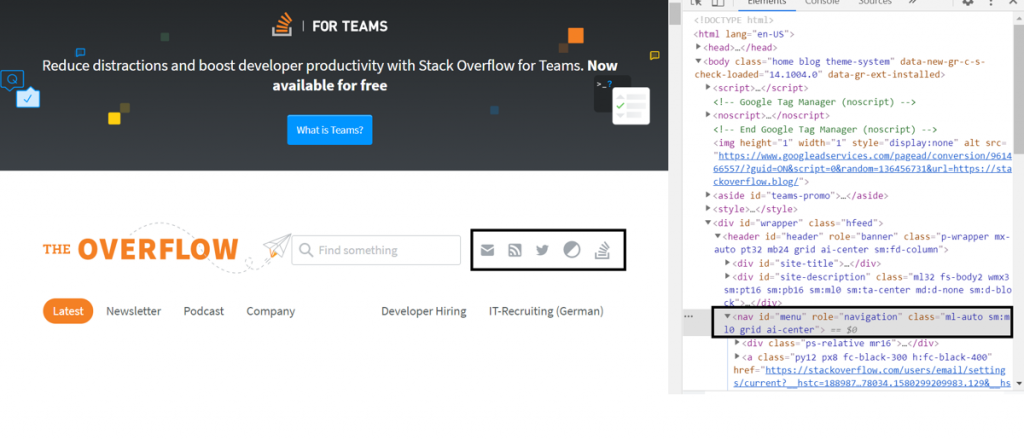
StackOverflow
Теперь можно создать xpath выражение. Оно должно выглядеть так: xpath=//html/body/div/header/nav.
Ниже приведен сценарий, который будет использовать xpath выражение для нацеливания на nav элемент в DOM.
const playwright = require('playwright');
async function main() {
const browser = await playwright.chromium.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://stackoverflow.blog/');
const xpathData = await page.$eval('xpath=//html/body/div/header/nav',
navElm => {
let refs = []
let atags = navElm.getElementsByTagName("a");
for (let item of atags) {
refs.push(item.href);
}
return refs;
});
console.log('StackOverflow Links', xpathData);
await page.waitForTimeout(5000); // wait
await browser.close();
}
main();
XPath в Playwrigh равносилен Document.evaluate(). Подробнее узнать об этом можете здесь.
Официальная документация Playwright о XPath.
Отправка форм и извлечение аутентифицированных маршрутов
Бывают случаи, когда нужно получить веб-страницу, защищенную аутентификацией. Одно из преимуществ Playwright состоит в том, что с его помощью очень просто отправлять формы. Далее представлен пример такого сценария.
// Example taken from playwright official docs
const playwright = require('playwright');
async function formExample() {
const browser = await playwright.chromium.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://github.com/login');
// Interact with login form
await page.fill('input[name="login"]', "MyUsername");
await page.fill('input[name="password"]', "Secrectpass");
await page.click('input[type="submit"]');
}
formExample();
// Verify app is logged in
Здесь можно с легкостью моделировать clicks и формировать fill события. Ниже видно результат выполненного сценария.

Ознакомьтесь с официальной документацией, чтобы узнать больше об аутентификации Playwright.
Playwright VS Puppeteer, Selenium
Чем отличается Playwright от других популярных решений, таких как Puppeteer и Selenium? Главное преимущество Playwright — простота в использовании. Эта библиотека очень удобна для разработчиков, если сравнивать с Selenium, при этом она не имеет значительного преимущества в сравнении с Puppeteer. Давайте посмотрим на тенденции и популярность пакетов NPM для всех трех библиотек.
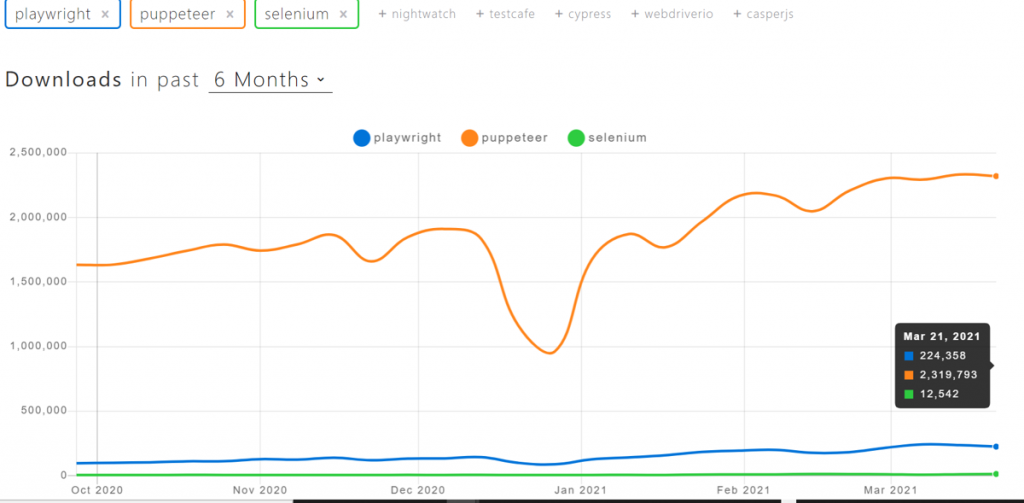
Playwright явно является самым популярным выбором. Однако, согласно активности этих библиотек на GitHub, можно заметить, что и Playwright, и Puppeteer достаточно востребованы среди программистов. Источник.
Что насчет документации?
Playwright и Puppeteer представлены отличной документацией. У Selenium также неплохая, но можно было сделать и лучше.
Сравнение производительности
При запуске одного и того же скрипта наблюдается более длительное время выполнения в Selenium по сравнению с Playwright и Puppeteer. При этом если проводить различные тесты производительности, то в некоторых случаях Playwright работает лучше, чем Puppeteer. Подробный анализ выходит за рамки статьи. Детальнее узнать о производительности этих инструментов можно здесь.
Вот краткое сравнение этих библиотек.
| Категория | Playwright | Puppeteer | Selenium Web Driver |
| Время выполнения | Быстро и надежно | Быстро и надежно | Медленное время запуска |
| Документация | Отличная | Отличная | В целом хорошая, но есть исключения |
| Отзывы программистов | Очень хороший | Очень хороший | Достаточно хороший |
| Сообщество | Небольшое, но активное | Имеет большое сообщество с большим количеством активных проектов | Имеет большое и активное сообщество |
Заключение
Playwright — мощный автономный инструмент с отличной документацией и растущим сообществом. Библиотека идеально подходит для парсинга веб-страниц, если у вас уже есть опыт работы с Node.js.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: