Что такое XPath? Функции и синтаксис

В этом небольшом вводном руководстве разберемся с XPath, а также с его наиболее распространенными типами, операторами, узлами и функциями.

Источник: habr.com
1. Что такое XPath? Отличия от XML
XPath или XML Path Language — язык запросов, используемый для навигации по XML-документу. XML — язык разметки, чем-то похожий на HTML, не выполняющий никаких действий, а просто служащий для описания и структурированного хранения каких-нибудь данных. Проще говоря — это куски информации, завернутые в теги, для получения которой разработчик пишет специальную программу. Чтобы такая программа нашла необходимые элементы, нужно проложить к ним путь. Этот путь называют XPath-выражение.
XPath применяется для перехода к любому необходимому нам тегу, атрибуту или текстовому блоку и используется в связке с такими технологиями, как XSLT, XQuery, XLink и XPointer. XPath можно использовать в индустрии разработки ПО — почти все языки программирования поддерживают его, — а также при тестировании программного обеспечения, в частности для разработки сценариев автоматизации в Selenium. Кроме всего прочего, он является рекомендуемым языком консорциума World Wide Web (W3C), поэтому с ним стоит разобраться. Сделать это лучше всего с практикующими специалистами, например, с преподавателями из школы наших партнеров Mate Academy.
2. Узлы XPath
Под узлами понимают вложенные теги, атрибуты и тексты, составляющие содержимое корневого элемента. От каждого вложенного тега могут отходить свои ветви. Элементы в дереве узлов имеют иерархические взаимоотношения друг с другом. Пример таких взаимоотношений показан на изображении ниже.
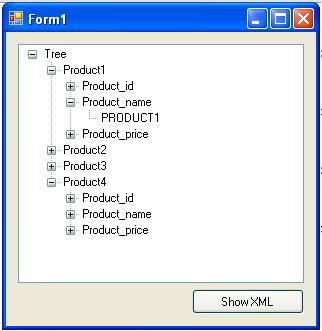
Существуют разные типы узлов XPath. Но прежде, чем их перечислить, напишем базовую программу XML, чтобы на ее примере объяснить все используемые здесь термины.
<SoftwareTestersList>
<softwareTester name="T1">
<State>Kiew</State>
<country>UA</country>
</softwareTester>
<softwareTester name="T2">
<State>Odessa</State>
<country>UA</country>
</softwareTester>
</SoftwareTestersList>
- Корневой узел. Самый верхний узел документа, содержащий все дочерние элементы внутри себя и не имеющий родителя. В приведенном примере корневым узлом является «
SoftwareTestersList». Для его выбора используется косая черта ‘/‘. - Узлы элементов. Находятся непосредственно под корневым узлом и могут содержать в себе атрибуты. В основном это теги XML или HTML. В примере им соответствуют:
Software Tester,State,Country. - Узлы атрибутов. Определяют свойство (атрибут) элемента и могут находиться не только под узлом элемента, но и под корневым узлом. В нашем примере: «
name» — это атрибутный узел тегов softwareTester. Для обозначения применяется значок «@». - Текстовые узлы. К ним относятся все тексты, появляющиеся между узлами элементов, в примере это — «
Kiew», «UA», «Odessa». - Узлы комментариев. Комментарии к коду, не обрабатываемые компилятором или интерпретатором языка программирования, помещенные в конструкцию
<!... >. - Атомарные значения (Atomic values): Это узлы, не имеющие дочерних и родительских элементов.
- Узел контекста: это конкретный текущий узел из XML-документа, обозначаемый точкой (
.).
3. Оси (axis) в XPath
Оси определяют отношение узлового набора по отношению к текущему узлу. Рассмотрим самые основные из них и поймем, как они могут работать, в нашем примере:
- Self-axis. Для выбора конкретного узла контекста применяется выражение
XPath self :: *или. - Child-axis. Чтобы выбрать дочерние элементы контекстного узла, необходимо написать
child :: software tester. - Parent-axis. При выборе родительского контекстного узла ось обозначается двойной точкой (
..). Например:parent :: Stateи../State. - Attribute-axis. Ось атрибутов обозначается символом (
@). Например:attribute :: name или @name.
4. Пути к элементам XPath
Мы с вами разобрали, что XPath ищет элементы на HTML или XML-страницах.
Для того чтобы добраться к искомому объекту, используются пути. Они являются наиболее полезным и широко используемым свойством XPath. Путь состоит из набора узлов XPath относительно его стартового (чаще всего корневого) элемента.
Есть два вида путей: абсолютный и относительный.
Абсолютным называется путь от корня документа. Он всегда начинается с косой черты “/”.
Корень документа всегда является узлом по умолчанию, то есть текущим полученным узлом или набором узлов, относительно которых рассчитывается следующий шаг.
Например:
<html>
<head>
<body>
<div class=”mainWrap”>
<h1> Основной заголовок</h1>
<p>абзац текста</p>
<div>Блок1</div>
<ul>
<li>пункт1</li>
<li>пункт2</li>
</ul>
</div>
<div class=”sideBar”>
<div>
<div>пустой блок</div>
<div>
<div>
<table border=”1”>
</body>
</html>
Из примера выше мы видим, что для того, чтобы добраться до тега (<li>пункт 1</li>), нам нужно, начиная с корня документа (<html>), посетить каждый дочерний элемент родителя.

В XPath это будет выглядеть так:
/html/body/div/ul/li[1]
Пример из жизни: есть семиэтажное здание. Чтобы попасть на седьмой этаж по лестнице, нам нужно последовательно посетить все этажи с первого по седьмой — /1/2/3/4/5/6/7. Это будет абсолютный путь.
Относительным называют путь от одного элемента (не обязательно от корневого) к другому. Чаще всего в таких случаях XPath-запрос начинают с «.//» или «//».
Символы «//», проставленные в начале запроса, возвращают полное множество потомков, являющихся дочерними для корня документа, то есть все элементы на текущей странице.
Например:

Чтобы добраться до тега (<li>пункт 1</li>), мы опустим все теги, находящиеся выше тега (<div>), и заменим их на «//». Также можем заменить всех предков тега (<li>) на «//», исключая тег (<div>).
Вот как это будет выглядеть в XPath:
//div//li[1]
Пример из жизни: есть семиэтажное здание. Нам нужно попасть с третьего на седьмой этаж, не посещая этажи четыре, пять, шесть (где живут наши недоброжелатели). Для этого можно воспользоваться лифтом и пропустить их. Наш путь будет выглядеть следующим образом: //3//7. А если нам придется подниматься по лестнице, то наш путь будет выглядеть так:
//3/4/5/6/7
5. Синтаксис XPath
Синтаксис языка запросов немного похож на обозначения, используемые в URL-адресах. XPath выражение — это не что иное, как путь к нужному нам элементу в дереве документа, где каждый уровень отделяется от другого косой чертой «/», а результатом его обработки может быть:
- node-set или комплект узлов. Например:
/html/body/div
Если применить к предыдущему участку HTML-кода, он вернет два узла элементов div, содержащиеся в элементе body.
- boolean или логическое выражение:
/html/body/div or p
вернет значение true, так как в элементе body содержится элемент div.
- number или число. Числа здесь дробные с плавающей запятой. Целочисленный тип данных не учитывается в XPath.
- string или строка:
/html/body/div/h1['Основной заголовок']
Вернет элемент h1 с текстом «Основной заголовок», содержащийся в первом элементе div.
Ниже перечислены подстановочные знаки, применяемые в XPath-выражениях.
(*): выберет все узлы элементов контекстного узла (включая текст, комментарии, инструкции и узел атрибутов).(@ *): выберет все узлы атрибутов контекстного узла.Node (): это выберет все узлы контекстного узла (включая пространства имен, текст, атрибуты, элементы, комментарии и инструкции).
Предикаты в XPath
Предикаты используются как фильтры, ограничивающие узлы, которые выбраны выражением XPath. Каждый предикат преобразуется в логическое значение, истинное или ложное, если оно истинно для данного XPath, то этот узел будет выбран, если ложно, то — нет.
Предикаты всегда заключаются в квадратные скобки, например:
softwareTester [@ name = ”T2 ″]:
Этот пример выберет элемент <softwareTester> с атрибутом, равным T2.
6. Функции XPath
XPath содержит стандартную библиотеку встроенных функций, необходимых для обработки узлов и работы с данными.
Их довольно много, поэтому перечислим некоторые из них:
1. Функции даты и времени:
current-date(). Возвращает текущую дату.current-dateTime(). Возвращает текущую дату и время.hours-from-time(time). Извлекает компонент часов из значения времени.dateTime(date, time). Объединяет указанную дату и время.days-from-duration(dayTimeDuration). Извлекает дневной компонент значения продолжительности дня.timezone-from-dateTime(dateTime). Извлекает компонент часового пояса значения даты и времени.
2. Функции имен:
base-uri(). Возвращает значение базового URI контекстного узла.local-name(). Возвращает локальную часть имени контекстного узла.name(node). Возвращает имя узла в виде строки в лексической формеQName.
3. Функции набора узлов:
avg(anyAtomicType_sequence). Возвращает среднее значение набора чисел или их продолжительности.count(item_sequence). Подсчитывает количество элементов в последовательности.error(). Вызывает ошибку.id(string_sequence). Находит элементы с заданными значениями атрибутаID.
4. Числовые функции:
number(object). Возвращает число на основе переданного ему объекта.floor(aNumber). Возвращает число, равное аргументу, округленное в меньшую сторону до ближайшего целого числа.abs(numeric). Возвращает абсолютное значение заданного числа. Возвращает тот же тип, что и предоставленный аргумент.ceiling(aNumber). Возвращает число, равное аргументу, округленное до ближайшего целого числа.
5. Строковые функции:
string(object). Преобразует объект в строку.compare(comparand1, comparand2). Сравнивает две строки с использованием параметров сортировки по умолчанию.lower-case(string). Изменяет символы в строке на нижний регистр.string(item). Возвращает строковое значение аргумента.
Описания всех существующих ныне функций можно найти в спецификации W3 XPath.
7. Примеры использования XPath из практики парсинга информации с сайтов
Ниже приведем наиболее часто встречающиеся участки кода XPath, применяемые разработчиками для парсинга данных с веб-страниц:
- Для получения текста заголовка h1:
//h1/text()
- Для получения текста заголовка с классом
productName:
//h1[@class="productName"]/text()
- Для получения значения тега
spanпо классу:
//span[@class="price"]
- Получаем значение атрибута
titleу тегаbuttonс классомaddtocart_button:
//input[@class="addtocart_button"]/@title
- Если нужен текст ссылки:
//a/text()
- Получаем
url-значение атрибутаhrefнеобходимой ссылки:
//a/@href
- Для получения атрибута
srcрассматриваемого изображения:
//img/@src
- Для получения изображения сразу за определенным элементом в DOM, ось
following:
//h1[@class="produnctName"]//following::div/img/@src
- Для получения изображения в четвертом
divпо счету:
//div[4]/img/@src
XPath довольно полезная вещь, широко применяемая при автоматизации тестирования. Он действует как локатор элементов. Чтобы найти определенный кусок данных на странице и выполнить над ним какое-либо действие, необходимо просто указать его XPath в целевом столбце сценария инструмента тестирования Selenium.
Для закрепления материала приводим несколько полезных ссылок на релевантные видеоролики по теме:
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: