«Я жалею, что писал на нем»: разработчик объяснил, почему PHP — не конкурент Java и C#

«Я сожалею, что писал на PHP», — написал разработчик Джордж Кастро из Чили. Совсем недавно он закончил большой серьезный проект (который был около трех лет в разработке), и этот проект даже работает так, как было задумано. Тем не менее, совсем не кажется надежным.
Джордж уверен, что теряет слишком много времени на другие задачи, а не на собственный кодинг (включая тестирование/бенчмаркинг, создание собственных библиотек).
Передаем ему слово.
Один из ключевых моментов проекта — доступ к базе данных, потому я использую технологию программирования ORM. Для этого в PHP вы можете использовать любой ORM, но такой проект непрост и требует некоторых хитростей.

Сначала я попробовал фреймворк Laravel. Поскольку я хотел использовать ORM, производительности Laravel оказалась недостаточно. Все работало слишком медленно, поэтому я полностью отказался от него. Я протестировал другие ORM, они тоже были медленными.
Тогда было принято решение создать ORM с нуля и достичь двух основных целей:
- простоты;
- быстродействия.
А это тот самый проект, который получился в итоге. И он работает!
Зачем мне ORM?
Невозможно создать проект, используя примитивные функции PHP (в данном случае PDO), например:
1) с использованием PDO (есть склонность к ошибкам):
$stmt = $pdo->prepare("SELECT * FROM myTable WHERE name = ?");
$stmt->bindParam(1,$_POST['name'],PDO::PARAM_STR);
$stmt->execute();
$result = $stmt->get_result();
$products=[];
while($row = $result->fetch_assoc()) {
$product[]=$row;
}
$stmt->close();
2) с использованием моей библиотеки:
$products=$pdoOne
->select("*")
->from("myTable")
->where("name = ?",[$_POST['name']])
->toList();
3) с использованием моей библиотеки (ORM):
ProductRepo // this class was generated with echo $pdoOne()->generateCodeClass(['Product']);
::where("name = ?",[$_POST['name']])
::toList();
Основная проблема, которую я обнаружил в PHP — это динамическая типизация.
Динамическая типизация
Предположим, у нас есть функция, которая возвращает список товаров:
$products=ProductRepo::listall();
Но PHP не знает, возвращаем ли мы список товаров. Мы могли бы добавить type hinting, но это всего лишь проверка типа и ничего более. Type hinting — дешевое решение и оно ненадежно.
function listall():array {
// code goes here
}
Но есть еще одна проблема. В PHP нет концепции array-of-a-specific-type.
Это Java:
products=new ArrayList<Product>();
Это С#:
products=new List<Product>();
А это PHP:
$products=array(); // или просто [], мы могли бы хранить здесь объект, число или любое другое значение.
Массивы VS объекты
Допустим, у нас есть модель инвойса:
class InvoiceDetails {
public $idInvoiceDetail;
public $idInvoice;
public $product;
public $quantity;
}
class Invoice {
public $idInvoice;
public $customer;
public $date;
public $invoiceDetails; // список деталей инвойса
}
Если мы хотим произвести сериализацию:
class InvoiceDetails {
public $idInvoiceDetail;
public $idInvoice;
public $product;
public $quantity;
}
class Invoice {
public $idInvoice;
public $customer;
public $date;
public $invoiceDetails; // список деталей инвойса
}
Мы могли бы преобразовать это вручную, но для правильной сериализации нужно очень много ресурсов.
Лучше решение — использование ассоциативного массива. Почему?
$invoice=['idinvoice'=>1...]; // $invoice это массив $json=json_encode($invoice); // $json это сериализованный массив $invoiceback=json_decode($json,true); // сейчас $invoice это массив.
В PHP нам вообще не нужно использовать модели. Мы могли бы использовать некоторые из них для type hinting, но это неидеальное решение, оно ненадежно и не поможет в большом проекте. Это также значительно снизит производительность (в основном при сериализации/десериализации).
Библиотеки — это решение?
Есть несколько библиотек, которые помогут решить эти проблемы. Но с их использованием возникает новая проблема: производительность.
Многие PHP-библиотеки используют множество «хакерских» решений для решения проблем, связанных с сериализацией, например, использование рефлексий. Они как минное поле, а некоторые вообще не заботятся о производительности.
Так почему же я сожалею об использовании PHP?
Допустим, наша первоначальная задача — функция, которая возвращает список товаров.
Это PHP:
$products=ProductRepo::listAll();
// show the first product if any
if($products!==null && count($products)>0) {
echo $products[0]->name; // or $products[0]['name'] if array
}
Нет гарантии, что этот код будет работать, потому что язык PHP на самом деле не знает, что $products содержит список товаров.
Это С#:
List<Product> products=ProductoRepo.listAll();
if(products!=null && products.Count()>0) {
console.log(products[0].name)
}
Код всегда будет работать, потому что С# знает, что переменная products представляет собой список товаров (или null), и другой альтернативы нет.
Это реализация функции в С#:
function listAll() {
var result=new List<Product>();
using(var dbase=new BaseExample()) {
result=dbase.Products.toList();
}
return result;
Здесь используется фреймворк Entity, он считывает из базы данные, конвертирует значение и возвращает список товаров. Падение производительности минимальное (я тестировал). Почему?
Во-первых, системе не нужно гадать (либо все работает, либо выдает ошибку), не нужно жонглировать типами. Во-вторых, C# — компилируемый язык. И в этом его преимущество. Это просто и это работает!
Это сериализация/десериализация:
string json = JsonSerializer.Serialize(products); var productsdes = JsonSerializer.Deserialize<List<Product>>(json);
И снова все просто: это или работает или выдает ошибку (золотой середины нет).
В качестве комментариев
О Swoole
Я протестировал Swoole, он работает, но возникают две проблемы.
Не работает в Windows
Нельзя сказать ничего плохого о Windows — это основа для многих корпораций и крупных компаний. Имею в виду, например, офисный пакет и другие программы вроде VPN, которые работают только в Windows. Я разрабатываю проекты в Windows, потому что на этой системе работают почти все программы (есть три исключения, одно из них — Swoole).
P.S. Вторая программа, которая не работает в Windows — Docker. Существует версия Docker для Windows, но это «крошечный» эмулятор. Это не легкий контейнер, а громоздкий (он в принципе ломает весь смысл существования контейнера).
Никакого волшебства в Swoole нет
Это не новый мощный движок PHP. Поэтому, если PHP медленный, то Swoole тоже. Swoole отлично работает в одних случаях, но плохо в других. Кроме того, я не хочу усложнять код.
И в этом случае C# изначально решает асинхронные задачи. Поэтому нам не нужно запускать отдельную службу, чтобы выполнить все медленные задачи одновременно в отдельном потоке (и без создания сокетов). Microsoft предупреждает о том, когда мы можем использовать его, а когда нет. Многозадачность — это не волшебная палочка на все случаи жизни.
Почему я использую PHP 5.x?
А вот и нет. Я использую PHP 8.0.10. Тем не менее, я могу поддерживать синтаксическую совместимость своего кода с PHP 5.6 (по крайней мере, библиотеки с открытым исходным кодом). В PHP 7 и 8 есть несколько новых синтаксисов, но большинство из них — синтаксический сахар![]()
![]() Синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным, поэтому не стоит переносить эти общедоступные библиотеки с версии 5.6 на 7 или 8. Почему?
Синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным, поэтому не стоит переносить эти общедоступные библиотеки с версии 5.6 на 7 или 8. Почему?
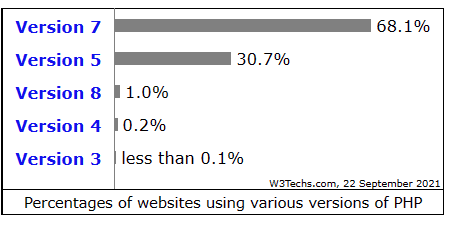
Здесь есть несколько полезных функций, но не более того. Мне нравится OPcache PHP > 7.0.
Type hinting
Одна из новых возможностей PHP 7 — type hinting. И это еще одна сложность.
В PHP type hinting одновременно и type validation. Валидация проверяется не один раз, а каждый раз, когда вызывается функция:
// what you write
function example(Class $field1): string {
}
// what php really does:
function example($field1) {
if(!get_type($gettype)!='Class') {
throw new Exception("field incorrect");
}
// ...
}
К счастью, type hinting нужно всего 0,0001 секунды на 5000 запросов. Но медлительность накапливается (например, 1000 пользователей одновременно используют 5000 строк, каждая строка вызывает 1 функцию). Это влияет на производительность. В большей части кода это не имеет большого значения, но некоторые функции вызываются не один раз, а тысячу по запросу пользователя.
Например, если у нас есть функция, на выполнение которой нужно 0,001 секунды и она вызывается 100 раз, то в сумме функции необходимо 0,1 секунды. Это не так уж плохо, но это мера для каждого запроса, поэтому, если у нас есть 100 запросов одновременно, получается уже 10 секунд.
Если разделить на 4 ядра, то каждое будет работать по 2 секунды. А это уже не совсем хорошо.
Я активно использую PHPDoc![]()
![]() Адаптированный стандарт документирования Javadoc для использования в PHP, так как он не влияет на производительность и еще более эффективен, чем
Адаптированный стандарт документирования Javadoc для использования в PHP, так как он не влияет на производительность и еще более эффективен, чем type hinting. Он неидеален, но дает некий баланс между производительностью и хинтингом.
Python в этом аспекте более прямолинеен. В Python type hinting — это всего лишь hint, а не валидация, поэтому валидация кода зависит от самого кода.
В C# валидация выполняется при компиляции и только один раз. Что касается PHP — это происходит при каждом вызове.
Psalm и PHPStan
Обе эти библиотеки хорошие, но они не бесплатны (добавляют новый «этап компиляции»). И они не творят чудес. С их помощью нет возможности обнаружить абсолютно все при нетипичных проблемах.
Потому я не беру в расчет Psalm и PHPStan. PHPStorm выполняет многие задачи обеих библиотек, не замедляя процесс разработки.
Обе библиотеки даже не в состоянии определить правильный тип поля переменной (если переменная достаточно сложная).
В C# есть несколько библиотек, выполняющих ту же работу. Тем не менее, Visual Studio (не код) также превосходно обнаруживает проблемы сразу после запуска и позволяет рефакторить.
Как итог
PHP — не плохой язык. Если посмотреть на Python и Django (или Ruby и Rails), PHP намного лучше. Но он все еще не конкурент Java и C#.
Язык PHP играет в игру с динамической типизацией, пытается имитировать статический типизированный язык. Возможно, PHP нужно разветвить и создать новый язык статического типа.
PHP и синдром самозванца
Что я увидел:
class Customer {
private $id;
private $name;
public function setId(int $id) {
$this->id=$id;
}
public function getId():int {
return $this-$id;
}
}
Производительность этого фрагмента кода ужасна. С таким кодом Java может работать, потому что оптимизирует сеттер и геттер. У PHP нет такой функции.
Что насчет Laravel:
class Customer extends Models {
}
// O_O
Нам нужно угадать пользовательские поля. Мы можем добавить hinting и значения по умолчанию, но не более того. Кроме того, эта модель полагается на рефлексию (__set method). Laravel основан на этом коде, а модель — это ядро для каждой функциональности кода, это и есть причина его медленной работы.
Да и Symphony не лучше. Например, использование YAML (у него есть некоторые альтернативы):
Article: actAs: [Timestampable] tableName: blog_article columns: id: type: integer primary: true autoincrement: true title: string(255) content: clob
И WordPress ничем не лучше:
$customers=['id'=1,'name'=>'john'];
Тем не менее, он дает лучшую производительность и является более простым.
Но почему С?
Конечно, здесь не показана вся картина. Например, серверы, на которых не разглашается используемая технология.
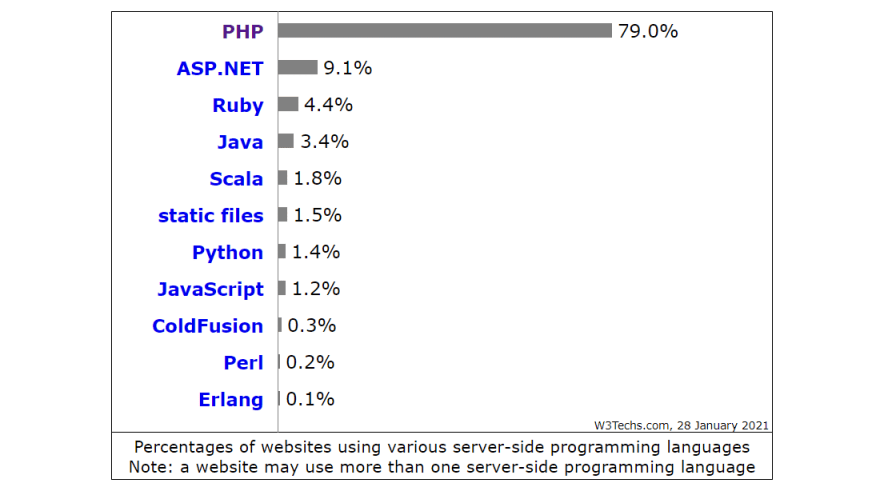
Также, если взглянуть на рабочие места в США:
- Python — 176k вакансий;
- Java — 142k вакансий;
- Javascript — 119k вакансий;
- C# — 83k вакансий;
- PHP — 15k вакансий.
Но это просто еще одна неполная мера.
Например, Python более популярен, чем Java, но Java-разработчик дольше задерживается на рабочем месте (проекты больше и высоко оплачиваются).
На заметку
Многие разработчики имеют неправильное представление о производительности и юзабилити. Пример: «Мой код медленный, но если я добавлю какой-нибудь фреймворк или библиотеку, он автоматически будет работать лучше».
Некоторые библиотеки, а особенно — фреймворки, не подходят для повышения производительности. Они больше сосредоточены на стабильности, валидации и общем использовании (и некоторые из них в основном синтаксический сахар).
В Laravel, чтобы назначить поле, мы прописываем:
$object->field='hello';
Но что делает фреймворк:
- проверяет, есть ли у поля мутаторы (если да, то применяет);
- проверяет, является ли поле датой;
- проверяет, является ли поле вызываемым;
- проверяет, является ли поле json castable;
- проверяет, является ли поле зашифрованным;
- и, наконец, присваивает значение внутреннему массиву.
Когда он проверяет, есть ли в поле мутаторы, он вызывает метод studly:
public static function studly($value)
{
$key = $value;
if (isset(static::$studlyCache[$key])) {
return static::$studlyCache[$key];
}
$value = ucwords(str_replace(['-', '_'], ' ', $value));
return static::$studlyCache[$key] = str_replace(' ', '', $value);
}
Каждый раз.
В этом и проблема:
for($i=0;$i<10000;$i++) {
$object[$i]->field='hello'; // bye bye performance
}
Перевод: Ольга Змерзлая
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: