База данных (БД) — это стандартный программный сервис для упорядоченного хранения данных. Повсеместно используется в том числе в клиент-серверной архитектуре. Например, вы заполняете свой профиль или делаете заказ в интернет-магазине, а система сохраняет ваши данные в базе, чтобы воспользоваться ими впоследствии (то есть БД не только сохраняет-оперирует данными, но и хранит их). В этой статье мы подробно поговорим про историю БД, принципы устройства и применение.
Содержание:
1. История появления первых БД
2. SQL
3. Требования и типы баз данных
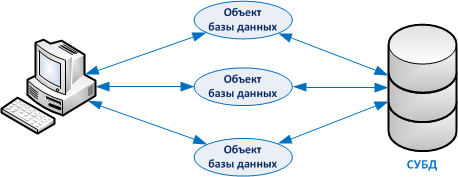
4. СУБД — интерфейс для управления БД
5. ACID: залог стабильной работы СУБД
6. БД по способу доступа к данным
7. Нереляционные БД — NoSQL
8. Области применения БД
Заключение
Еще в 1804 году Жозеф Мари Жаккар придумал использовать для хранения информации перфокарты — с их помощью ткацкий станок легко мог бы быть перепрограммирован на определенный узор. В 1890 году Бюро переписи США использовало схожие перфокарты и табуляторы для автоматизации подсчетов при переписи населения. Идея с перфокартами успешно использовалась и в первых компьютерах. В картонных листах пробивались определенным образом отверстия, кодируя полезную информацию. Однако, объем и скорость чтения данных на перфокартах, понятное дело, были низкими.
С появлением электронно-вычислительных машин возникла необходимость в программном обеспечении для устройств обработки записей на основе файловой структуры
С середины 1950-х годов стали разрабатываться основные подходы и требования к базам данных. В 1972 году вышел труд британского ученого Тедда Кодда, в котором автор описал основную идею реляционной технологии. Он сформулировал несколько правил для «настоящей» базы данных.
Во-первых, она должна включать в себя элементы, своего рода строительные кирпичики — коллекции типов объектов данных. Во-вторых, структура выборки данных должна подчиняться правилам целостности, ограничивающим набор экземпляров массива информации. И, наконец, к элементам выборки можно применять различные операции. Эти идеи заинтересовали Ларри Эллисона, и вскоре была выпущена самая первая база данных.
Забавно, что первая версия БД, выпущенная Oracle, уже имела версию «v2». На эту маленькую хитрость пошли из маркетинговых соображений.
Второй номер версии должен был подчеркнуть отрыв от конкурентов (например, IBM, в которой и работал Тедд Кодд) и стимулировать спрос на продукт. СУБД Oracle создавалась на ассемблере, однако, впоследствии от ассемблера отказались в пользу языка С, лицензия на который стоила значительно меньше.
В 1970-х годах был создан язык структурированных запросов или сокращенно SQL (Structured Query Language). Первое название этого языка — SEQUEL. Это был простой и легкий в изучении язык, который применялся для записи и чтения информации из базы данных. Несложный синтаксис позволял создавать таблицы данных, редактировать структуру БД и объединять данные.
Сегодня этот язык является стандартом для оптимизации и обслуживания реляционных баз данных. Язык SQL оказался очень живучим, он актуален и по сей день. Запрос SQL зачастую более производителен чем написание кода. В разных базах данных синтаксис SQL почти не отличается. Практически в каждом запросе присутствуют ключевые слова SELECT, FROM и WHERE — фундаментальные аспекты построения запросов к базе. Более сложные запросы являются надстройками над ними. SQL применяют сегодня даже с Deep Learning!
Также существуют так называемые диалекты SQL. Например, в Microsoft SQL Server — Transact-SQL или T-SQL, в Microsoft Access — Jet SQL, в Oracle Database — PL/SQL, в IBM DB2 — SQL PL.
Первые данные были простыми — табличными. Со временем, когда их стало очень много, человек стал использовать не одну табличную выборку, а несколько. В конечном итоге он изобрел иной подход к хранению и обработке информации — стал заботиться о том, чтобы табличные данные были связанными и логичными. Он начал выводить алгоритмы для устранения дубликатов и думать над тем, как избавиться от противоречивости при хранении данных в разных таблицах.
Правил, рекомендаций и вариантов решения проблем, возникающих при построении баз данных, очень много. Вот, например, элементарный случай неудачной записи базы данных: когда в одном из полей в «шапке» таблицы стоит «Адрес». Человек, заполняющий такую таблицу, нарушает одно из главных свойств реляционной базы данных — атомарность.
Он пишет в рамках одного поля и номер дома, и улицу, и город, и индекс. При этом запись одного и того же значения может выглядеть совершенно по-разному. Слово «проспект» можно писать как «п.», «пр.» или «пр-т» — это все приводит к путанице и неоднозначности.
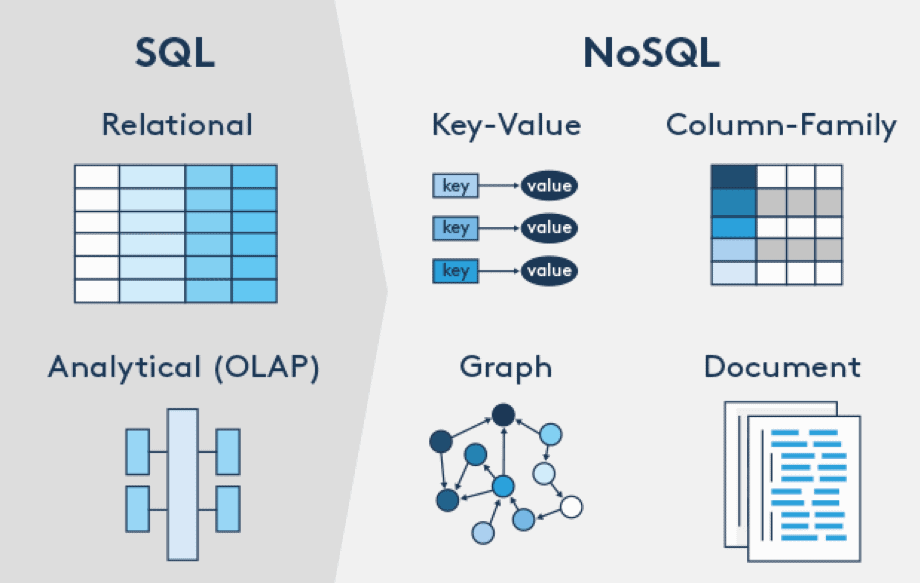
На сегодняшний день насчитывается более 50 разных видов баз данных. Однако, несмотря на разнообразие, существует несколько категорий, на которые их можно разделить:
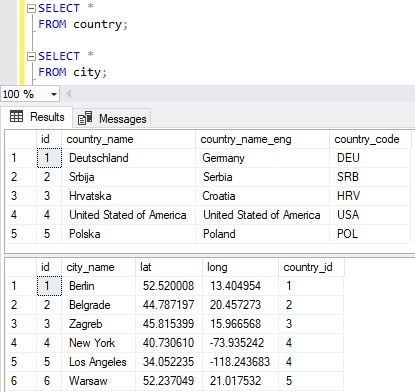
Представьте себе две таблицы, которые используются небольшой фирмой, занимающейся продажами. В первой таблице содержатся данные о клиентах: адрес отправки товара, имя клиента, платежная информация, контактный телефон и пр. Каждый элемент такой информации — атрибут — записан в отдельный столбец и ему присвоен так называемый ключ — идентификатор строки.
Вторая таблица включает в себя информацию о заказе товара: название позиции, выбранный цвет, размер, количество и так далее, а также тот самый идентификатор заказчика.
Именно наличие общего столбца в двух таблицах позволяет установить взаимосвязь между группами данных. Когда приложение обрабатывает оформление заказа, оно обращается к базе данных, запрашивает информацию по заказу из таблицы, а затем по ключу (идентификатору) подгружает данные о заказчике — способ оплаты, адрес и пр.
Приложение передает эту информацию на склад, где уже и происходит факт покупки. Сегодня, когда говорят «база данных», с большой степенью вероятности, имеют в виду именно реляционную базу данных.
Предположим, перед разработчиками стоит задача создать приложение — электронную базу рецептов. Сформулируем требования для нее.
Первое требование — стрессоустойчивость при работе с внештатными ситуациями. Всем хорошо знаком форс-мажор, когда, например, пропадает электричество и текстовый файл оказывается поврежден. При работе с файловой системой результат такого сбоя может быть непредсказуем и решение проблемы носит весьма нетривиальный характер.
Следующее требование — высокая производительность. Наверняка найдется пользователь, который захочет занести в эту базу все рецепты мира, после чего мы получим проблемы с ограничением оперативной памяти и файлом подкачки и головную боль по оптимизации кеша.
Далее — желательно организовать многопользовательский режим. Периодически необходимо делать резервную копию всей информации без остановки основного приложения. Задача по разработке такого ПО может быть реализована с помощью СУБД. Большинство используемых сегодня СУБД являются кроссплатформенными решениями и способны функционировать на компьютерах с разной архитектурой, под разными операционными системами.
При этом, чтобы избежать ошибок, влияющих на эффективность работы кода, мы должны понимать, как работает такой механизм управления базами данных.
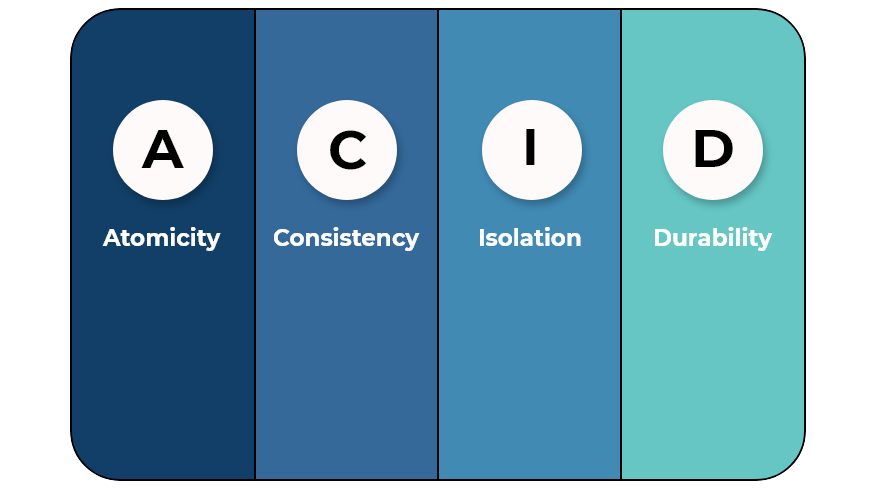
Работая с БД, мы ожидаем надежную и предсказуемую работу. В конце 1970-х годов еще один ученый — Джим Грей — вывел формулу, которая определяет безотказность СУБД. У него получился акроним ACID:
Требования к СУБД удобно объяснить на примере денежных транзакций. Допустим, вы отправляете перевод. Атомарность гарантирует, что каждая транзакция будет выполнена полностью или не будет выполнена совсем. Это означает, что два запроса: запрос по списанию денег с первого счета и запрос пополнения второго счета — должны быть выполнены оба. При наличии ошибки в одном из запросов транзакция должна быть отменена. То есть либо есть факт перевода денег, либо нет.
До проведения транзакции и после ее проведения БД у нас согласована. Мы не можем допустить неконсистентности базы, например, добавив атрибут без клиента и не связав его при помощи foreign key.
При задействовании многопользовательской системы возникает проблема изолированности операций. Если два человека проводят одновременно операции с одним денежным счетом, возникает масса проблем. Например, когда один из них видит устаревшую информацию, по причине того, что текущая транзакция, проводимая другим пользователем, не была закрыта. Для борьбы с этими проблемами используется блокировка данных в базе и версифицирование после каждого изменения.
Ну и последнее требование к реляционным СУБД очевидно: они должны быть надежными, транзакция должна оставаться неизменной при любых сбоях и нештатных ситуациях.
БД также можно разделить по способу доступа к данным. Различают файл-серверную архитектуру СУБД и клиент-серверную архитектуру СУБД. В первом случае данные хранятся на файловом сервере, а сама СУБД развертывается на рабочей станции и обращается к БД через локальную сеть. При этом синхронизация доступа к данным и обновления информации синхронизируются файловыми блокировками.
По такому принципу работают все современные СУБД: Oracle Database, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL и прочие.
Реляционные БД имеют недостатки. Это и сложность структуры, вызванная необходимостью проведения нормализации
Резкий рост количества данных и появление технологий Big Data привели к тому, что новое поколение СУБД было вынуждено отходить от реляционных принципов в пользу больших объемов. Появилось много кластерных решений, которые были построены не на реляционной модели.
Для больших БД, которые выходят за рамки одного сервера, необходимо выполнять кластеризацию. Обеспечивать целостность данных на кластерах трудно, появляются задержки, что, понятное дело, нежелательно. Поэтому мы жертвуем возможностью составлять сложные запросы и рядом ограничений, накладываемых реляционной моделью, и получаем простое масштабирование.
Так появилась парадигма MapReduce — модель распределенных вычислений в компьютерных кластерах с очень большими (до нескольких петабайт) наборами данных. Появился целый класс СУБД, который назывался NoSQL
Сегодня понятие базы данных заметно усложнилось. Теперь ее нельзя воспринимать как просто объем хранимой информации. Если бы это было так, то все базы данных можно было бы записывать в текстовый документ или документ Excel. Однако современные базы данных имеют ряд характерных особенностей, благодаря чему отличаются от обычных табличных данных.
База данных от простых табличных данных отличается, во-первых, объемом
Зачем вообще нужны базы данных? Это не только массив информации, пусть и упорядоченный. Во-первых, это инструмент для математического моделирования и средство для решения численных расчетов, которые трудно или невозможно произвести вручную. Во-вторых, проектирование баз данных позволяет организовать поисковые, справочные, банковские системы, автоматизированные системы для различных предприятий. При этом задействуются колоссальные объемы памяти.
Суммарный объем данных «цифровой вселенной» удваивается каждые два года, поэтому сейчас крупные БД исчисляются петабайтами и даже эксабайтами.
Примеров использования БД бесконечно много — они применяются в интернете, в промышленности, в маркетинге, в мобильных устройствах, в финансовой и банковской сферах, на телевидении, в телекоммуникациях, в рекламе. Базы данных обязательно используются для управления персоналом, бухгалтерского учета, связи и т.д.
Нередко использование баз данных решает общенациональные проблемы, как например, в Исландии — стране с небольшим населением, всего 300 тысяч человек. По причине географического расположения, а также в силу истории, за последние 200 лет на этом острове практически не было ни эмиграции, ни иммиграции населения. Поэтому правительство Исландии смогло создать генеалогическую базу данных всех родственных связей в стране — Íslendingabók. Все те, у кого есть исландский идентификационный номер, могут сверить свое родство, например, чтобы исключить вероятность брака с близким родственником.
База данных является главной и сложной частью современных информационных систем. Однако в одной статье уместить всю информацию о современных БД и СУБД очень сложно. Мы постарались дать начальное представление о том, как устроены современные базы данных, рассказали о принципах их функционирования и их классификации, преимуществах и архитектуре.
В заключение рекомендуем вам посмотреть видео в котором разъясняется язык запросов SQL на примере СУБД MySQL:
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}