Когда мы в Jooble решили перейти на использование микросервисной архитектуры в своих проектах, перед нами встал вопрос: как организовать коммуникацию между этими микросервисами и не превратить это в производственный ад?
Как балансировать нагрузку, как реализовать failover, как получить единую точку входа для взаимодействия между сервисами и как, в конце концов, это все поддерживать, когда постоянно добавляются новые серверы, сервисы, экземпляры сервисов и т.д.? Особенно остро эти вопросы стоят, когда количество сервисов уже исчисляется десятками или даже сотнями.
У нас есть куча проблем и нет решения. Поэтому начать нужно с того, что сможет связать все микросервисы и стать базой для нашей системы, — прокси-сервера. Мы будем посылать запросы на него, а он будет направлять их на соответствующие сервисы.
Рассмотрим подробнее.
В качестве такого прокси-сервера, который будет содержать всю информацию о наших сервисах, мы будем использовать Nginx. Это мощный и к тому же легкий в освоении инструмент.
Какие проблемы мы хотим решить с помощью Nginx:
Допустим, у нас есть сервис, трафик на который мы хотим направлять через Nginx. Для примера мы опустим большинство параметров настроек самого Nginx и сконцентрируемся на части, касающейся проксирования запросов. В таком случае наш конфиг будет иметь вид:
http {
include mime.types;
default_type application/octet-stream;
upstream service1 {
keepalive 512;
// для каждого экземпляра сервиса мы указываем адрес,
// разрешенное количество неудачных запросов и время,
// в течение которого этот экземпляр сервиса не будет принимать запросы
//после достижения максимального количества неудачных запросов
server 10.0.0.1:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.2:5000 max_fails=5 fail_timeout=1m;
}
server {
listen 80;
//перечень условий, по которым запрос будет передан к следующему экземпляру сервиса в рамках upstream
proxy_next_upstream error timeout invalid_header http_500 http_503;
server_name localhost;
location ~* ^/service1/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service1$path;
proxy_pass_request_headers on;
}
}
} Пока все довольно компактно, но что будет, когда мы начнем масштабировать систему, вводя все новые и новые сервисы? Давайте посмотрим на наш новый конфиг:
http {
include mime.types;
default_type application/octet-stream;
upstream service1 {
keepalive 512;
server 10.0.0.1:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.2:5000 max_fails=5 fail_timeout=1m;
}
upstream service2 {
keepalive 512;
server 10.0.0.3:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.4:5000 max_fails=5 fail_timeout=1m;
}
upstream service3 {
keepalive 512;
server 10.0.0.5:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.6:5000 max_fails=5 fail_timeout=1m;
}
...
...
...
upstream service100 {
keepalive 512;
server 10.0.0.199:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.200:5000 max_fails=5 fail_timeout=1m;
}
server {
listen 80;
proxy_next_upstream error timeout invalid_header http_500 http_503;
server_name localhost;
location ~* ^/service1/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service1$path;
proxy_pass_request_headers on;
}
location ~* ^/service2/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service2$path;
proxy_pass_request_headers on;
}
location ~* ^/service3/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service3$path;
proxy_pass_request_headers on;
}
...
...
...
location ~* ^/service100/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service100$path;
proxy_pass_request_headers on;
}
}
} Когда у нас десятки сервисов, то вместо простого и лаконичного конфигурационного файла мы получаем условно бесконечный набор похожих между собой конструкций. Теперь этот конфиг будет крайне трудно как читать, так и модифицировать.
Можно попробовать разделить один большой конфиг на набор мелких, но это не решает главную проблему масштабирования системы, ведь все изменения мы должны будем делать вручную и далеко не самым удобным способом.
Единственный логичный выход из ситуации — автоматизация процесса внесения изменений в конфиг Nginx. Но для этого нужно где-то хранить данные обо всех наших сервисах.
Consul — это веб-сервис, который решает нашу проблему сохранения данных обо всех сервисах. Он автоматически поддерживает данные о сервисах в актуальном состоянии и предоставляет удобный доступ к этим данным через API.
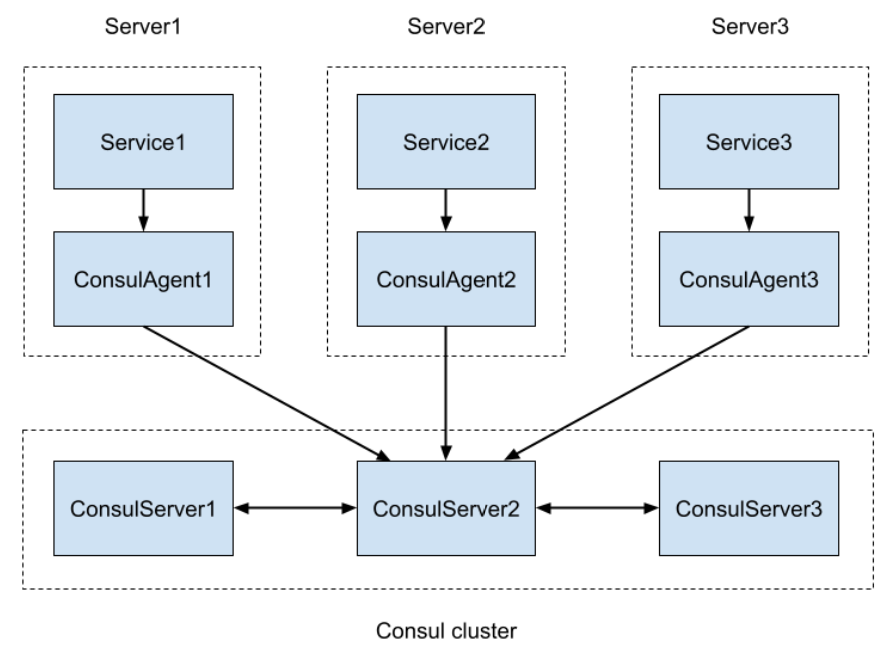
Для production-среды поднимают кластер Consul, который имеет несколько серверных нод и множество агентов.
Как это работает:
Это позволяет при обращении к любой из серверных нод получать информацию обо всех сервисах данного кластера. Агенты мы поднимаем на всех серверах, где только есть микросервисы.
Схематично процесс выглядит так:
Какая же информация о сервисах нам нужна? Вот ответ от Consul на запрос по получению информации о service1:
{
"ID": "service1-5000",
"Service": "service1",
"Tags": [
"green",
"metrics"
],
"Meta": {
"Cluster": "prod1",
"ExternalAddress": "http://10.0.0.1:5000",
"InternalAddress": "http://10.0.0.1:5000",
"Version": "69"
},
"Port": 5000,
"Address": "http://10.0.0.1",
"Weights": {
"Passing": 0,
"Warning": 0
},
"EnableTagOverride": true,
"ContentHash": "7be933df34d7e251"
} Есть адрес сервиса в Address и название в Service — это уже тот минимум, который позволит нам сгенерировать правильный конфиг для Nginx. Теперь остается только настроить трансфер этих данных.
Consul Template позволяет нам получать данные с Consul и записывать их в файл с определенным, указанным нами же, шаблоном. При каждой смене данных в Consul файл будет перегенерироваться, к тому же есть возможность выполнить определенную команду при этом. Например, перезагрузка изменения в Nginx, когда Consul Template обновил данные в конфиг-файле.
Есть развернутая документация и все необходимые ссылки на GitHub.
Для начала попробуем достать данные из Consul и поместить их в обычный файл. Для этого нам нужно создать:
Создаем конфигурационный файл:
consul {
address = "localhost:8500" //адреса консула
retry {
enabled = true
attempts = 10
backoff = "250ms"
}
}
template {
source = "in.tpl" //входной файл, он же темплейт
destination = "out.conf" //выходной файл
perms = 0600
command = "nginx -s reload" //команда, которая выполняется после генерации файла
error_on_missing_key = false
}
wait {
min = "1s"
max = "2s"
} Теперь создаем темплейт с названием “in.tpl” и содержимым:
{{range service "service1" }}
server {{index .ServiceMeta "InternalAddress" |replaceAll "http://" "" }}
{{end}} Запускаем Consul Template и в исходном файле “out.conf” получаем:
server 10.0.0.1:5000 server 10.0.0.2:5000
Следующий шаг — создание шаблонов для генерации конфигурационного файла Nginx:
http {
include mime.types;
default_type application/octet-stream;
{{range services -}}
{{$service := service .Name -}}
{{range $service -}}
upstream {{ .Name }} {
keepalive 512;
{{range $service -}}
server {{index .ServiceMeta "InternalAddress" |replaceAll "http://" "" }} max_fails=5 fail_timeout=1m;
{{end -}}
}
{{end}}
{{end}}
server {
listen 80;
proxy_next_upstream error timeout invalid_header http_500 http_503;
{{range services -}}
{{$service := service .Name -}}
{{range service .Name -}}
location ~* ^/{{.Name}}/(.*) {
set $path /$1$is_args$args;
proxy_pass http://{{.Name}}$path;
proxy_pass_request_headers on;
}
{{end}}
{{end}}
}
} И после запуска можем проверить, какой конфиг для Nginx мы получили:
http {
include mime.types;
default_type application/octet-stream;
upstream service1 {
keepalive 512;
server 10.0.0.1:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.2:5000 max_fails=5 fail_timeout=1m;
}
upstream service2 {
keepalive 512;
server 10.0.0.3:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.4:5000 max_fails=5 fail_timeout=1m;
}
upstream service3 {
keepalive 512;
server 10.0.0.5:5000 max_fails=5 fail_timeout=1m;
server 10.0.0.6:5000 max_fails=5 fail_timeout=1m;
}
server {
listen 80;
proxy_next_upstream error timeout invalid_header http_500 http_503;
server_name localhost;
location ~* ^/service1/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service1$path;
proxy_pass_request_headers on;
}
location ~* ^/service2/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service2$path;
proxy_pass_request_headers on;
}
location ~* ^/service3/(.*) {
set $path /$1$is_args$args;
proxy_pass http://service3$path;
proxy_pass_request_headers on;
}
}
} Как теперь это все работает:
http://{nginx-address}/{service-name}/Схематично нашу микросервисную экосистему можно изобразить так:
Благодаря связке Consul→Consul Template→Nginx мы получаем систему, которая всегда будет находиться в актуальном состоянии. Добавляется новый сервис или останавливается один из существующих — данные в Nginx изменятся автоматически в течение миллисекунд, сохраняя нам кучу времени и не давая возможности ошибиться.
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}