Привет! Меня зовут Никита Роатэ, я Java Developer в NIX. Уже около двух лет я очень плотно работаю с Keycloak и построением микросервисной архитектуры вокруг него. За это время у меня накопилось достаточно полезных знаний, которыми хотелось бы поделиться с вами.
Сама по себе тема OAuth 2 довольно обширная, сложная и поначалу даже может слегка напугать. Но с Keycloak ее вполне можно осилить. Главное — разобраться в самом Keycloak, и этот гайд поможет вам увереннее подойти к его использованию.
В статье мы коснемся таких тем:
Безопасность — важный аспект разработки и всего проекта в целом. Каждый API должен быть защищен. Для этого можно разработать полностью кастомное решение, воспользоваться Spring Security или не изобретать велосипед, а выбрать готовое решение по типу Okta и Keycloak. Я расскажу именно о последнем, и причин такого выбора несколько:
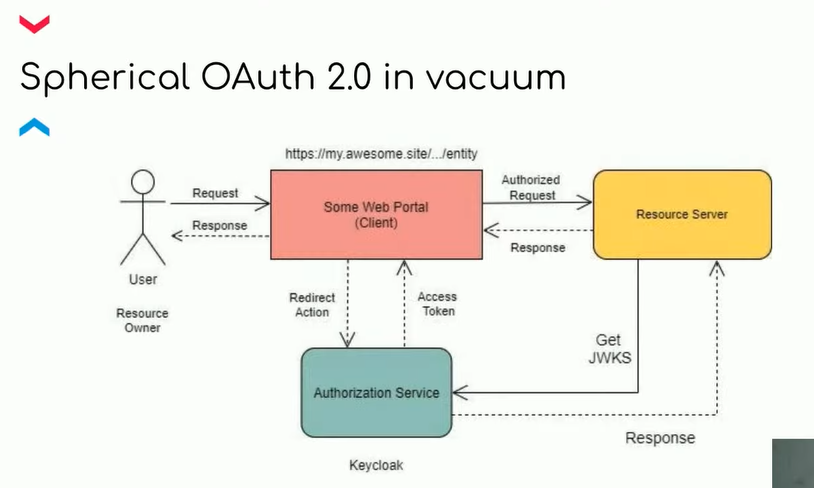
В статье я уделю внимание OAuth 2. Где он может нам встретиться? Допустим, мы хотим скачать свою фотографию из Google-диска. Мы приходим на портал, который достанет нашу фотку по ID. Если мы не аутентифицированы, нас перенаправят с клиентского приложения на авторизационный сервис, где откроется логин-страница для ввода логина и пароля. Так Authorization Service проверит, что мы — это действительно мы, и имеем право скачать это фото.
Если мы успешно авторизировались и получили заветный токен, то через портал идем на Resource Server. Resource Server — это микросервисная архитектура, в которой и происходит вся бизнес-логика. То есть это именно то, что мы и разрабатываем.
Если вернуться к примеру с Google Фото, то чтобы достать файл, нужно обратиться к API этого микросервиса. Но микросервис не должен отдавать API кому угодно, даже если он пришел с токеном. Он должен убедиться, что токен подписан именно нашими Authorization-сервисом, то есть Keycloak. Микросервис делает запрос за JWKS, по одному из ключей валидирует токен, и если он валидный, возвращает ответ — в нашем случае фотографию.
На верхнем уровне система изображена на иллюстрации. Это стандартная трехступенчатая схема OAuth 2-аутентификации. Владельцем ресурса выступаем мы, как пользователь, клиентским приложением является веб-портал, Authorization Service — это Keycloak, а Resource Server — набор микросервисов.
Вы можете спросить: что такое JWKS, за которым ходит ресурс? За этой аббревиатурой скрывается JSON Web Key Set. По сути, это набор ключей, которым валидируют подпись токена. В токене лежит Key ID — айдишник ключа, которым можно проверить подпись токена. Если подпись валидна, процесс идет дальше по флоу.
Представьте, что вы заходите в большой торговый центр с множеством магазинов. Этот ТРЦ — Keycloak, а магазины — это наши realm
Keycloak позволяет осуществлять менеджмент ролей. Если есть кассир, то у него есть свои роли: чтобы он мог доставать деньги из кассового аппарата, менять цену, удалять товар и т.п. У пользователей другие задачи: брать или не брать ту или иную вещь. В этом случае нужно разграничивать не только пользователей по отделам, но и наши магазины в целом. То есть если кто-то может бесплатно брать вещи в магазине-1, это не значит, что он может бесплатно брать вещи и в магазине-2.
Далее я приведу стандартный пример URL при логинке Keycloack, где красным выделены realm и client:
https://someDomain/auth/realms/myRealm/protocol/openid-connect/auth?client_id=myClient...
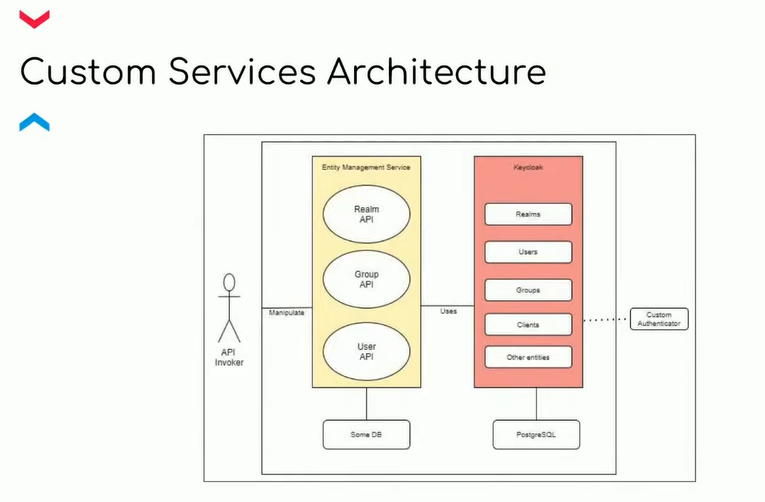
Перейдем к созданию микросервисов. Начнем с построения архитектуры. Ниже вы можете увидеть верхнеуровневую схему того, как должен выглядеть микросервис, и как он должен взаимодействовать с Keycloak.
Как я уже писал, у Keycloak есть реалмы, пользователи, группы, клиенты, роли. Всю метадату о них он хранит в PostgreSQL. Но не стоит свою метадату хранить вместе с сущностями Keycloak. Все-таки нужно придерживаться single responsibility — все должно быть изолировано друг от друга.
Нам нужно написать кастомный микросервис или набор микросервисов, которые будут общаться с Keycloak. Он позволяет обращаться к нему по определенным URL. И если мы хотим создать realm, то это будет post-запрос, а если хотим обновить — put-запрос. И так со всеми сущностями. Соответственно, нужен микросервис, который будет предоставлять такую API для выполнения кастомной логики при обращении к Keycloak.
Как вариант, будем хранить в нашей базе данных свою метадату, которая нужна только нам. Если говорить о большом enterprise-проекте на крупной SaaS-платформе, то здесь будет очень много данных. Их лучше держать в нереляционной базе данных (например, MongoDB).
Возникает вопрос: есть ли в Keycloak решения для обращения к API «из коробки»? Ответ короткий — нет. Поэтому нам нужно самим придумать SDK, которую бы по необходимости подключали в микросервисы.
Благодаря этому можно будет осуществлять HTTP-запросы в Keycloak не через веб-клиент, а с использованием готовых методов, реализованных в SDK.
А вот и следующий челлендж. Мы хотим привлекать все больше кастомеров. Представим, что приходит к нам крупная организация и говорит: «Хочу, чтобы были станки и сотрудники для работы с ними». Для этого нам нужно наладить юзер-менеджмент API, чтобы пользователи могли работать с устройствами. Также надо реализовать те или иные роли и те или иные возможности станков.
К примеру, заказчик говорит, что на станках есть суперфича. Благодаря ей удается делать HTTP-вызовы в портал и присылать свою дату — и, соответственно, заказчик хочет воспользоваться вашей платформой. И таких смежных, но с разными требованиями заказчиков пришло 10, 100, 1000! Что делать?
Keycloak позволяет создать сколько угодно реалмов и в них — любое количество клиентов и пользователей. Но тут необходимо действовать вдумчиво, масштабироваться. С ростом количества сущностей Keycloak станет замедляться. По факту он предназначен для пары реалмов и работы с ними. Когда же мы будем логиниться суперпользователем в админку даже при 1500 реалмов, логин будет идти несколько минут, а то и падать по таймауту. Если мы говорим о создании нового реалма, процесс займет порядка 20-30 секунд в лучшем случае. Поэтому надо менять логику и взаимодействие с Keycloak.
Одно из решений этой задачи — внедрение асинхронного механизма. Допустим, пришел кастомер и говорит: нужно насетапить всю сеть пользователей, которые будут работать в контексте нашего заказа, но делать они это будут потом. То есть прямо сейчас не нужно нагружать Keycloak. Для этого мы можем научить микросервис посылать ивент в Kafka с созданием пользователя, а Keycloak — слушать эти запросы. За счет этого станет возможно асинхронно создавать пользователей: в кастомном микросервисе создавать какую-то метадату, а уже в Keycloak она приедет позже.
Или же наоборот: используя Kafka и асинхронно создавая, удаляя или изменяя сущности, мы сможем из Keycloak удалять и создавать пользователей, а в кастомных микросервисах они появятся потом. Конечно, можно попробовать решить проблему вертикальным масштабированием, то есть наращиванием ресурсов, но это стоит денег.
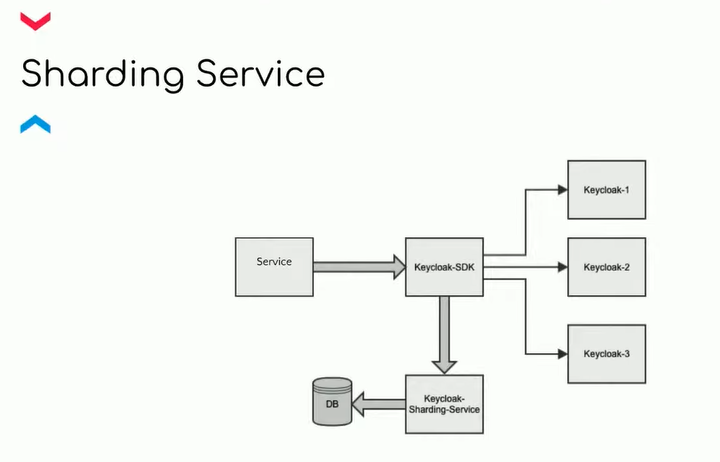
Есть и другое решение: ограничить один инстанс 500 реалмами, а на каждый 501-й реалм создавать новый инстанс. Для этого понадобится сделать входную точку, которая бы понимала, что если пришел пользователь из определенного реалма, то нужно идти в этот инстанс из Keycloak, а если из другого — то в другой инстанс.
Этот механизм — и помощь, и челлендж. Ведь нужно придумать, как соединять инстансы и кастомный сервис. Плюс ко всему надо помнить, что это своеобразный bottleneck
Но не будем забывать, что Keycloak не стоит на месте. Его команда разработки обещает к июлю 2022 года представить Keycloak.X. Все-таки разработчики понимают, что их продукт часто используют не так, как они ожидали изначально. Поэтому они обещают улучшенную работу с большим количеством данных, более быстрый старт и меньше «болей» при апдейте той или иной версии Keycloak.
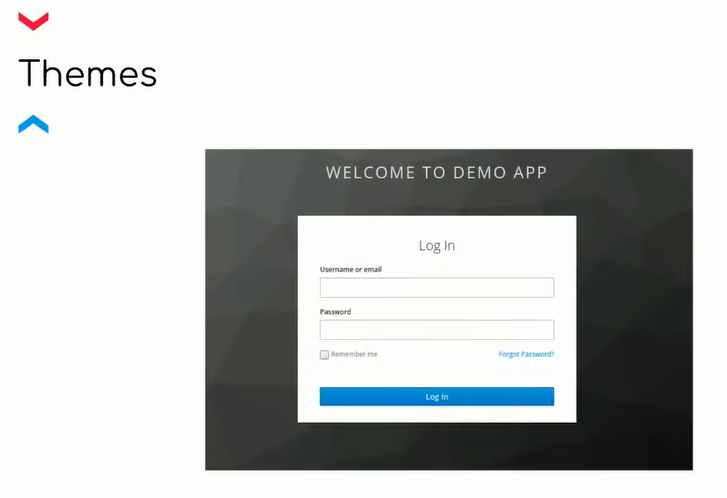
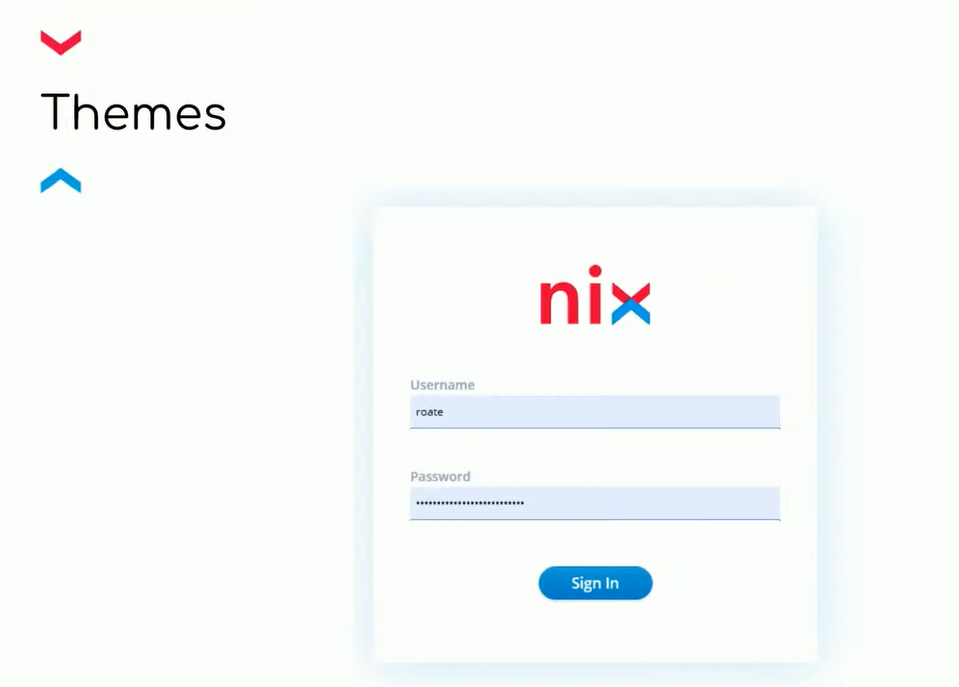
Все кастомеры разные, а инструмент в виде Keycloak — один. При этом пользователям надо дать понимание того, что они уникальны. Проще всего это сделать кастомизацией логин-страницы. Для этого в Keycloak есть реализация тем. На иллюстрации ниже приведена стандартная тема: она простая и невзрачная.
Но ее можно довольно легко и быстро превратить в такую:
Для этого предусмотрен набор FTL-страниц. FTL (Freemarker Template) — это некий симбиоз Java, JavaScript и HTML. Переопределив набор FTL-страниц, мы сможем как добавлять кастомные темы, так и менять базовую.
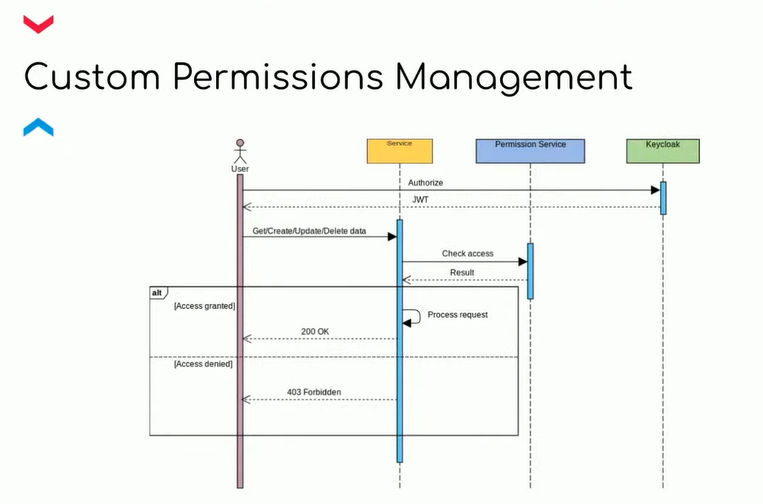
Теперь давайте представим набор из тысяч пользователей в каждом реалме. У всех должна быть роль чтения ресурса, но мы хотим, чтобы к этой роли добавилось еще несколько либо они объединились в одну кастомную. На этот случай в Keycloak есть композитные роли. Мы указываем, что он администратор, который получит доступ для чтения, удаления, обновления и т.д.
А если у нас другая задача: чтобы во всех организациях роль «администратор» получила дополнительную роль либо вообще исчезла и на ее месте появилось несколько маленьких? И это требуется сделать во всех реалмах для всех пользователей сразу. Как это реализовать? Пример микросервиса для решения этой задачи — ниже.
Мы все так же логинимся в Keycloak и получаем токен. Но ответственность за менеджмент ролей перекладываем из Keycloak на этот кастомный продукт. Затем при взаимодействии сервисов друг с другом они обращаются в этот permission-сервис и получают тот или иной набор разрешений. А уже на стороне сервиса валидируется, может ли пользователь в соответствии с разрешением выполнять операцию.
Как вариант, можно реализовать API, которые в реальном времени будут добавлять роли или изменять их — вместо того, чтобы делать риквест на девелоперов, которые должны будут своими силами выполнять ту же операцию.
Заказчиков становится еще больше. У всех разные цели, возможности и приоритеты. Одним нужен менеджмент ролей в большей степени, другим — требуется более гибкая настройка взаимодействия с сущностями. В таком случае мы можем задать определенные шаблоны, по которым такие организации будут создаваться. И когда появляется новый кастомер, мы предлагаем разные наборы «из коробки». Можем реализовать и базовый набор функций под требования заказчика, а он уже доделает, как ему нужно.
Также можно создать этот realm в Keycloak. Тогда кастомный микросервис, который занимается генерацией реалмов, будет в запросе получать информацию, какой тип он хочет создать, вытаскивать realm из Keycloak, добавлять переданную кастомную информацию и формировать новый realm. Есть вариант, конечно, хранить это все на какой-то машине. Ведь по факту realm — обычный JSON-объект, который можно изменять. Но в этом случае возникает проблема с тем, что его нужно как-то изменять от релиза к релизу и хранить актуальную версию, плюс быть уверенным в его валидности. Мы обязаны обеспечить процедуру кеширования. Тогда микросервис при поднятии сохранит темплейты и не будет добивать Keycloak запросами.
Весь процесс создания продукта включает разработку, потом тестирование, а доход приносит прод, которым пользуется конечный пользователь.
И здесь возникает вопрос: как изменения с низших инвайроментов доставить до наивысших в созданном виде и количестве, и быть уверенным в их правильности?
К примеру, в релизе создано 100 реалмов, в них по 100 клиентов с разной бизнес-логикой. Нужно перенести их и на тестирование, и на прод после замечаний от тестировщиков. Можно заставить девелопера переносить все эти изменения мануально… А можно написать кастомный микросервис, который раз в релиз доставлял бы все изменения посредством миграции.
Liquibase позволяет насетапить миграции на реляционной базе данных. В нашем проекте мы используем нереляционную базу MongoDB и нам отлично подходит Mongock.
Как это выглядит? Сначала создаем чейндж-логи — списки изменений, которые должны быть доставлены. В них есть чейндж-сеты — описанные изменения. При помощи Mongock-аннотаций мы указываем точную последовательность, в которой должны идти миграции. Сначала должен создаться realm, а уже потом обновляться — и только в таком порядке. Плюс можно хранить кастомную метадату по типу автора, список, как все должно выполняться, а также ID. Именно последнее — главное, ведь по ID проверяется уникальность миграции. Если она уже бежала, она просто не пробежит в следующий раз — это и делает Mongock.
Но все это подводит к следующей проблеме. Все-таки нам надо доставить изменения из разработки на тестирование и дальше на прод, что происходит в процессе деплоймента. Если миграций много, они могут бежать очень долго и следить за ними стоит много человеко-часов. Потому необходимо приоритезировать миграции, которые должны бежать до старта всех остальных микросервисов.
Как я уже отметил выше, некоторые микросервисы должны закешировать темплейтные реалмы с уже правильными изменениями. Если нужно в организации нашего заказчика какому-то работнику добавить read permission, то это уже неважно в контексте большого проекта. И мы по факту не обязаны эту миграцию запустить в самом начале — ее можно запустить потом и быть уверенным, что она побежит. Как это решить?
Spring предоставляет такую прекрасную аннотацию, как Profile. Мы можем создать профайлы (например, мажорные и минорные) и отмечать: эта миграция мажорная и должна бежать до деплоймента, а эта — минорная, и ее можно запустить потом.
К мажорным миграциям относятся темплейтные изменения и добавления и удаления клиентов OAuth 2, о которых поговорим далее.
Минорные — это все остальные, которые не кэшируются на стороне микросервиса и не важны на данный момент для старта остальных микросервисов.
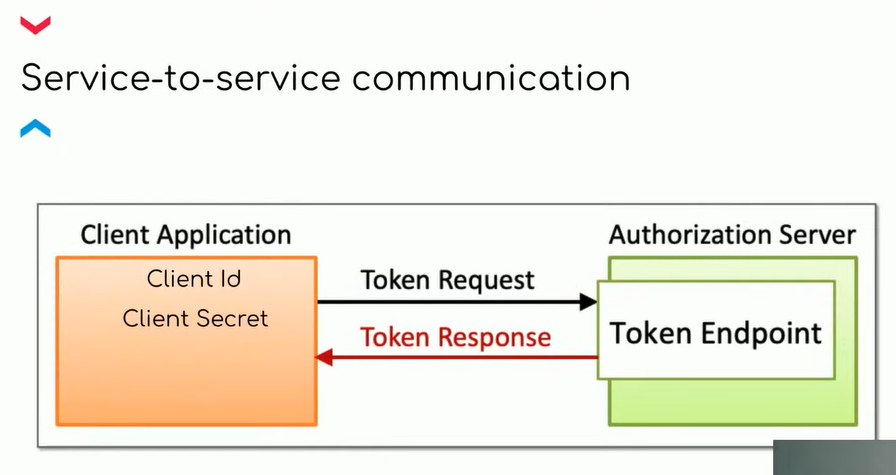
Очень важно продумать, как микросервисы будут коммуницировать между собой. Их может быть много, и они могут обращаться к API друг друга. Следовательно, нужно наладить процедуры авторизации и аутентификации для этих процессов. Для этого можно воспользоваться процедурой аутентификации по Client ID и Client Secret. В таком случае для каждого сервиса создается клиент OAuth 2 в Keycloak. На каждой стороне сервиса зашивается секрет, с которым он будет получать токен и затем обращаться в нужный микросервис. Как это реализовать?
В первую очередь мы можем передавать его как environment variable, зашив где-нибудь в зашифрованном виде. Но представим: в релиз создалось 10-15 микросервисов. И нужно, чтобы во время деплойментов в каждый из них зашивался его секрет. Ведь без этого он просто не заведется и не сможет общаться с другими микросервисами. Как автоматизировать этот процесс? Надо научить машину делать все самой.
Допустим, нужно, чтобы микросервис получил секрет. Он хранится в клиенте в Keycloak. Мы можем реализовать дополнительного пользователя, креды которого зашьем в environment variable в заинкрипченном виде. Сервис будет получать эти креды, ходить за клиентом за его ID, а потом сам же за секретом. Зная свой секрет, он с самого начала будет хранить его у себя.
И в заключительной части я бы хотел рассказать про тесты. Чем лучше написан тест, тем быстрее идет процесс девелопмента, и тем выше уверенность разработчика и кастомера в корректности изменений и нововведений.
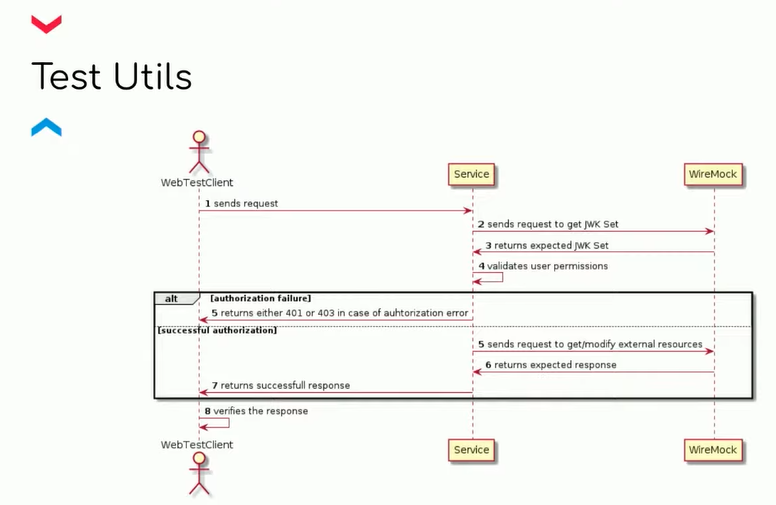
Я предлагаю написать тестовую библиотеку, которая будет реализовывать так называемые стабы этих коллов в Keycloak. Ведь когда мы пишем тест, мы хотим пройти все флоу. И если мы можем подложить в базу нужную метадату и обратиться к какому-то API нашего микросервиса, то эти коллы в Keycloak мы напрямую как-то помокать не можем. Если говорить про Keycloak SDK, то мы можем замокать, используя Mockito. Обратите внимание: этот кол мокается не в другой сервис, а в вызов методов внутри сервиса.
Поэтому я предлагаю внедрить WireMock
Главное — послать колл и получить придефайненный респонс. Следовательно, в тестах можно навешивать кастомные разрешения для обращения на тот или иной API и подкладывать респонсы при взаимодействии с другими микросервисами и Keycloak в целом.
Все это подтверждает тот факт, что Keycloack — функциональный инструмент, с которым процесс разработки становится заметно проще, а конечный продукт — безопаснее, стабильнее и удобнее. Надо просто не бояться вникнуть в эту технологию и полюбить ее, как это удалось мне. Удачи!
Читайте также: Авторизация OAuth 2.0: два полезных решения для тестировщиков
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}