В своей предыдущей статье на Highload я подробно рассказал о пользе лямбда-функций, значительно упрощающих работу девелопера.
Сегодня мы продолжим разговор и обратим внимание на расходы, мониторинг, популярные варианты использования лямбда-функции, а также фреймворки и инструменты для работы с ней.
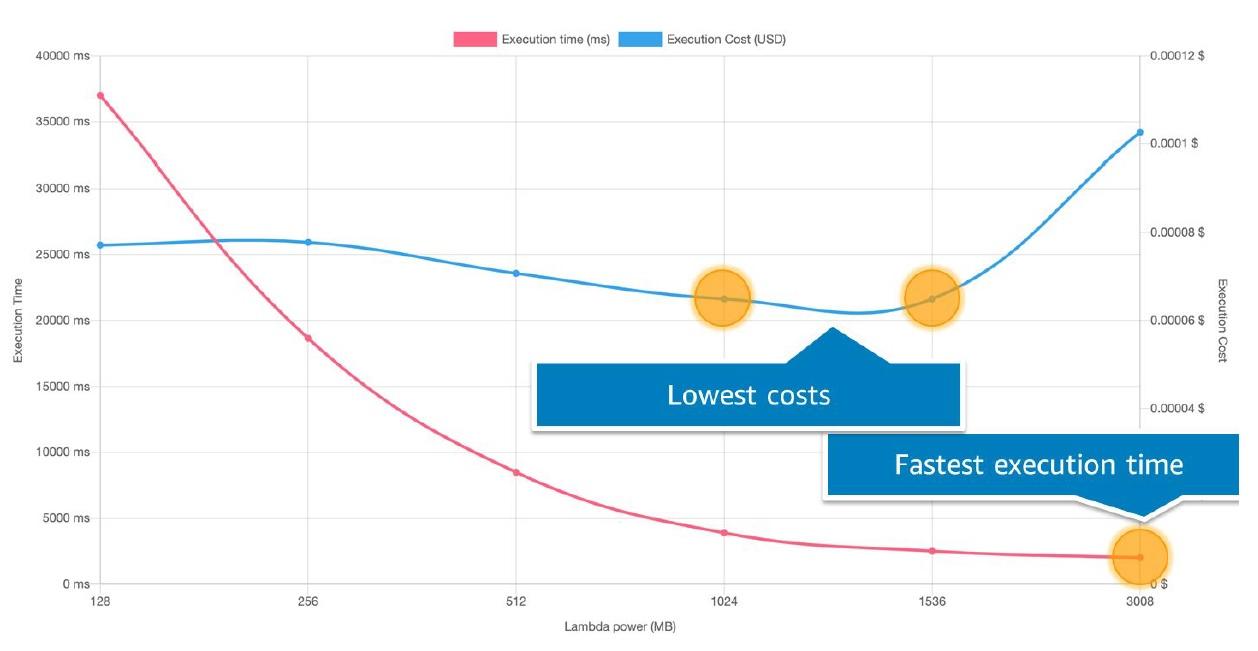
Оплата услуг AWS рассчитывается в килобайт-секундах. Это количество килобайт оперативной памяти в настройках лямбды, умноженных на время выполнения функции в секундах. Почти всегда увеличение памяти никак не влияет на общую сумму. А все потому, что вместе с ростом производительности уменьшается и время.
К примеру, при увеличении оперативной памяти вдвое время может сократиться более чем в два раза.
Давайте посмотрим на этот график. Здесь самые низкие издержки достигаются на отрезке от 1024 до 1536 МБ. Хотя поначалу могло казаться, что для наибольшей экономии нужно ставить базисные 128 МБ.
По умолчанию отслеживание работы лямбда-функции осуществляется через сервис CloudWatch. В него интегрируются и отправляются служебные данные, частично недоступные в логах. Есть около десятка популярных метрик для настройки и вывода на дашборд.
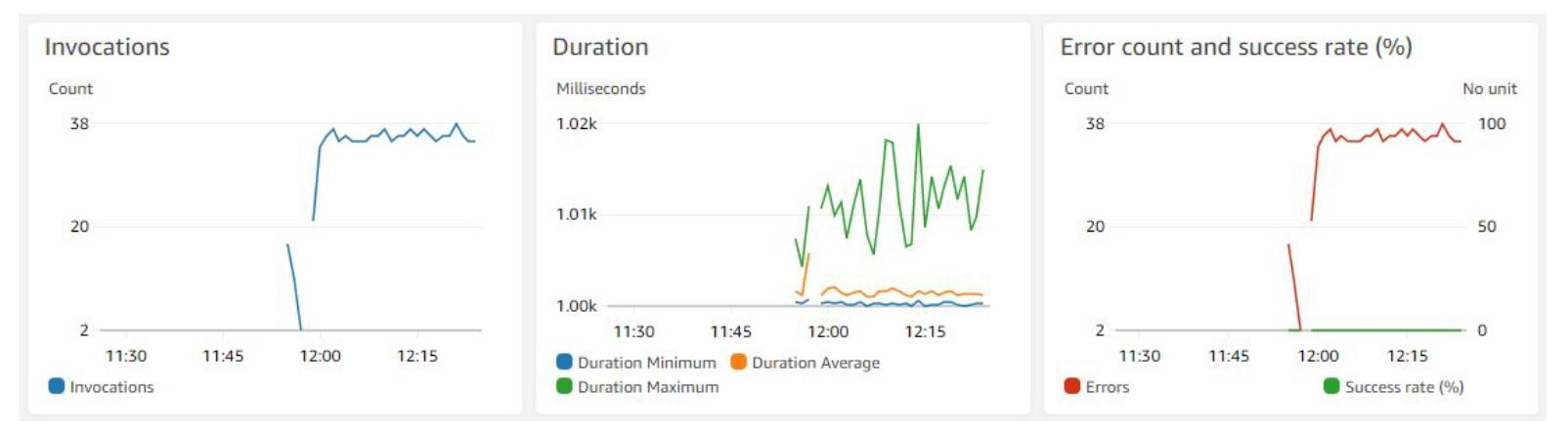
В примере ниже приведены три следующих метрики:
Из первого графика видно, что около 12:00 значительно возросло количество обращений к лямбда-функции. На втором графике видно, что время выполнения функции в среднем составляет около 1000 миллисекунд. На третьем — фиксируется высокий показатель ошибок. Все вместе дает немало поводов к размышлению о выполнении лямбды, падении тайминга и полученных фейлах.
Также через сервис CloudWatch происходит логирование данных из лямбда-функции.
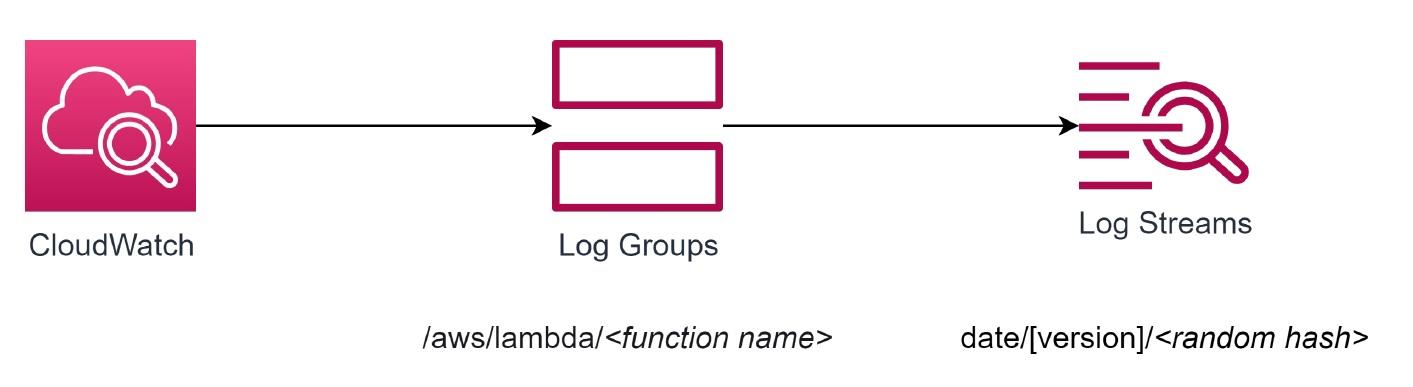
То есть все, что отправляется в STDOUT (log или print), отправляется именно в CloudWatch. Там для каждой лямбда-функции создается своя лог-группа, внутри которой собираются стримы.
Стрим — это вся информация из логов от функции, от одного экземпляра энвайромента. Если у вас было несколько обращений к функции за короткое время, и она все время работала, это будет собрано в одном стриме.
Путь к нему состоит из даты первого исполнения, версии лямбда-функции и рандомного хеша из цифр:
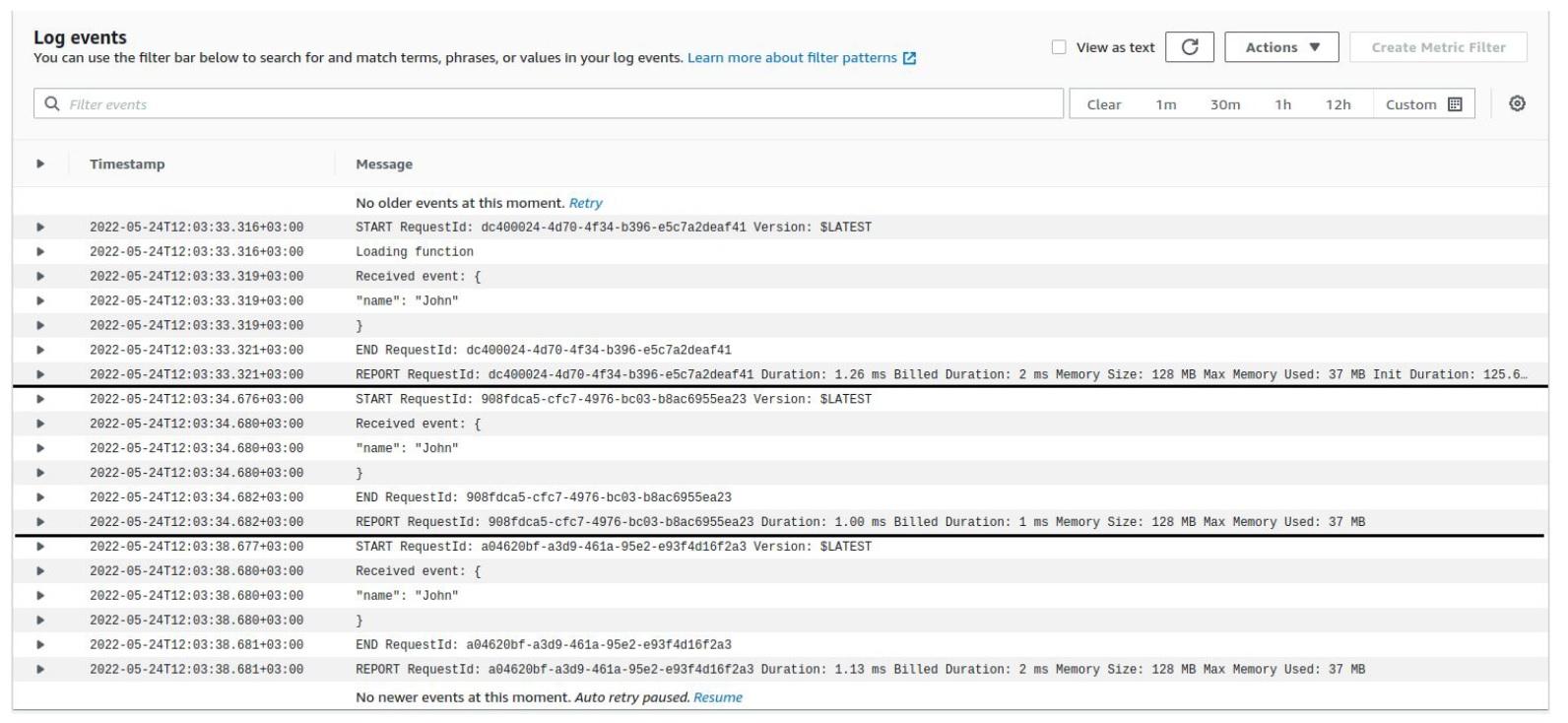
На следующей иллюстрации представлен пример логов лямбда-функции, которая была написана выше. Есть три обращения к лямбде, когда трижды передавалось имя John. И все это с интервалом в несколько секунд трижды собиралось в этом отчете:
В первом логе обратите внимание на принт Loading function во второй строке, который объявлен вне лямбда-функции. Он нигде не повторяется. В этом случае для Python не происходит никакого импорта библиотек для уже созданного окружения.
Также в первом логе есть важный блок Init Duration. Это время на загрузку кода, создание окружения и выполнение всех импортов и самого кода вне метода обработчика. Фактически это все, что происходит при холодном старте: подключение к разным базам данных и сервисам, где хранятся секреты. При повторном использовании среды этого уже происходить не будет.
В инфраструктуре сервисов AWS предусмотрено четкое разделение доступов на чтение и выполнение для различных ресурсов даже в одном аккаунте. Для этого используется механизм сервиса Identity Access Management. Он предполагает создание Policy — политик. Описания объясняют, какой ресурс и к чему имеет доступ.
Здесь все строго ограничено: невозможно даже сделать запись в CloudWatch без Policy на разрешение изменения в логах. Мы в нашей команде часто создаем предел на функцию консоли, в дашборде AWS, чтобы он автоматически подставлял такие пермиссии к ролям.
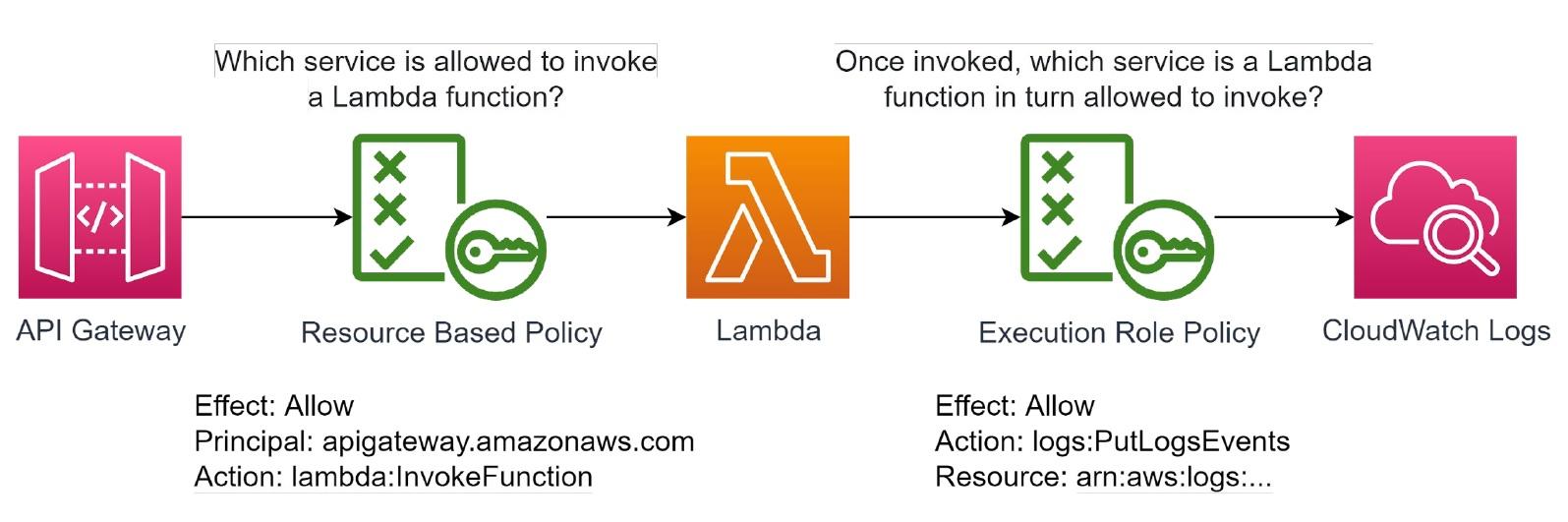
Для лямбда-функции существуют два типа политик:
Описывают, какой сервис может обращаться к лямбде и запускать ее. Эта политика применяется на лямбда-функцию и существует как отдельный роут. API Gateway обращается к функции, ведь речь не идет о конкретной функции. Такая политика связана с одним действием для нескольких ресурсов.
Указывают, к каким ресурсам может обращаться функция. Эти политики существуют как отдельные сущности и могут быть расшарены между несколькими лямбдами. Также здесь прописываются действия, которые должны осуществиться, и ресурс, к которому есть доступ. Для этого используется ARM (Amazon Resource Name), выступающий идентификатором ресурса.
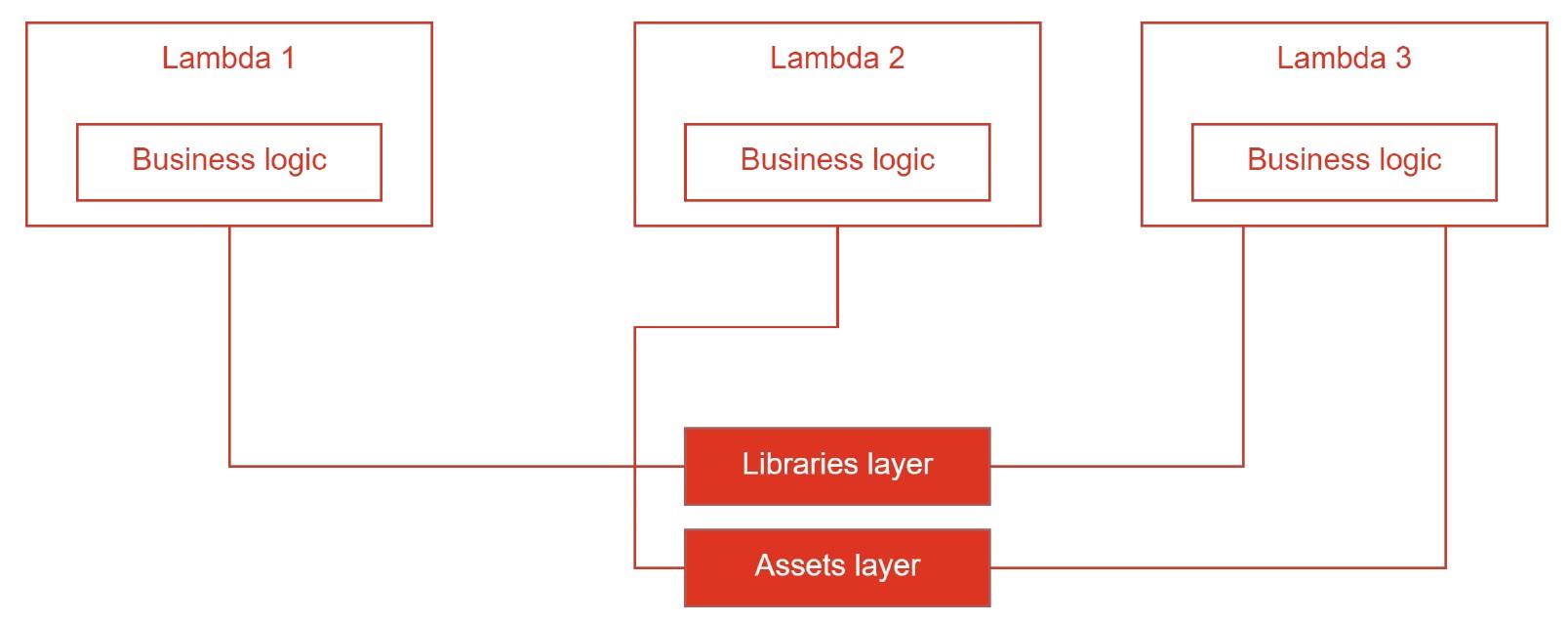
Это удобный способ упаковки библиотек и зависимостей, если их следует использовать совместно для нескольких лямбда-функций. Сам по себе это ZIP-архив, который для окружения лямбда-функции распаковывается в директорию opt. Он может быть публичным или приватным.
Также лейеры понадобятся в случае частых изменений кода лямбда-функции, когда зависимости остаются прежними. Тогда вы изменяете размер функции при деплое. Бизнес-логика преимущественно весит мало, но пакет зависимостей может быть очень тяжелым. Поэтому с лейером вам не нужно тратить время на повторную загрузку зависимостей к облаку.
Вот пример распределения лейеров. Лямбда-функции 1 и 3 совместно используют библиотеки. Лямбда функции 2 и 3 делят ассеты. Например, шаблоны писем или HTML, к которым они будут иметь доступ:
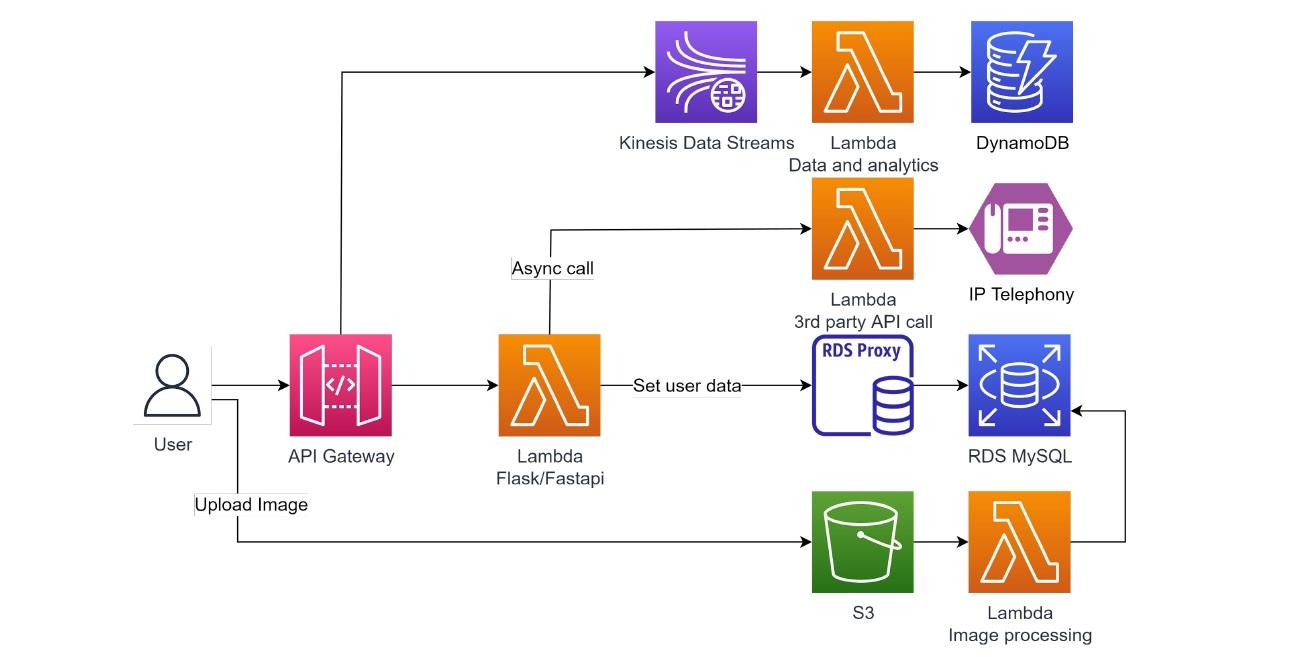
Все эти примеры касаются взаимодействия пользователей с функцией и базой данных. О каждом из них расскажу отдельно.
Начнем по строкам сверху вниз:
В следующем Use Case по API Gateway следует лямбда-функция. Фактически она и есть веб-приложение Flask или Fastapi (на них пишутся функции).
Перед нами монолит, не являющийся хорошей практикой, но это решение оправдано. Ведь так можно избавиться от потерь времени на холодном старте.
Схема организована следующим образом:
Третья строчка на схеме определяет работу с базой данных. В ней лямбда-функция подключена к базе данных через RDS Proxy. Это хорошая практика, ведь инстанций в лямбде может быть множество. То есть в базу данных будут поступать десятки обращений. RDS Proxy помогает избежать возможных проблем. Прокси собирает все подключения от лямбда-функции и устанавливает единое подключение к реляционной базе данных.
Поскольку в этой схеме отсутствуют Gunicorn, Nginx или Apache, разработчику достаточно подключить какую-нибудь библиотеку. Есть только способ handler для обработки реквеста от API Gateway.
Например, для Flask этот способ — Lambda middleware, подключаемая к Flask-применению. Он трансформирует ивент от API Gateway в нечто более читающее и похожее на WSGI-реквест от вашего HTTP-сервера.
Для асинхронных фреймворков типа Fastapi существует несколько библиотек, которые запускают программу в асинхронном цикле. Внутри цикла они также трансформируют ивент от API Gateway в объект, альтернативный ASGI-реквесту.
Самый низкий пример на схеме показывает загрузку пользователем файлов непосредственно в S3 в обход эндпойнта и лямбда-функции. В ответ на ей ивент срабатывает определенный триггер. Он вроде говорит: нужно сохранить информацию о загруженном файле в базу данных и метаданные вроде времени загрузки. Все это записывается в ивент, который формируется в S3. Лямбда-функции остается только получить эти данные и записать их в реляционную базу данных.
На мой взгляд, это самый удобный и гибкий инструмент для написания лямбда-функций. Он разработан и поддерживается Amazon.
SAM состоит из двух частей:
Причем, это необязательно должна быть лямбда-функция. Допустимы как serverless-ресурсы, вроде DynamoDB и Aurora, так и обычные амазонские. Также здесь можно расписать все роли с правами доступа.
Основная консольная утилита для работы с аккаунтом. Если работаете с TensorFlow, возможно, вам понадобится генерировать креды и токены. Их можно прописать с помощью этой утилиты. Практически все фреймворки для разработки лямбда-функций — надстройка AWS CLI.
Своеобразный шаблон, где описываются нужные ресурсы. Serverless Framework поддерживает работу с Azure и Google Cloud.
Одновременно консольная утилита и Python библиотека для разработки serverless-приложений. В этом случае вам не нужно описывать свойства ресурсов в шаблонах, как это необходимо с YAML.
Все операции выполняются с помощью декораторов, предоставляемых функциям, написанным в Chalice. Далее эта утилита перед деплоем с помощью консоли подхватывает все данные и разворачивает. Очень удобно и быстро.
Мощный фреймворк для фулстек-разработки. Представляет собой консольную утилиту с набором библиотек для фронтенда. К примеру, можно разработать сервис для авторизации пользователей без понимания принципов работы самого AWS.
Вам достаточно прочитать документацию, чтобы за несколько операций в консоли создать Amplify At Authorization. Потом так же читаете документацию с фронтенда — и в самом проекте импортируете, например, класс для React. Он уже реализует форму авторизации и локально сохранит токен.
Правда, из-за определенных ограничений это иногда работает «на костылях». Например, в SAM можно вписать в шаблон нужные ресурсы, чтобы утилита сама генерировала все необходимое. А у Amplify в принципе нет такой реализации. Если вы впишете что-то самостоятельно, то при последующем обновлении ресурса или изменении его свойств система все сотрет. Итак, используйте этот фреймворк осторожно.
Этими инструментами работа с лямбда-функциями не ограничивается. Да и сама тема AWS Lambda гораздо шире. Поэтому советую вам не останавливаться на базовых понятиях и постоянно пробовать что-то новое. С лямбда-функциями вы обязательно получите широкие возможности для улучшения своего проекта.
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}