Привет! Меня зовут Андрей Годяцкий и я Senior Software Engineer PHP в украинской продуктовой IT-компании Appflame. В этой статье я хочу рассказать о двух кейсах реиндекса/ремапинга или, как принято в SQL, миграции:
Статья будет интересна тем, кто работает с ElasticSearch и базами пользователей под большой нагрузкой, где очень важна актуальность информации и ее постоянное обновление. А также тем, у кого есть необходимость в стабильной рабочей базе без просадок/даунтаймов/остановок, чтобы можно было создать желаемую структуру индекса в процессе работы без каких-либо отображений на клиентской части.
В этой статье я расскажу о двух кейсах реиндекса в нашем приложении для знакомств Hily. Оно насчитывает около 25 миллионов пользователей в мире и работает на рынках Tier 1
В какой-то момент возникла продуктовая необходимость изменить структуру данных одной секции и определенных типов данных в ней. Для решения этих задач нам нужно было провести реиндекс.
При запуске первого реиндекса нам нужно было остановить все наши воркеры, которые поставляли данные в ElasticSearch, обновляли и записывали туда новую информацию. Поэтому мы столкнулись с такими проблемами:
В результате такой операции мы получили просадку около 20% практически по всем продуктовым метрикам, выросли дубликаты действий (ивент, повторявшийся несколько раз из-за того, что временно не обновлялись данные в ElasticSearch), появился риск потерять некоторых клиентов: пользователь зашел, не увидел релевантных пользователей, не получил желаемой активности, вышел и удалил приложение.
Была еще одна проблема: мы не знали, сколько времени понадобится, чтобы провести реиндекс на проде. На проде у нас большая база — около 25 миллионов пользователей, а на стейдже
Если на стейдже мы запустили реиндекс и он состоялся через пять минут, то на проде этот процесс занял около двух часов!
Мы не могли просто взять и стопнуть его, потому что тогда бы у нас получились одни индексы битые с уже переработанной структурой, а другие — со старой структурой. У нас была бы каша, которую нужно бы «расхлебывать» повторным запуском операции реиндекса.
Когда завершился процесс реиндекса, все воркеры снова заработали и данные начали обновляться. Но эти два часа остались с просадкой. Со временем все процессы возобновились и в течение нескольких часов мы догнали все метрики по пользователям.
После того, как у нас произошла просадка, появился вопрос: как нам в будущем провести реиндекс без просадок?
Мы нашли для себя такое решение: создать копию индекса с новой структурой
Я написал скрипт, который занимался всем этим процессом: создал новый индекс и команды для ElasticSearch, который должен был переливать данные из старого индекса в новый, параллельно изменяя/обновляя их структуру в соответствии с продуктовыми потребностями.
Таким образом мы получали данные из старого индекса в новом и с новой структурой. Но что делать с данными, прилетающими в старый индекс, но уже перемещенными операцией реиндекса? Для решения такой задачи пришло решение дублирования операций CUD в новый индекс. Такая схема позволила нам работать без остановки воркеров на CUD и смогла сохранить максимальную актуальность данных в процессе реиндекса.
Когда ElasticSearch закончил процесс перелива данных из старого индекса в новый, мы получили абсолютно валидные данные в обеих версиях и ничего не потеряли. В этот момент мы выполнили команду переключения alias. Система начала работать с новым индексом, и все запросы CRUD
Если раньше во время первого реиндекса операции «обновить/вставить/удалить» были приостановлены и вообще не состоялись (происходило только получение данных), то в процессе с новым индексом все операции выполнялись во время процесса реиндекса.
Для новых и существующих пользователей все работало так, как нужно. Если во время реиндекса существующий пользователь получал активность, менял свои данные — алгоритм получал всю информацию и учитывал ее.
Таким образом во время второго реиндекса мы смогли сохранить актуальность данных и релевантность выдачи пользователей.
Но мы решили пойти дальше и подумали: как мы можем оптимизировать скорость реиндекса?
В ElasticSearch есть возможность конфигурировать (Slicing), сколько процессов реиндекса он запустит для того, чтобы переливать данные из старого индекса в новый. Мы нарезали больше процессов, благодаря чему скорость увеличилась и переливание данных произошло не за два часа, а за час.
В ElasticSearch есть понятие версий документа. Например, если пользователь зарегистрировался в нашем приложении, создается документ с версией 1. Этот документ содержит всю информацию, которую ввел пользователь (имя, возраст, предпочтения и т.п.). Если этот пользователь обновил или добавил информацию, создается документ с версией 2, 3 и т.д.
В момент переливания (реиндекса) мы могли столкнуться с конфликтом версий — это когда ElasticSearch пытается вставить документ более старой версии (например, 4), а в базе уже существует новая версия (5). Это может произойти тогда, когда мы дублируем все процессы в новый индекс.
Поскольку конфликт версий обрывает процесс реиндекса, выбрасывая ошибку, то нам следует избегать таких случаев, так как процесс нужно будет начинать сначала.
Для решения этого вопроса мы переключили опцию conflicts в значение proceed, что позволило продолжить процесс без прерывания, игнорируя этот конфликт. Для нас игнорирование никак не отразилось на актуальности данных, так как в новом документе была вся необходимая актуальная информация.
Когда мы перелили все данные из старого индекса в новый и полностью переключились в работе на него, старый индекс остался неактивным.
Мы проверили, чтобы продуктовые метрики были в норме, чтобы не было никаких просадок после перелива и никаких проблем с новым индексом, после чего удалили старый индекс.
Смысл переключаться назад на старый индекс и сохранять его есть только тогда, когда операция реиндекса не состоялась и этот процесс оборвался по какой-то технической причине.
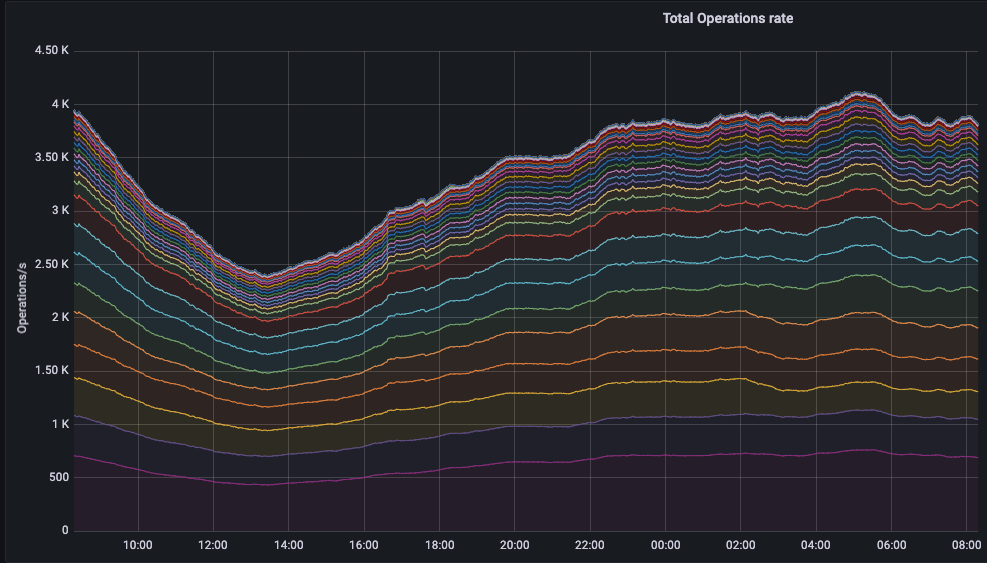
До начала и в процессе второго реиндекса мы следили за:
Наша бэкенд-команда следила за этими мониторами в момент реиндекса, чтобы в случае возникновения проблемы отключить процесс, понять, что это за проблема, и быстро пофиксить ее. Мониторы очень помогают нам держать наше приложение в нормальном рабочем режиме.
Наши девопсы подняли отдельный сервер, на котором они развернули ElasticSearch со всей базой. Это была полностью настроенная тестовая среда, похожая на наш бэкенд на проде — тот, на котором у нас сейчас работает приложение.
Я написал скрипты, которые нагружали ElasticSearch, имитируя операции CRUD, подобные проду, на нашу тестовую среду. Таким образом мы создали нагрузку, схожую с продакшен-средой.
В это время под этой нагрузкой я запустил процесс реиндекса. Он прошел прекрасно. На этом этапе мы еще поймали пару нюансов и ошибок, которые пофиксили. Эта тестовая среда дала нам понимание, что мы можем спокойно выкатывать все на продакшен.
Я не могу сказать, что это привычный для нас подход, мы такие операции делаем очень редко. Это недешевое удовольствие — нужно на время арендовать большие мощные серверы, развернуть и настроить там среду. Но именно благодаря такому тестированию можно понять, какую оптимизацию получишь на продакшене, поймать пару неявных багов и убедиться, что можно ехать на прод, ведь система четко работает даже под нагрузкой.
Здесь ключевой момент в нагрузке. Дело в том, что на своих локальных компьютерах и даже на обычных тестовых средах мы не можем создать такую сильную нагрузку — у них нет такой мощности, чтобы выдерживать такие тяжелые условия. До этого я не слышал и не видел, чтобы в компаниях создавалась отдельная среда для тестирования под нагрузкой. Это был классный опыт.
Мы запускали скрипт в то время, когда у нас наименьшая загрузка на наших серверах: для нас это 12 часов дня по киевскому времени. Когда происходил второй реиндекс было очень классно наблюдать, что все бизнес-метрики идут ровно, что наши пользователи используют приложение, не замечая, что у нас что-то происходит, что для них все выглядит так же, как и раньше.
Ну и процесс произошел в два раза быстрее: мы совершили реиндекс за час, при этом никаких просадок метрик не получили. Все было тихо, классно, чисто.
Сейчас, сравнивая первый и второй реиндекс, я мог бы поделиться несколькими советами.
Если перед вами стоит сложная задача, это еще не значит, что вызов нужно принять. Возможно, есть другие, более простые решения, а может, этот сложный путь вообще надуманный, ненужный и не сделав этот шаг вы ничего не потеряете и наоборот сэкономите кучу ресурсов. Ваши потраченные усилия должны быть оправданы полученным результатом. Убежден, что это касается всего: вас лично или бизнеса, в котором вы работаете.
Бывает так, что покрытие тестами (smoke, acсeptance, unit, integration, manual, automation и т.п.) — недостаточное, и реальную картинку можно увидеть только под нагрузкой, подобной реальной среде.
Очень круто, если есть возможность сделать тестовую среду, приближенную к проду, и на ней погонять сложные операции. Не проводить тест и исправлять ошибки после их проявления на проде часто получается в разы дороже.
Очень вероятно, что у вас появится решение проще или исчезнет необходимость выполнения такой задачи, потому что найдется другое решение. В таком случае вы прислушаетесь к нашему первому совету 🙂 Также вы сможете учесть конфликт версий, подумать, как можно оптимизировать скорость реиндекса и что еще можно сделать более эффективно.
Поделитесь, пожалуйста, своим опытом: как вы проводите реиндекс? Также было бы интересно узнать, как у вас происходит тестирование нагруженных систем и сложных операций до того, как вы залили код в прод. Есть ли у вас тестовая среда, и как вы понимаете, что все пройдет отлично?
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}