Вы никогда не задумывались над тем, как много новой информации появляется ежедневно в интернете? Простейшие события, скажем, открыли страничку Facebook или просто проверили поступившую почту на ящик Gmail — ведут к увеличению объема данных. Это огромное количество информации, которая где-то записывается, растет и растет.
Музыка, видео, фотографии, текстовые сообщения, различные лог-файлы, программные уведомления в смартфоне и данные о каждом действии пользователя, начиная с его авторизации в интернете и заканчивая статистикой просмотра товаров в магазине — это все имеет совокупное название Big Data. А, ведь, еще есть масса других данных, которые появляются «сами собой» — ежедневный прогноз погоды, сведения о дорожных заторах, данные об анализах пациентов, спутниковые снимки и пр.
Зачем нужно накопление этих данных, а также о возможностях их обработки — в нашей подробной статье о Big Data.
Содержание:
Что такое большие данные
Характеристики Big Data
Сферы применения Big Data
Методики анализа и поиск зависимостей
Принципы Big Data (MapReduce, NoSQL, Hadoop)
Блокчейн vs Big Data
Примеры успешных проектов блокчейна и больших данных
Заключение
Многие не любят термин «большие данные», считая его понятием, навязанным маркетологами. Тем не менее, этот феномен объективно существует и он захлестнул нашу жизнь с 2008 года, когда этот термин впервые упомянул в своей статье Клиффорд Линч.
Говоря простым языком, Big Data — это огромные массивы данных (терабайты, петабайты и т.д.), часто неупорядоченных, которые невозможно обработать традиционными методами с использованием человеческого ресурса и настольных компьютеров. Говоря чуть более строго, это обозначение структурированных и неструктурированных данных огромных объемов и значительного многообразия, эффективно обрабатываемых горизонтально масштабируемыми программными инструментами.
Большие данные также невозможно анализировать обычными статистическими методами. С такой задачей не справится один компьютер, и на их основе не сможет сделать правильный вывод даже очень опытный аналитик. Трудность работы с такой информацией объясняется не только ее колоссальным объемом, но и постоянным ростом в геометрической прогрессии. Кроме того, задачу усложняет масса косвенных факторов, определяющих результат, которые также следует учитывать при анализе данных.
Для описания больших данных выделяется три основных характеристики, так называемая парадигма трех «V»: Velocity, Volumе и Variety. Volume — это объем данных, с которыми приходится иметь дело, Velocity — скорость их разрастания и, наконец, Variety — вариативность информации.
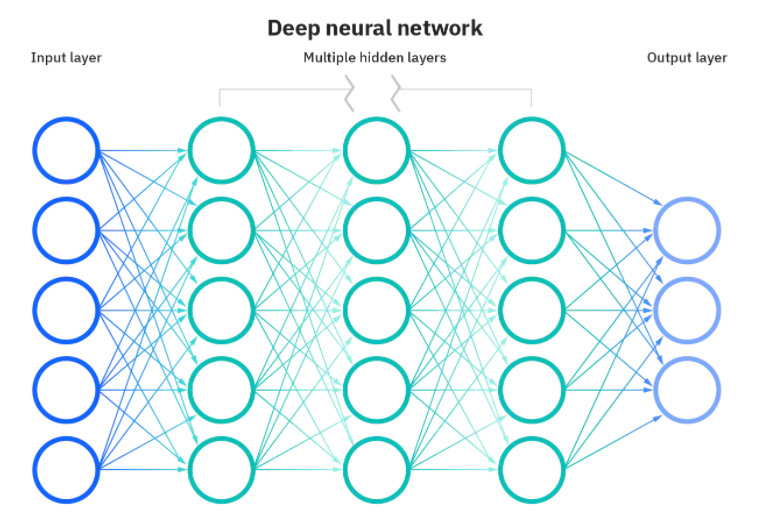
Термин Big Data — относительно молодой, поскольку ранее у человечества просто не было вычислительных мощностей, достаточных для анализа этих данных. Сегодня обработка информации выполняется не одним компьютером и не одним человеком, а целой сетью объединенных компьютеров, которые имитируют работу головного мозга человека — искусственный интеллект.
Под искусственным интеллектом мы понимаем нейронную сеть, то есть некоторую математическую модель, которая позволяет выполнять параллельные вычисления, выполняя анализ большого количества факторов влияния.
Результатом такой обработки чаще всего становится прогнозирование. Например, составив матрицу предпочтений для разных возрастных категорий, искусственный интеллект способен определить, будет ли спрос на новый продукт, а также определить параметры аудитории, которая будет в нем заинтересована.
Когда ваш мобильный оператор предлагает новый тариф, он его берет не с потолка, а именно прогнозирует с помощью нейросетей. Огромную роль во всем играет машинное обучение — главный принцип настройки нейронных сетей.
Машинное обучение состоит в том, что сеть получает выборку значений, ту самую «биг дату», а затем на основе исходных данных компьютерный интеллект ищет статистические закономерности и связи между событиями и сопутствующими факторами.
Во всем этом есть некоторая магия, которая порой не укладывается в голове.
Результат обработки данных может быть совершенно неожиданным и, даже, может казаться нелогичным.
Так, например, разработчики «Яндекса» проводили исследование на предмет того, как влияют предпочтения в еде на совместимость характеров между мужчиной и женщиной. Логика нам подсказывает, что если интересы совпадают, то это хорошо.
А что показывает анализ данных? Если парень и девушка вегетарианец, то процент вероятности того, что у них сложатся отношения, действительно, достаточно велик. А, вот, если они оба предпочитают еду из фастфуда, то, оказывается, очень велика вероятность, что отношения между такими людьми не сложатся. Почему? Видимо, есть какая-то связь. Об этом упрямо говорят результаты обработки данных нейросетью. Да, это магия, объяснить которую зачастую невозможно.
Прогнозировать можно что угодно. Еще один пример, где очень важно предсказание — это составление кредитной истории. Предположим, банк получил запрос на предоставление кредита. Как ему решить, давать деньги или нет? Надежна ли личность, которая его запросила или нет?
В этом случае в дело вступает нейросеть, которая с помощью десятков всевозможных поведенческих маркеров проводит скоринг человека и безошибочно определяет — доверять ему или нет. Среди факторов, которые принимаются во внимание — доход этого человека, пол, а также прочие данные, известные банку — наличие детей, уровень дохода, занимаемая должность и т.д.
По тому же принципу в супермаркете формируются акции на те или иные группы товаров. Если предположить, что покупатель приобретает товары из секции «здоровое питание», то, возможно, его заинтересуют скидки на авокадо или зелень. А, если покупатель берет кофе, то через месяц, когда у него этот кофе предположительно закончится, ему можно предложить другой, «по акции».
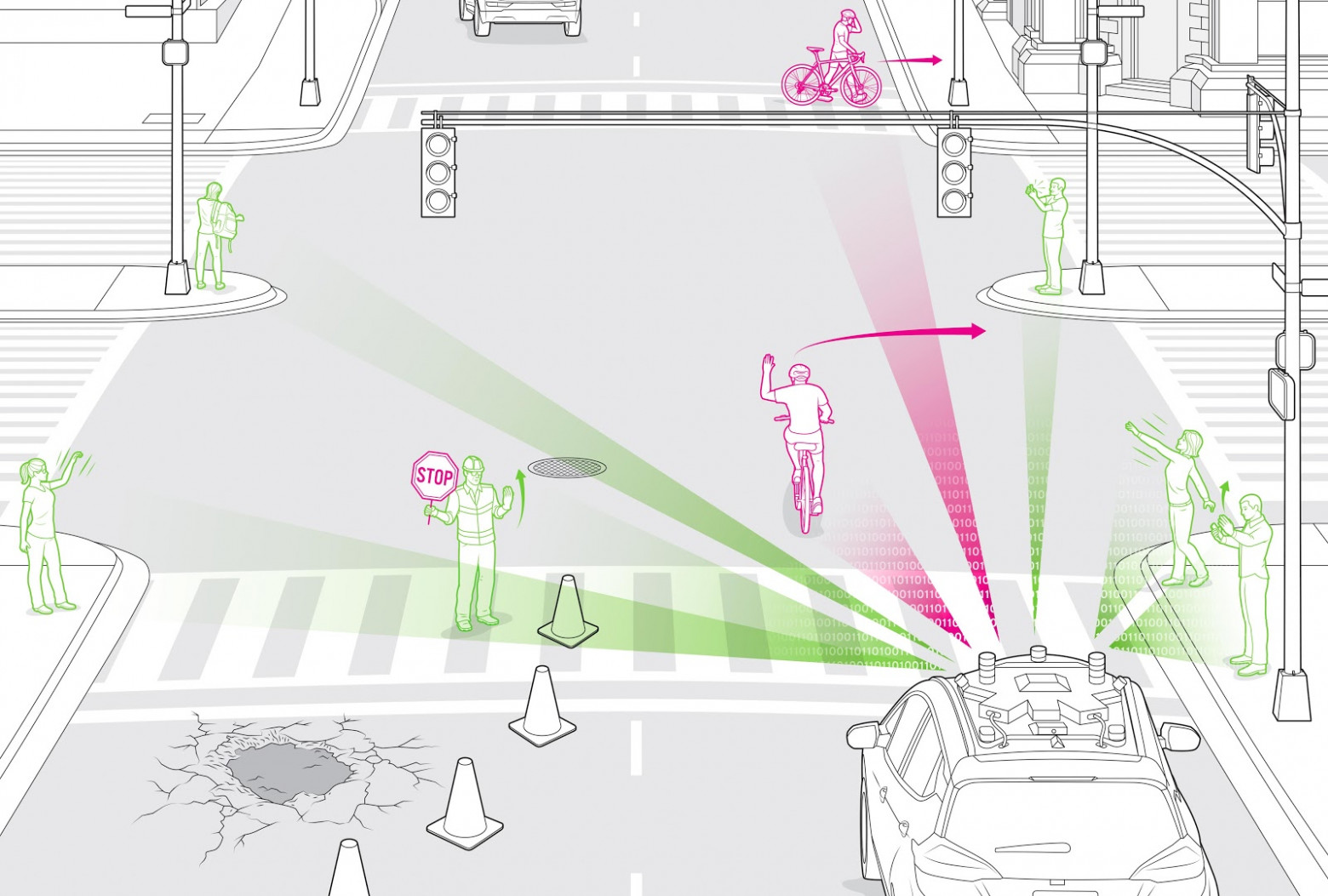
Обработка Big Data позволяет спрогнозировать чрезвычайные ситуации и минимизировать человеческие жертвы. Искусственный интеллект способен предсказывать землетрясения, ураганы и прочие погодные катаклизмы. Машинное обучение используется при создании систем беспилотного транспорта. Помимо понимания карт и ориентирования на местности, автомобиль учится определять препятствия, а также понимать дорожные знаки и, даже, жесты прохожих.
Обработка Big Data позволяет спрогнозировать чрезвычайные ситуации и минимизировать человеческие жертвы
Отдельная область применения больших данных — для распознавания речи и образов. Эта задача реализуется на нейронной сети, с использованием глубокого обучения.
Чтобы научиться «видеть», сеть должна обработать массив изображений. Чем больше она пропустит через себя выборку, тем точнее будет результат. В связи с этим, хочется вспомнить недавнее исследование сотрудников Массачусетского технологического института. Работая с машинным обучением, они выявили, что как только нейронная сеть набирает достаточно опыта, чтобы решать задачи, она начинает торопиться и допускать ошибки, полагая, что уже хорошо «видит».
Чтобы научить такую сеть хорошо идентифицировать корову на зеленой поляне, разработчикам пришлось изменить входные условия. Если сеть дольше смотрела на изображение, количество ошибок заметно снижалось. Это только лишний раз показывает, насколько искусственный интеллект поведенчески приблизился к реальному.
Как это работает на практике? Рассмотрим элементарный пример, позволяющий понять, суть анализа данных.
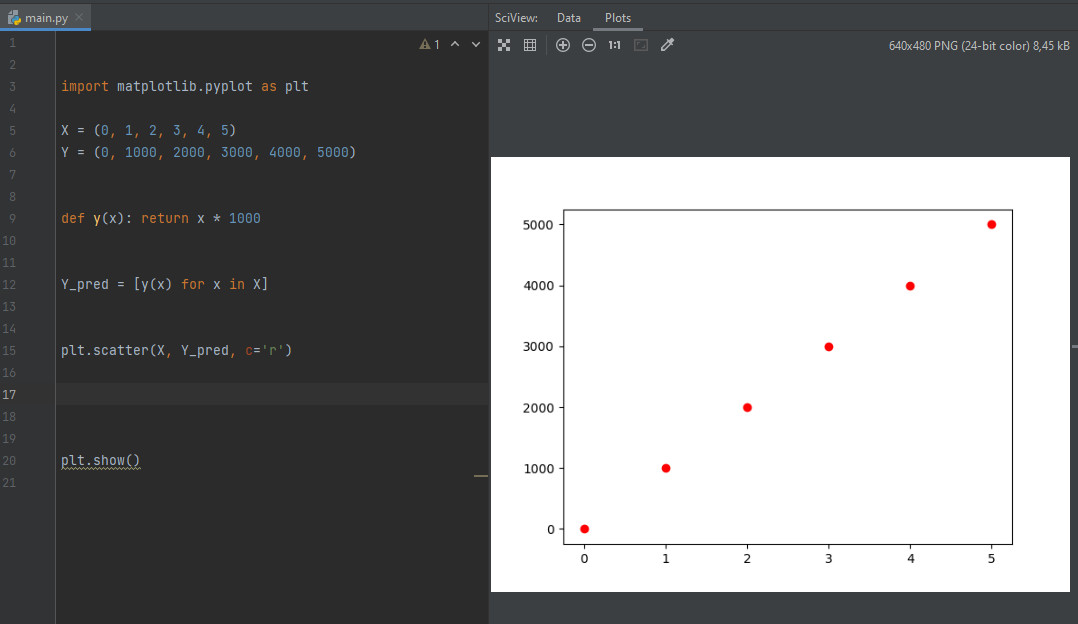
Предположим, у вас есть некоторые данные — результаты проведенных экспериментов. Чтобы выполнить прогнозирование, необходимо установить зависимость между этими данными. Допустим, вы получили в свое распоряжение массив данных с опытами по растягиванию пружины. Вы имеете два типа данных: Y — сила, которая прикладывалась к пружине и X — длина ее деформации при этом. Попробуем представить эти данные в виде графика.
Визуализируем эту информацию на Python, используя библиотеку matplotlib (для установки выполним команду pip install matplotlib)
Далее — заведем массив данных и построем точечный график.
import matplotlib.pyplot as plt X = (0, 1, 2, 3, 4, 5) Y = (0, 1000, 2000, 3000, 4000, 5000) plt.scatter(X, Y_pred, c='r') plt.plot(X, Y_pred) plt.show()
Как видите, эти данные, с определенной погрешностью, располагаются вдоль прямой линии. Из этого можно сделать вывод, что все данные подчиняются одной и той же линейной зависимости. Построив ее, мы можем сделать относительно точный прогноз — какую силу нужно приложить, чтобы растянуть пружину на заданную длину.
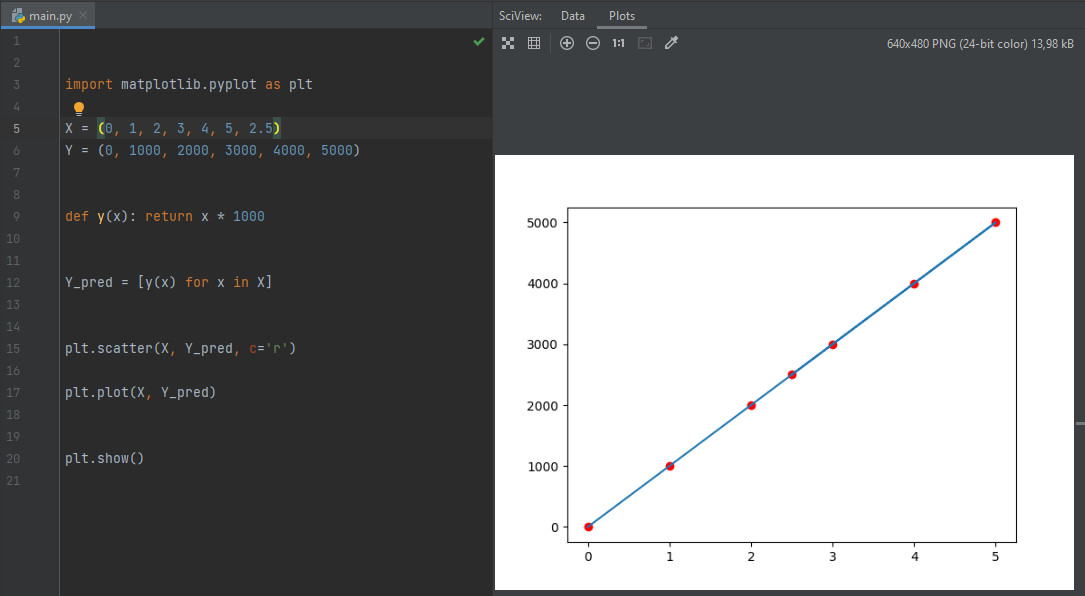
Из графика мы видим, что любая деформация помноженная на некоторый коэффициент (в нашем случае — 1000) дает результат. Таким образом, очевидно, что если взять график этой функции для нового «эксперимента», мы без труда найдем нужную точку — «предсказав» результат.
import matplotlib.pyplot as plt X = (0, 1, 2, 3, 4, 5, 2.5) Y = (0, 1000, 2000, 3000, 4000, 5000) def y(x): return x * 1000 Y_pred = [y(x) for x in X] plt.scatter(X, Y_pred, c='r') plt.plot(X, Y_pred) plt.show()
Разумеется, это очень упрощенный вариант того, как работает Data Scientist. Зачастую определить зависимость очень сложно, да и графики для ее определения, порой, приходится делать трехмерными, чтобы получить специфический срез. Однако, принцип прогнозирования остается тем же.
Чтобы определить зависимость, повсеместно используется машинное обучение. В результате обработки данных нейронная сеть автоматически вычисляет зависимости. Механизмы, высчитывающие закономерности, базируются на теории алгоритмов, математическом анализе, линейной алгебре и статистике.
В отличие от традиционных средств обработки информации, данные Big Data невозможно обрабатывать на одном компьютере и, тем более, в Excel.
Чтобы можно было просчитать любой массив больших данных, необходимо выполнение ряда условий. Во-первых, это масштабируемость системы. В каждом кластере аппаратная поддержка должна увеличиваться пропорционально объему данных. Увеличились данные — выросло количество железа. Из этого следует второе условие — отказоустойчивость системы. При использовании большого количества компьютеров, вероятность выхода из строя одного из них — достаточно велика и это событие не должно влиять на систему.
Например, в кластере сети Facebook используется около 2 тыс. узлов на 21 Пбайт, а в eBay — 700 узлов на 16 Пбайт.
По возможности, все данные подчинены принципу локальности — чтобы избежать затрат ресурсов на трансфер биг даты. Обработка идет преимущественно на тех же вычислительных узлах, где данные и хранятся.
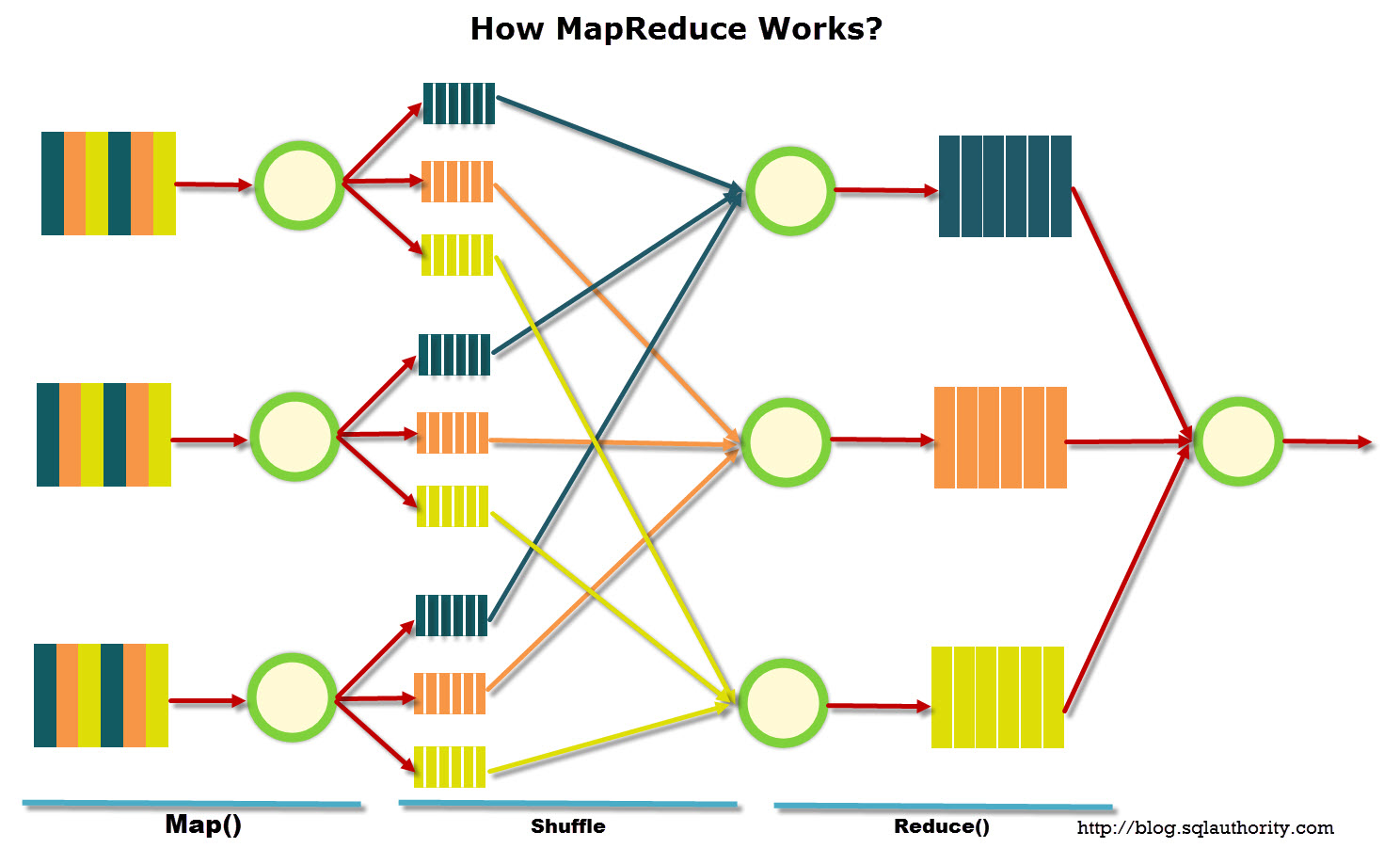
Распределенные вычисления требуют особой организации исходных данных. Часто для использования в больших массивах данных, вплоть до петабайт (десять в пятнадцатой степени байт) используется модель, предложенная компанией Google, которая называется MapReduce.
По возможности, все данные подчинены принципу локальности — чтобы избежать затрат ресурсов на трансфер биг даты. Обработка идет преимущественно на тех же вычислительных узлах, где данные и хранятся.Распределенные вычисления требуют особой организации исходных данных. Часто для использования в больших массивах данных, вплоть до петабайт (десять в пятнадцатой степени байт) используется модель, предложенная компанией Google, которая называется MapReduce.
Данный фреймворк включает в себя несколько этапов «сортировки» исходных данных. Сначала главный узел кластера, называемый master node, «просеивает» информацию, создавая так называемые пары ключ-значение. Эти пары он передает рабочим узлам кластера (node) и уже они сортируют данные, так сказать, по корзинам.
Визуально это можно себе представить так: система сортирует студентов по имени, составляя очереди, одна очередь для каждого имени. Далее идет сокращение объема данных, например, подсчет количества студентов в каждой очереди, с указанием частоты того или иного имени.
Данные, собираемые в массив, хранятся в специальных нереляционных СУБД с возможностью доступа посредством языка SQL. В таких системах управления базами данных проблема масштабируемости и доступности решается за счёт полного или частичного отказа от требований атомарности и согласованности данных.
Называются такие системы NoSQL. Они существуют с конца 1960-х годов, но само название «NoSQL» было придумано только в начале XXI века, с появлением концепции Web 2.0, когда объем информации резко возрос.
Одним из инструментов для реализации поисковых и контекстных запросов для ресурсов с высокой загруженностью стала разработка Apache Hadoop, бесплатный набор утилит, библиотек и фреймворк. Он используется, например, Facebook и Yahoo!, а также в других проектах распределенных вычислений, для применения на кластерах из сотен и тысяч узлов.
Говоря о больших данных, нельзя обойти стороной тему технологий распределенного реестра — блокчейн. В некоторых случаях совместное использованием блокчейна и больших данных дает выгоду. Однако, несмотря на некоторую схожесть, блокчейн и Big Data — совершенно разные технологии. В первом случае — это копии информационных цепочек, которые хранятся на множестве компьютеров, во втором случае — интегрированная информация из разных источников, объем которой намного превышает размеры данных, с которыми связан блокчейн.
Кроме того, следует отметить низкую скорость работы с данными, которая определяется децентрализованным хранением и последовательным считыванием данных.
Работать с большими массивами, как в случае с Big Data, блокчейн не в состоянии. В связи с тем, что информация в блокчейне остается навсегда, глупо было бы использовать распределенный реестр исключительно для хранения, скажем, списка покупок.
Однако, есть отрасли, в которых требуются высокая достоверность и устойчивость информации, например, в сфере информационной безопасности. В этом сегменте блокчейн вполне может обеспечить требуемую стабильность системы и гарантировать достоверность данных.
Например, совместное использование Big Data и блокчейна может быть применено в здравоохранении. Благодаря блокчейну информация о здоровье пользователей, анализы и медицинские карты, данные о прививках — могут оставаться защищенными от подделок, с возможностью проверки. Кроме этого, децентрализация реестра блокчейн устраняет любые промежуточные агенты, будь то технологический брокер или страховой агент.
В перспективе объединения технологий блокчейна и Big Data появится возможность получения аналитических данных о поставках. Также можно будет просто осуществлять контроль за потерей продукции при транспортировке и препятствовать фальсификации товара, а также интегрировать транзакции.
На сегодняшний день можно выделить ряд проектов, успешно сочетающих технологии блокчейна и больших данных.
Наиболее очевидная область применения технологии Big Data — маркетинг, однако сфера применений данной технологии расширяется с каждым днем. Анализ больших данных это не всегда поиск оптимальных продаж и продвижения тех или иных сервисов и услуг.
Так, например, Google вложил крупную сумму средств на сбор и анализ данных с мобильных телефонов в рамках проекта по борьбе с малярией в Африке. Тем самым интернет-гигант помогал ученым вовремя обнаружить болезнь и остановить её распространение.
Другой большой источник нескончаемого потока данных — NASA. Эта организация держит руку на пульсе сразу большого числа проектов — от центра моделирования климата до сети телескопов и космических летательных аппаратов, которые постоянно присылают снимки в большом разрешении.
Одних только космических моделей, телеметрии, изображений и другой полезной информации, собранной в ходе планетарных миссий за последние 30 лет в архиве Planetary Data System хранится более 100 Тб.
Большие данные могут быть задействованы в любых социологических исследованиях и, что особенно важно — в информационных войнах. Не секрет, что подобная технология уже вовсю задействуется для формирования лояльной аудитории к политическим фигурам. Так, например, не секрет, что во время выборов президента США в 2016 году маркетологи Дональда Трампа использовали психолого-поведенческий анализ и персонифицированную рекламу, систематизируя интересы избирателей. В зависимости от их предпочтений им выдавались те или иные месседжи, которые подходили под их потребности, настроения, политические предпочтения и даже цвет кожи. В штабе Хиллари Клинтон опирались на классические статистические методы.
Результат говорит сам за себя — Трамп победил с большим отрывом, вложив в «раскрутку» в два раза меньше средств по сравнению с оппонентом.
Влияние на людей математической модели, просчитанной с помощью больших данных, невероятно велико и поднимает очень важный этический вопрос — где та грань, за которой личная информация перестает быть таковой и вправе ли кто-нибудь использовать подобные сведения ради выгоды. А может, проблема будет в большей или меньшей степени решена с помощью разработанного недавно протокола конфиденциального вычисления или MPC (multi-party computation). Этот протокол дает возможность обмениваться пользовательскими данными конфиденциально, т. е. вместо обмена реальной информацией между серверами ведется обмен «секретами» — исходные данные в них обработаны математическими функциями. Но это уже тема для отдельного обсуждения.
Напоследок рекомендуем посмотреть очень содержательную онлайн-лекцию на тему «Big Data в жизни современного человека» от заведующего учебно-научной лабораторией компьютерных средств обучения ТГУ Артем Фещенко:
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}