Роль машинного обучения и нейронных сетей неоценима с точки зрения бизнеса. Кажется, только ленивый не писал об их преимуществах и потенциале для роста. Но за историями успеха и растущими финансовыми показателями стоят не менее впечатляющие процессы.
Команда Data Science компании Competera поделилась с Highload примером реального бизнес-кейса, где будущий успех клиента напрямую зависел от способности модели предсказывать неизвестные исторические значения. В этой статье ребята детальнее расскажут о закулисье современных ML-решений. Передаем им слово.
Результаты, описанные в этой статье, будут в первую очередь интересны как специалистам и аналитикам Data Science, так и всем, кто интересуется современными технологиями в области ценообразования.
Американский производитель искусственных елок и украшений обратился к Competera для внедрения алгоритмов машинного обучения, чтобы оптимизировать цены на товары. Полноценному роллауту
Традиционный A/B-тест с тестовой и контрольной группами оказался невозможным из-за особенностей бизнеса — высокой сезонности. 80% годовых продаж ритейлера происходит в последние три месяца года. Так, решение можно было применить на практике только в горячий сезон следующего года.
Учитывая особенности бизнеса и запроса клиента, мы решили проверить точность алгоритмов с помощью бэккастинга
Чтобы доказать эффективность решения на основе машинного обучения, нам понадобились две вещи: модель и данные, которые будут в нее загружены.
Клиент предоставил нам:
Работа над проектом происходила в 2020 году, но объем всех необходимых исторических данных охватывал только два сезона продаж (2017-2018), а данные о транзакциях были предоставлены за 2008-2018 годы.
Клиент намеренно не делился с нами данными о продажах за 2019 год, чтобы наша модель могла доказать свою эффективность, с точностью восстановив эти данные.
Другими словами, наша предиктивная модель должна была делать прогноз так, как будто она была запущена не в 2020 году, а в начале 2019-го.
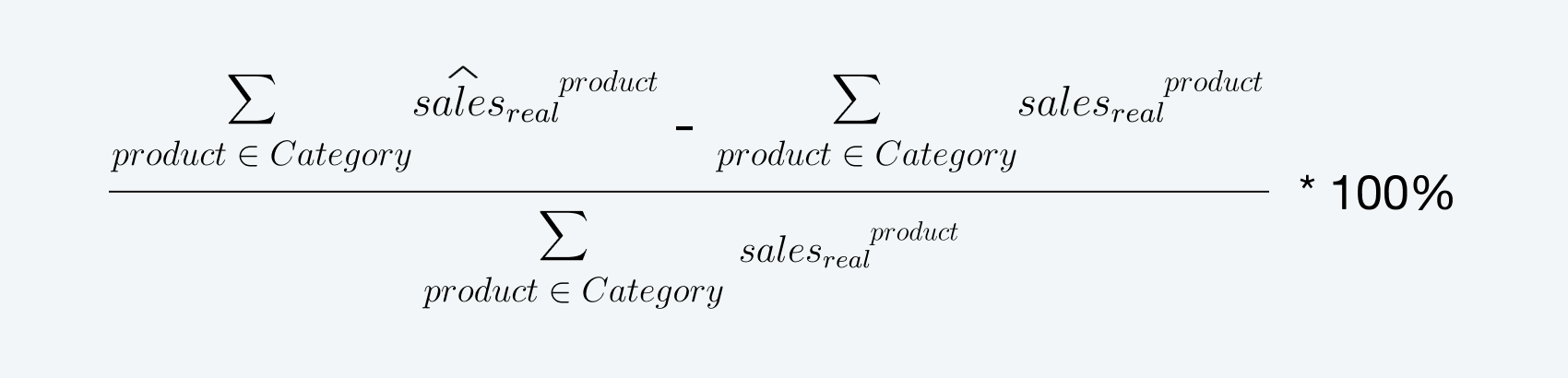
Основным критерием успеха была точность прогноза продаж и выручки за 8 недель теста высокого сезона на уровне всего ассортимента и отдельной категории (которая составляет ~30% от общего ассортимента и ~75% от общей выручки). Это могло быть представлено в следующем виде:
Процентную ошибку рассчитывали с помощью формулы:
Чтобы добиться высокой точности по заданным критериям, можно построить статистическую авторегрессионную модель для каждой из двух категорий на уровне недель, а затем, после обучения модели, агрегировать прогноз на 8 недель тестового периода и получить окончательный результат. А благодаря тому, что исторические данные о транзакциях содержали наблюдения за более чем 10 лет, модель сможет лучше изучить сезонность бизнеса.
Итак, мы построили модель SARIMA для прогнозирования. После получения реальных данных о продажах нужно было проверить точность этой модели. В результате для каждой из категорий значение абсолютной процентной ошибки на тесте составило <5%.
И хотя результаты были хорошими, модель неприменима для реального бизнеса, потому что не позволяет оценить изменение продаж на уровне отдельных единиц товара.
Конечно, можно было бы построить отдельную модель на уровне каждого продукта, но:
Теперь предположим, что вы проводите оптимизацию цен с использованием упомянутой модели прогнозирования спроса. Вы устанавливаете ценовые ограничения +- 50% от текущей цены продукта, и ваша цель — оптимизировать доход. Поскольку ваша модель не может оценить изменение продаж на уровне SKU
Предиктивная модель, которая бы одновременно была точной и применимой на практике для бизнеса, должна:
Кроме SARIMA, есть и другие авторегрессионные модели, которые отвечают заданным требованиям. Например, (S)ARIMAX и VARMA(X), которые могут помочь оценить влияние экзогенных
Тем не менее, у таких подходов есть ряд недостатков, таких как:
Исправить эти недостатки может переход от задачи прогнозирования временных рядов к построению регрессии.
Характеристики временной оси кодируются путем прямой передачи в модель лагов временных переменных, в то время как временные характеристики передаются в форме признаков для модели.
Прогноз на несколько периодов вперед можно получить с помощью рекуррентного прогнозирования. То есть основная модель прогнозирует на один период вперед, а для составления прогнозов на несколько периодов рекуррентно используются предыдущие прогнозы.
Бейслайн может быть основан на обычной линейной регрессии, нейронной сети или градиентном бустинге для задачи регрессии, который лучше всего подходит для гетерогенных (табличных) данных.
Реализованы несколько бустинговых фреймворков, которые позволяют работать с пропущенными значениями, категориальными переменными, использовать кастомные целевые функции:
Подход рекуррентного прогнозирования легко реализовать, но он требует динамического пересчета данных
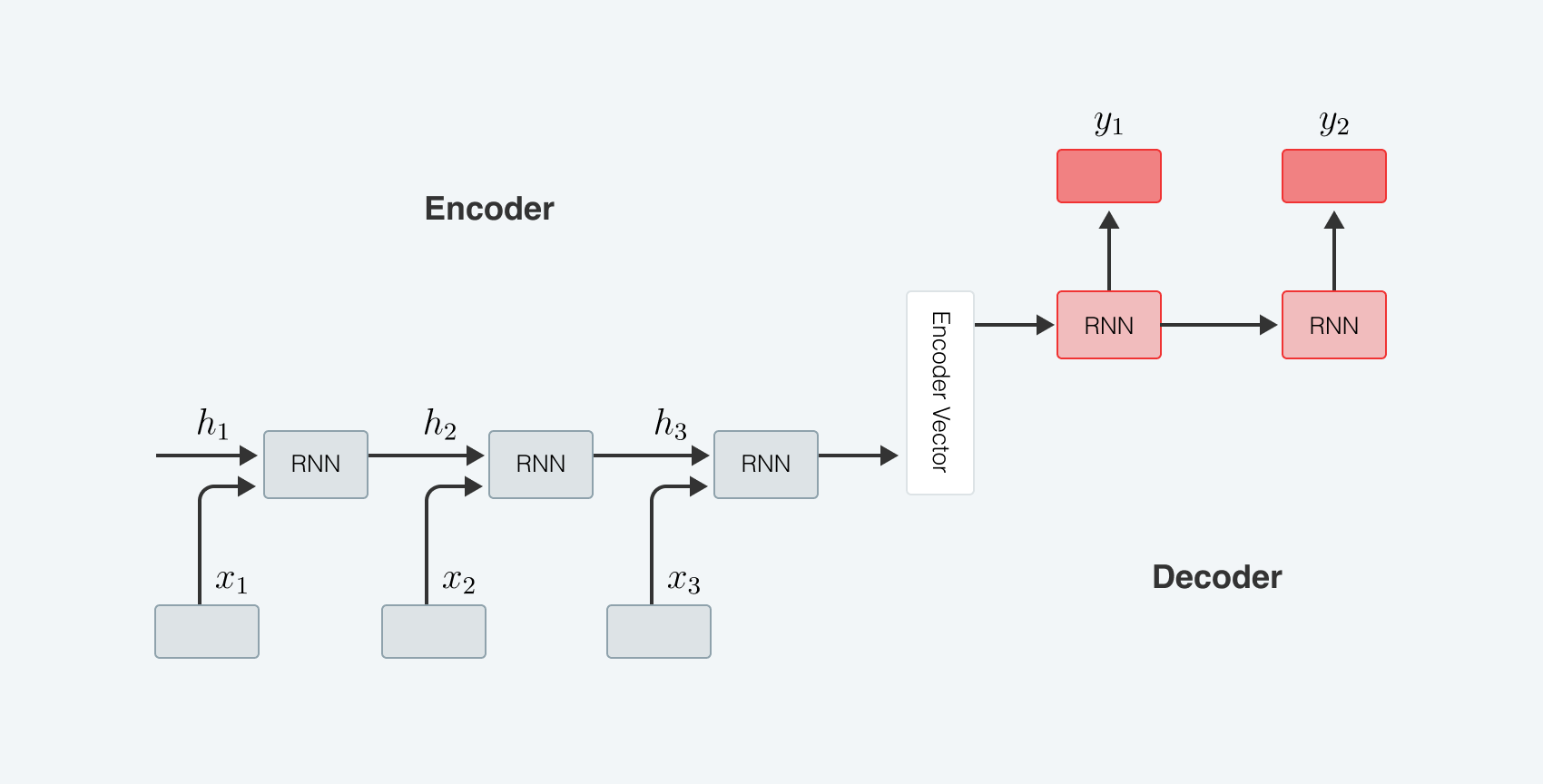
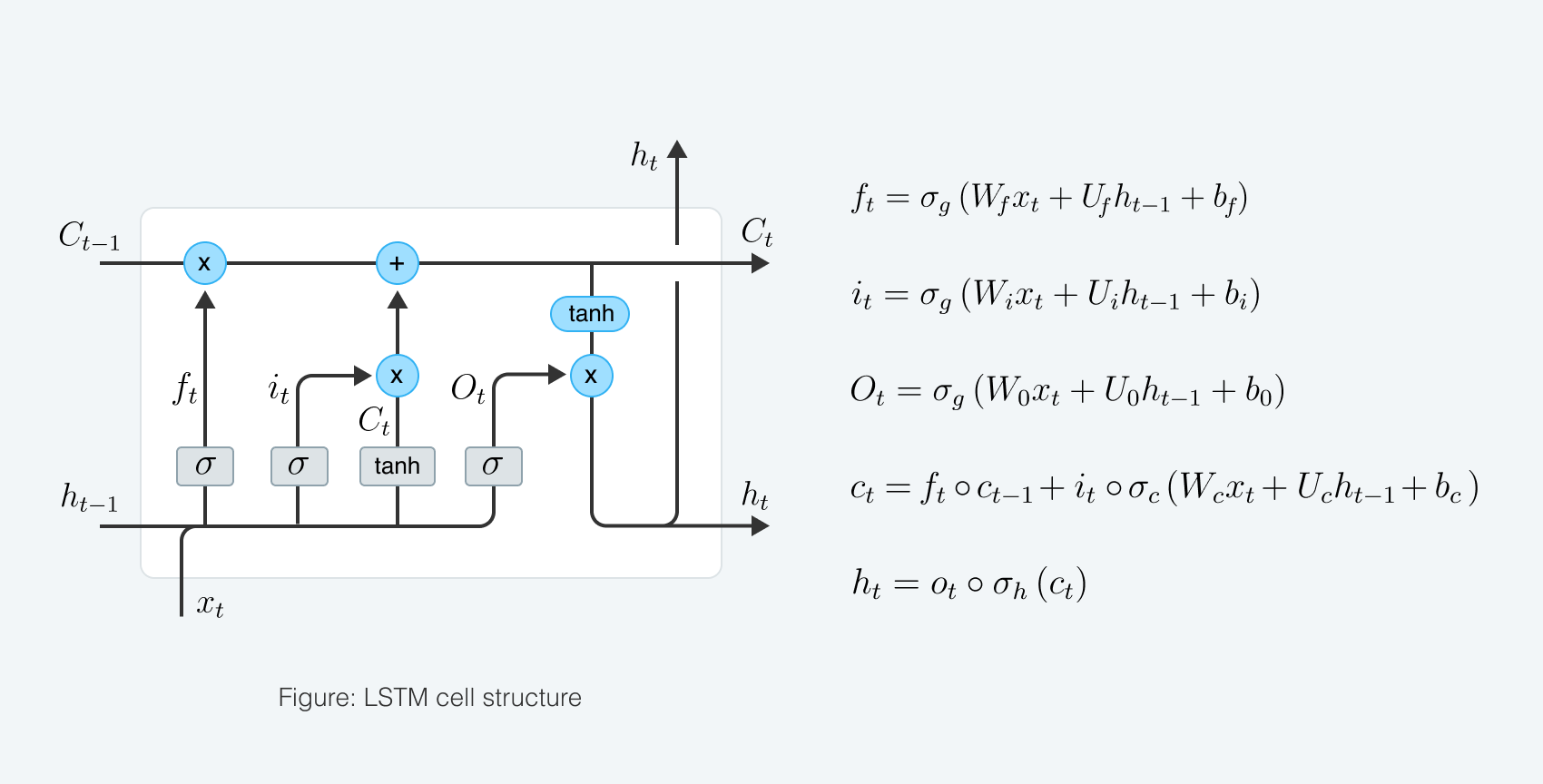
Альтернатива подходу рекуррентного прогнозирования — использование RNN
Таргетом для прогноза могут выступать, например:
Мы построили seq2seq-LSTM
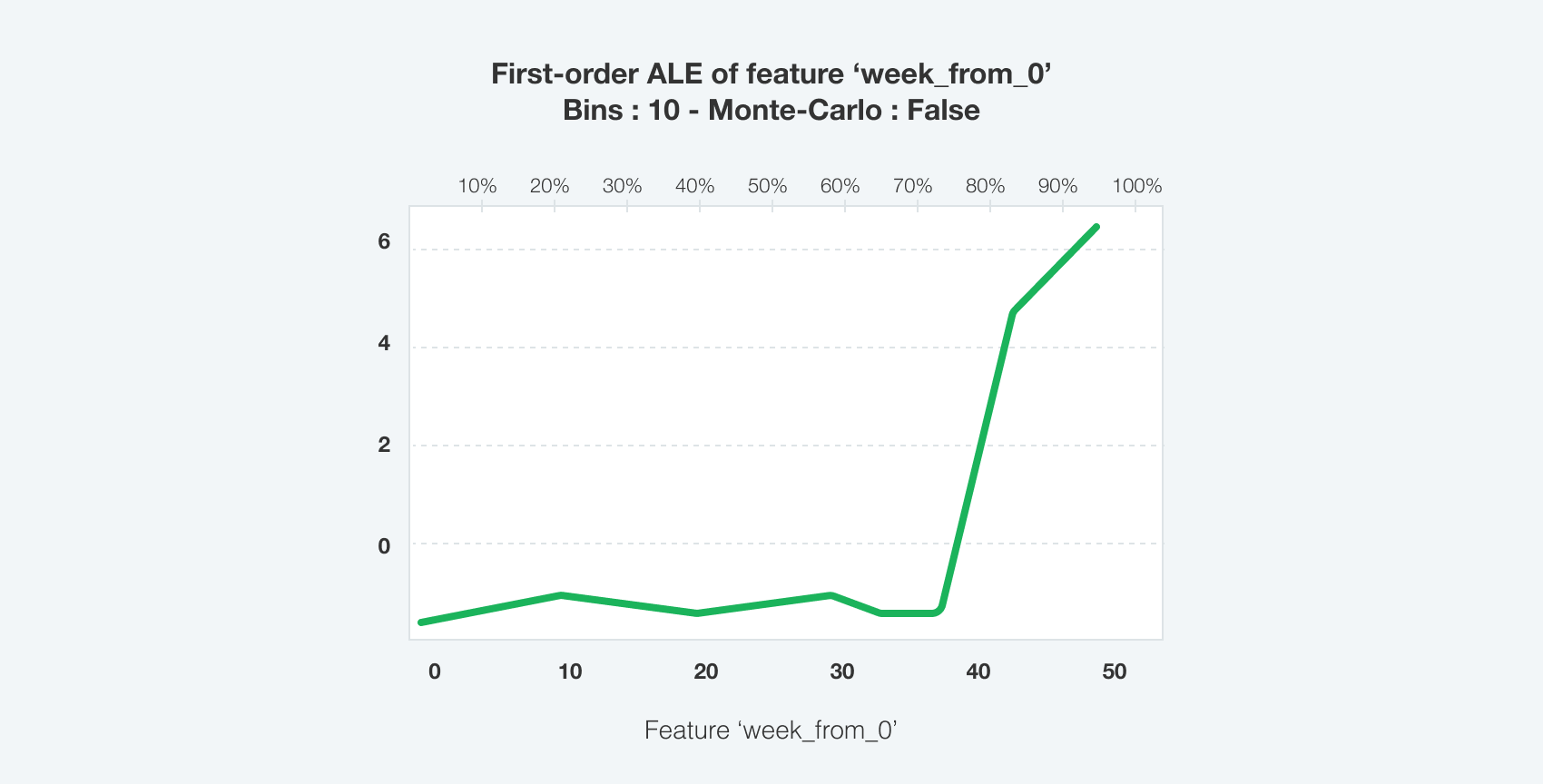
Чтобы уловить влияние зависимостей на уровне категорий, мы использовали статические эмбеддинги категорий. Такие временные характеристики, как номер недели и месяца, подавались в модель в виде динамических темпоральных эмбеддингов, что значительно повысило ее точность из-за высокого фактора сезонности данных. Накопленные локальные эффекты
Детальнее: Apley, Daniel W., and Jingyu Zhu. 2016. Visualizing the Effects of Predictor Variables in Black Box Supervised Learning Models. https://arxiv.org/abs/1612.08468; Molnar, Christoph. 2020. Interpretable Machine Learning: https://christophm.github.io/interpretable-ml-book/
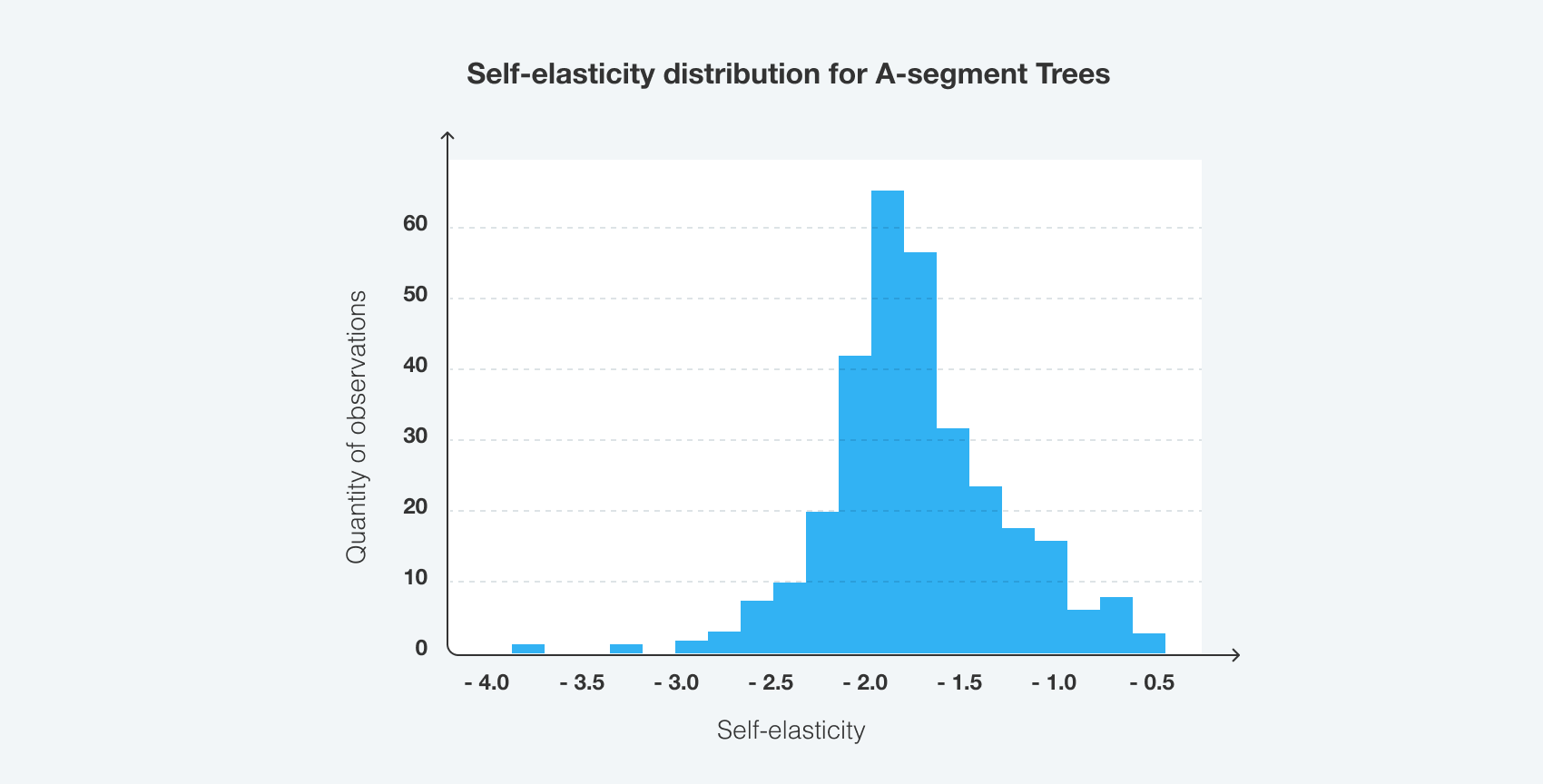
Чтобы лучше приспособить модель к потребностям бизнеса, мы использовали взвешивание наблюдений в зависимости от цен на товары, динамики продаж и временного периода. Это позволило нам получить более точные прогнозы для А-сегмента ассортимента в высокий сезон.
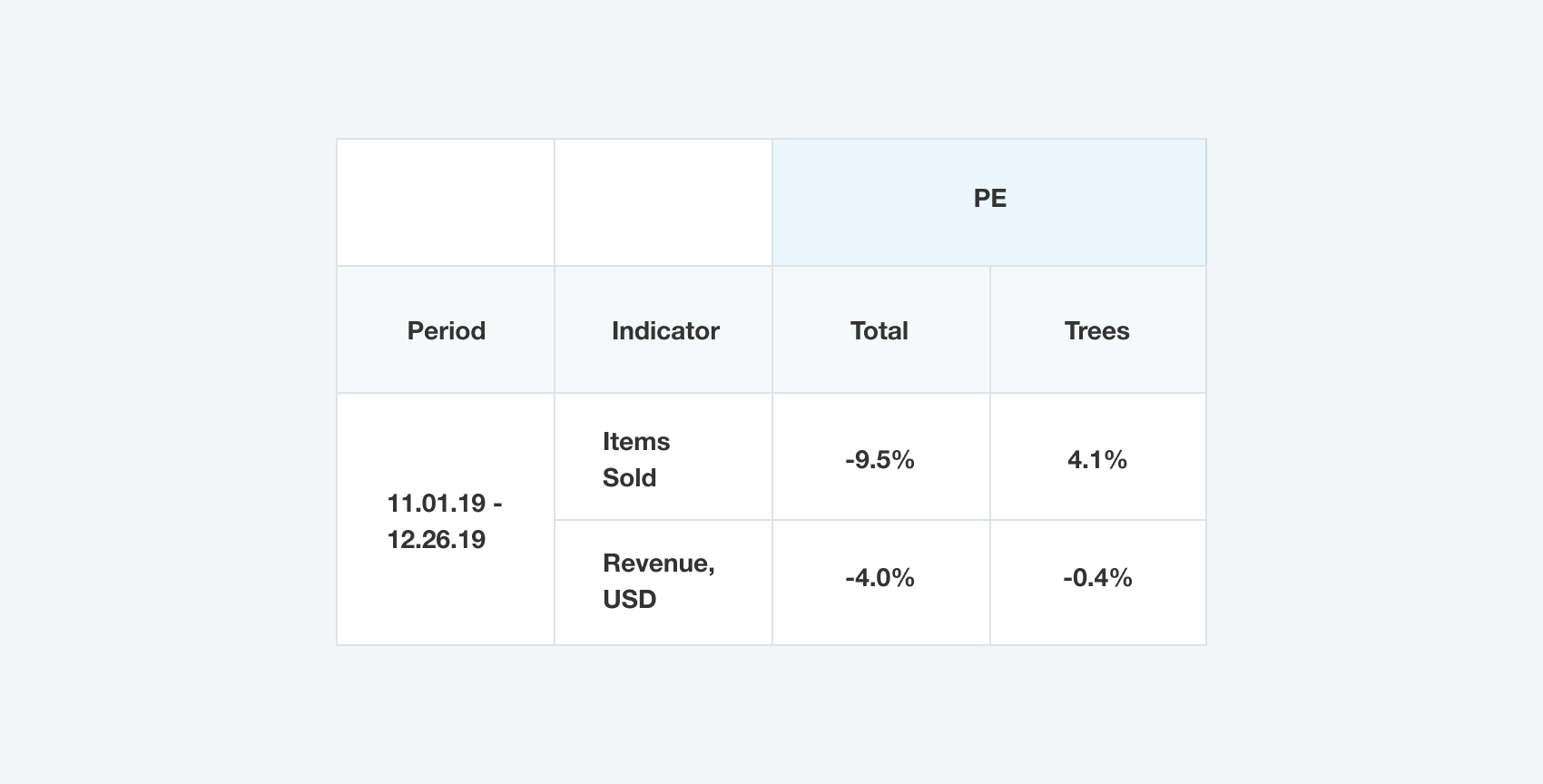
Модель достигла 96% точности прогнозов общего дохода и 99,6% точности прогнозов доходов выбранной в тестовый период:
Ее точность также оставалась высокой на уровне продукта и недели. WAPE
Читайте также: Как мы используем similarity queries в парсинге данных: что это и какой метод выбрать
Сегодня мы поговорим о том, как выбрать лучшие курсы Power BI в Украине, особенно для…
В 2023 году во всех крупнейших регионах конкуренция за вакансию выросла на 5–12%. Не исключением…
Unicorn Hunter/Talent Manager Лина Калиш создала бесплатный трекер поиска работы в Notion, систематизирующий все этапы…
Edtech-стартап Mate academy принял решение отправить своих работников в десятидневный отпуск – с 25 декабря…
Служба безопасности Украины задержала в Киеве 46-летнего программиста, который за деньги устанавливал шпионские программы и…
IT-специалист Джордан Катлер создал и выложил на Github подборку разнообразных ресурсов, которые помогут достичь уровня…
{kind=link}
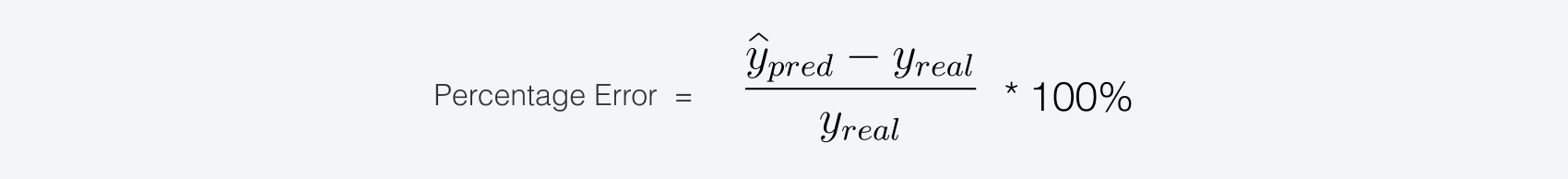{kind=link}
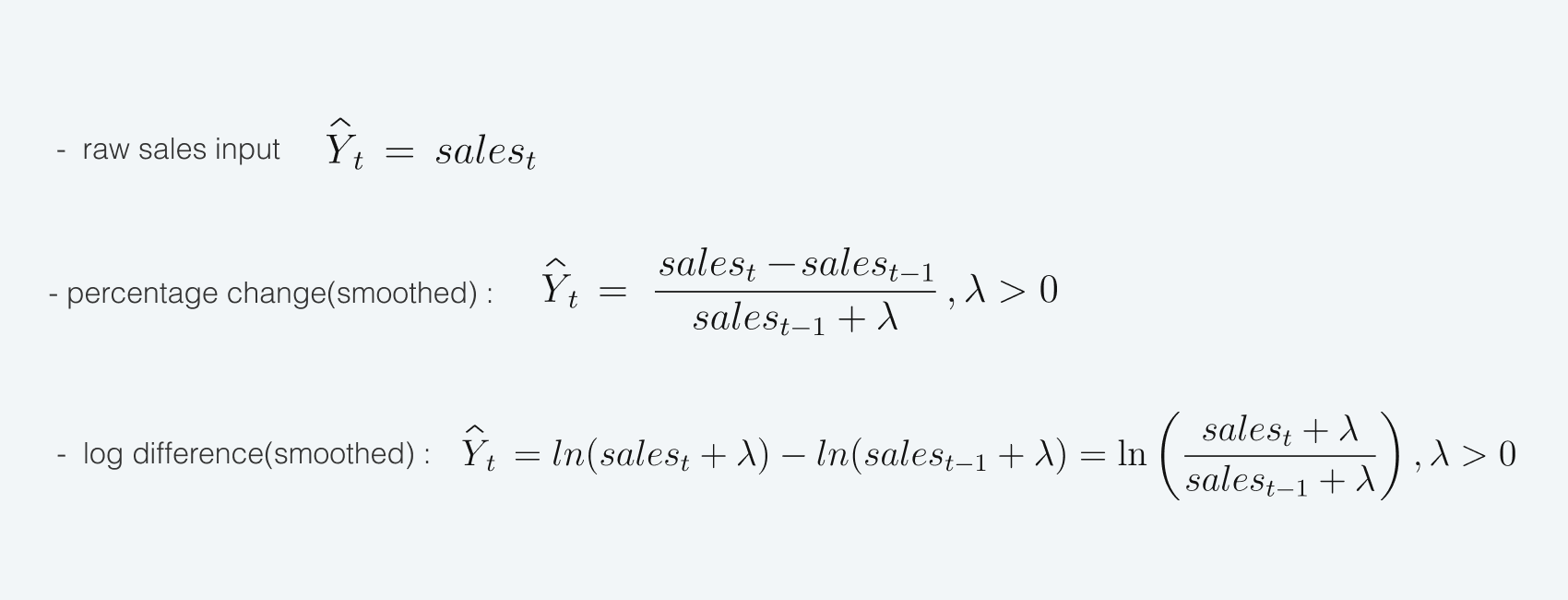{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}