The funny cat in glasses is holding a open orange book. White background. Isolated.
В інтернеті щотижня архівується понад мільярд сторінок. Веб-архіви використовуються для різних цілей: за їх допомогою можна знайти вже неіснуючий сайт або статтю, вебсторінку, дизайн якої змінився, витягти/завантажити дані для аналізу.
Редакція Highload розібралася, що таке веб-архів, які актуальні ресурси є в інтернеті та навіщо їх використовують.
Зміст
Як і будь-який інший матеріал, який збирається бібліотеками та архівами, веб-архіви потрібні для того, щоб доповнювати існуючі колекції та слугувати різним цілям.
Основною метою веб-архівування є збереження вихідної форми зібраного контенту без змін.
Оскільки інтернет надає доступ до найсвіжішої інформації, сайти регулярно оновлюються, постійно розвиваються та зазнають змін. Безумовно, це одна із сильних сторін інтернету. Але вона означає ще й те, що важливу інформацію також можна втратити.
Веб-архіви і призначені для того, щоб захоплювати контент як «докази» в ділових чи історичних цілях.
Веб-архівування — це процес збору даних з інтернету, забезпечення їх збереження та надання зібраної інформації для майбутніх досліджень. Цей процес аналогічний до традиційного архівування паперових документів. Вся інформація також відбирається, зберігається та обробляється.
Як і в традиційних архівах, веб-архіви збираються і обробляються архівістами, у цьому випадку «веб-архівістами».
Оскільки інтернет містить величезну кількість сайтів та контенту, веб-архівісти зазвичай використовують автоматизовані методи збору даних. Сам процес включає «збір» сайтів за допомогою спеціально розробленого програмного забезпечення — краулера.
Краулери — пошукові роботи — копіюють і зберігають інформацію по мірі її надходження.
Веб-архіви записують вміст веб-сторінки, включаючи її вихідний HTML, вбудовані зображення, таблиці стилів або код JavaScript. При перегляді користувач може взаємодіяти із заархівованою сторінкою, у тому числі здійснювати переходи за посиланнями.
Загальнодоступні веб-архіви, як правило, створюються та підтримуються незалежними організаціями, щоб уникнути зловмисних маніпуляцій та фальсифікацій.
Більшість раннього інтернету і дані, які він колись містив, зникли назавжди. З 1990 до 1997 року збереглося дуже мало веб-інформації.
Практика веб-архівування була ініційована лише у 1996 році, надаючи гігантський обсяг історичної інформації про саму мережу, нещодавню історію та культуру, а також дані про те, як мережа змінила методи спілкування людей один з одним.
Засновником архіву вважається Брюстер Кейл. З цього часу в ньому збережено мільйони книг, аудіофайлів, відеоконтент, терабайти даних та мільярди сайтів та вебсторінок.
Веб-архів — це спеціальний онлайн-сервіс, який зберігає історії сайтів, які обійшла пошукова машина. Він зберігає як HTML-код сторінок, і інші типи файлів — медіа, zip-архіви, .pdf, .doc, css стилі і не лише.
Все це дозволяє відновити сайт у тому первісному вигляді, в якому він колись працював, подивитися його історію та авторитетність.
Існує безліч причин, за яких виникає необхідність перегляду старих версій сайтів. На багатьох сайтах згодом багато змінюється, у тому числі:
Інтернет-архіви виконують ту саму функцію, що й бібліотеки, дозволяючи нам зазирнути у минуле та побачити, як усе змінилося з часом. Веб-архіви зберігають інформацію, опубліковану в інтернеті або оцифровану з друкованих видань. Більшість цієї інформації унікальна і історично цінна.
Історія сайтів у веб-архіві зберігається за роками у вигляді скріншотів. Він корисний і при SEO-просуванні, дозволяє уникнути помилки при виборі доменного імені сайту, відновити інформацію (контент, зображення), загублену в часі.
Хоча Wayback Machine є найстарішим і найбільшим загальнодоступним веб-архівом, це не єдина загальнодоступна веб-бібліотека, яка містить дані про сайти та веб-сторінки. Нижче наводимо приклад лише деяких із них.
Wayback Machine — це одна з найкращих архівних бібліотек, якою щодня користуються мільйони людей. Багато компаній покладаються на цей веб-архів при оцінці конкурентів та побудові стратегії розвитку. Він дозволяє побачити історію проіндексованого сайту та те, як він був створений.
Якщо ви вмієте скористатися пошуковою системою, вам буде досить просто розібратися в питанні пошуку заархівованих вебсторінок.
Просто зайдіть на Wayback Machine та введіть пошуковий запит, з’явиться список релевантних сайтів. Також можна відразу ввести адресу сайту або конкретну URL-адресу. У ресурсу також є дуже докладна опція розширеного пошуку, яка дозволяє звузити пошуковий запит, обрати дату та багато іншого.
Wayback Machine — це платформа, яка відіграє життєво важливу роль у наданні історичної інформації про будь-який сайт.
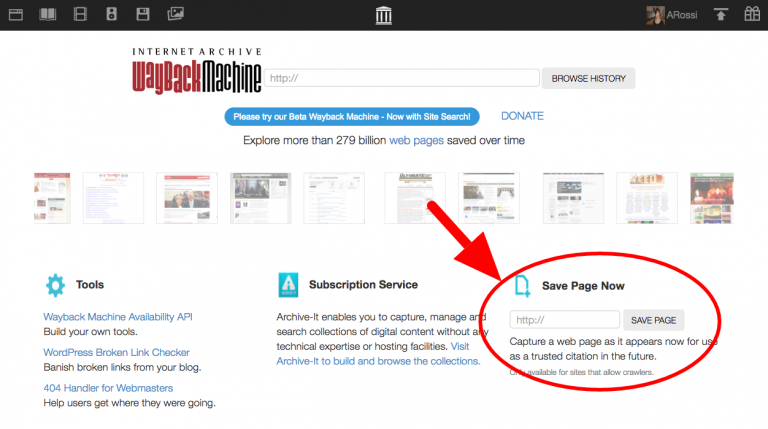
Архів існує з 1996 року. Крім знімків та історії сайтів у ньому містяться тисячі терабайт фото- та відеоконтенту, старих телепередач, оцифрованих книг. Щоб знайти збережені версії сайтів, необхідно ввести в поле адресу і натиснути на кнопку пошуку — Browse History .
Натисніть на сайт у результатах пошуку для завантаження його останньої заархівованої версії з повзунком у верхній частині сторінки, який дозволяє обрати дату. Оберіть час, і архів завантажить знімок сайту з цією датою та часом.
На сайті доступні інструменти:
Веб-архів також доступний як розширення для браузерів Chrome, Firefox та Safari. Також розроблені програми для Android та iOS.
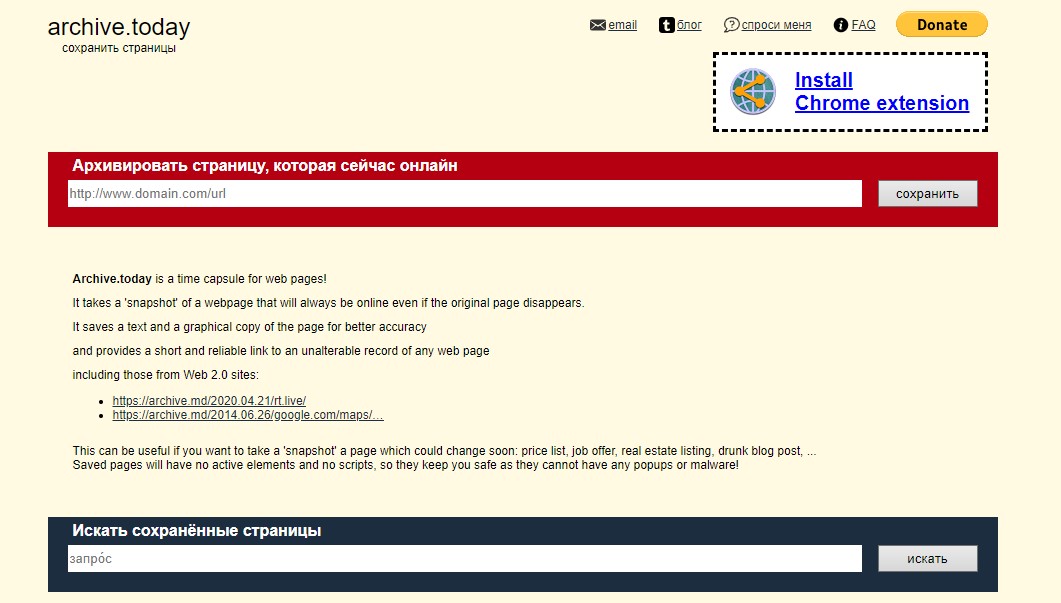
Архів archive.md доступний також за адресами http://archive.today/ та http://archive.ph/ .
Сервіс дозволяє знаходити збережені сторінки, а також архівувати існуючі. Для того, щоб знайти збережену раніше вебсторінку, потрібно ввести конкретну URL-адресу або вказати домен сайту.
Архів не зберігає аудіо та відео із сайтів, RSS, документи у форматі .pdf, flash-сторінки.
Доступне збереження:
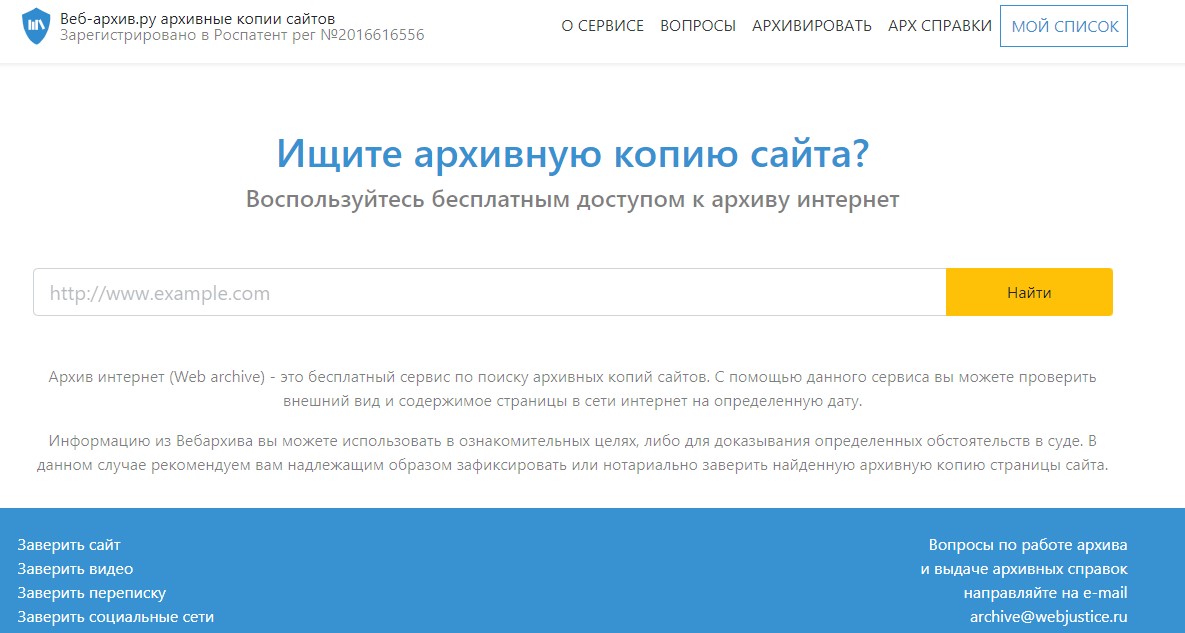
Сервіс Web-arhive.ru зберігає копії сторінок сайтів. Він повністю безкоштовний.
Доступні функції:
Трапляються випадки, коли користувач для перегляду історії не може знайти у веб-архіві потрібну вебсторінку, документ або файл.
Що робити? Насамперед необхідно звернутися до кількох веб-архівів та пошукати там. Якщо нічого так і не знайшлося, скоріш за все, сторінку було видалено ще до обробки її пошуковими інструментами архівів.
У цьому випадку можна звернутися до кешу Google. Для цього в полі пошуку необхідно ввести: cache:URL/ім'я сайту.
Наприклад: cache:https://mysite.ua/?p=3027
Відкриється кешована пошуковою системою вказана сторінка сайту.
Важливо, що в кеші пошукової системи Google міститься остання актуальна сторінка. З кожним новим обходом цієї сторінки пошуковим роботом дані перезаписуватимуться на актуальні.
Пам’ятайте, що для оновлення кешу в Google потрібно в середньому до 15 днів.
Як знаходити архівні копії сторінок сайтів, використовуючи спеціальні онлайн-сервіси — ми обговорили. Але як повністю завантажити та відновити сайт з архіву?
Wayback Machine Downloader — це онлайн-сервіс, який допоможе завантажити вебресурс із усіма внутрішніми сторінками та вкладеними файлами з інтернет-архіву.
Він здійснить завантаження останніх версій кожного з архівних файлів, які є на Wayback Machine, в директорію ./websites/mysite.ua. Наново створить структуру каталогів та сторінки index.html. Це необхідно для стабільної роботи з Apache та Nginx.
Всі файли, які завантажуються, не будуть перезаписані з Wayback Machine як є, вони будуть повністю оригінальними, а тому урли і структура посилань залишаться такими ж, як і були колись.
Щоб запустити Wayback Machine Downloader і розпочати завантаження повної версії сайту, необхідно ввести: wayback_machine_downloader https://mysite.ua
Позначки:
-d | --directory. Тека за замовчуванням: ./websites/mysite.ua/. |
-s | --all-timestamps. Завантаження позначок часу сайту. |
-f | --from TIMESTAMP. Завантаження файлів на вказану або пізнішу тимчасову мітку. |
-t | --to TIMESTAMP. Завантаження файлів на вказану або більш ранню мітку. |
-e | --exact-url.Завантаження виключно вказаних URL-адрес. |
-o | --only ТОЛЬКО_ПО_ФИЛЬТРУ. Завантаження URL-адреси щодо фільтра. |
-x | --exclude ФИЛЬТР_ИСКЛЮЧЕНИЯ. Не завантажувати URL, вказані у фільтрі. |
-a | --all. Завантаження також файлів редиректів та помилок. |
-c | --concurrency ЧИСЛО. Число файлів, що завантажуються. |
-p | --maximum-snapshot ЧИСЛО. Максимальна кількість скринів сторінок (100), які будуть розглянуті. |
-l | --list. Виведення списку URL у форматі JSON. |
-v | --version. Виведення версії. |
Наприклад:
Виведення з архіву виключно посилань на файли > mysite-urls.json —
wayback_machine_downloader https://mysite.ua -l > mysite-urls.json
Список посилань буде збережено у файлі.
Припустимо, перед нами стоїть завдання завантажити архівну копію сайту не повністю, а лише його окрему веб-сторінку. Для такої мети необхідно задіяти програму Waybackpack .
Waybackpack — це невелика утиліта командного рядка, яка дозволяє за заданою URL-адресою завантажити архів з Wayback Machine повністю.
Наприклад, щоб завантажити всі вебкопії головної сторінки сайту до 2019 року (рік, коли сайт був вперше заархівований), ви повинні запустити: waybackpack http://www.mysite.ua/ -d ~/Downloads/dol-wayback --to-date 2019
Позначки:
| URL | URL-адресу, яку потрібно завантажити. Обов’язковий аргумент. |
| Необов’язкові аргументи | |
-h | --help. Виведення довідки. |
--version | Виведення версії. |
-d DIR | Створення каталогу для збереження файлів. |
--list | Вивід списку всіх копій. |
--raw | Завантаження вихідних файлів без змін. |
--root ROOT | URL для обробки архіву даних (за замовчуванням https://web.archive.org). |
--from-date | Мітка часу для завантаження раннього архіву. |
--to-date | Мітка часу для завантаження останнього архіву. |
--user-agent USER_AGENT | Відправлення разом із запитами до Wayback Machine. |
--follow-redirects | Дотримання редиректів. |
--uniques-only | Завантажує першу версію копій файлів. |
--collapse COLLAPSE | Параметр для archive.org. |
--ignore-errors | Продовжувати роботу при помилках не http. |
--quiet | Не повідомляти про прогрес у stderr. |
Наприклад:
Завантаження з архіву всіх копій домашніх сторінок ресурсу, починаючи з 2020 року ( --to-date 2020), розміщення їх у директорії -d /home/my/test з успадкованими редиректами ( --follow-redirects)waybackpack mysite.ua -d /home/my/test --to-date 2020 --follow-redirects
Сервіс Wayback Machine може здійснювати виведення всіх копій вебсторінок сайту. Для того щоб це зробити, необхідно в адресний рядок ввести: https://web.archive.org/web/*/[URL]/*.
Для цього також можна використовувати інструмент Waybackurls — приймає домени з роздільниками рядків, витягує всі відомі адреси URL з Wayback Machine для *.domain.
Для того, щоб з Wayback Machine отримати повний список всіх сторінок сайту mysite.ua, необхідно ввести: echo mysite.ua | waybackurls
Для того, щоб з Wayback Machine отримати список сторінок відразу кількох сайтів, необхідно ввести: cat домени.txt | waybackurls
Позначки:
-dates | Виведення першої шпальти з датою архівування вебсторінки. |
-no-subs | Не виводити субдомени. |
Наприклад:
Отримання з Wayback Machine повного списку сторінок з адресами для сайту mysite.ua echo mysite.ua | waybackurls -dates (з показом дати архівування ( -dates).
Щоб убезпечити себе від несанкціонованого використання контенту з вашого сайту після його видалення, додавання ресурсу до веб-архіву можна заборонити.
Найпростіший спосіб — зміна налаштувань у robots.txt та блокування доступу до сайту пошукових роботів з метою сканування всіх його сторінок з подальшим додаванням до архіву. Але зроблені раніше сканування та вивантаження даних в архівах будуть доступні однаково.
Щоб видалити інформацію остаточно, скористайтеся офіційною поштою веб-архіву — info@archive.org — для надсилання запиту на видалення. Важливо, щоб цей лист був надісланий з вашого домену. Тільки в цьому випадку протягом трьох днів сайт повністю зникне з Wayback Machine.
Щоб відновити сайт у веб-архіві, необхідно також надіслати запит на вказаний вище імейл веб-архіву.
Інтернет — один із основних засобів комунікації. У ньому міститься інформація про нещодавні події, що описується людьми різних точок зору. Мережа — цінний ресурс для сучасних історичних досліджень.
Так, наприклад, історик Ян Мілліган використовував веб-архіви для вивчення онлайн-спільнот GeoCities, популярних наприкінці 1990-х років. Йому вдалося вивчити питання формування користувачами власних спільнот та їх взаємодій за часів, коли ще не було соціальних мереж. Мережеві веб-архіви допомагають заглибитись у вивчення важливих культурних та історичних подій останніх 20 років.
Веб-архівування спрямоване на отримання, збереження та надання доступу до історичної інформації, опублікованої в інтернеті. За веб-архівуванням реалізовано безліч ініціатив. Архівні колекції веб-документів утворюють повну картину нашої культурної, комерційної, наукової та соціальної історії.
У майбутньому веб-архіви, ймовірно, стануть для багатьох одним із джерел особистих спогадів.
Також на тему роботи з веб-архівом є чудове відео англійською мовою:
Більше половини Go i Ruby розробників з досвідом 3+ роки найняли на $5000 або більше.…
Прикордонники недалеко від с. Кучурган Одеської області затримали двох програмістів, які намагалися втекти з України…
Українське Solana-комʼюніті Kumeka Team з 7 травня запускає безплатне навчання блокчейн-розробці — Solana BootCamp. Про…
Туреччина створила спеціальні візи для диджитал-номадів або «цифрових кочівників». Скористатися ними зможуть і українці. Про…
Російська студія NoName Company, вірогідно, вкрала для розробки тактичного шутеру Best in Hell про ПВК…
11 та 12 травня в NAU HUB відбудеться хакатон студенських новацій University Software Bootcamp. Про…
{kind=link}
{kind=link}
{kind=link}