По данным Fundacion Mapfre, каждую минуту более 4,5 млрд человек отправляют почти 42 млн сообщений в WhatsApp, 2704 раза устанавливают TikTok, публикуют почти 348 000 постов в Instagram и загружают более 147 000 фотографий на Facebook. С каждым годом объем информации растет, а с ней — и требования к системам поиска. Возникает потребность в структурировании, анализе и обработке больших данных. Решить такую задачу можно с помощью Elasticsearch.
Эта статья даст вам базовое понимание основных возможностей Elasticsearch. Материал будет полезен тем, кто только начинает знакомство с этой поисковой системой.
В 2006 году разработчик Шей Бенон захотел помочь своей девушке — создать для нее приложение, которое напоминало бы справочник с рецептами. Но довести начатое до конца так и не удалось. Парень решил не останавливаться и разработал предшественника Elasticsearch — систему Compass.
Бейнон пришел к выводу, что для разработки масштабируемой версии приложения нужно создать программу с нуля. В результате в 2010 году появилась первая версия Elasticsearch 0.4. Сегодня этой поисковой системой пользуются множество всемирно известных компаний, среди которых GitHub, Uber, Microsoft. Elasticsearch позволяет в режиме близком к реальному времени хранить, искать, анализировать и обрабатывать большие объемы данных.
Предлагаю детальнее разобраться в технологии поиска и ключевых особенностях системы.
Elasticsearch позволяет качественно и быстро обрабатывать текст благодаря принципу полнотекстового поиска. Для того, чтобы наглядно объяснить механизм анализа данных, приведу пример из жизни.
Представьте, что вы вводите запрос в Google и хотите найти книгу «Алиса в стране чудес». Как только вы нажимаете кнопку «Поиск», система начинает анализировать информацию по всем страницам в интернете, чтобы выдать вам наилучшее совпадение. В Elasticsearch запускается аналогичный процесс. Система разбивает текстовые данные на ключевые слова, и каждое из них доступно для поиска.
Elasticsearch — это продукт с открытым исходным кодом, основные инструменты которого находятся в открытом доступе на GitHub. Благодаря этому без нарушения авторских прав разработчиков вы сможете реализовать недостающий функционал на языке Java и стать контрибьютором Elasticsearch.
Одно из важных преимуществ системы — распределенность и масштабируемость. Что это значит? Говоря о больших массивах данных, стоит задуматься о том, как увеличить производительность и сделать так, чтобы процессы выполнялись быстрее.
Elasticsearch установлен на одном сервисе и успешно справляется с поисковыми запросами. Со временем количество пользователей увеличивается, и система может не справиться с текущей нагрузкой. Тогда вы можете легко масштабировать ее путем автоматического добавления отдельного узла (ноды). Для базовых нужд вам не понадобятся никакие дополнительные настройки.
Elasticsearch — отказоустойчивая поисковая система. Ее кластеры продолжают работать, даже если возникает ошибка. Например, сбой узла или неполадка сети. Elasticsearch незаметно для пользователя автоматически поднимает другую ноду и сохраняет работу системы. Вы можете быть уверены в том, что данные не исчезнут и производительность сохранится.
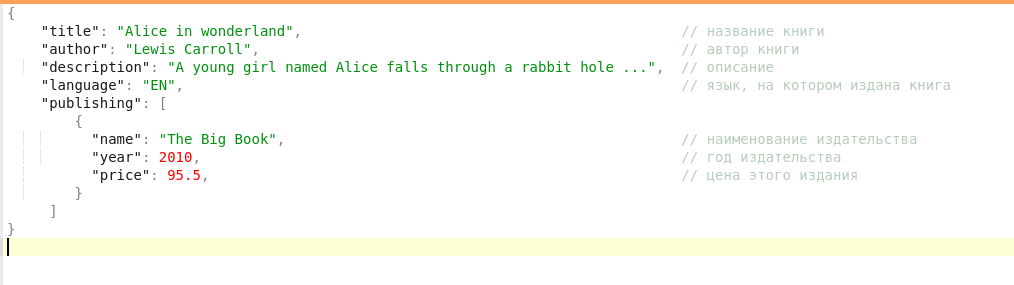
Elasticsearch — документоориентированное хранилище, где данные организованы по определенным типам (сущностям). Представьте, вы покупаете книгу в интернет-магазине. Проводя аналогию с сущностями — это основные характеристики книги (автор, название, год издания, аннотация). В Elasticsearch эти данные хранятся в формате JSON и находятся в определенном месте (папке), которую принято называть индексом. Информация распределена. Значит, можно переходить к поиску.
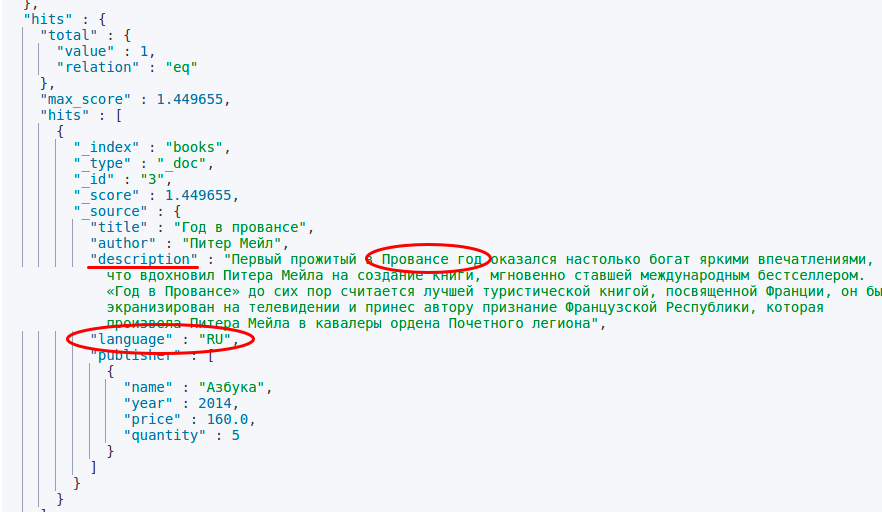
Допустим, вы хотите прочесть книгу на русском языке о Провансе 1995 года. Для того, чтобы обработать ваш запрос, Elasticsearch обратится к выше указанным полям и оперативно найдет необходимый источник.
Elasticsearch легко интегрировать в любое приложение для различных задач поиска благодаря RESTful API — правилам общения между двумя приложениями. Возвращаемся к примеру с книгами. Библиотека — это тот же Elasticsearch только со своим набором стеллажей. Вы — читатель, который обращается к библиотекарю с просьбой найти книгу «Алиса в стране чудес». Ваша коммуникация и будет примером RESTful API. Почему? Потому что вы обращаетесь с конкретным запросом к определенному специалисту. Если же человек не понял ваш запрос, то вы не получите ответ. Точно так же происходит и в RESTful API. Тогда на экране компьютера вы увидите знакомую фразу «Страница не найдена».
Прежде чем приступить к работе с поисковой системой, советую вам внимательно ознакомиться с технической документацией. Это подробный гайд о том, как правильно установить и настроить Elasticsearch в вашем окружении (Windows, Linux, Docker). Так вы сможете стать уверенным пользователем поисковой системы и будете находить нужную информацию в считанные секунды.
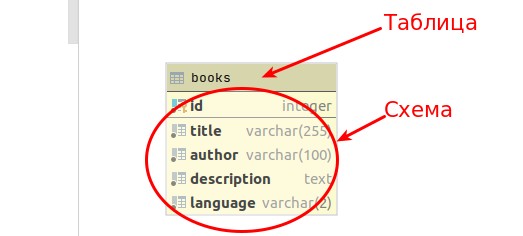
После успешной установки актуальной версии Elasticsearch, попробуйте разобраться в основных понятиях и загрузить первые данные в систему. Предлагаю вам провести аналогию с реляционной базой данных и Elasticsearch.
| БД | ElasticSearch |
| Таблица | Индекс |
| Схема | Отображение (mapping) |
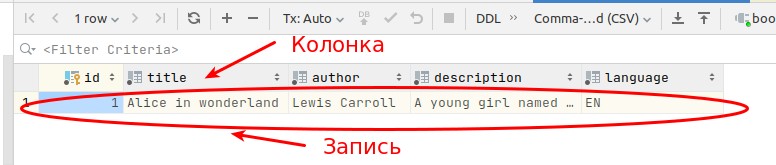
| Запись | Документ |
| Колонка | Поле |
| SQL | Query DSL |
Теперь посмотрим на Elasticsearch:
Теперь приведем пример запросов.
SQL:
SELECT * FROM books WHERE description like '%rabbit%'
Query DSL (Elasticsearch):
Результат выполнения:
На первый взгляд может показаться, что существенной разницы в хранении информации и скорости выполнения поисковых запросов между базой данных и Elasticsearch нет. Но процессы аналогичны до тех пор, пока мы не вспомним о том, что нужно получать ответ в считанные миллисекунды и при этом справляться с высокой нагрузкой.
Читайте также: Как обновить данные в базе, чтобы 25 млн пользователей ничего не заметили: опыт приложения для знакомств
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}