Привет! Меня зовут Александр Бричак, я Golang Developer в NIX. В этой статье я расскажу об авторизации с помощью JSON Web Token.
Вы узнаете, как устроен токен и какие типичные задачи решаются с помощью такой авторизации. Также я поделюсь best practices использования JWT и немного затрону тему безопасности.
Содержание:
1. Аутентификация с помощью сессий
2. JSON Web Tokens
3. Проблемы использования токенов
4. Различные типовые задачи с использованием JWT
5. Logout и Only one active device
6. Automatic logout
7. Сравнение сессий и JWT
8. Best practices в JWT
Когда говорят об авторизации, зачастую понимают под этим термином разные процессы. Проверка пользователя подразумевает и идентификацию, и аутентификацию, и авторизацию.
И эти понятия нужно уметь разделять:
В статье я буду в основном говорить об аутентификации. Зачастую используя термин «авторизация», говорят об аутентификации, поэтому в этом материале я буду использовать термины попеременно в одном и том же смысле.
Обратите внимание на курс от Mate Academy. На нем вы получите знания, которые потребуется вам для повседневной работы. А менторы помогут вам закрепить знания на практике и ответить на все ваши вопросы.
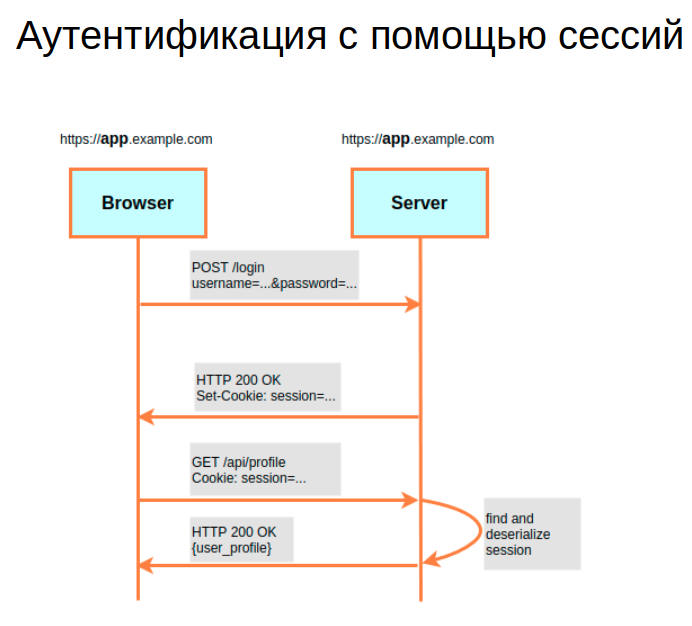
На иллюстрации ниже изображена традиционная схема аутентификации с помощью сессий. Представим фронтенд-приложение в браузере и бэкенд на сервере. Когда пользователь для входа в систему вводит во фронтенде свои креды, логин и пароль, на бэкенде сервер проверяет их. Если все в порядке, он подтверждает аутентификацию юзера возвращением ответа «200» и добавляет cookies с идентификатором сессии — Session ID. После этого стартует сессия пользователя, и он может работать с системой.
Когда юзер выполняет новые запросы, браузер отправляет их на сервер и автоматически снабжает каждый из них той самой Session ID. Задачи сервера на данном этапе: вытащить из запроса эти куки, распарсить и проверить их правильность. Если все окей, то пользовательская сессия валидна — и можно отдать юзеру запрошенный контент.
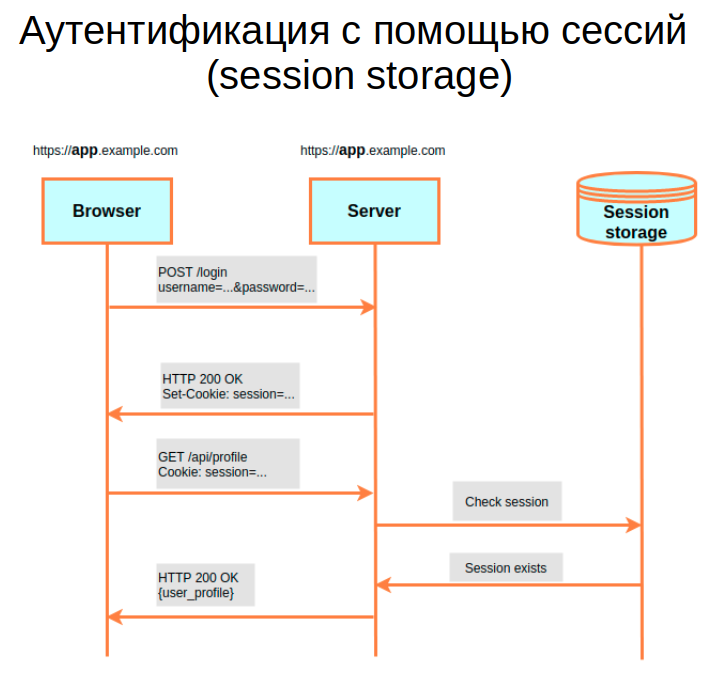
Но при таком подходе необходимо понимать: часто идентификатор сессии должен жить не сам по себе, а еще и хранить определенную информацию. Например: какая роль у пользователя или какие товары он просматривал. Но браузер не дает возможности записывать слишком много данных в cookie.
По этой причине появилось такое понятие, как Session storage — это место на сервере для хранения информации, привязанной к Session ID.
Практически все современные фреймворки предлагают широкий выбор вариантов для Session storage:
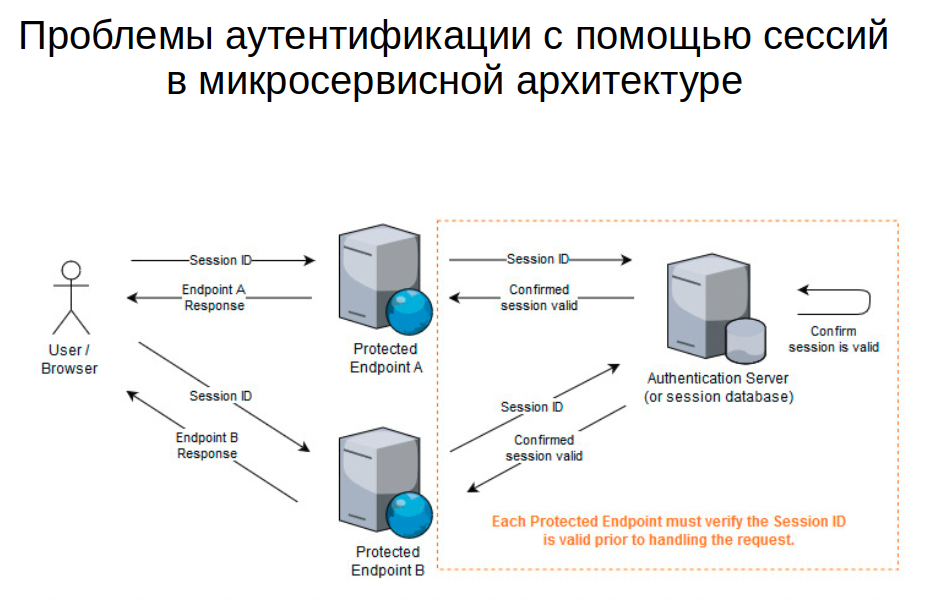
Описанная схема прекрасно работает в пределах одного домена, но вызывает определенные проблемы при архитектуре с микросервисами.
Это демонстрирует изображенная ниже схема, на которой представлены два сервиса Protected Endpoint — они защищены и должны предоставлять пользователям ресурсы по их запросам. Также в системе есть Authentication Server — этот сервер отвечает за изначальный логин пользователей и проверку валидности Session ID, которую юзер передает со своим запросом.
При такой архитектуре видна одна проблема: если пользователь для получения, скажем, дашборда должен обращаться к нескольким защищенным эндпоинтам, то каждый из них должен проверить валидность Session ID и связаться для этого с сервером аутентификации. В таком случае этот сервер рано или поздно станет узким местом и замедлит все процессы. Причем вне зависимости от того, как изменится архитектура.
Можно поставить сервер аутентификации перед Protected Endpoint — то есть объявить его API Gateway. Другой вариант — разрешить защищенным эндпоинтам напрямую соединяться с Session storage. Но проверка Session ID все равно останется так называемым bottleneck
Более того, при установке cookie можно указать, к какому домену она относится. Тогда браузер во время обращения к другим доменам не будет подставлять ее в запрос. Но если защищенные эндпоинты микросервисов будут находиться на разных доменах, то будет сложно устанавливать cookie с Session ID. Кроме того, есть вероятность CSRF-атак, ведь они как раз нацелены на cookies с таким содержанием, которые предоставляют доступ юзерам к защищенным ресурсам.
Учитывая указанные проблемы, в сообществе разработчиков много лет назад появилась идея использовать некую строку, которую с одной стороны невозможно подделать, с другой — которую каждый ресурсный сервер мог бы сам проверить на валидность. В качестве такой строки оказалось удобно использовать JWT — JSON Web Token.
JWT представляет собой строку из трех частей, разделенных точками. На иллюстрации ниже приведены значения каждой части:
При этом открыть обратно первую и вторую части не составит труда для любого пользователя, имеющего тот самый двусторонний алгоритм.
Но никто не может прочитать записанное в третьей части — и соответственно никто не может подделать токен.
Если злоумышленник, например, укажет во второй части другое имя пользователя, то изменится и подпись в третьей части. Но поскольку у злоумышленника нет секретного ключа, то он не сможет правильно подписать токен. JWT попросту не будет валидным. Благодаря этому любой сервер, имеющий секретную строку для подписания токена, сможет проверить его валидность и вытащить информацию из второй части payload.
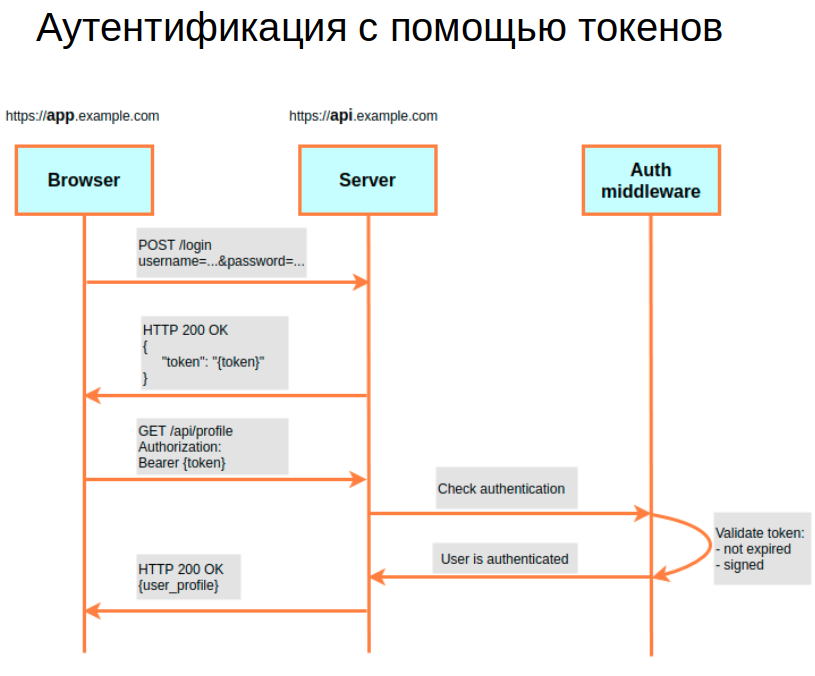
Перейдем к следующей схеме на иллюстрации ниже. Схема похожа на аутентификацию с помощью сессий, но есть одно отличие. После введения кредов сервер дает юзеру не cookies с Session ID, а токен. Затем клиентское приложение добавляет токен к каждому запросу в виде специального заголовка Authorization. При этом оно вписывает в него слово «Bearer» (предъявитель), а после пробела — сам токен. Также на схеме представлен Auth middleware. Это достаточно стандартная часть любого фреймворка, которая умеет проверять, в частности, валидность токена. То есть обработка на сервере проходит этап проверки.
Если токен не заэкспайрился и правильно подписан с помощью секретной строки, то пользователь аутентифицирован. В результате при использовании архитектуры микросервисов не нужно каждый запрос к ресурсным серверам прогонять через сервер аутентификации. Каждый сервер может иметь секретную строку и самостоятельно проверять валидность токена.
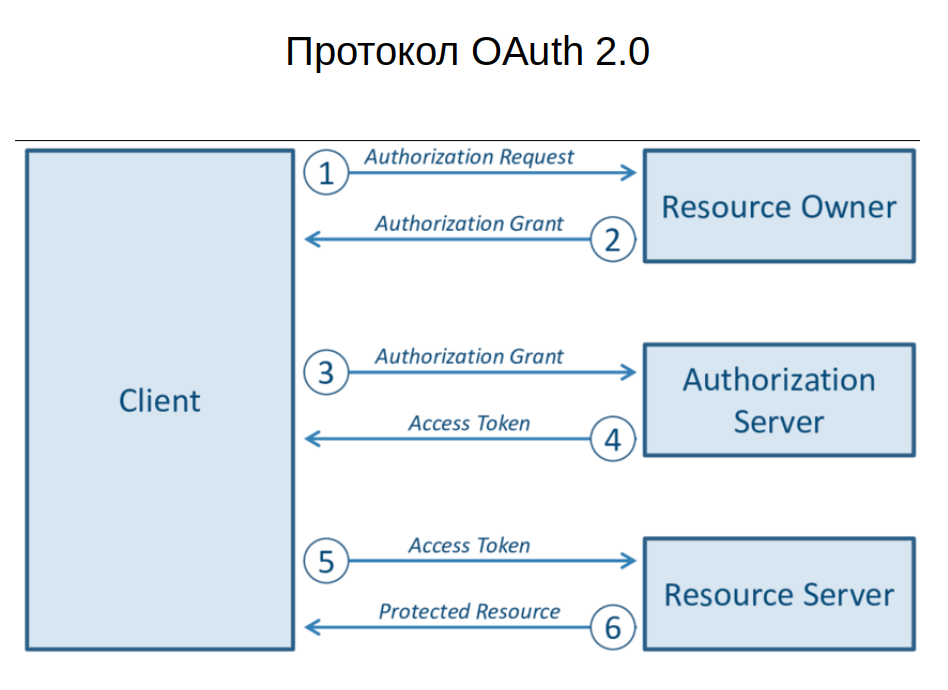
В контексте обсуждения JWT обязательно стоит упомянуть протокол OAuth 2.0, который построен на основе данной структуры (см. схему ниже). Он позволяет пользователям авторизоваться в приложениях и получать токен для обращения к ресурсным серверам, используя, например, Google- или Facebook-приложения.
В таком случае идентификация и аутентификация перекладывается на сторонних провайдеров:
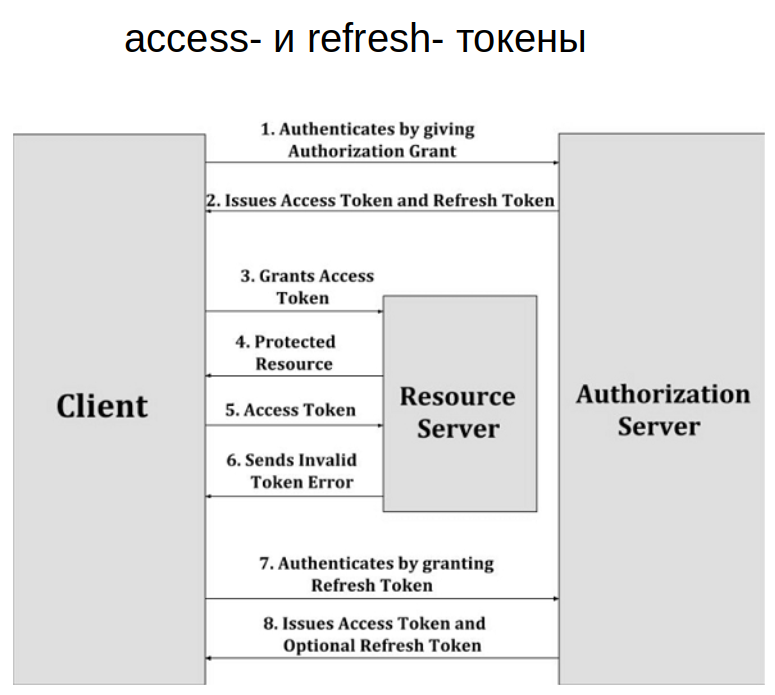
Отдельно стоит обратить внимание на access- и refresh-токены. Как правило, access-токен — это некий короткоживущий токен, который много раз используется приложением для обращения к серверу. Когда срок жизни токена истекает, можно обратиться к серверу для продления срока. Для этого и понадобится refresh-токен. Он одноразовый, но имеет более долгий срок жизни и позволяет получить новую пару токенов. Схема их использования приведена на этой схеме:
Благодаря такому решению появляется возможность обезопасить юзера. Если в незащищенном http-соединении злоумышленник украдет access-токен, он не сможет им долго пользоваться. Через определенное время access-токен утратит валидность. Настоящий пользователь со своим refresh-токеном сможет получить новую пару, а вот злоумышленник — нет.
Как и с любой технологией, в работе с токенами есть некоторые ограничения и проблемы. Их надо осознавать и правильно обращаться с JWT при использовании в проектах. Я уже отмечал, что токен может быть проверен ресурсным сервером независимо ни от чего, достаточно лишь секретной строки.
Но отсюда следует проблема: если выдать пользователю новую пару токенов, а старая пара еще валидна, то средств ее заэкспайрить нет.
Ведь сам по себе токен — это строка, которая нигде не хранится. Пока он валидный, им можно пользоваться. В итоге юзер может получить вторую пару, третью, четвертую — а предыдущие еще будут работоспособны.
Из этого вытекает следующая сложность — невозможно провести полноценный логаут. Во фронтенд-приложении после нажатия кнопки выхода пользователь уверен, что он вылогинился из системы. Но выданные ему токены проживут еще некоторое время! По этой же причине невозможно вылогинить юзера в случае утери или кражи токена.
А еще есть проблемы при краже секретной строки. Да, это происходит не часто, потому что этот ключ лежит на сервере. Но если строка украдена, то все токены будут скомпрометированными.
Есть проблемы с хранением токенов на фронтенде — нередко их помещают прямо в local storage. Так удобнее для разработчика, но это требует дополнительных средств для повышения секьюрности системы.
Сегодня в проектах приходится решать задачи, которые выходят за рамки описываемых токенов, но при этом они базируются на их использовании. Первая подобная задача — lockout-механизм. Он предполагает блокирование пользователя после нескольких безуспешных попыток аутентификации. Я не буду подробно останавливаться на этой задаче, она достаточно простая. Если пользователь несколько раз подряд ввел корректные имя или email, но неправильный пароль, надо заблокировать этого юзера на определенное время. Для этого на сервере нужно записать, допустим, в базу данных или промежуточное хранилище количество безуспешных попыток и задать блокировку доступа в случае превышении этого показателя.
Более интересные задачи — Logout и Only one active device, которые в принципе связаны между собой.
Logout предполагает, что после нажатия кнопки логаута во фронтенд-приложении надо с подтверждением выхода еще и инвалидировать сами токены, сделать их недействительными.
Что касается Only one active device, то эта задача позволяет юзеру быть одновременно залогиненным только на одном устройстве. Если он войдет в аккаунт с другого устройства, то выданные первому устройству токены должны потерять свою валидность. Подробнее о реализации обоих механизмов и их связи я расскажу далее.
Еще одна интересная задача — с автоматическим логаутом. Она встречается в приложениях достаточно часто, а для некоторых типов приложений (например, дающих доступ к сенситивной или финансовой информации) даже является обязательной.. Суть такая: если залогиненый в приложение пользователь неактивен в течение некоторого заданного времени, то он должен быть автоматически вылогинен из системы без возможности ее использовать заново, пока не будут повторно введены креды.
Давайте подробнее рассмотрим задачи авторизации Logout и Only one active device. Сами по себе токены задуманы как stateless, то есть они не предназначены для размещения на сервере. А идея заключается в том, чтобы предусмотреть возможность хранения какой-то информации о них на сервере. Способы могут быть разными. Например, можно создать blacklist для токенов, которые должны стать невалидными.
Такие токены будут храниться в «черном списке», пока не истечет срок их использования. С другой стороны, можно создать на сервере whitelist, что может оказаться даже несколько проще. Этот список станет реестром выданных токенов, с которым может сверяться система. Если предъявленный юзером токен не просрочен и указан в «белом списке», то он валиден.
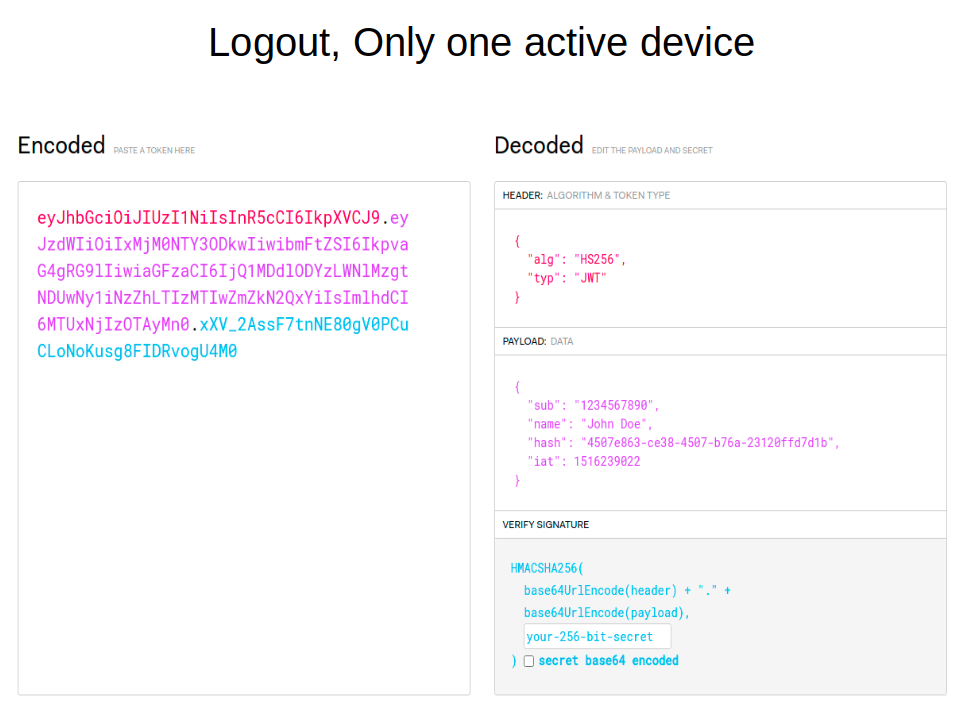
Хранение самих токенов в базе данных сложно назвать безопасным. Можно ли как-то выйти из этой ситуации? Да. Обратите внимание на иллюстрацию ниже: в разделе payload добавился пункт hash. Это некая рандомно сформированная строка. Она записывается в payload токена и в хранилище на сервере с привязкой к идентификатору пользователя.
Когда юзер предъявляет токен, система парсит его, проверяет срок действия токена и его подпись секретной строкой. Затем вытаскивает hash и сверяет его с пользовательским ID в хранилище. Это может быть key-value хранилище, основная база данных или другое хранилище, которое предоставит современный фреймворк.
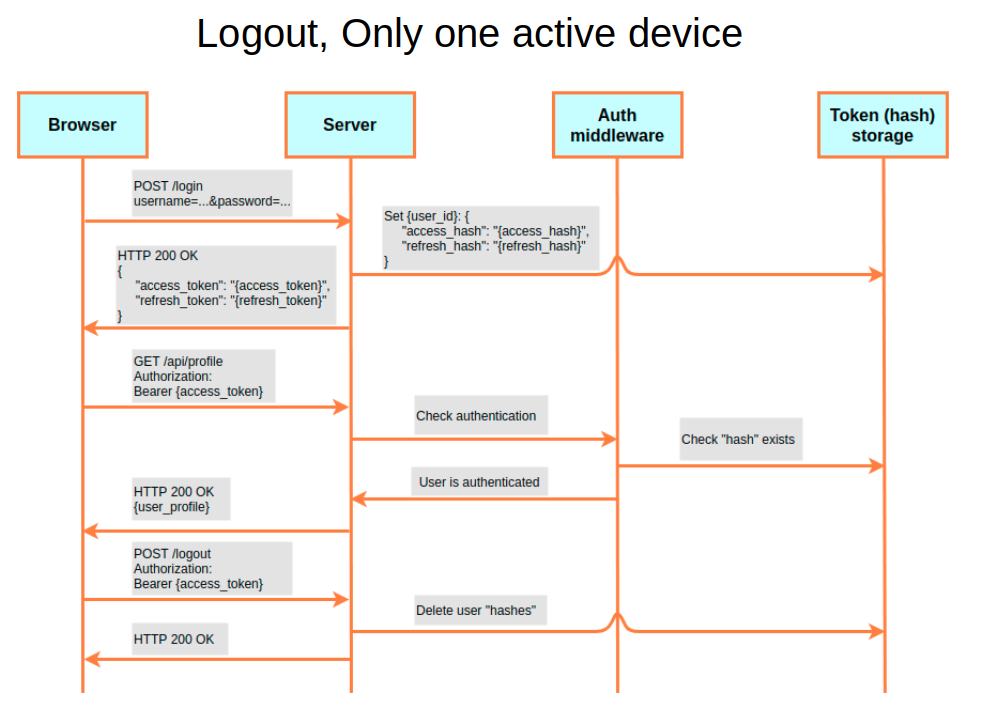
За счет использования поля hash схема взаимодействия клиента и сервера становится такой (см. следующую картинку). Сначала браузер отправляет на сервер креды. Сервер проверяет их и при корректно введенных данных записывает в Token (hash) storage связку из User ID и hash для access- и refresh-токенов, а после этого — отдает их. Далее пользовательский браузер предъявляет access-токен в API. Для проверки аутентификации сервис снова обращается к базе данных, находит связку hash с User ID и, если все в порядке, возвращает ответ с запрошенной информацией.
Для логаута нужно удалить hash из базы данных. Когда пользователь в следующий раз создаст запрос с этим токеном, проверка покажет, что такой hash отсутствует. Значит, юзер ранее выполнил выход из системы.
Как это связано с Only one active device? Если в базе данных разрешено хранить по каждому User ID несколько хешей для нескольких access- или refresh-токенов, то это позволяет пользователю логиниться одновременно с разных девайсов. Но если мы разрешим хранить в базе данных только один хэш для каждого User ID , то это и будет реализация Only one active device. Как только юзер логинится с другого девайса, старая связка перезаписывается. Из-за этого предыдущий девайс больше не сможет обращаться к серверу.
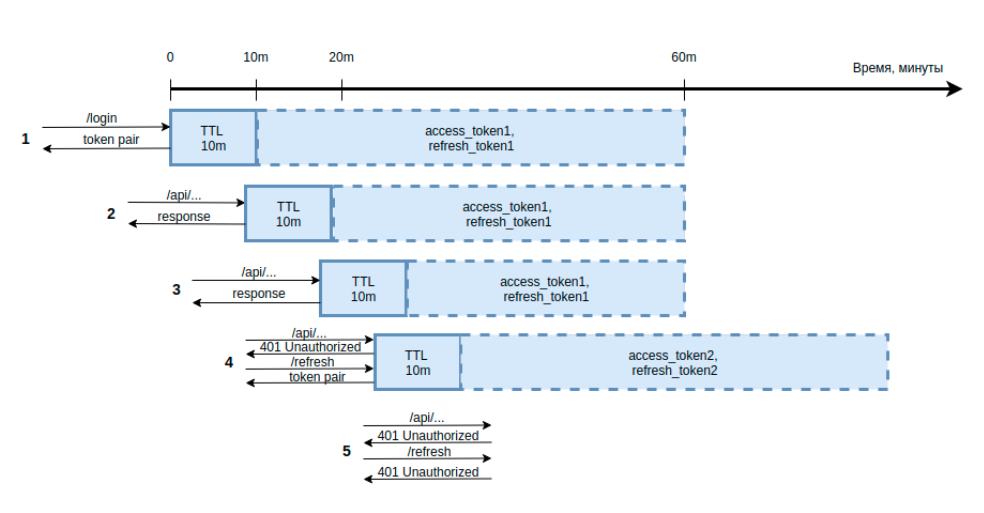
Немало вопросов на практике возникает с automatic logout. Может показаться, что задачу можно решить путем манипуляции сроков действия access- и refresh-токенов. То есть после обращения пользователя к бэкенду система выдает ему эти токены со сроком действия, который нужен четко для автоматического логаута. И тогда если токен просрочен, то логаут состоится. Ниже на иллюстрации приведена именно такая схема:
Но есть проблема. Допустим, надо автоматически вылогинивать пользователя в случае неактивности в течение 10 минут. Под неактивностью следует понимать, что к серверу никто не обращался.
Представим, что в нулевой момент времени юзер выполнил вход, ему был выдан access-токен на 10 минут, зато refresh-токен более «долгий», как это и задумано в архитектуре. Здесь может возникнуть следующая ситуация: если до истечения 10 минут пользователь обратится к серверу, то access-токен еще действует, и юзер получает ресурсы. Но если он отправит запрос через 11 минут, access-токен будет недействителен. Вроде бы должен произойти автоматический логаут, но refresh-токен еще остается действительным. В итоге пользователь может обратиться на эндпоинт и получить новую пару токенов. Поэтому такая схема не подходит.
На схеме ниже изображен альтернативный вариант — когда у access- и refresh-токенов одинаковый срок действия. Если в нулевой момент времени пользователь получил пару токенов и на девятой минуте законнектился к API, то эта пара токенов еще действительна. И это, по идее, должно бы обнулить счетчик и позволить юзеру обращаться к бэкенду на 19-й минут (9 истекших плюс 10 новых). Но когда клиент запросит ресурсы на 11-й минуте, его пара токенов окажется просроченной.
Поэтому придется повторно вводить креды, а значит, задача так и не решена. Что делать?
Как вариант решения, если задан достаточно длинный срок автоматического логаута (допустим, два часа), то можно оставить два часа как срок действия refresh-токена, а для access-токена этот параметр ограничить в минуту. Тогда в случае неактивности в течение «2 часов + 1 минуты» пользователя будет вылогинивать из системы. Но слишком часто менять access-токен тоже неправильно, как и менять access- и refresh-токены после каждого обращения к защищенному эндпоинту.
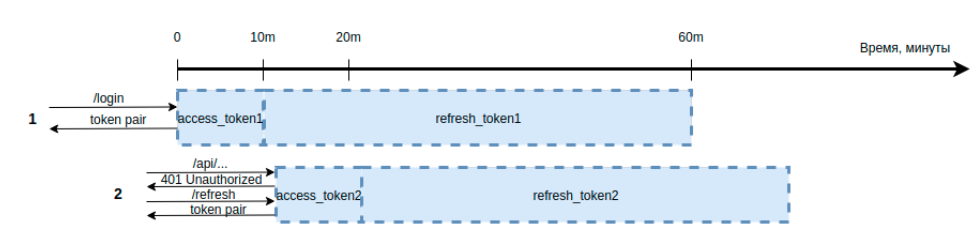
Решим эту задачу с помощью механизма автоматической экспирации записей, который реализован в key-value базе Redis. В таком случае производится манипуляция не сроком службы токенов, а сроком хранения пары токенов в базе данных. Этот параметр обозначают как TTL. На иллюстрации ниже показана такая схема.
Допустим, что автоматический логаут должен происходить после 10 минут неактивности пользователя, срок действия access-токена составляет 20 минут, а refresh-токена — 60 минут:
Наверняка кто-то скажет: «Ура, вы переоткрыли механизм сессий», и в этом есть доля правды. Токен нужен для подтверждения аутентификации пользователя. А идентификатор сесии — это признак пользовательской сессии: находится ли сейчас юзер в системе, может ли он работать с ней, или сессия завершена.
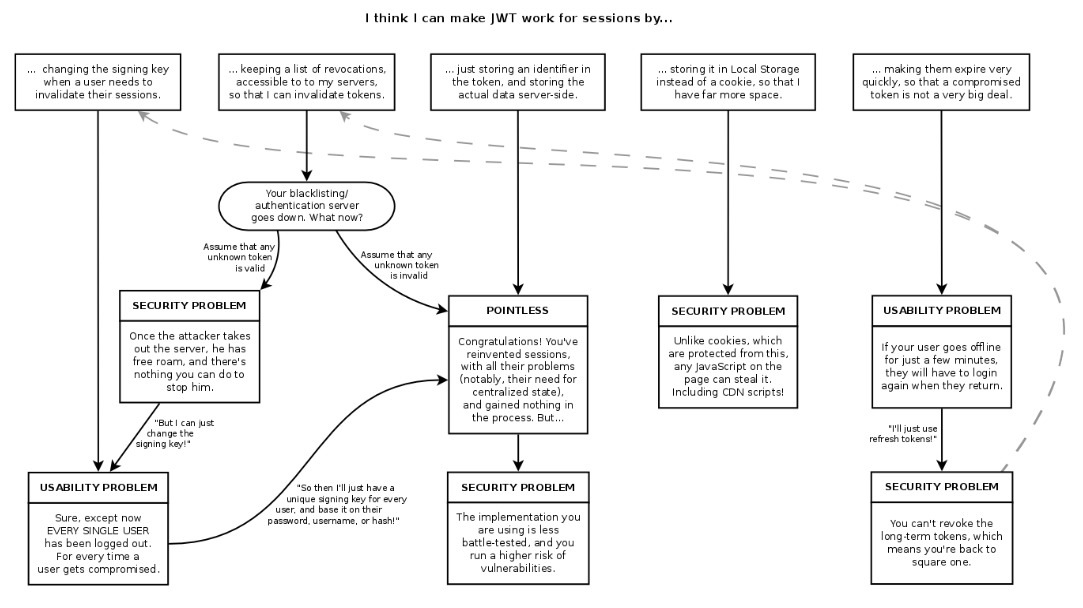
В интернете вам может попасться такая немного саркастическая картинка:
Здесь показано, как попытки использования JWT в качестве идентификатора сессии приводят к тем же проблемам, что и с сессиями. Как только пользователь хочет сделать логаут, нужно инвалидировать токен и поменять секретную строку. Но при смене этого ключа будут разлогинены все пользователи. Если же изменять секретную строку только этого пользователя, то нужно хранилище для таких ключей. В итоге все приходит фактически к воспроизведению механизма сессий. Ведь изначально JWT не требовал хранилищ, а получилось, что для решения определенных задач без них не обойтись.
Тем не менее, такой подход имеет право на жизнь. Тем более не всегда с помощью сессий можно правильно реализовать некоторые фичи.
Например, трудно распознать и показать пользователю правильное сообщение в зависимости от того, прошел ли срок действия токена или сессии, или же, пользователь произвел логин на втором девайсе, и его вылогинило из первого устройства. Поэтому с механизмом сессий придется решать те же задачи, как и с помощью токенов.
Мой совет: подходите взвешенно к выбору технологии. Все зависит от вашего проекта. Токены хороши тем, что используются повсеместно, а сессии — продуманными решениями, которые за годы использования разработчиками подтвердили свою эффективность. В качестве эксперимента можете попробовать создать смешанный вариант из двух механизмов.
И в завершении приведу best practices при использовании этого вида токенов, которых следует придерживаться:
Использование JWT — хороший инструмент с достаточно интересным кругом решаемых задач. Но в этой теме нет единственно правильных и абсолютно однозначных решений. К вопросу безопасности систем всегда нужно подходить комплексно и до мелочей прорабатывать разные варианты. Удачи!
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}