Привет всем! Меня зовут Владислав Хирса, я — Software Engineer в Grid Dynamics. Сегодня я расскажу вам, как с помощью Node.js создать поток видеоданных. Статья будет полезна тем, кто еще только начинает разбираться в теме Streams in Node.js (в конце будет немного важной теории).
Создать поток данных в Node.js сейчас просто, но все ли мы понимаем о том, как работает эта абстракция?
Найти код вы можете по ссылке.
Начнем!
Сначала запустим наш сервер, находясь в папке проекта, командой npm start.
Далее наш сервер запустится по адресу http://localhost:8000/. Перейдя по ссылке, в вашем браузере должна появиться вкладка следующего содержания:
Здесь мы можем увидеть в действии наш проект. И теперь то, ради чего мы здесь — узнать, как все работает.
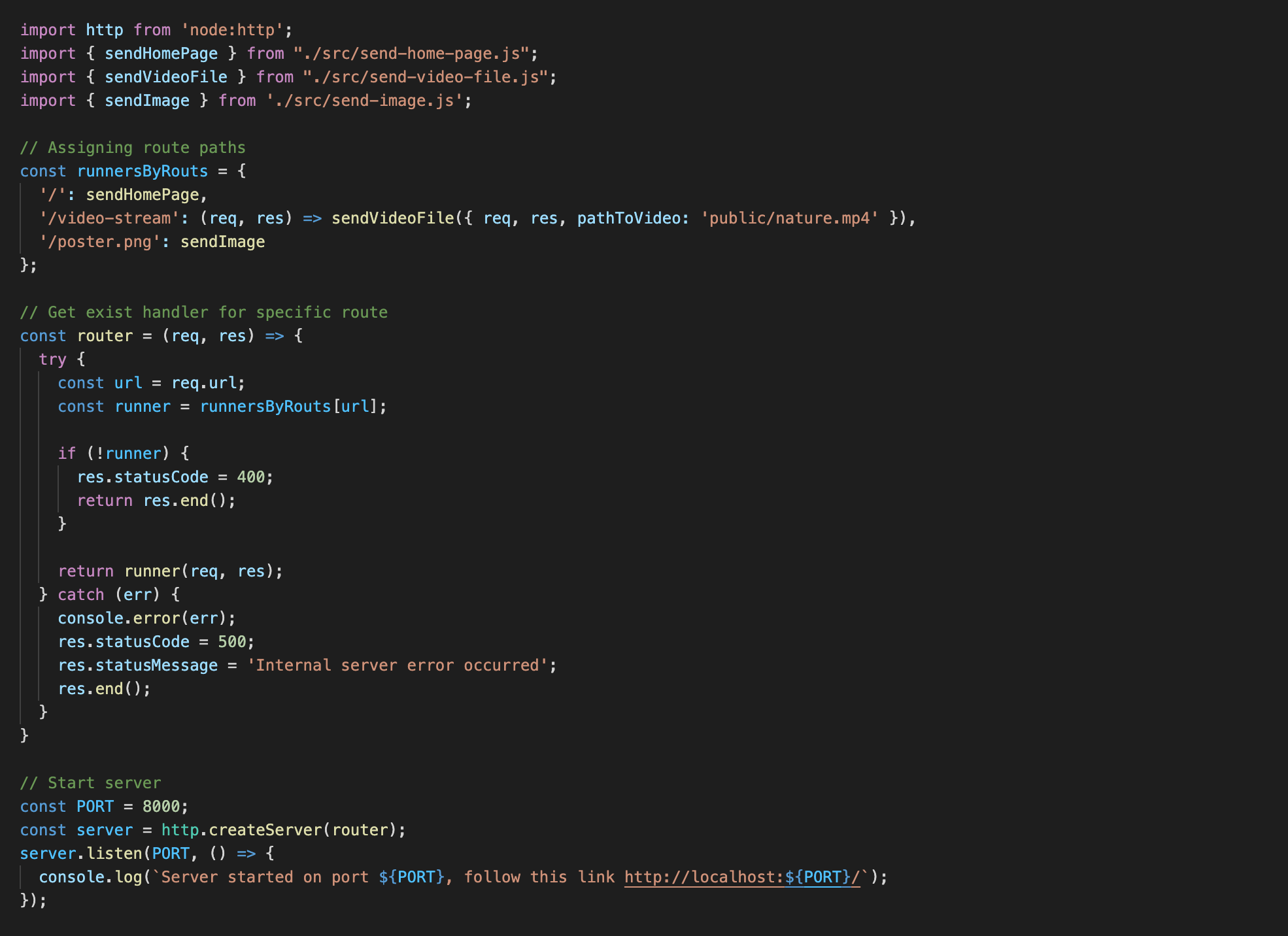
Здесь мы создали простой сервер, функцией обратного вызова назначили функцию router, получающую параметры request и response. Далее мы проверяем, имеем ли по полученному request.url совпадению в нашем объекте runnersByRouts по данному имени ключа. Если да — то вызываем соответствующую функцию, если нет — то возвращаем ответ об ошибке к клиенту.
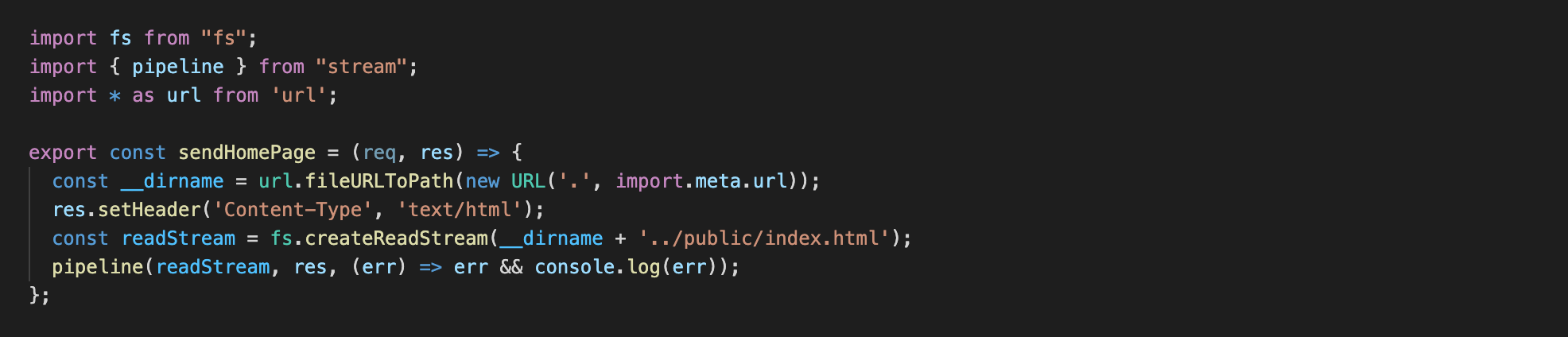
При открытии вкладки в браузере по нашей ссылке на сервер поступает запрос с url / и мы отдаем нашу страницу, файл index.html.
Сначала мы находим путь к нашей папке с помощью url.fileURLToPath(new URL('.', import.meta.url)), назначаем тип контента, который собираемся отправить клиенту res.setHeader('Content-Type', 'text/html'), далее создаем читаемый поток fs.createReadStream(__dirname + '../public/index.html')и на последней строке вызываем наш поток с помощью функции pipeline().
Пока все предельно ясно, но чуть ниже мы обсудим как все работает немного подробнее.
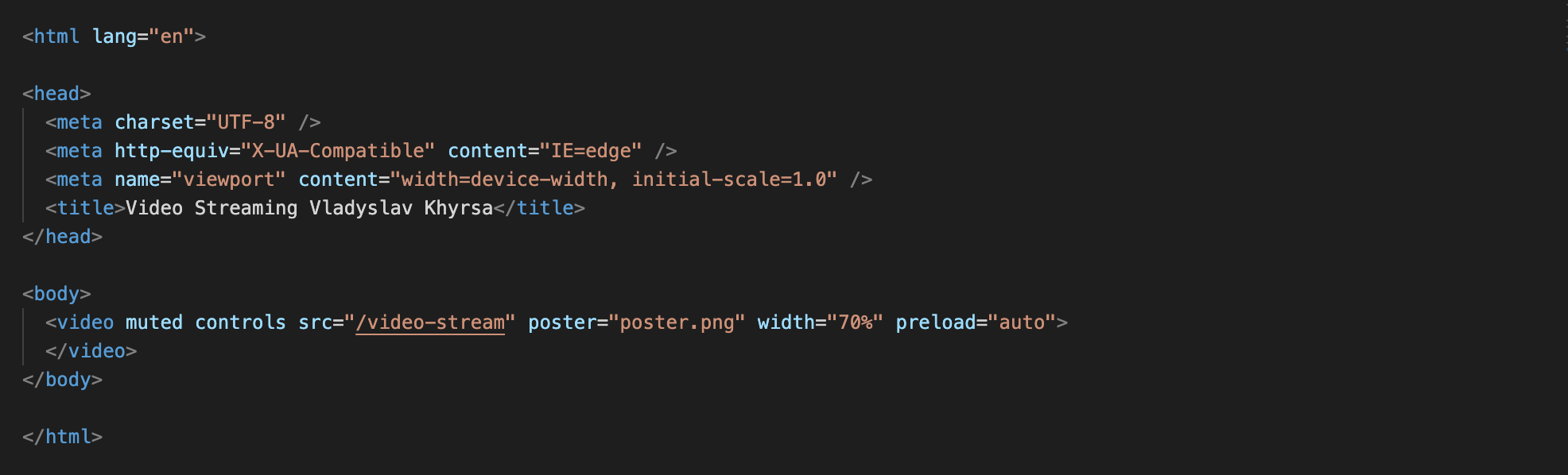
Рассмотрим несколько важных для нас атрибутов в html-элементе <video>:
src="/video-stream"— при рендеринге нашей страницы в браузере мы обращаемся к серверу по адресу http://localhost:8000/video-stream и получаем наше видео.controls— этот атрибут позволяет пользователю иметь контроль над видео (старт/пауза, звук и т.п.).preload="auto"— в спецификации указано, что весь видеофайл может загрузиться даже если пользователь не будет использовать его. Но на практике все зависит от браузера и будет происходить скорее всего более динамично. Например, да — ваше видео будет загружено примерно на 1 мин. наперед и через каждые 5 секунд воспроизведенного видео дозагрузятся еще 5 секунд и т.д.Поэтому нам поступает запрос с url /video-stream и мы вызываем нашу функцию sendVideoFile.
В нашей функции sendVideoFile все начинается с того, что:
pathToVideo. Было public/nature.mp4 — стало /your_folder/your_folder/project_folder/public/nature.mp4.fs.statSync(resolvedPath).size — узнаем размер файла в байтах.req.headers.range — получаем параметр range (bytes=12582912-), то есть то, с какой позиции нужно скачивать видео в байтах.В зависимости от браузера и проигрывателя параметр range может быть null или, например, bytes=123456-, поэтому у нас есть две различные функции для обработки этих на самом деле разных подходов.
Здесь уже все просто — код схож с тем, который мы уже рассматривали в src/send-home-page.js. Единственная разница в том, что мы назначаем обязательные заголовки Content-Type и Content-Length для того, чтобы браузер понимал, какого типа мы посылаем ему информацию и какого размера. Это необходимо как для корректной работы проигрывателя, так и для дальнейшего взаимодействия проигрывателя с сервером во время последующих транзакций данных.
И внизу также один из самых частых случаев — когда параметр range существует.
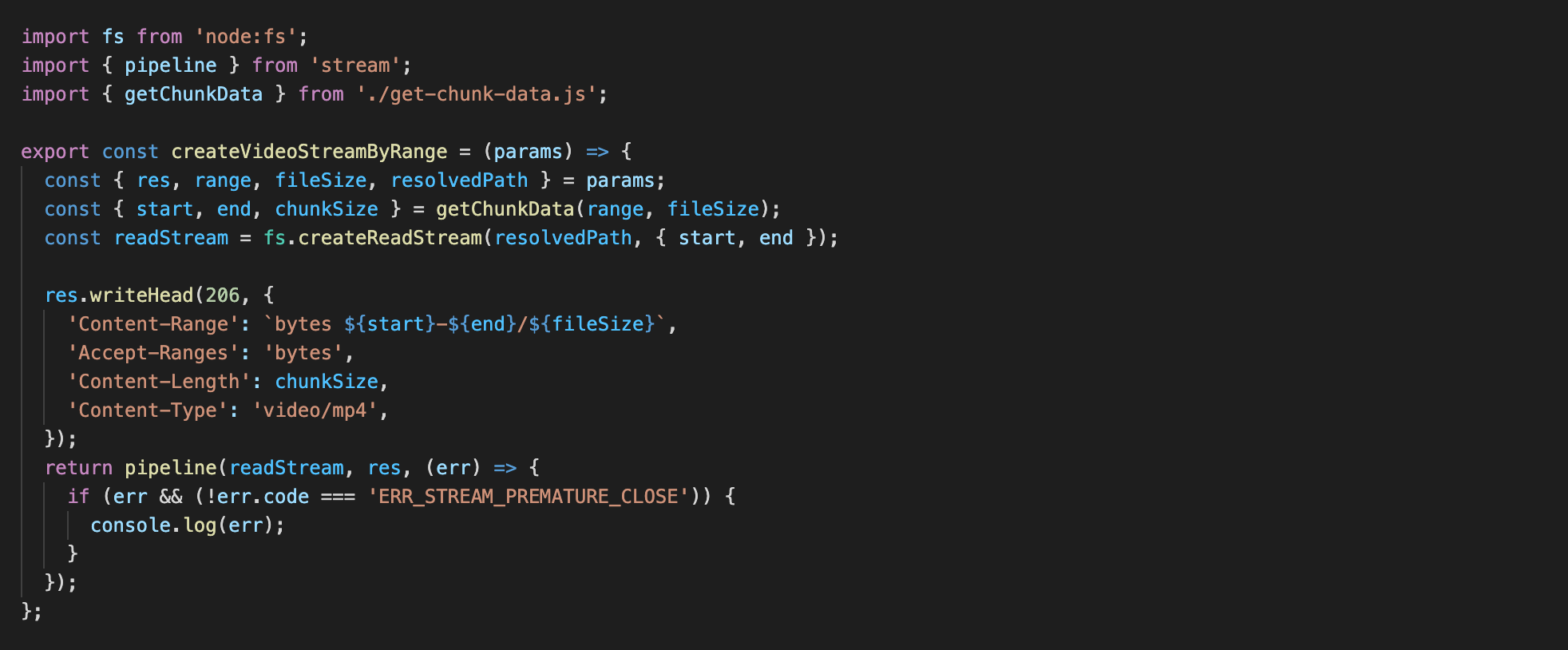
Здесь у нас есть функция getChunkData, которая принимает входящий параметр range и fileSize осуществляет следующие шаги:
range = bytes=36634624- и получает массив parts = [ '36634624', '' ].start = 36896768, end = 86890916, chunkSize = 49994149.Также createVideoStreamByRange мы указываем обязательным статус ответа 206, а также Content-Range — какую часть данных со всего видео мы отправляем, а также Accept-Ranges — в каком формате данные, которые мы отправляем.
Еще несколько дополнений, которые полезно знать:
pipeline почему лучше использовать pipeline(), а не очередь pipe() при работе с потоками. В функции pipeline() последний аргумент — функция обратного вызова. Мы использовали ее в вышеперечисленных примерах кода. Если возникнет ошибка в любом из переданных потоков, то мы ее можем обработать в одном месте. Также pipeline() самостоятельно закрывает все оконченные, но не закрытые запросы к серверу. Например, когда мы используем someReadStream(path).pipe(res), то после ошибки или окончания передачи данных запрос на сервер скорее всего не закроет, из-за чего возникают непонятные и очень веские ошибки и потеря оперативной памяти. Об этом вы можете почитать подробнее здесь.ES modules — чтобы использовать импорт функционала с помощью imports, в js-файлах нам нужно указать в package.json тип таким образом { "type": "module" }, но такие переменные, как __dirname и __filename не существуют в ES modules, а есть возможность CommonJS. С этим вы можете ознакомиться по ссылке из официальной документации. Так что найти пути мы можем следующим образом:const __filename = url.fileURLToPath(import.meta.url);
const __dirname = url.fileURLToPath(new URL('.', import.meta.url));
highWaterMark — это значение размера внутреннего буфера, то есть количество данных в байтах, которые мы можем прочитать за один раз, то есть один chunk данных (по умолчанию он 64kB). Также значение highWaterMark мы можем изменить при создании потока fs.createReadStream(path, { highWaterMark: 2 }), теперь мы считываем наш файл по два символа за раз, а также можем узнать его размер следующим образом: readStream.readableHighWaterMark, значение по умолчанию будет 65536 байтов.Сначала мы создаем поток по считыванию файла и назначаем его в смену readStream, после этого используем его в функции pipeline(), далее chunk данных передается к потоку res (т.е. response, если полностью) и тогда res его получает и отправляет клиенту с помощью res.write(chunk). Каждый раз когда мы читаем и передаем ему наши chunk данные, то в конце, когда уже нет данных для считывания, вызывается событие end для каждого потока и функция pipeline()самостоятельно закрывает их. Что очень важно, в случае res после последнего вызывается res.end() и наш запрос к серверу успешно заканчивается.
На этом все, спасибо всем за внимание. Продуктивного вам кодинга 😉
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}