Иллюстрация: Provectus
Как организовать рабочий процесс ML-команд? Как сделать так, чтобы DevOps-инженеры, которые работают над внедрением моделей машинного обучения и искусственного интеллекта, имели возможность полностью погрузиться в процесс, не беспокоясь о развертывании самой инфраструктуры? Это рассказ о внутреннем инструменте команды Provectus — SAKK — и о том, как легко и быстро начать работу с Kubeflow.
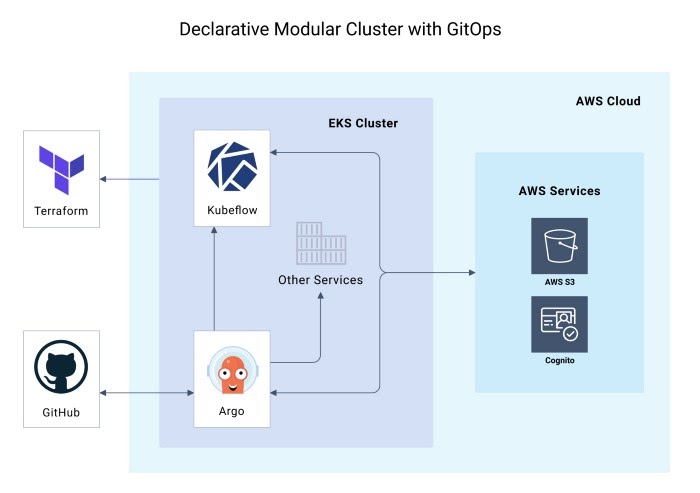
Схема управляемого кластера GitOps с Kubeflow и Argo CD внутри EKS, развернутого с использованием Terraform и SAKK. Источник: Provectus
Популярность ML-технологий (Machine Learning) устойчиво растет, а по мере увеличения числа ML-проектов растет и спрос на внедрение облачных решений.
Kubeflow — один из самых популярных инструментов для упрощения развертывания ML-проектов. Этот инструмент с открытым исходным кодом появился еще в декабре 2017-го, а с тех пор значительно вырос и окреп. Amazon для гибкого запуска и масштабирования приложений Kubernetes в облаке AWS предлагает Amazon EKS (Elastic Kubernetes Service). Amazon EKS стал общедоступным в 2018 году, сейчас это одна из ведущих сред для Kubernetes, который в свою очередь часто используется для запуска Kubeflow.
Но несмотря на широкие возможности, многие все еще не видят очевидного пути к быстрой установке и запуску Kubeflow-кластера c EKS. В Provectus эту проблему решили.
Многим компаниям, которые работают над ML/AI-проектами (клиентскими или собственными), часто приходится развертывать несколько копий Kubeflow-кластеров, а затем управлять ими и дополнять их новыми ресурсами по мере роста рабочей нагрузки на обучение и вывод. Когда над проектом работают несколько команд, им также может потребоваться изолированный доступ к конвейерам данных Kubeflow из соображений безопасности.
И хотя в одной копии Kubeflow может быть несколько конвейеров данных, пока нет способа предоставить безопасный доступ к инструменту сразу нескольким командам, работающим в одном кластере Kubeflow. Кроме этого, для каждой копии Kubeflow требуется отдельный кластер Amazon EKS. Существующие способы настройки и развертывания кластера Kubeflow EKS требуют наличия собственных инструментов для Kubeflow и Kubernetes, которые не позволяют добавлять неродные ресурсы в развернутые кластеры.
Например, если ваша компания работает над несколькими ML/AI-проектами, ей необходимо как минимум несколько кластеров с копиями Kubeflow (dev, test, рабочие среды, client stands и т. д.) для каждого проекта, а часто и для каждой проектной команды. Все эти развертывания требуют установки нескольких инструментов CLI и их отдельной настройки для Kubernetes и Kubeflow. Для каждого из кластеров необходима отдельная настройка.
Все это означает одно: надо нанимать высококвалифицированных специалистов для развертывания и обслуживания инфраструктуры машинного обучения. Они настроят несколько конфигураций кластера вручную или напишут гору скриптов. Дальнейшая поддержка и апгрейд кластера также будет требовать вмешательства профессионалов.
SAKK для Kubeflow предлагает простое решение, основанное на лучших практиках DevOps. Оно избавит вас от необходимости отдельных развертываний Kubeflow, Amazon EKS и других ресурсов, которые могут потребоваться для процесса машинного обучения.
Папка с SAKK-репозиторием играет роль готового шаблона проекта. Все, что необходимо сделать — это проверить ветку и настраивать ее каждый раз, когда необходимо развернуть Kubeflow с Amazon EKS.
ML-команды могут настраивать кластер со всем необходимым сразу, задав переменные в одном файле main.tf в корне репозитория, и разворачивать его с помощью пары Terraform-команд. Это позволит за считанные минуты запускать несколько кластеров машинного обучения, используя Terraform в качестве единой точки входа.
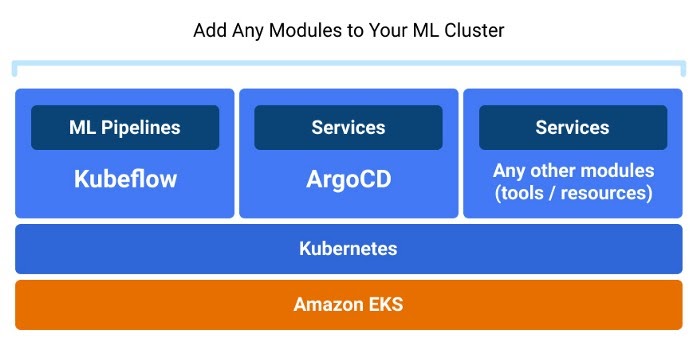
Кластер Amazon EKS с Kubeflow и Argo CD, который вы получаете в результате настройки и развертывания ML инфраструктуры с Terraform с использованием SAKK. Источник: Provectus
После развертывания кластерами можно управлять с помощью Argo CD CLI или пользовательского интерфейса. Они хранятся в репозитории GitHub с организованным CI/CD-конвейером. Такой подход позволяет пользоваться всеми преимуществами портативности и стандартизации Kubernetes и Amazon EKS.
В дополнение к этому также можно добавлять ресурсы в свои кластеры, которые не являются родными инструментами Kubeflow, Kubernetes или Amazon EKS CLI. Для этого нет никакой необходимости писать кастомный код.
Использование SAKK для настройки и развертывания кластера не требует знаний об инструментах DevOps. Это означает, что DevOps-инженеры смогут уделять больше времени решению более важных задач. SAKK дает возможность сократить время, ресурсы и затраты, связанные с развертыванием и обслуживанием ML-инфраструктуры.
Основные моменты такие:
SAKK использует Argo CD для автоматизации состояний приложений с GitOps-оператором. Состояние вашего кластера будет храниться в репозитории GitHub и сегменте S3, описанном как код.
Terraform используется для унификации и стандартизации развертывания облачной инфраструктуры с IaC — одним из лучших стандартов для ML DevOps (MLOps). Terraform позволяет создавать файлы конфигурации с применением синтаксиса HCL (HashiCorp Configuration Language). Это лучшая альтернатива случайным скриптам для работы с кластерами. Более того, у Terraform есть большое сообщество и подробная документация.
Для управления доступом в AWS SAKK использует Cognito User Pools (пулы пользователей). В кратком руководстве ниже Cognito используется для создания безопасной среды, в которой правами доступа можно управлять из одного места. Но SAKK не ограничивает вас одним провайдером, можно использовать любой другой.
Развернуть Kubeflow на EKS с помощью SAKK довольно просто. Помимо предварительных условий, потребуется еще несколько действий:
После этого вы получите доступ к кластеру с возможностью управления.
Далее установите Terraform, используйте официальный гайд:
Создайте ответвление и клонируйте SAKK для репозитория Kubeflow:
Вот и все! Осталось развернуть и настроить кластер Amazon EKS Kubeflow:
Настройка кластера осуществляется в одном файле Terraform: main.tf. Минимальные настройки конфигурации следующие:
Пример конфигурации main.tf:
terraform {
backend s3 {}
}
module "sak_kubeflow" {
source = "git::https://github.com/provectus/sak-kubeflow.git?ref=init"
cluster_name = "simple"
owner = "github-repo-owner"
repository = "github-repo-name"
branch = "branch-name"
#Main route53 zone id if exist (Change It)
mainzoneid = "id-of-route53-zone"
# Name of domains aimed for endpoints
domains = ["sandbox.some.domain.local"]
# ARNs of users who will have admin permissions.
admin_arns = [
{
userarn = "arn:aws:iam::<aws-account-id>:user/<username>"
username = "<username>"
groups = ["system:masters"]
}
]
# Email that would be used for LetsEncrypt notifications
cert_manager_email = "info@some.domain.local"
# An optional list of users for Cognito Pool
cognito_users = [
{
email = "qa@some.domain.local"
username = "qa"
group = "masters"
},
{
email = "developer@some.domain.local"
username = "developer"
}
]
argo_path_prefix = "examples/simple/"
argo_apps_dir = "argocd-applications"
} В некоторых случаях также потребуется переопределить переменные, связанные с репозиторием GitHub (репозиторий, ветка, владелец), в main.tf.
Далее можно настроить backend.hcl, в котором хранится состояние Terraform.
Пример конфигурации backend.hcl:
bucket = "bucket-with-terraform-states" key = "some-key/kubeflow-sandbox" region = "region-where-bucket-placed" dynamodb_table = "dynamodb-table-for-locks"
Кластер, который только что был настроен, развертывается с помощью следующих команд Terraform:
terraform init terraform apply aws --region <region> eks update-kubeconfig --name <cluster-name>
Эти команды позволяют:
Эти команды Terraform сгенерируют несколько файлов в дефолтной папке приложений в репозитории. Прежде чем вы начнете развертывать сервисы в кластере EKS Kubernetes, необходимо добавить их в Git и отправить в репозиторий Github.
Обратите внимание на то, что установленная конфигурация Argo CD отслеживает изменения в текущем репозитории. Когда в его папку apps вносятся изменения, они запускают процесс синхронизации. В этом случае будут созданы все объекты, помещенные в эту папку.
После этого вы сможете управлять своим кластером Kubernetes с помощью Argo CD CLI/UI или kubectl. Чтобы начать использовать kubectl (Kubernetes CLI для управления кластером), установите и настройте его. Для этого обратитесь к официальному гайду:
Итак, кластер развернут и готов к работе. В процессе развертывания были созданы две конечные точки доступа к службам в соответствии с настройками переменных вашего домена. Они находятся в файле main.tf:
Проверьте e-mail, который вы указали в переменной domains, для получения доступа к учетным данным.
Чтобы узнать больше о Kubeflow и Argo CD, ознакомьтесь с соответствующей официальной документацией:
После успешного входа в кластер Amazon EKS через kubectl, вы попадете в панель управления Kubeflow:
В разделе Pipelines есть несколько примеров конвейеров. Чтобы узнать больше об использовании Kubeflow в AWS, ознакомьтесь с официальной документацией.
Также можно загружать собственные конвейеры, используя AWS SageMaker и Kubeflow. Например, давайте загрузим демо-модуль с одним из встроенных алгоритмов AWS SageMaker.
Создайте папку для управления отдельными состояниями Terraform (с ресурсами, связанными с выполнением конвейера) и добавьте файл main.tf со следующим кодом:
module kmeans_mnist {
source = "path/to/kmeans-mnist-pipeline/folder/at/root/of/the/project"
cluster_name = "<your-cluster-name>"
username = "<your-kubeflow-username>"
} Запустите Terraform:
terraform init terraform apply
Terraform сгенерирует файл training_pipeline.yaml и создаст учетную запись Kubernetes, которая будет соответствовать вашему имени пользователя Kubeflow и иметь все необходимые AWS разрешения для запуска конвейера.
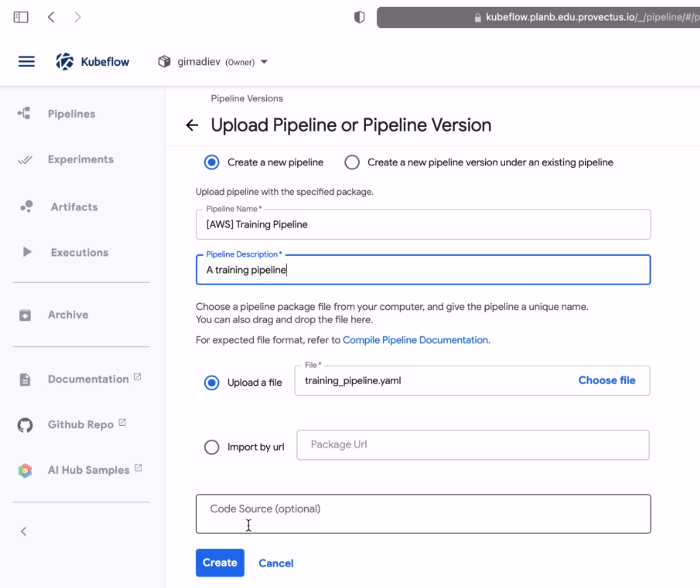
Загрузите конвейер в Kubeflow через раздел Pipelines:
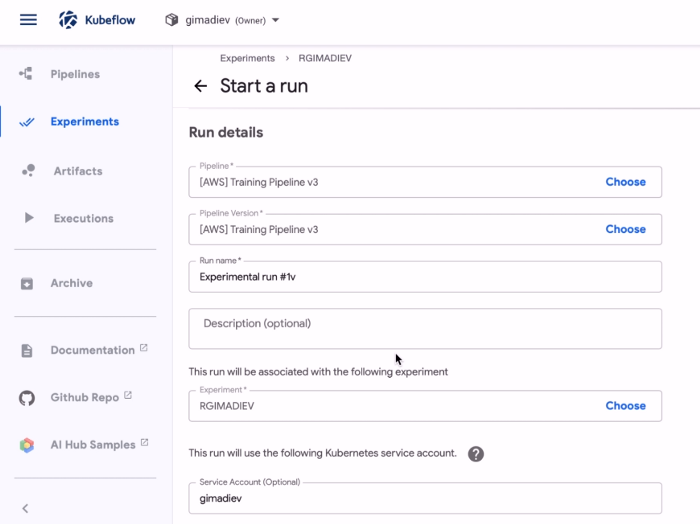
Теперь, когда у вас есть первый конвейер и учетная запись в Kubernetes, укажите их в форме, чтобы начать запуск:
Готово! Теперь у вас есть запущенный конвейер в Kubeflow.
SAKK продолжит развиваться в соответствии с Roadmap. В ближайших планах разработчиков — сделать больше ресурсов, которые будут настраиваться через Terraform (в main.tf):
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}