Hi-Tech futuristic user interface head up display screen with digital data and information display for digital background. Computer desktop display screen concept
Невозможно точно узнать, что происходит внутри удаленной или распределенной системы, даже если они запущены на локальном ПК. Именно телеметрия предоставляет всю информацию о ходе внутренних процессов. Эти данные могут быть в виде логов, метрик или Distributed Trace.
В блоге поговорим отдельно о каждом из этих форматов, а также рассмотрим, чем полезен протокол OpenTelemetry и как вы можете гибко настроить телеметрию.
Большая IT-система и даже некоторые виды бизнеса не могут существовать без телеметрии. Поэтому этот процесс следует поддерживать и внедрять в проекты, если его нет.
Простейший тип данных в телеметрии. Логи бывают двух типов:
Обычно логовать все данные не нужно. Оцените систему, найдите (если этого не сделали) наиболее уязвимые и ценные части системы. Скорее всего, там нужно добавить логов. Иногда вам нужно будет использовать логориентированное программирование. В моей практике был проект десктопного приложения на WPW, плохо работавший с потоками. Единственный шанс увидеть, что происходило – логовать каждый шаг.
Более сложные данные по сравнению с логами. Могут быть ценны и для команды разработки, и для бизнеса. Метрики также выделяют автоматические и мануальные:
Эти данные необходимы для работы с распределенными системами, находящимися не на одном инстансе. То есть, мы не знаем, какой инстанс и какого сервиса обрабатывает тот или иной реквест в определенный промежуток времени. Все зависит от построения системы. Здесь возможны следующие варианты:
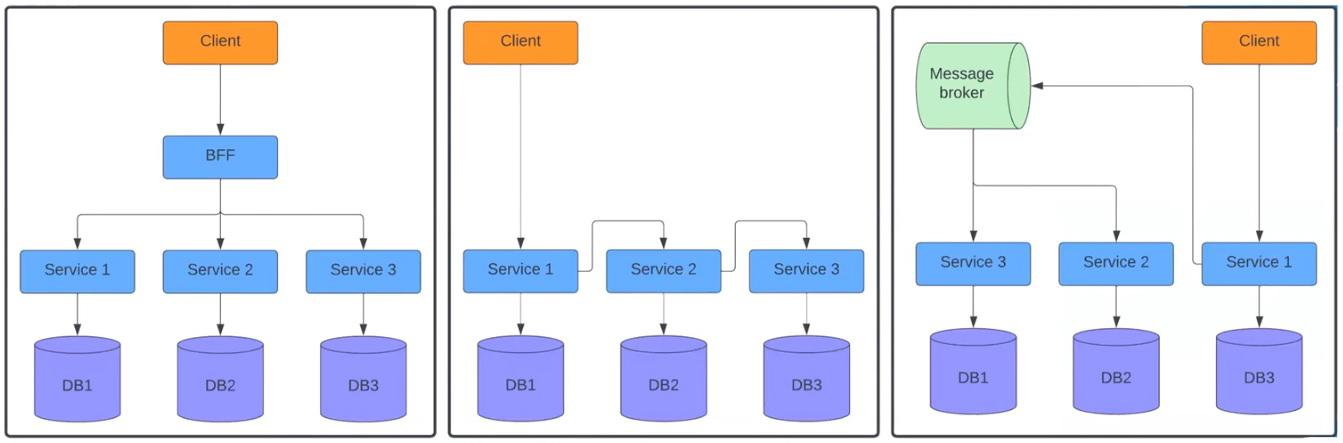
На первой схеме слева клиент посылает реквест в BFF, а тот – отдельным трем сервисам. В центре показана ситуация, когда реквест поступает в первый сервис, отправляющий его во второй, а тот уже в третий. Схема справа отображает, как сервис посылает реквесты в Message Broker. Далее он распределяет их между вторым и третьим сервисами.
Думаю, вы сталкивались с подобными системами, и примеров можно привести множество. Эти схемы сильно отличаются от монолитов. В системах с одним инстансом нам известен стек вызовов от контроллера к базе данных. Поэтому можно относительно легко обнаружить, где и что произошло в течение определенного API call. Скорее всего, эту информацию предоставляет фреймворк.
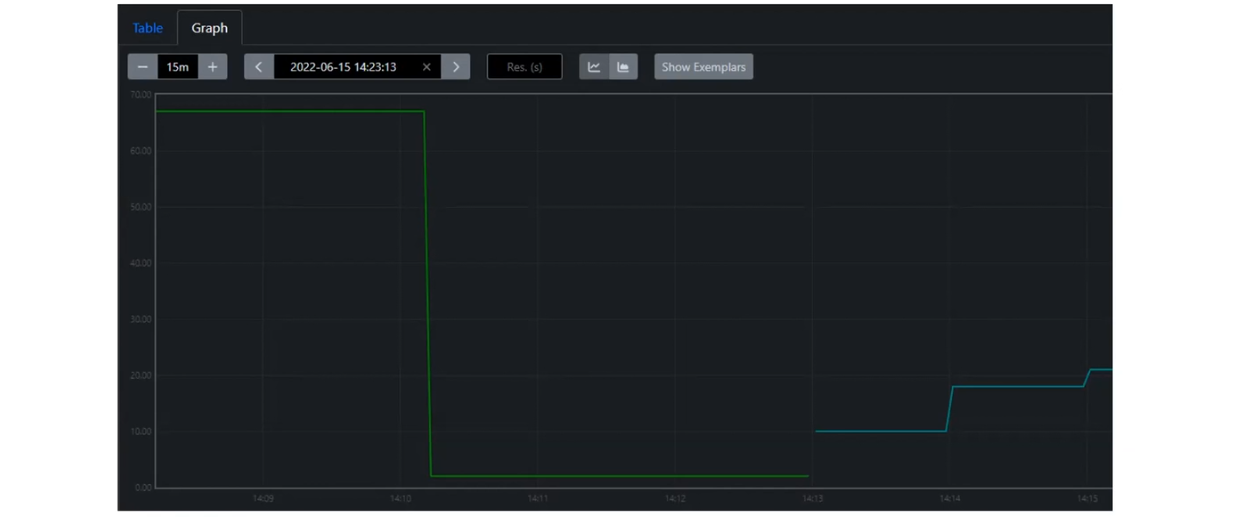
Но в распределенных системах невозможно увидеть весь флоу. Каждый сервис имеет отдельную систему логирования. При отправке реквеста на BFF мы видим, что произошло внутри, но не знаем, что происходило в сервисах 1, 2 и 3. Именно для такой ситуации придумали Distributed Trace. Вот пример работы:
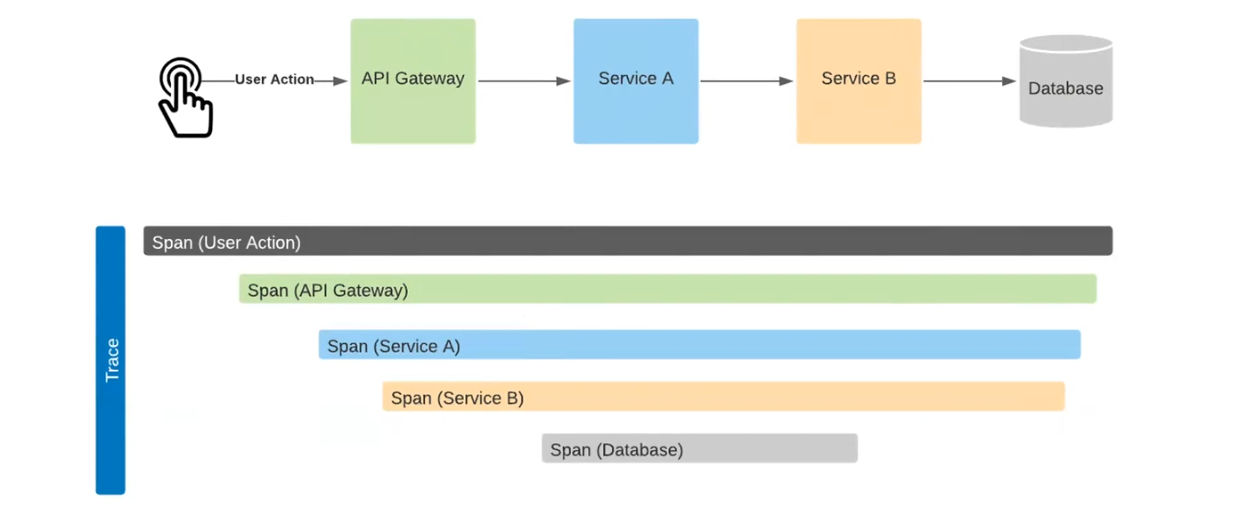
Разберем подробно. Здесь User Action идет на API Gateway, затем – на сервис А, далее – на сервис В. В результате создается вызов в базу данных. При их отправке в систему на выходе получим сходную с приведенной схему.
Здесь хорошо видна продолжительность каждого процесса: от User Action до Database. К примеру, видим, что вызовы шли один за другим. Время между вызовом API Gateway и Service A пришлось скорее на этап HTTP-соединения. Время между вызовом Service B и Database понадобилось на сэтап в базу данных и обработку данных. Так что можно оценить, где и сколько времени потрачено на каждую операцию. Это возможно благодаря механизму Correlation ID.
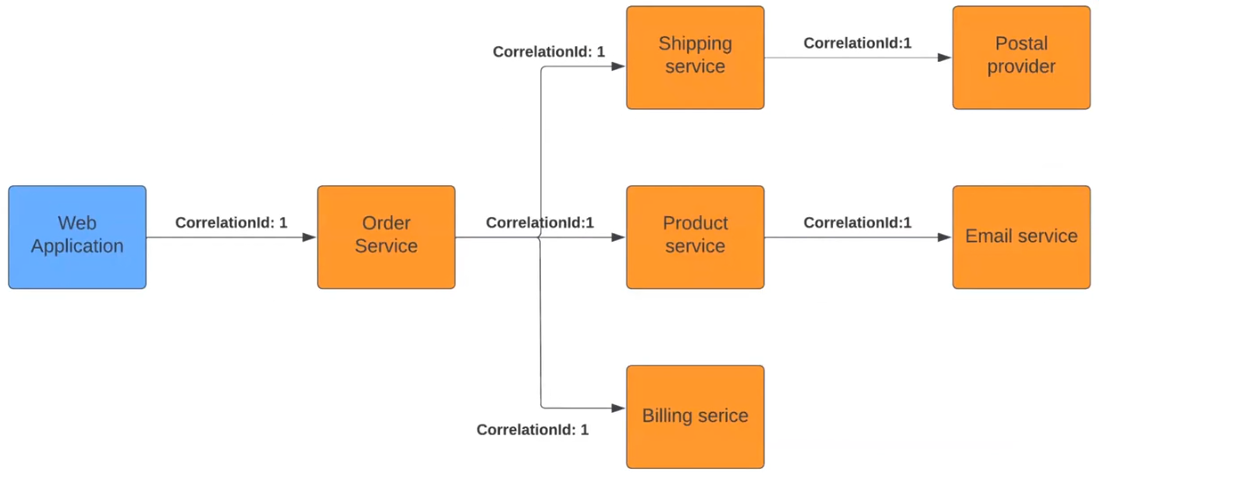
В чем суть? Обычно в монолитных приложениях при логовании система привязывает логи и экшены к process ID или thread ID. Здесь механизм тот же, но мы его искусственно добавляем к реквестам. Посмотрим на пример:
При старте в Web Application экшена Order Service он видит добавленный Correlation ID. Так сервис понимает, что он является частью цепочки, и передает маркер дальше следующим сервисам. Они, со своей стороны, понимают себя как часть большого процесса. В результате каждый элемент будет логовать данные так, чтобы система видела все происходящее в течение многоэтапного экшена.
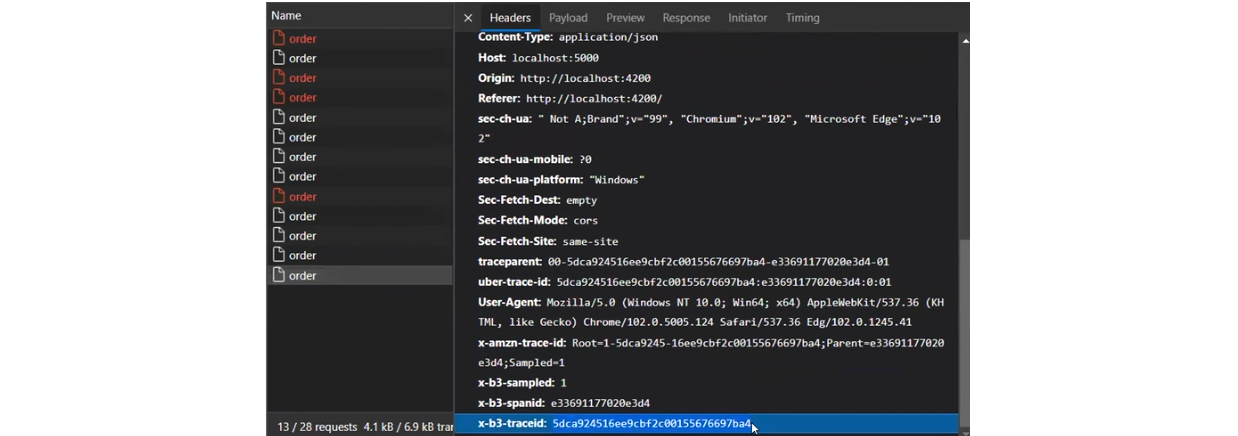
Передача Correlation ID может происходить по-разному. Например, в HTTP эти данные чаще всего передаются как один из параметров хедеров. В сервисах Message Broker обычно записывается внутри месседжа. Хотя, возможно, в каждой платформе есть SDK или библиотеки, которые помогут реализовать этот функционал.
Часто формат телеметрии старой системы не поддерживается в новой. Это приводит ко многим проблемам при переходе с одной системы в другую. Например, так было с AppInsight и CloudWatch. Данные не группируются, а значит, что-то работает не так.
OpenTelemetry позволит обойти следующие проблемы. Это протокол передачи данных посредством объединенных библиотек OpenCensus и OpenTracing. Первую создавали разработчики Google для сбора метрик и трейсов, вторую – специалисты Uber только для трейсов. В какой-то момент компании поняли, что работают фактически над одной задачей. Потому решили объединить усилия и сделать универсальный формат отображения данных.
Благодаря протоколу OTLP логи, метрики и трейсы посылаются в едином формате. Согласно репозиторию OpenTelemetry, сегодня известные IT-гиганты контрибьютят этот проект. Он пользуется спросом в продуктах, собирающих и отображающих данные (например, Datadog и New Relic). Также он помогает в системах, которым нужна телеметрия (Facebook, Atlassian, Netflix и другие).
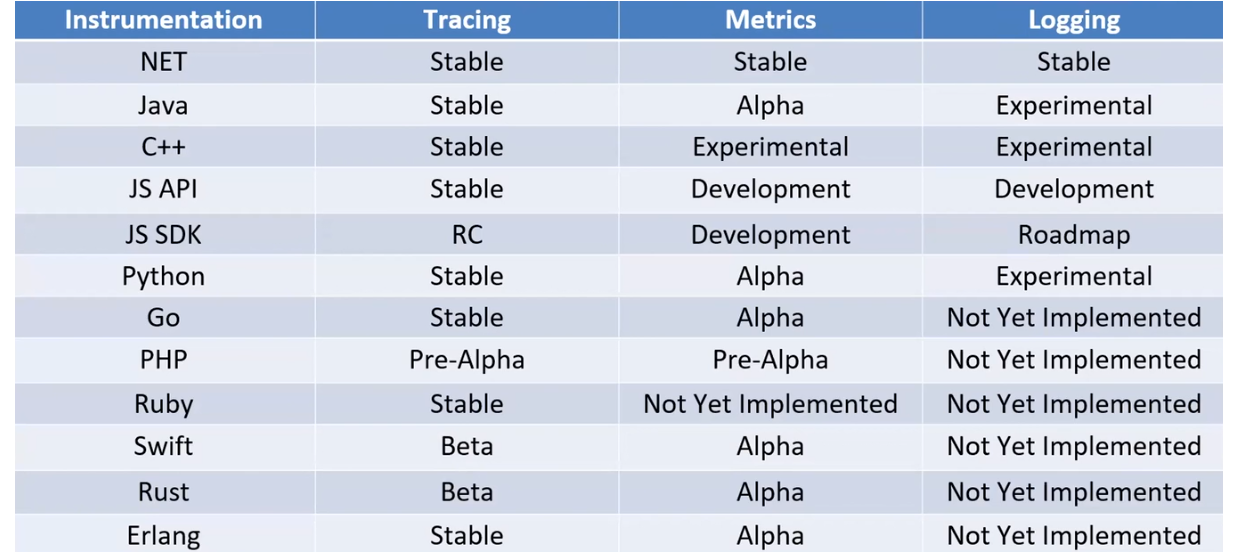
Есть много SDK для популярных языков программирования. Однако все они имеют разные возможности. Обратите внимание на таблицу. Трейсинг имеет стабильные версии повсеместно, кроме PHP и JS SDK. А вот с метриками и логами до сих пор не очень хорошо во многих языках. Где-то есть только альфа-версии, где-то экспериментальные, иногда вообще не реализована имплементация протокола. По собственному опыту скажу, что на сервисах на .NET все работает нормально. Здесь и простое подключение, и надежность логования.
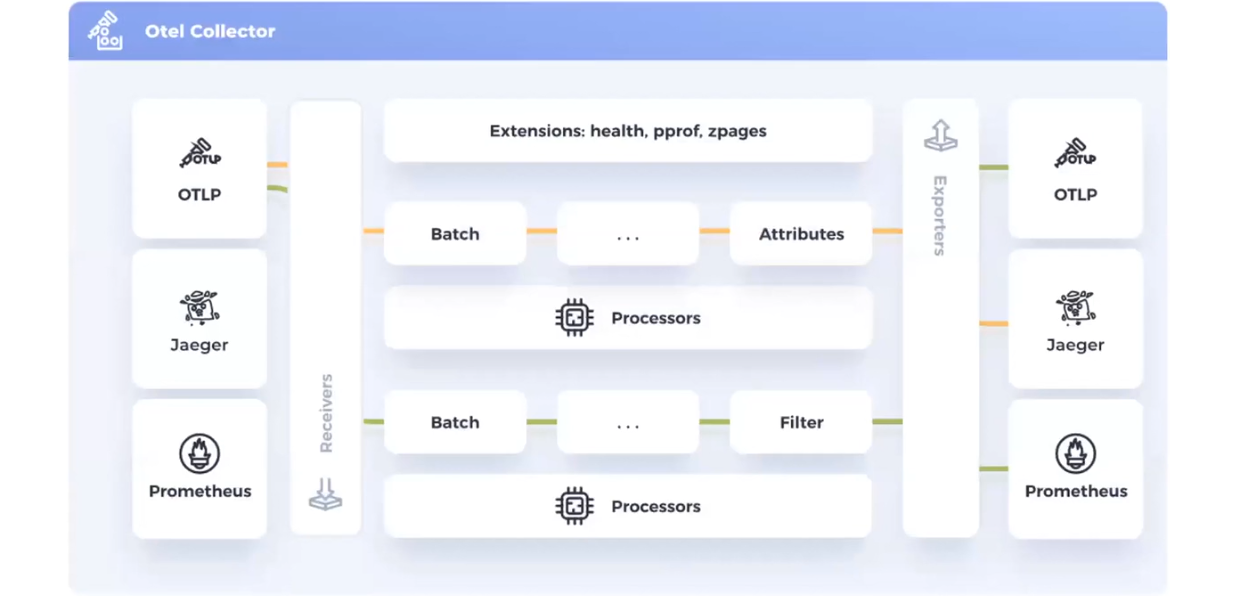
Коллектор состоит из четырех компонентов:
health_check. С его помощью можно посылать реквест на эндпоинт и понять, работает ли коллектор. Экстеншены показывают многое: сколько ресиверсов и экспортеров в системе, как они работают и т.д.На этой схеме есть два типа данных — метрики и логи (обозначенные разными цветами). Логи идут через свой процессор в Jaeger. Метрики следуют через другой процессор, имеют свой фильтр и отправляются в два источника данных: OTLP и Prometheus. Это дает гибкие возможности анализа данных. Ведь разный софт имеет разные способы демонстрации телеметрии.
Интересный момент: данные можно принимать из OpenTelemetry и отправлять их туда же. То есть в определенных случаях одинаковые данные вы можете отправлять в один и тот же коллектор.
Есть много способов, как построить систему сбора телеметрии. Одна из самых простых схем изображена на иллюстрации ниже. Здесь есть один .NET-сервис, который посылает OpenTelemetry сразу в New Relic:
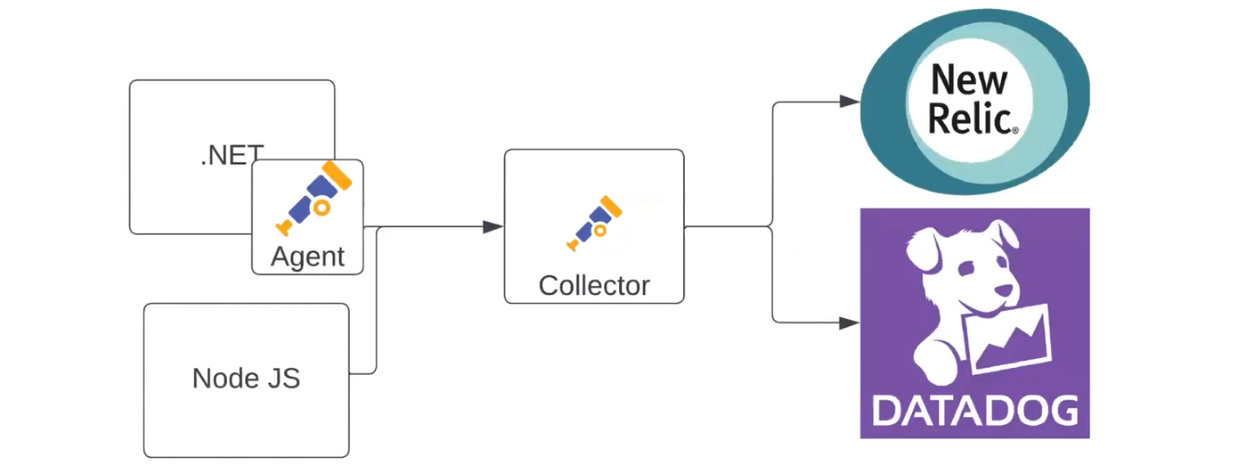
При необходимости схему можно дополнить агентом. Он может выступать в качестве хост-сервиса или бэкграунд-процесса внутри сервиса, собирать данные и отправлять их в New Relic:
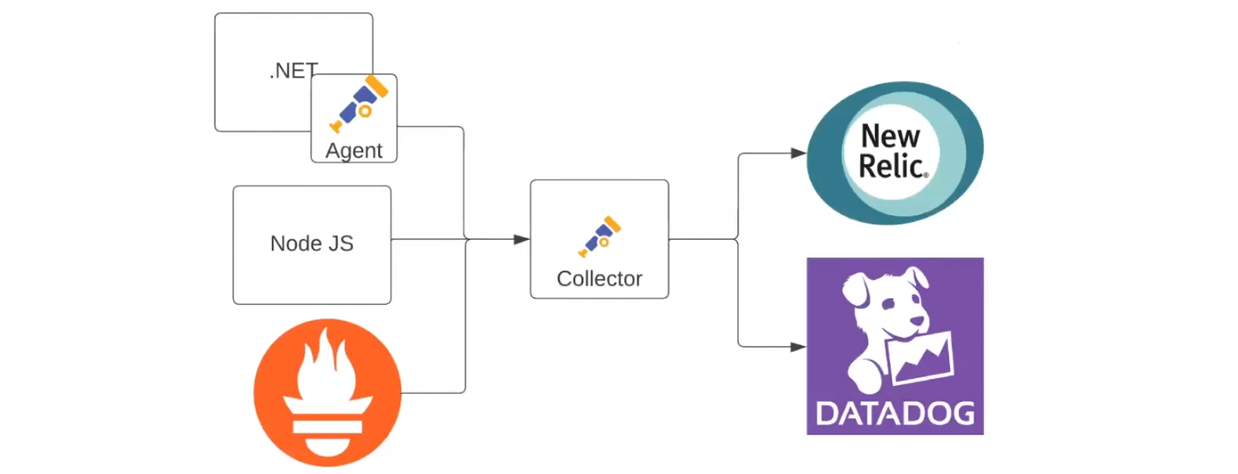
Идем дальше – добавляем в схему еще одно приложение (например, на Node JS). Оно будет передавать данные напрямую в коллектор. А первое будет делать это через собственного агента с помощью OTLP. Коллектор будет отправлять данные уже в две системы. Например, метрики будут идти в New Relic, а логи — в Datadog:
Сюда можно добавить Prometheus как источник данных. К примеру, когда в команде появился человек, который любит этот инструмент и хочет использовать его. Здесь данные все равно будут собираться в New Relic и Datadog:
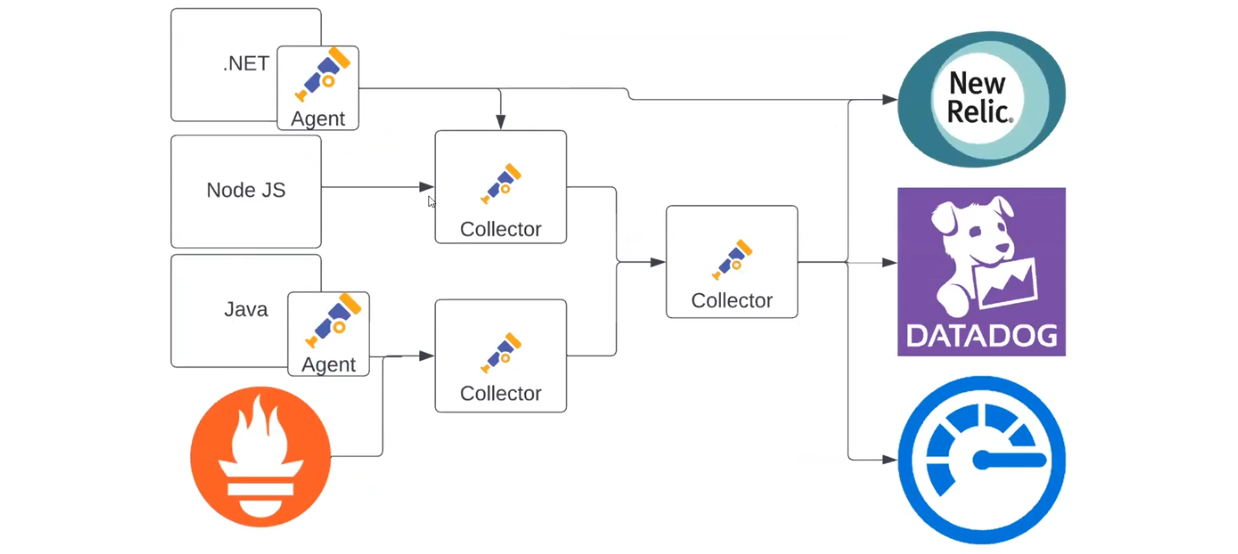
Систему телеметрии можно усложнять до бесконечности, адаптируя ее под свой проект. Вот еще один пример:
Здесь есть несколько коллекторов, каждый из которых собирает данные по-своему. Агент в .NET-приложении отправляет данные в New Relic и в коллектор. При этом один коллектор может отправлять информацию в другой, так как OTLP посылается другому источнику данных. Он может делать с ними что угодно. В результате первый коллектор отфильтровывает нужные данные и передает следующему. Последний – распределяет логи, метрики и трейсы между New Relic, Datadog и Azure Monitor. Благодаря этому механизму анализировать телеметрию можно так, как удобно вам.
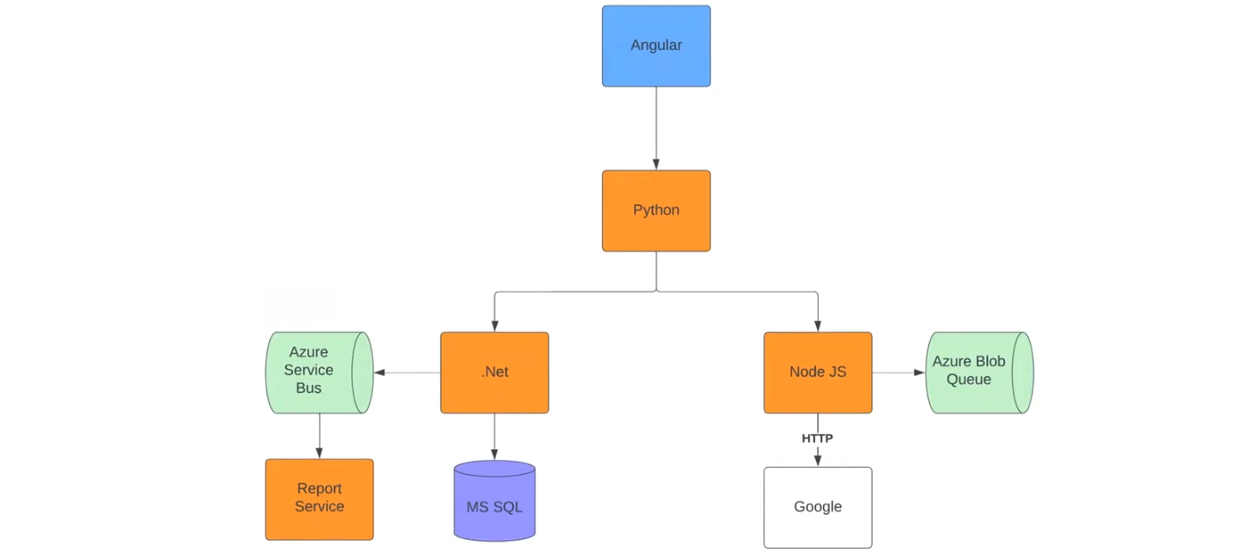
Прежде всего, это гибкость. Рассмотрим данное свойство на практике. Для этого тестирования я сделал проект по приведенной схеме:
Все начинается с Angular-приложения, которое отправляет HTTP-реквесты в Python-приложение. Тот со своей стороны посылает реквесты в приложения на .NET и Node JS. Они работают по своим сценариям. Приложение на .NET отправляет в Azure Service Bus реквесты и хендлит их в Report Service.
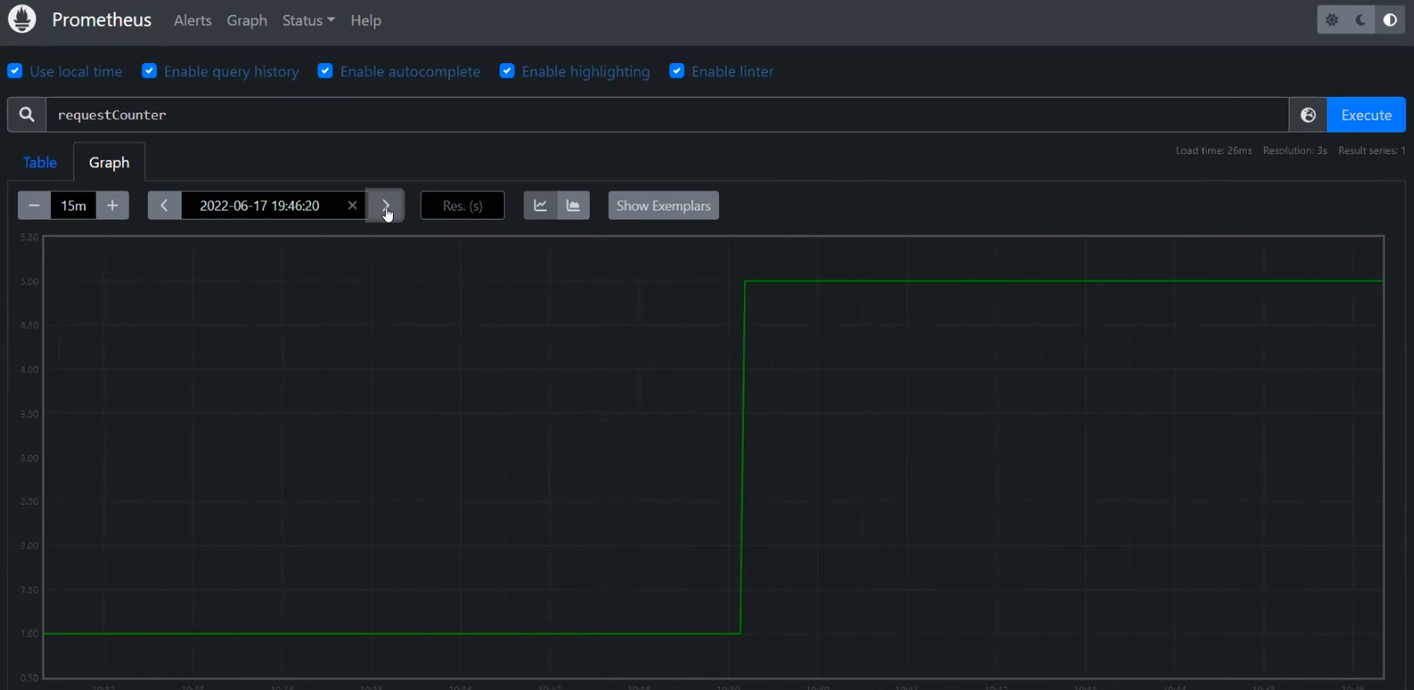
Затем посылает метрики о том, сколько реквестов он обработал. Дополнительно .NET отправляет реквесты в MS SQL. Реквести Node JS идут в Azure Blob Queue и Google. То есть система эмулирует какую-нибудь работу. Во всех приложениях используются автоматические системы отправки трейсов в коллектор.
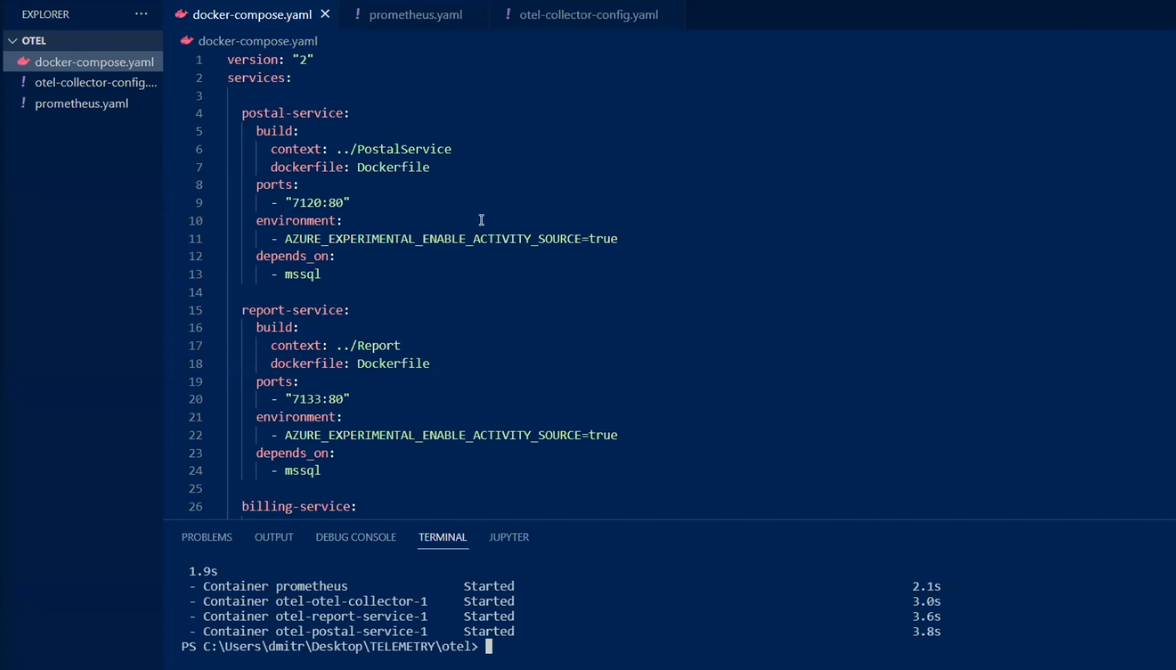
Начнём с разбора docker-compose файла.
Здесь собран этап нескольких сервисов BFF. Среди закоменченых – Jaeger, помогающий смотреть трейсы.
Предусмотрен еще один софт для просмотра трейсов – это Zipkin.
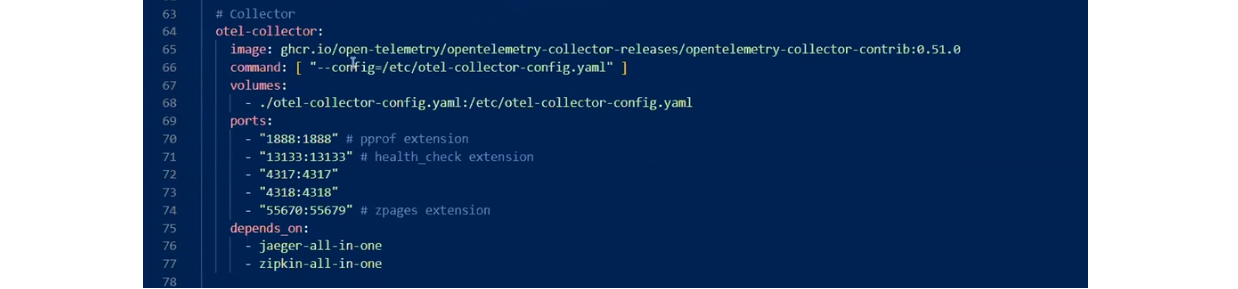
Также есть MS SQL и собственно коллектор. В последнем указан config-файл и много портов, на которые можно что-то отправлять.
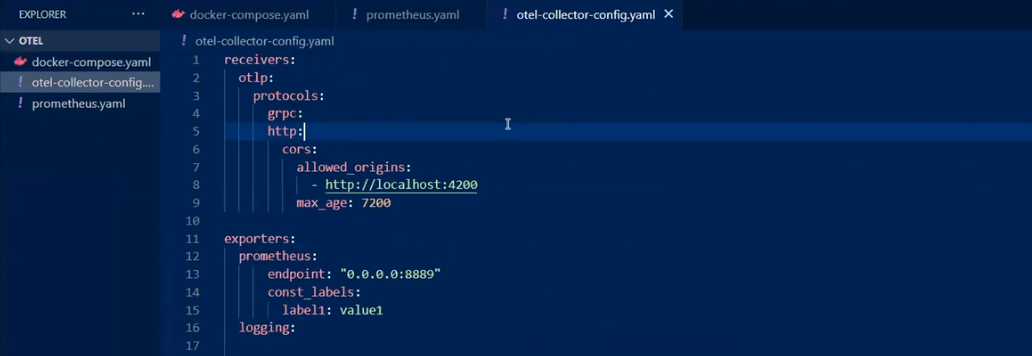
Сonfig-файл содержит набор главных топиков: recievers, exporters, processors, extensions. Завершает все service. Он выступает как конструктор всего этого.
Ресивер один. Это otlp, то есть именно Open Telemetry Protocol. Хотя можно подключать и другие ресиверы (например, Prometheus). Ресивер можно конфигурировать. Предположим, сетить allowed_origins, как в моем примере.
Следующий элемент – экспортеры. С ними можно отправлять метрики в Prometheus.
health_check. Он является эндпойнтом, проверяющим активность коллектора.
pipelines, traces, metrics. С ними понятно, какой тип данных откуда берется, чем он обрабатывается, куда отправляется. В этом примере трейсы из ресивера отправляются для логования на два бекенда, а для метрик используется Prometheus.
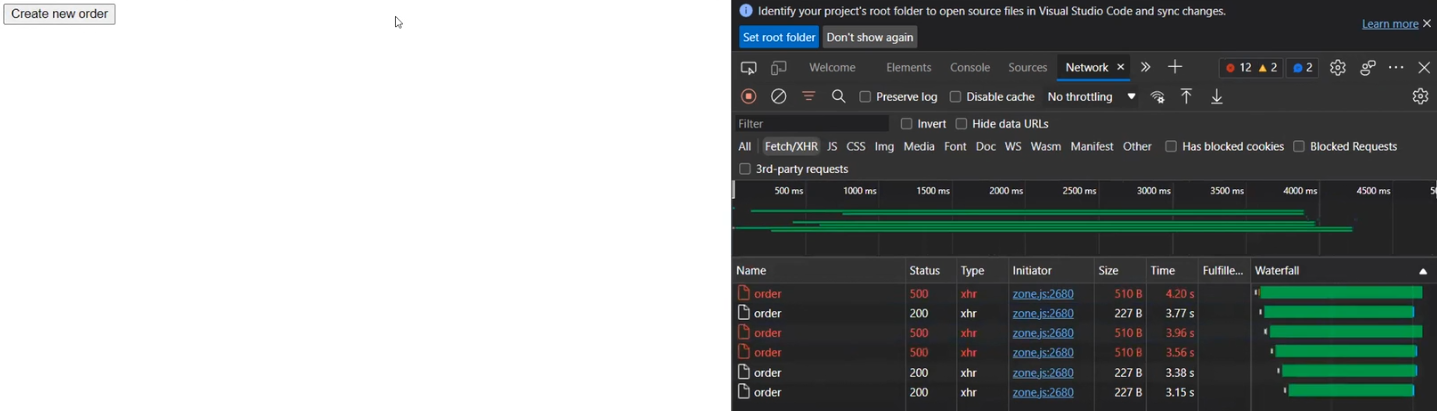
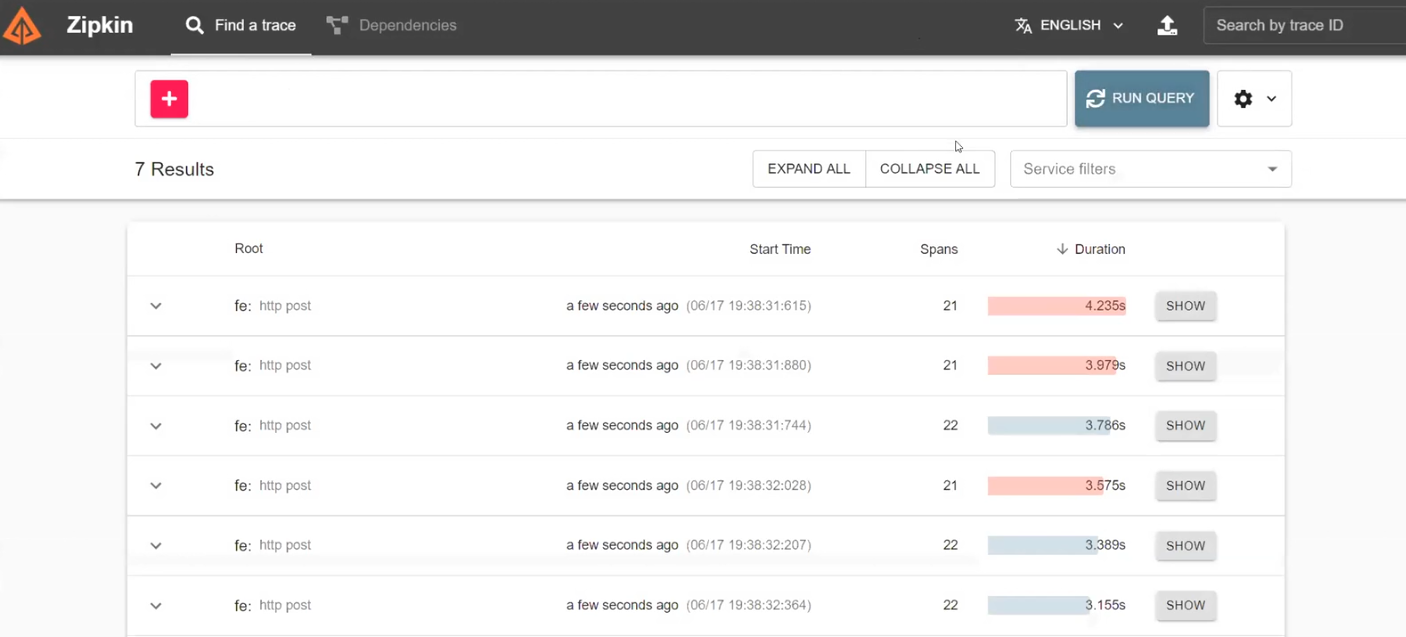
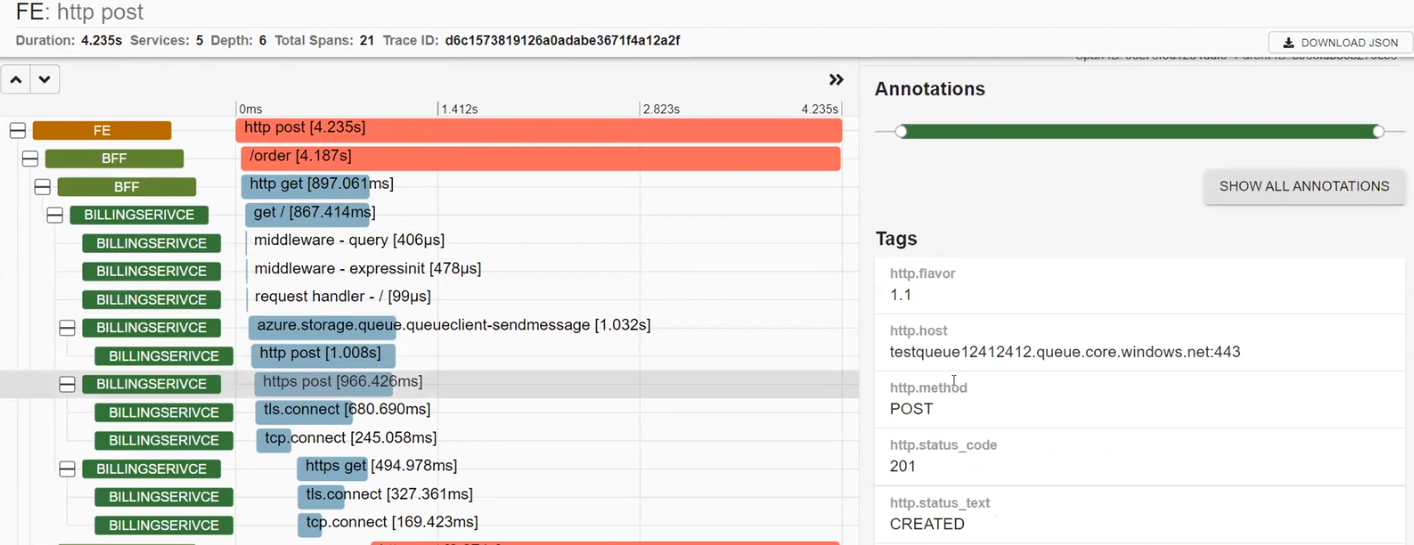
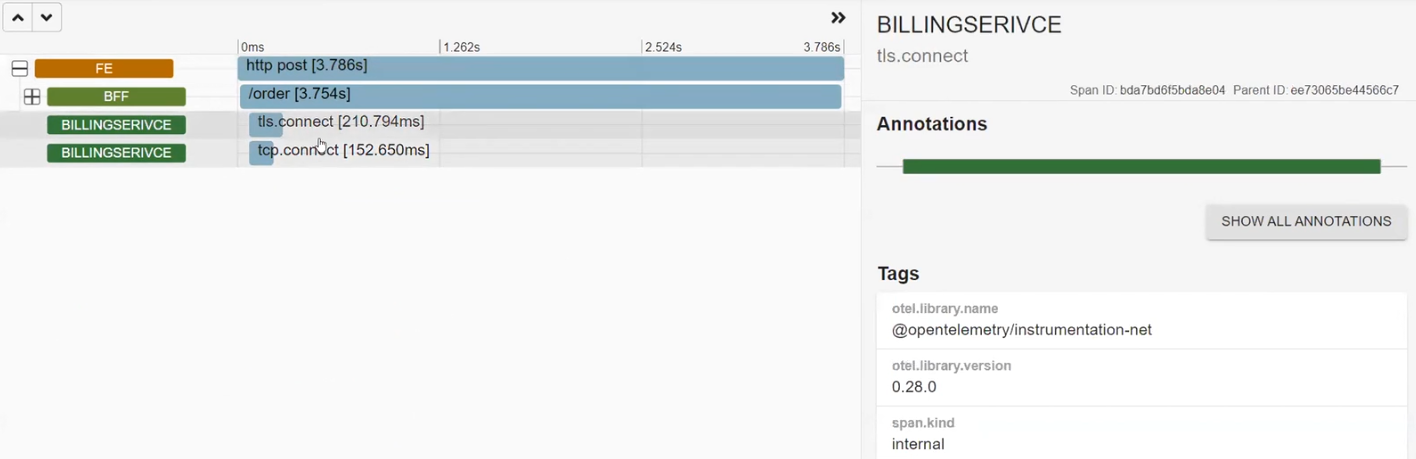
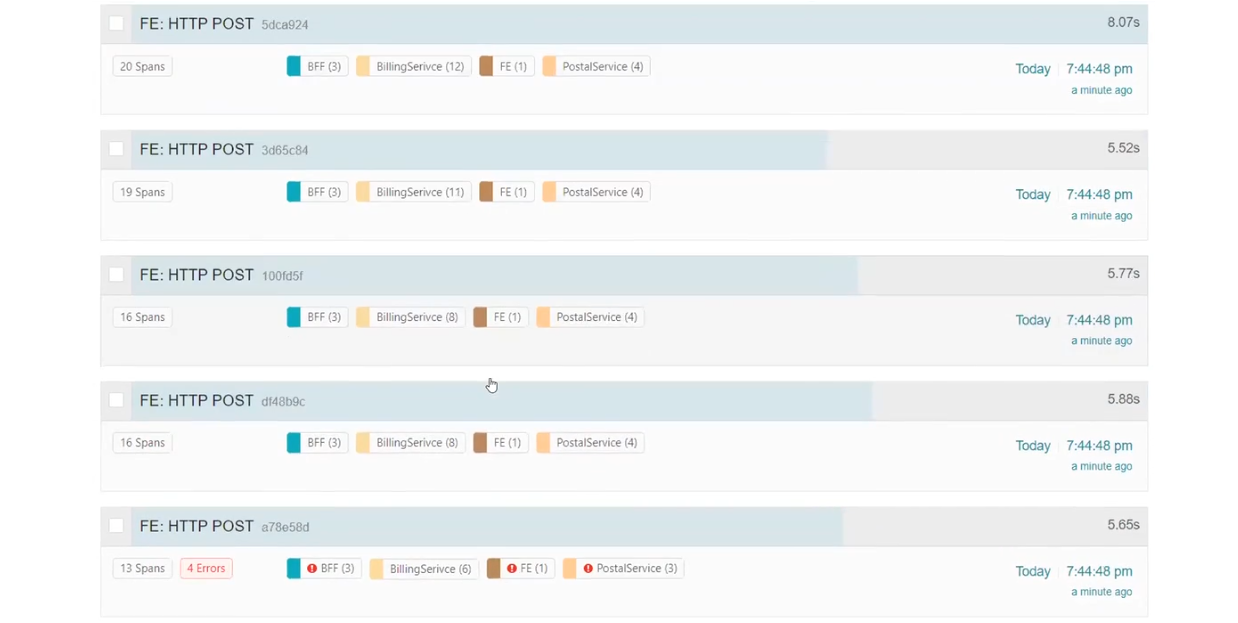
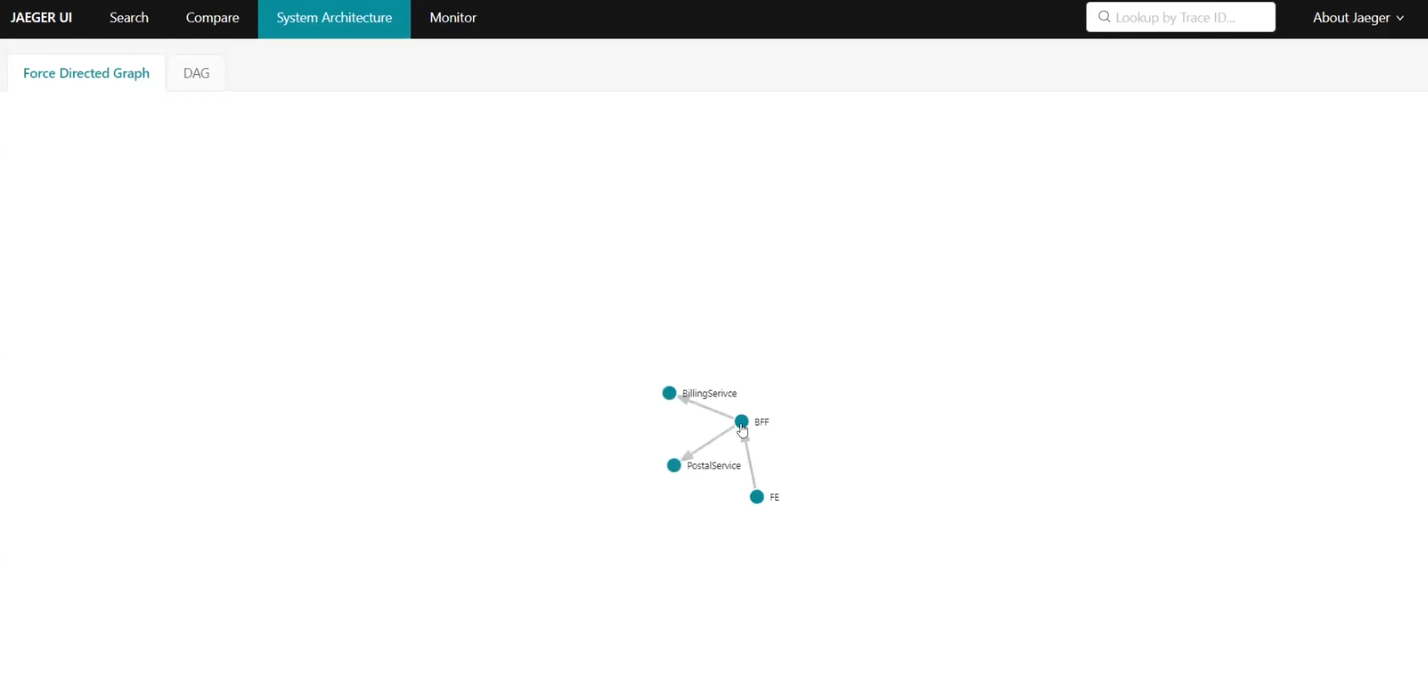
Разберем, как это работает в действительности. Фронтенд посылает реквесты в бэкенд, а бэкенд использует BFF для отправки реквестов. Создаем круг и видим результаты. Среди них, например, есть некоторые реквесты со статусом 500.
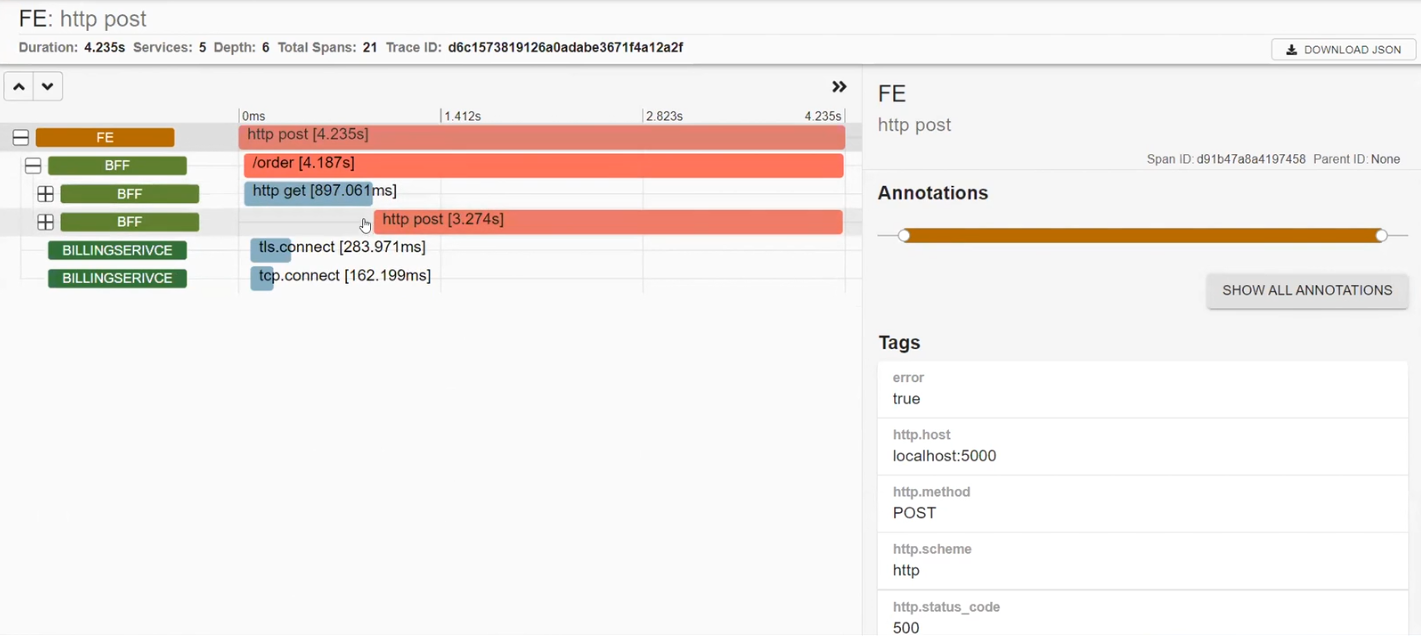
BFFвызвал BILLINGSERVICE. В нем работают middleware, посылается реквест в Azure и есть http.post, который отправлялся в Azure. В результате получен статус CREATED. Далее система сетапила и отправляла реквест в Google.
POSTALSERVICE, в котором упал один реквест. Посмотрим на него внимательнее и увидим описание ошибки: ServiceBusSender has already been closed…Поэтому в следующий раз нужно быть осторожным с ServiceBusSender. Также здесь можно увидеть отправку нескольких запросов на MS SQL.
А еще вспомним о health_check. Он покажет, работает ли наш коллектор вообще.
Поэтому преимущества использования OpenTelemetry Protocol очевидны. Это гибкая система сбора, обработки и отправки телеметрии. Особенно удобно в сочетании с Docker, который я использовал при создании этого демо.
Однако всегда помните об ограничениях OTLP. В случае с трейсами все достаточно хорошо. А целесообразность использования этого протокола для метрик и логов зависит от готовности библиотек и SDK конкретной системы.
If you have found a spelling error, please, notify us by selecting that text and pressing Ctrl+Enter.
В благословенные офисные времена, когда не было большой войны и коронавируса, люди гораздо больше общались…
Вот две истории из собственного опыта, с тех пор, когда только начинал делать свою карьеру…
«Ты же программист». За свою жизнь я много раз слышал эту фразу. От всех. Кто…
Отличные новости! Если вы пропустили, GitHub Copilot — это уже не отдельный продукт, а набор…
Несколько месяцев назад мы с командой Promodo (агентство инвестировало в продукт более $100 000) запустили…
Пару дней назад прочитал сообщение о том, что хорошие курсы могут стать альтернативой классическому образованию.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}