


Невозможно точно узнать, что происходит внутри удаленной или распределенной системы, даже если они запущены на локальном ПК. Именно телеметрия предоставляет всю информацию о ходе внутренних процессов. Эти данные могут быть в виде логов, метрик или Distributed Trace.
В блоге поговорим отдельно о каждом из этих форматов, а также рассмотрим, чем полезен протокол OpenTelemetry и как вы можете гибко настроить телеметрию.
Телеметрия – для чего нужна?
- Отображает текущее и предыдущее состояние системы. Это может пригодиться во многих ситуациях. Например, так можно узнать, что ночью нагрузка системы достигала 70%, а потому, возможно, нужно добавить новый инстанс. Также в метриках можно увидеть, когда возникали ошибки, и какие трейсы и экшены внутри трейсов падали.
- Демонстрирует, как пользователи пользуются системой. Благодаря телеметрии можно увидеть, какие User Actrions популярны, какие кнопки чаще всего нажимают пользователи. Эта информация поможет разработчикам, например добавлять кэш к экшенам. А бизнесу эти данные важны для понимания реального использования системы людьми.
- Подсвечивает, где и как уменьшить затраты на работу системы. Предположим, по телеметрии видно, что из четырех инстансов реально работает только один — и тот на 20%. В таком случае можно отказаться от двух лишних (базовый минимум – два инстанса). Это позволяет в соответствии с обстоятельствами варьировать мощность системы и затраты на ее поддержку.
- Оптимизирует CI/CD-пайплайны. Эти процессы можно логовать и анализировать. Например, если один из степов билда или деплой занимает много времени, то с телеметрией можно увидеть, что именно занимает так много времени и когда эти проблемы начались. Затем вы сможете разработать определенные шаги по устранению проблем.
- Другое. Нестандартных кейсов может быть невероятно много. Вы собираете данные, а как их обрабатывать и где использовать — это уже другое дело. Всё зависит от особенностей системы и проекта. Где-то нужно логовать все-все, а где-то хватит трейсов на центральных сервисах.
Большая IT-система и даже некоторые виды бизнеса не могут существовать без телеметрии. Поэтому этот процесс следует поддерживать и внедрять в проекты, если его нет.
Типы данных в телеметрии
Логи
Простейший тип данных в телеметрии. Логи бывают двух типов:
- Автоматические – генерируются с помощью фреймворка или сервиса (App Service в Azure). С помощью этих данных можно логовать, например, какой реквест пришел и получился, что было внутри реквеста. С автоматическими логами ничего не нужно делать для сбора данных, что удобно для рутинных задач.
- Мануальные – нужно запускать вручную. Не так просто, как с автоматическими, но это оправданно при логовании важных частей системы. Это обычно нагруженные или нацеленные на бизнес-задачи процессы. Скажем, в education-системе будет значимой проблемой потерять тесты студентов за определенный период.

Обычно логовать все данные не нужно. Оцените систему, найдите (если этого не сделали) наиболее уязвимые и ценные части системы. Скорее всего, там нужно добавить логов. Иногда вам нужно будет использовать логориентированное программирование. В моей практике был проект десктопного приложения на WPW, плохо работавший с потоками. Единственный шанс увидеть, что происходило – логовать каждый шаг.
Метрики
Более сложные данные по сравнению с логами. Могут быть ценны и для команды разработки, и для бизнеса. Метрики также выделяют автоматические и мануальные:
- Автоматические – метрики, которые предоставляет система. Например, в Windows можно увидеть показатели нагрузки на CPU, количество реквестов и т.д. Таков же принцип на вкладке Monitoring при развертывании виртуальной машины на AWS или Azure. Там можно найти количество данных, которые поступают в систему или исходят из нее.
- Мануальные – можете добавлять их сами. Например, когда нужно видеть актуальное количество подписок на сервис. Это можно реализовать через логи, но их нужно сосчитать. С метриками все смотрится наглядно и понятно для клиента.
Distributed Trace
Эти данные необходимы для работы с распределенными системами, находящимися не на одном инстансе. То есть, мы не знаем, какой инстанс и какого сервиса обрабатывает тот или иной реквест в определенный промежуток времени. Все зависит от построения системы. Здесь возможны следующие варианты:
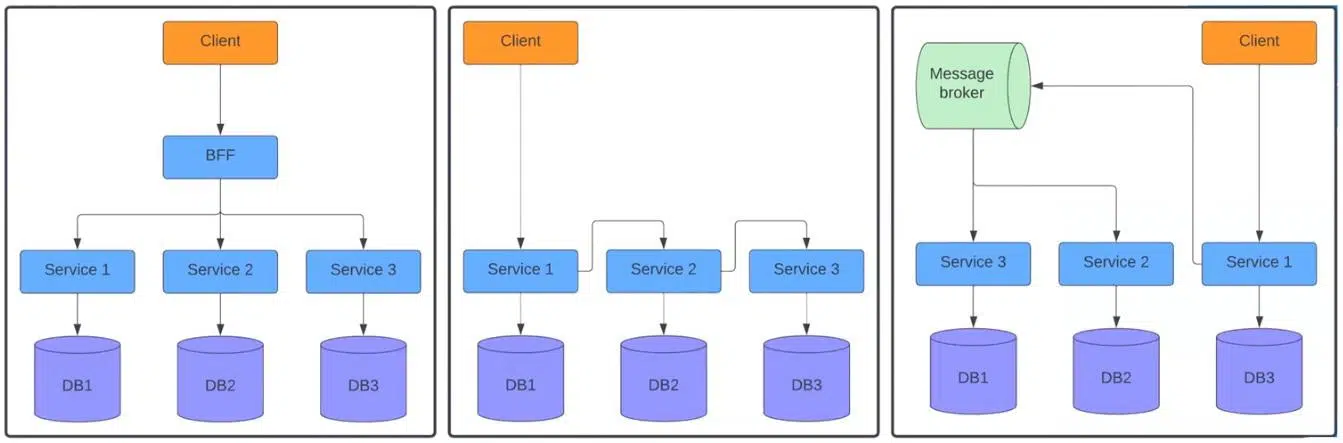
На первой схеме слева клиент посылает реквест в BFF, а тот – отдельным трем сервисам. В центре показана ситуация, когда реквест поступает в первый сервис, отправляющий его во второй, а тот уже в третий. Схема справа отображает, как сервис посылает реквесты в Message Broker. Далее он распределяет их между вторым и третьим сервисами.
Думаю, вы сталкивались с подобными системами, и примеров можно привести множество. Эти схемы сильно отличаются от монолитов. В системах с одним инстансом нам известен стек вызовов от контроллера к базе данных. Поэтому можно относительно легко обнаружить, где и что произошло в течение определенного API call. Скорее всего, эту информацию предоставляет фреймворк.
Но в распределенных системах невозможно увидеть весь флоу. Каждый сервис имеет отдельную систему логирования. При отправке реквеста на BFF мы видим, что произошло внутри, но не знаем, что происходило в сервисах 1, 2 и 3. Именно для такой ситуации придумали Distributed Trace. Вот пример работы:
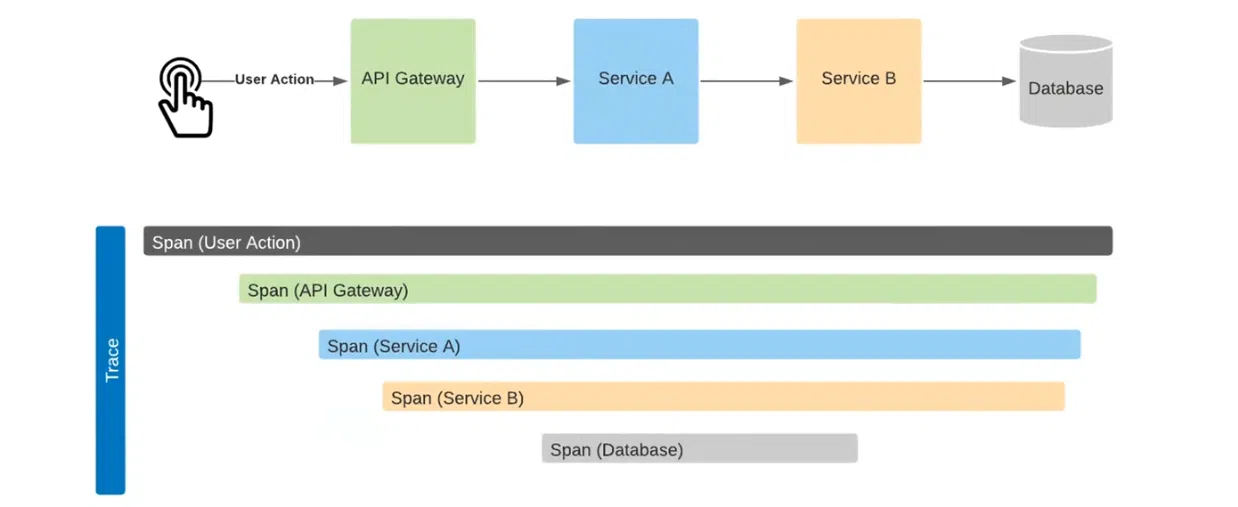
Разберем подробно. Здесь User Action идет на API Gateway, затем – на сервис А, далее – на сервис В. В результате создается вызов в базу данных. При их отправке в систему на выходе получим сходную с приведенной схему.
Здесь хорошо видна продолжительность каждого процесса: от User Action до Database. К примеру, видим, что вызовы шли один за другим. Время между вызовом API Gateway и Service A пришлось скорее на этап HTTP-соединения. Время между вызовом Service B и Database понадобилось на сэтап в базу данных и обработку данных. Так что можно оценить, где и сколько времени потрачено на каждую операцию. Это возможно благодаря механизму Correlation ID.
В чем суть? Обычно в монолитных приложениях при логовании система привязывает логи и экшены к process ID или thread ID. Здесь механизм тот же, но мы его искусственно добавляем к реквестам. Посмотрим на пример:
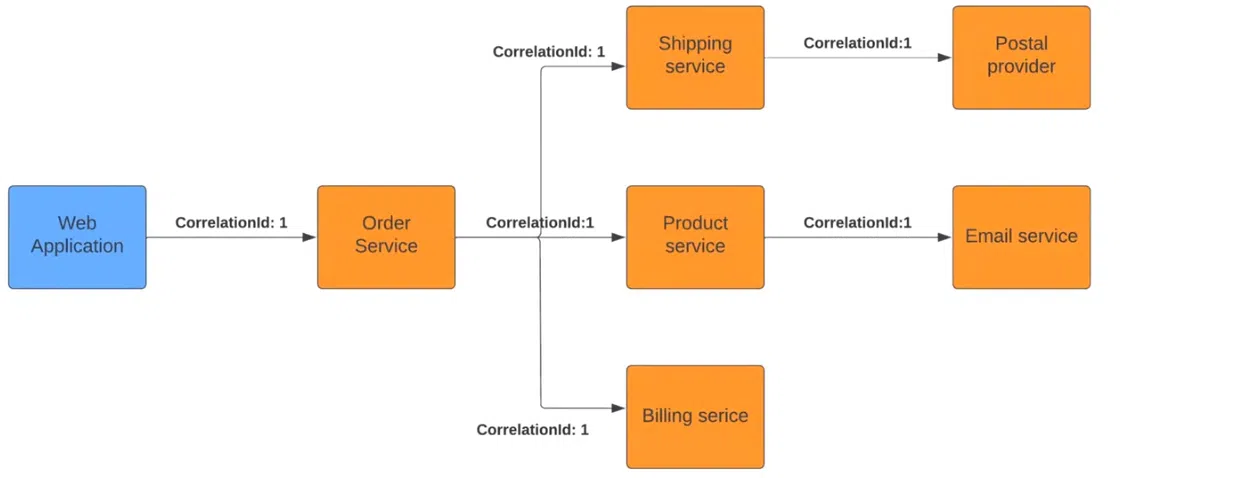
При старте в Web Application экшена Order Service он видит добавленный Correlation ID. Так сервис понимает, что он является частью цепочки, и передает маркер дальше следующим сервисам. Они, со своей стороны, понимают себя как часть большого процесса. В результате каждый элемент будет логовать данные так, чтобы система видела все происходящее в течение многоэтапного экшена.
Передача Correlation ID может происходить по-разному. Например, в HTTP эти данные чаще всего передаются как один из параметров хедеров. В сервисах Message Broker обычно записывается внутри месседжа. Хотя, возможно, в каждой платформе есть SDK или библиотеки, которые помогут реализовать этот функционал.
Как работает OpenTelemetry
Часто формат телеметрии старой системы не поддерживается в новой. Это приводит ко многим проблемам при переходе с одной системы в другую. Например, так было с AppInsight и CloudWatch. Данные не группируются, а значит, что-то работает не так.
OpenTelemetry позволит обойти следующие проблемы. Это протокол передачи данных посредством объединенных библиотек OpenCensus и OpenTracing. Первую создавали разработчики Google для сбора метрик и трейсов, вторую – специалисты Uber только для трейсов. В какой-то момент компании поняли, что работают фактически над одной задачей. Потому решили объединить усилия и сделать универсальный формат отображения данных.
Благодаря протоколу OTLP логи, метрики и трейсы посылаются в едином формате. Согласно репозиторию OpenTelemetry, сегодня известные IT-гиганты контрибьютят этот проект. Он пользуется спросом в продуктах, собирающих и отображающих данные (например, Datadog и New Relic). Также он помогает в системах, которым нужна телеметрия (Facebook, Atlassian, Netflix и другие).

Основные компоненты протокола OTLP
- Cross-language specification – набор интерфейсов, которые нужно реализовать для отправки логов, метрик и трейсов в систему отображения телеметрии.
- SDK – заимплементированные части в виде автоматических трейсов, метрик и логов. По существу это библиотеки подключенного фреймворка. Благодаря им можно увидеть необходимую информацию без написания кода.
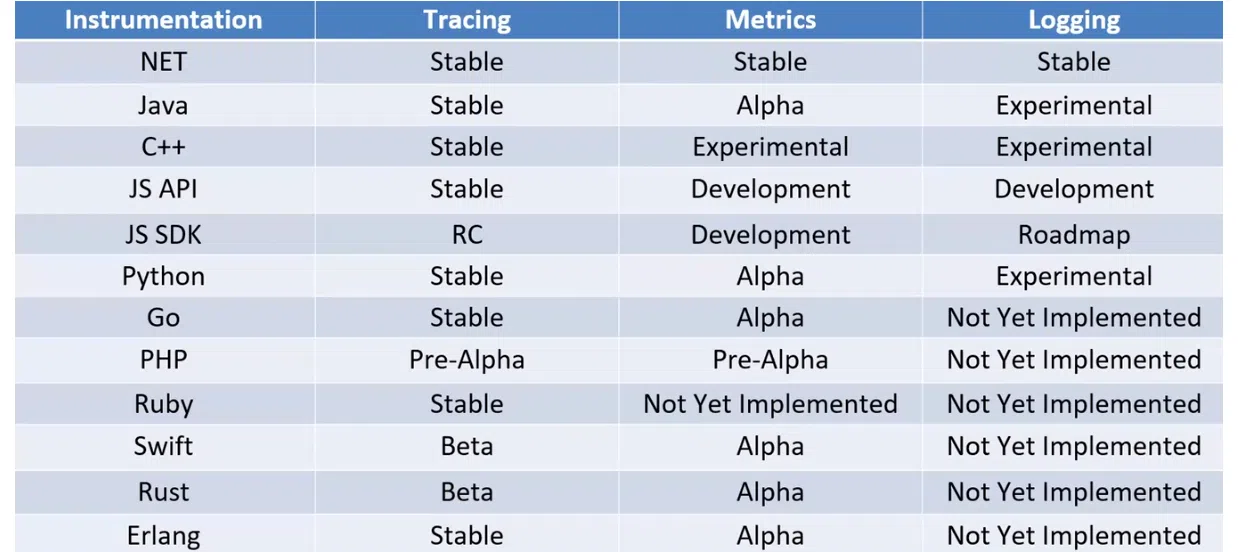
Есть много SDK для популярных языков программирования. Однако все они имеют разные возможности. Обратите внимание на таблицу. Трейсинг имеет стабильные версии повсеместно, кроме PHP и JS SDK. А вот с метриками и логами до сих пор не очень хорошо во многих языках. Где-то есть только альфа-версии, где-то экспериментальные, иногда вообще не реализована имплементация протокола. По собственному опыту скажу, что на сервисах на .NET все работает нормально. Здесь и простое подключение, и надежность логования.
- Collector – главная часть OpenTelemetry. Это софт, который передается из OpenTelemetry в виде exe-, pkg- или docker-файла.
Коллектор состоит из четырех компонентов:
- Receivers – это источники данных коллектора. Технически логи, метрики и трейсы отправляются в ресиверы. То есть они действуют как точка доступа. Ресиверы могут принимать OTLP из Jaeger или Prometheus.
- Processors – их можно запустить для каждого типа данных. Они будут фильтровать данные, добавлять атрибуты и кастомизировать процесс под конкретные задачи системы или проекта.
- Exporters – конечная цель для отправки телеметрии. Отсюда они попадают в OTLP, Jaeger или Prometheus.
- Extensions – эти инструменты расширяют коллектор. В качестве примера:
health_check. С его помощью можно посылать реквест на эндпоинт и понять, работает ли коллектор. Экстеншены показывают многое: сколько ресиверсов и экспортеров в системе, как они работают и т.д.
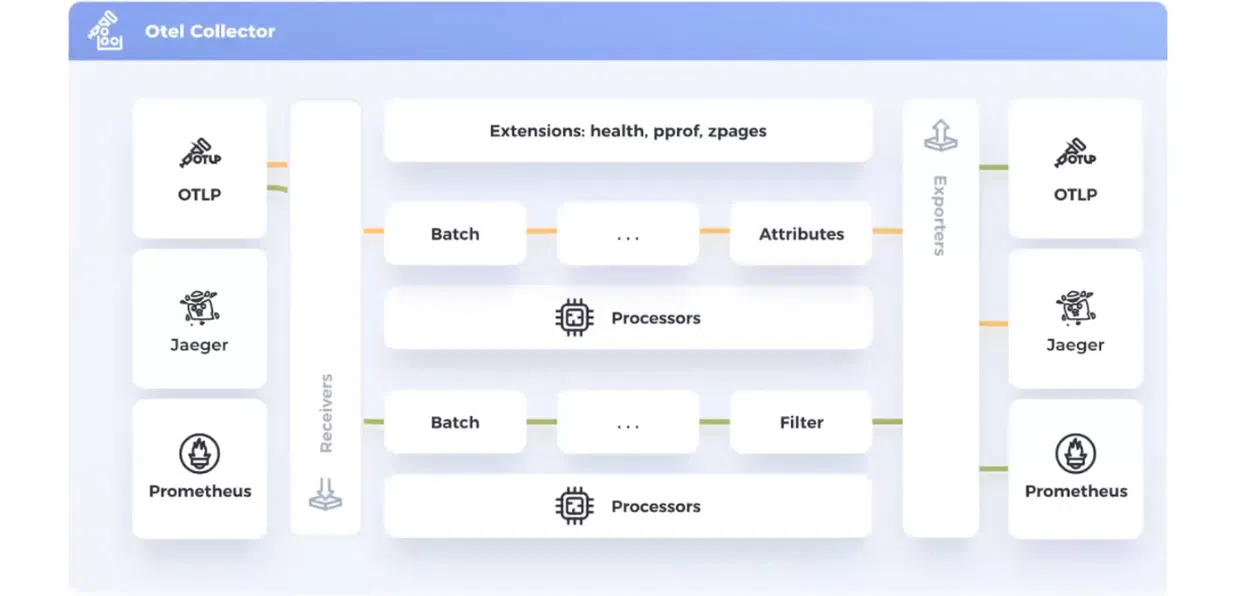
На этой схеме есть два типа данных — метрики и логи (обозначенные разными цветами). Логи идут через свой процессор в Jaeger. Метрики следуют через другой процессор, имеют свой фильтр и отправляются в два источника данных: OTLP и Prometheus. Это дает гибкие возможности анализа данных. Ведь разный софт имеет разные способы демонстрации телеметрии.
Интересный момент: данные можно принимать из OpenTelemetry и отправлять их туда же. То есть в определенных случаях одинаковые данные вы можете отправлять в один и тот же коллектор.
Деплоймент OTLP
Есть много способов, как построить систему сбора телеметрии. Одна из самых простых схем изображена на иллюстрации ниже. Здесь есть один .NET-сервис, который посылает OpenTelemetry сразу в New Relic:

При необходимости схему можно дополнить агентом. Он может выступать в качестве хост-сервиса или бэкграунд-процесса внутри сервиса, собирать данные и отправлять их в New Relic:

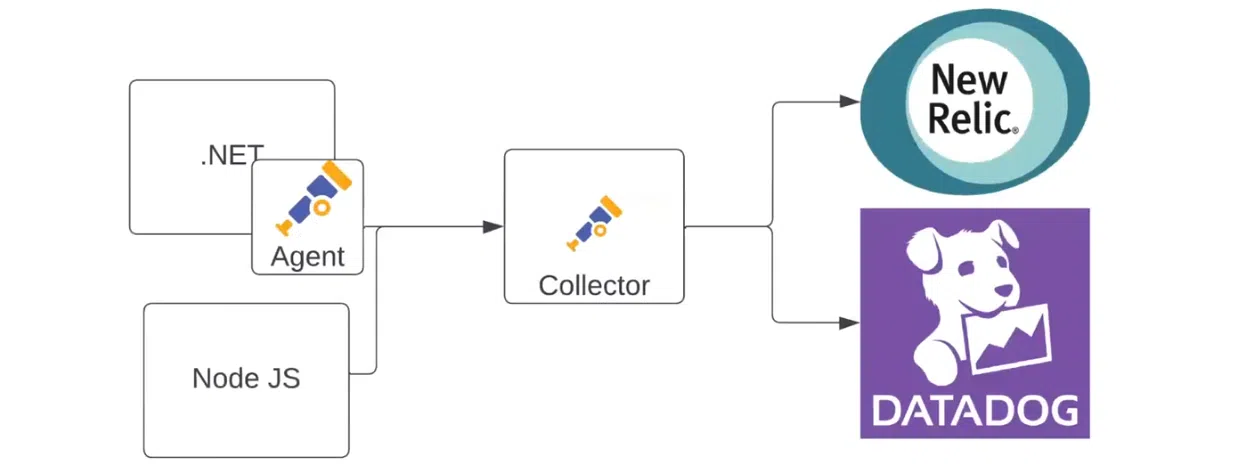
Идем дальше – добавляем в схему еще одно приложение (например, на Node JS). Оно будет передавать данные напрямую в коллектор. А первое будет делать это через собственного агента с помощью OTLP. Коллектор будет отправлять данные уже в две системы. Например, метрики будут идти в New Relic, а логи — в Datadog:
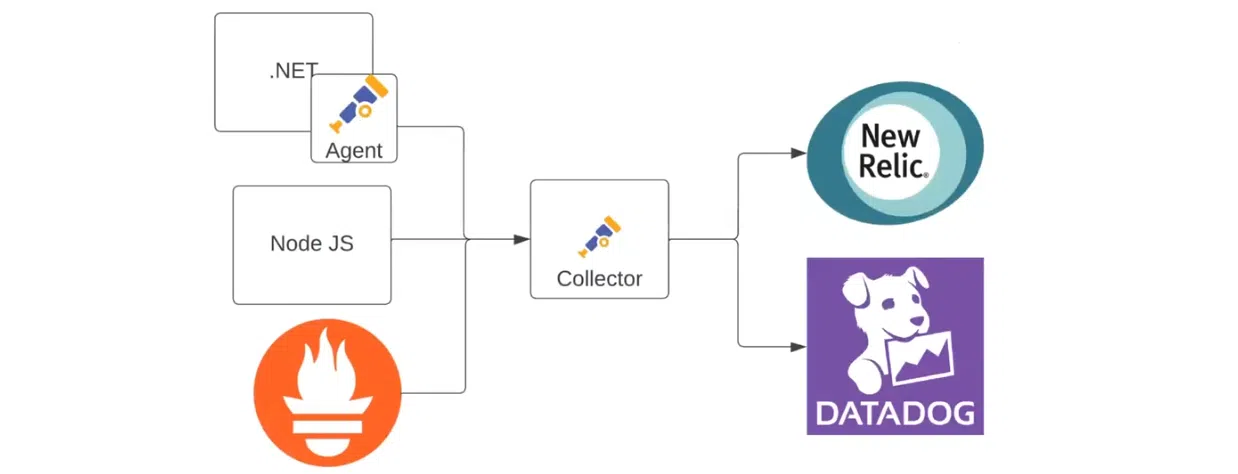
Сюда можно добавить Prometheus как источник данных. К примеру, когда в команде появился человек, который любит этот инструмент и хочет использовать его. Здесь данные все равно будут собираться в New Relic и Datadog:
Систему телеметрии можно усложнять до бесконечности, адаптируя ее под свой проект. Вот еще один пример:
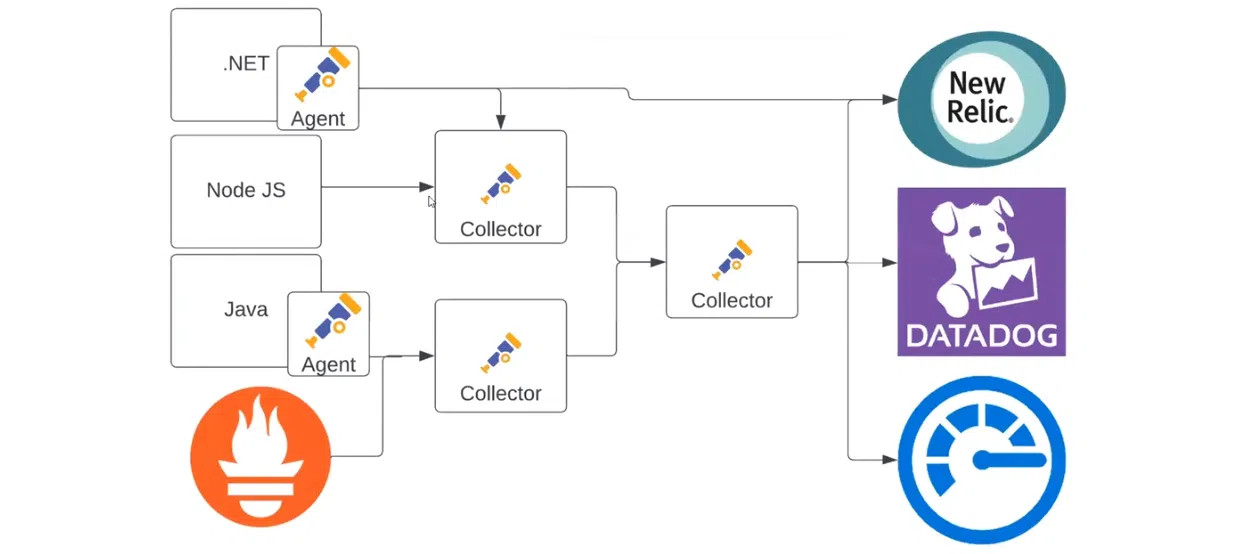
Здесь есть несколько коллекторов, каждый из которых собирает данные по-своему. Агент в .NET-приложении отправляет данные в New Relic и в коллектор. При этом один коллектор может отправлять информацию в другой, так как OTLP посылается другому источнику данных. Он может делать с ними что угодно. В результате первый коллектор отфильтровывает нужные данные и передает следующему. Последний – распределяет логи, метрики и трейсы между New Relic, Datadog и Azure Monitor. Благодаря этому механизму анализировать телеметрию можно так, как удобно вам.
Разбираем возможности OpenTelemetry
Прежде всего, это гибкость. Рассмотрим данное свойство на практике. Для этого тестирования я сделал проект по приведенной схеме:
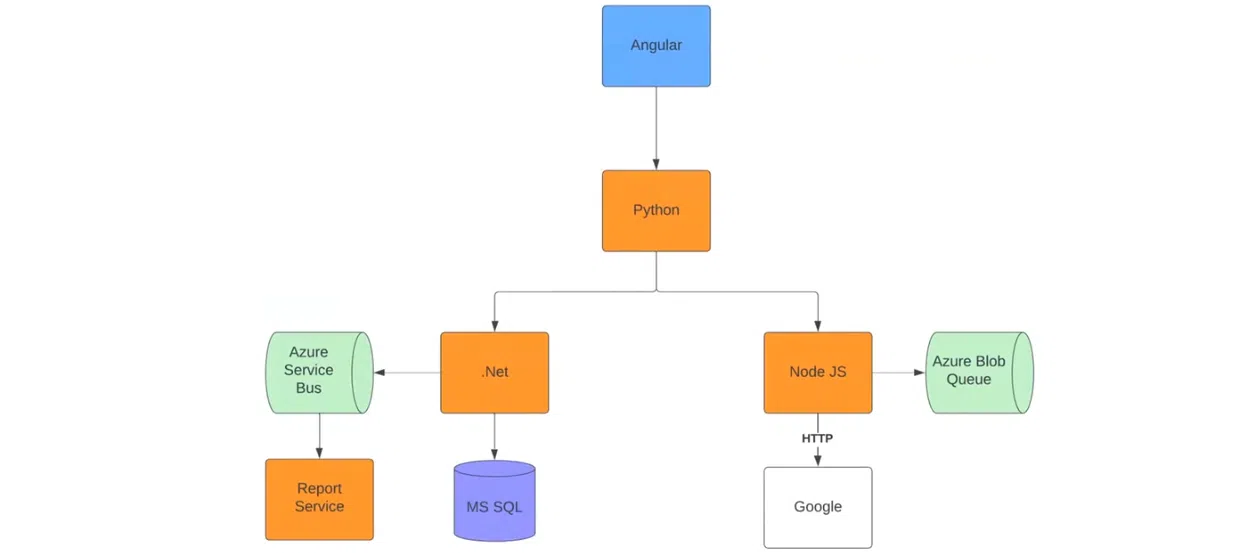
Все начинается с Angular-приложения, которое отправляет HTTP-реквесты в Python-приложение. Тот со своей стороны посылает реквесты в приложения на .NET и Node JS. Они работают по своим сценариям. Приложение на .NET отправляет в Azure Service Bus реквесты и хендлит их в Report Service.
Затем посылает метрики о том, сколько реквестов он обработал. Дополнительно .NET отправляет реквесты в MS SQL. Реквести Node JS идут в Azure Blob Queue и Google. То есть система эмулирует какую-нибудь работу. Во всех приложениях используются автоматические системы отправки трейсов в коллектор.
Начнём с разбора docker-compose файла.
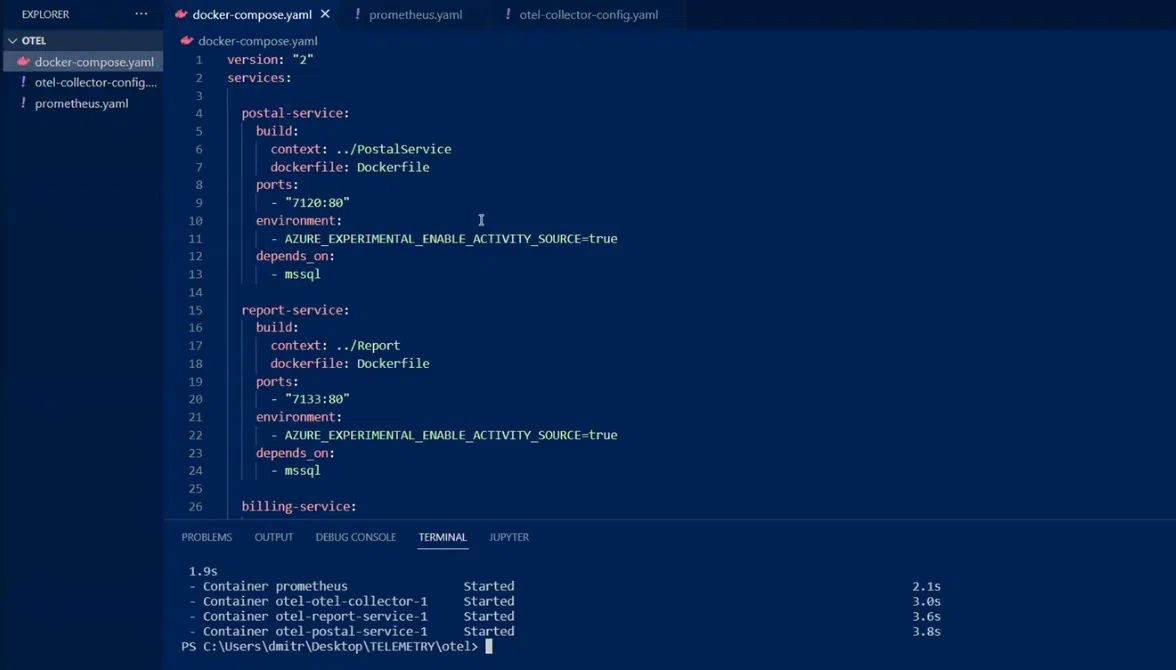
Здесь собран этап нескольких сервисов BFF. Среди закоменченых – Jaeger, помогающий смотреть трейсы.

Предусмотрен еще один софт для просмотра трейсов – это Zipkin.

Также есть MS SQL и собственно коллектор. В последнем указан config-файл и много портов, на которые можно что-то отправлять.
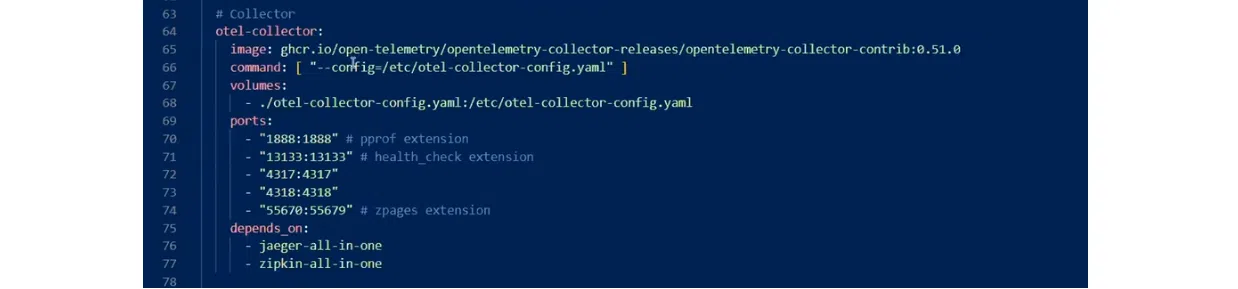
Сonfig-файл содержит набор главных топиков: recievers, exporters, processors, extensions. Завершает все service. Он выступает как конструктор всего этого.
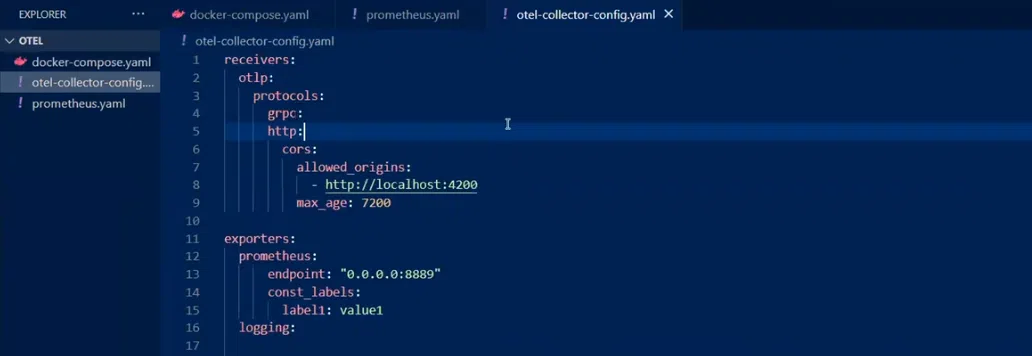
Ресивер один. Это otlp, то есть именно Open Telemetry Protocol. Хотя можно подключать и другие ресиверы (например, Prometheus). Ресивер можно конфигурировать. Предположим, сетить allowed_origins, как в моем примере.

Следующий элемент – экспортеры. С ними можно отправлять метрики в Prometheus.
 Дальше идут экстеншенсы. В этом случае это
Дальше идут экстеншенсы. В этом случае это health_check. Он является эндпойнтом, проверяющим активность коллектора.
 Напоследок имеем сервис с
Напоследок имеем сервис с pipelines, traces, metrics. С ними понятно, какой тип данных откуда берется, чем он обрабатывается, куда отправляется. В этом примере трейсы из ресивера отправляются для логования на два бекенда, а для метрик используется Prometheus.

Разберем, как это работает в действительности. Фронтенд посылает реквесты в бэкенд, а бэкенд использует BFF для отправки реквестов. Создаем круг и видим результаты. Среди них, например, есть некоторые реквесты со статусом 500.
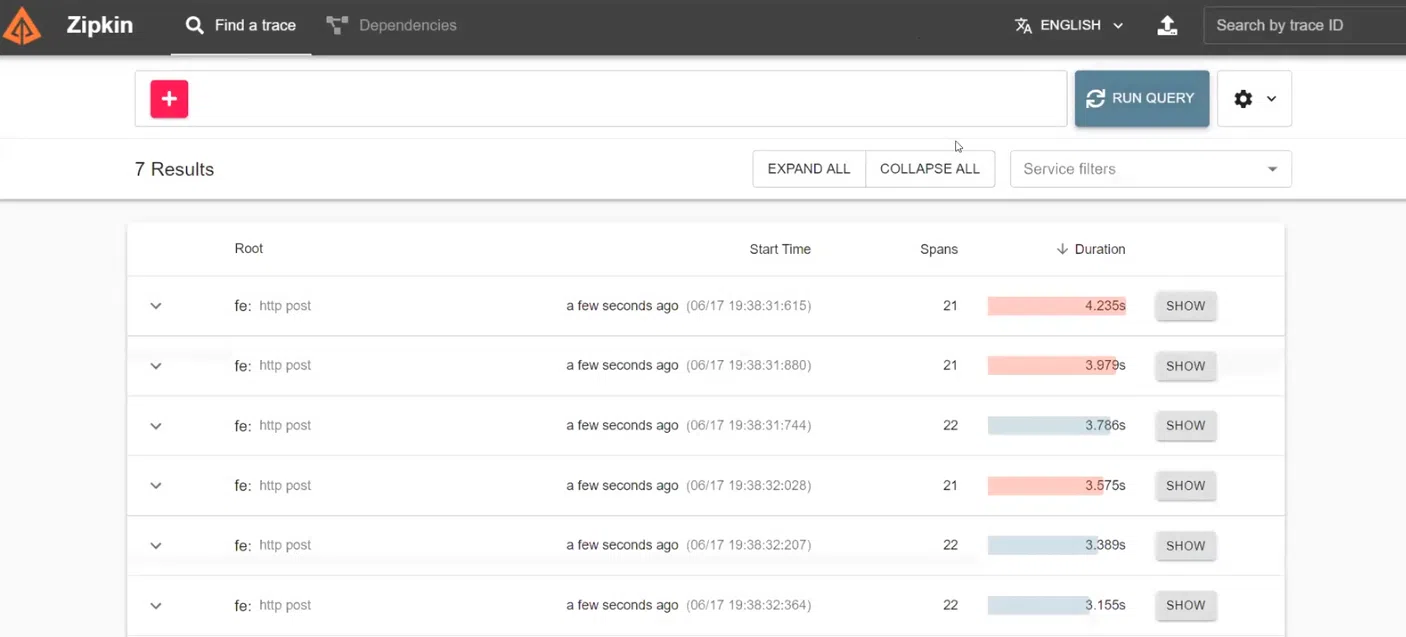
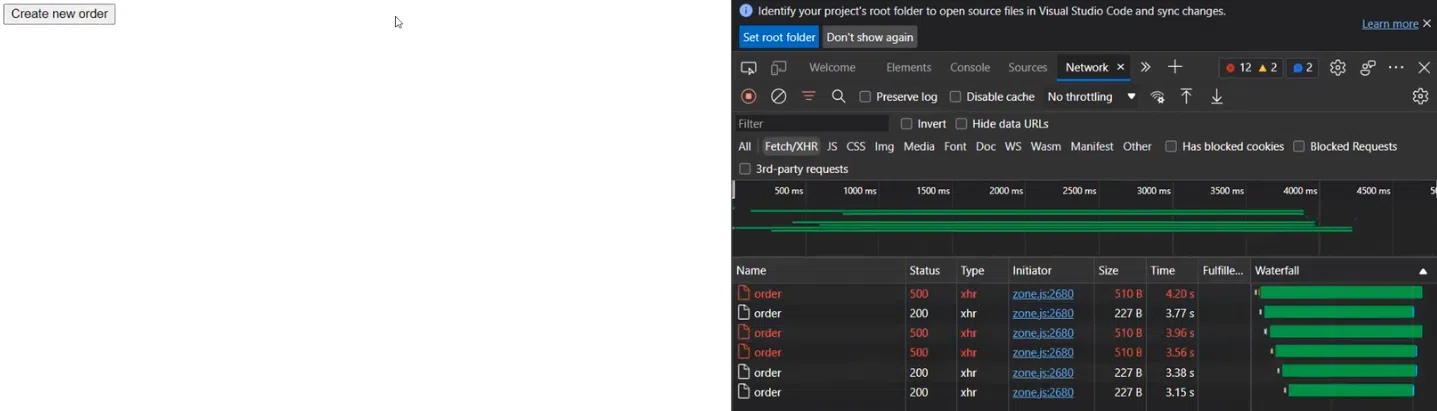 Чтобы разобраться, что пошло не так, смотрим трейсы через Zipkin.
Чтобы разобраться, что пошло не так, смотрим трейсы через Zipkin.
 Подробное описание проблемного реквеста показывает: фронтенд вызвал BFF, а тот отправил два реквеста. Они синхронны, то есть отправляются друг за другом. По трейсам можно узнать, куда направлен этот реквест, на какой URL, какой HTTP-метод использовался. И все это сгенерировано на базе автоматических данных. Также можно добавлять мануальные трейсы – они сделают инфографику более информативной.
Подробное описание проблемного реквеста показывает: фронтенд вызвал BFF, а тот отправил два реквеста. Они синхронны, то есть отправляются друг за другом. По трейсам можно узнать, куда направлен этот реквест, на какой URL, какой HTTP-метод использовался. И все это сгенерировано на базе автоматических данных. Также можно добавлять мануальные трейсы – они сделают инфографику более информативной.
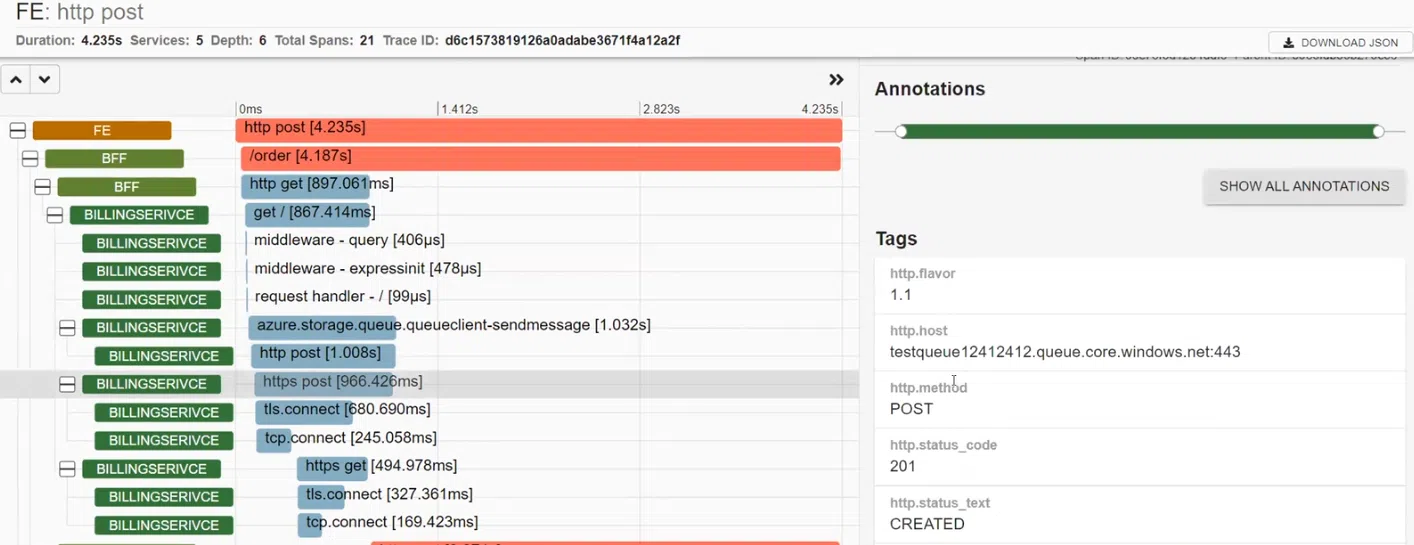
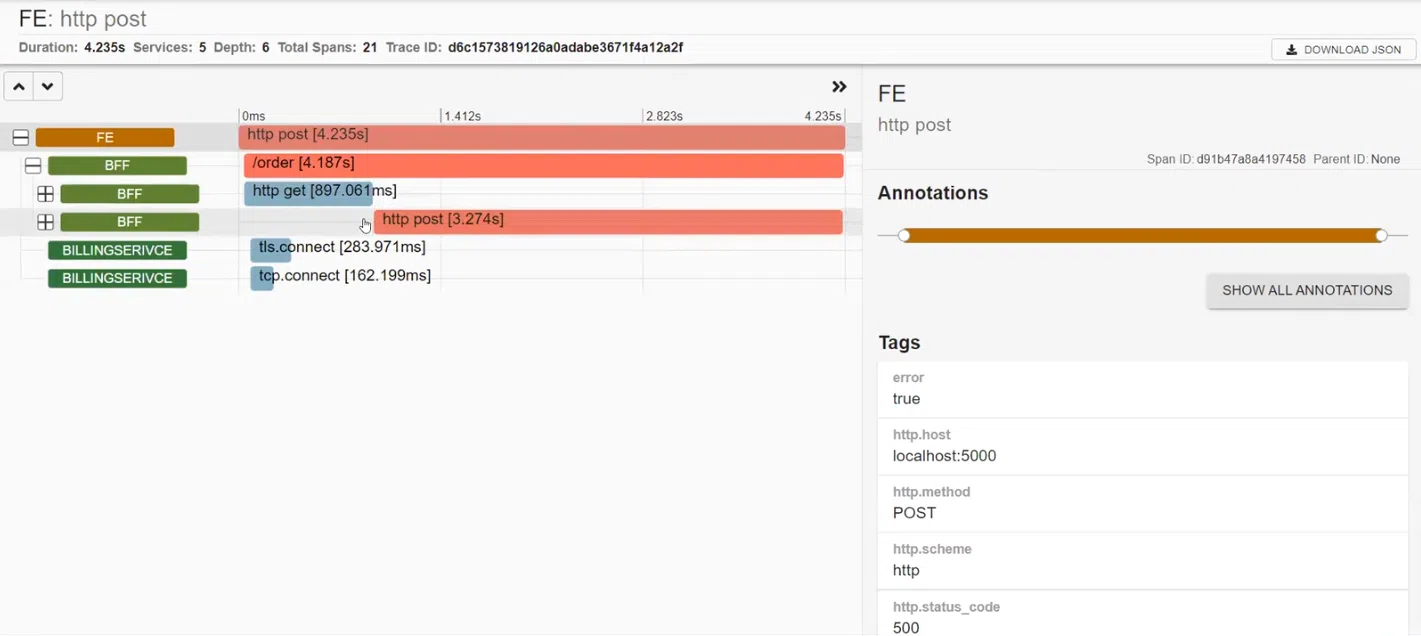 Кроме того, в этом случае видим, что
Кроме того, в этом случае видим, что BFFвызвал BILLINGSERVICE. В нем работают middleware, посылается реквест в Azure и есть http.post, который отправлялся в Azure. В результате получен статус CREATED. Далее система сетапила и отправляла реквест в Google.
 Также есть
Также есть POSTALSERVICE, в котором упал один реквест. Посмотрим на него внимательнее и увидим описание ошибки: ServiceBusSender has already been closed…Поэтому в следующий раз нужно быть осторожным с ServiceBusSender. Также здесь можно увидеть отправку нескольких запросов на MS SQL.
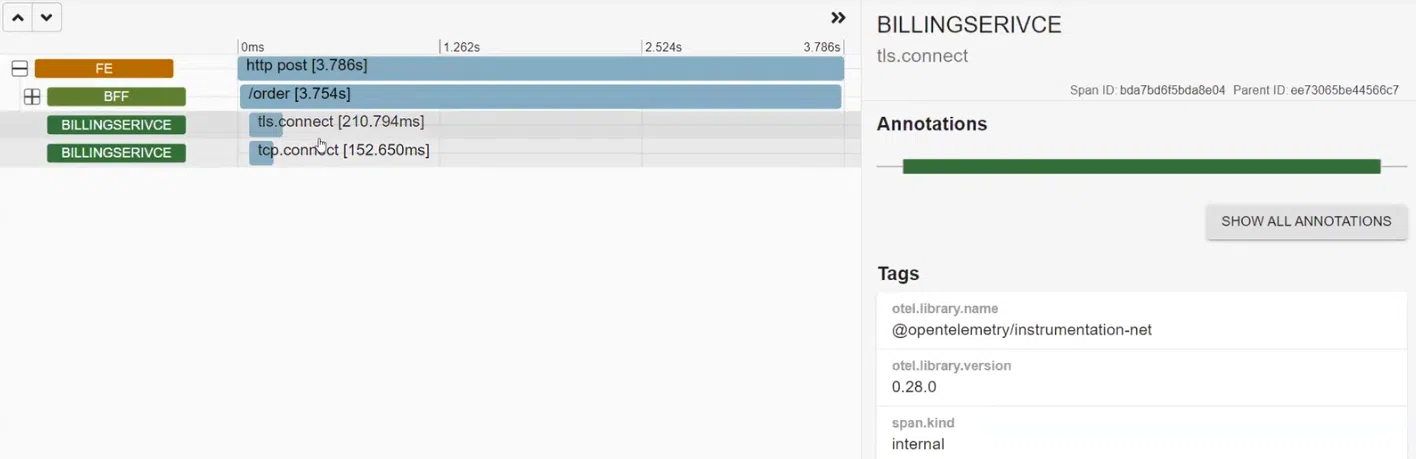
 Наконец, мы получили достаточно содержательную инфографику обо всех процессах в системе. Однако хочу вас предостеречь: не всегда все так прозрачно. В нашем случае два трейса, как говорится, out of context. С ними ничего не понятно: где они выполняются, что с ними происходит, деталей минимум… Такое иногда случается и к этому надо быть готовыми. Как вариант, добавлять мануальные трейсы:
Наконец, мы получили достаточно содержательную инфографику обо всех процессах в системе. Однако хочу вас предостеречь: не всегда все так прозрачно. В нашем случае два трейса, как говорится, out of context. С ними ничего не понятно: где они выполняются, что с ними происходит, деталей минимум… Такое иногда случается и к этому надо быть готовыми. Как вариант, добавлять мануальные трейсы:
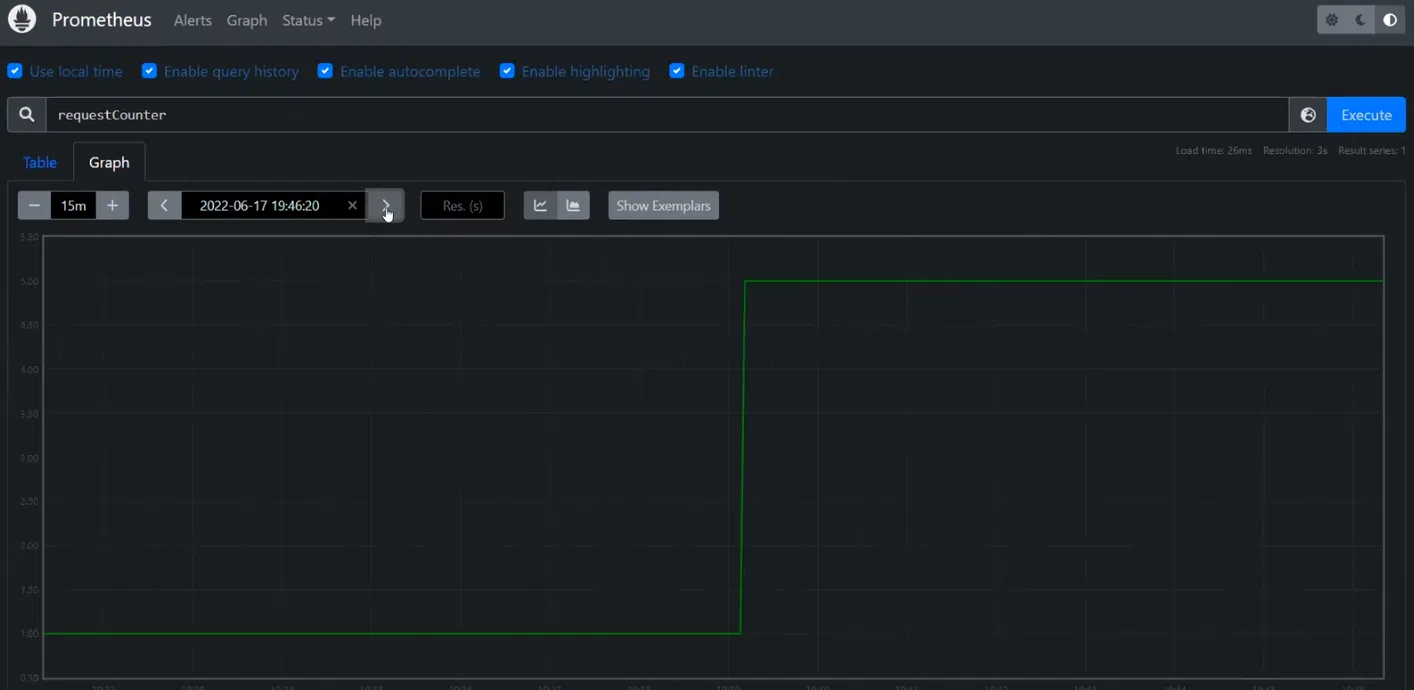
 Давайте посмотрим, как в Prometheus отправляются метрики. На иллюстрации видно, что отправка дополнительных реквестов прошла успешно. Был один, а стало пять. То есть метрики работают исправно:
Давайте посмотрим, как в Prometheus отправляются метрики. На иллюстрации видно, что отправка дополнительных реквестов прошла успешно. Был один, а стало пять. То есть метрики работают исправно:
 В схеме .NET-приложение отправляет реквесты в Azure Service Bus, далее их обрабатывает Report Service. Однако у Zipkin не было Report Service. Но ведь метрики показывают, что он работает! Поэтому помните: до сих пор не все и не всюду в OTLP работает так, как нужно. Я знаю библиотеки, которые в месседжброкеры добавляют трейсы по умолчанию, и их можно увидеть в стеке. Хотя это до сих пор считается экспериментальным функционалом.
В схеме .NET-приложение отправляет реквесты в Azure Service Bus, далее их обрабатывает Report Service. Однако у Zipkin не было Report Service. Но ведь метрики показывают, что он работает! Поэтому помните: до сих пор не все и не всюду в OTLP работает так, как нужно. Я знаю библиотеки, которые в месседжброкеры добавляют трейсы по умолчанию, и их можно увидеть в стеке. Хотя это до сих пор считается экспериментальным функционалом.
А еще вспомним о health_check. Он покажет, работает ли наш коллектор вообще.
 Теперь отправим данные еще я в Jaeger (добавим новый ресурс трейсов). После его старта нужно заново отправить рекламу, ведь он не получает предварительные данные. Получим следующее:
Теперь отправим данные еще я в Jaeger (добавим новый ресурс трейсов). После его старта нужно заново отправить рекламу, ведь он не получает предварительные данные. Получим следующее:
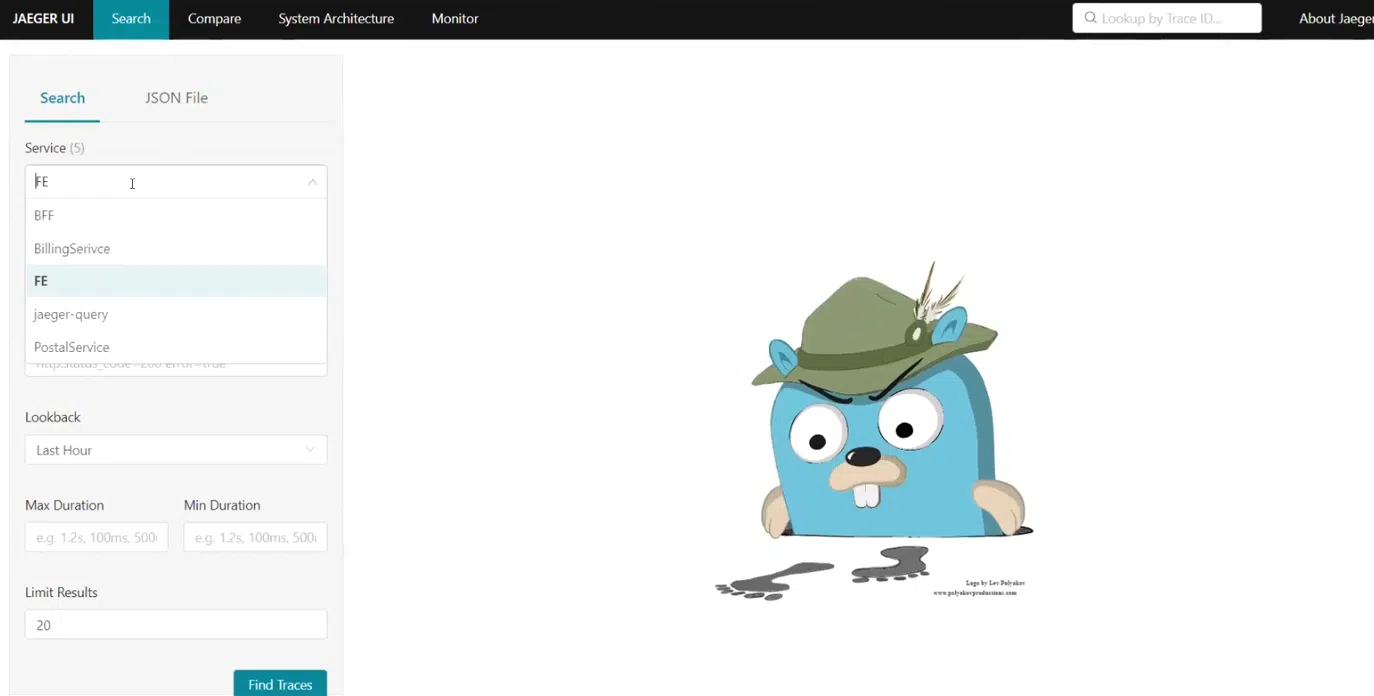 Есть примерно такие же трейсы, как у Zipkin (в частности, со статусом 500):
Есть примерно такие же трейсы, как у Zipkin (в частности, со статусом 500):
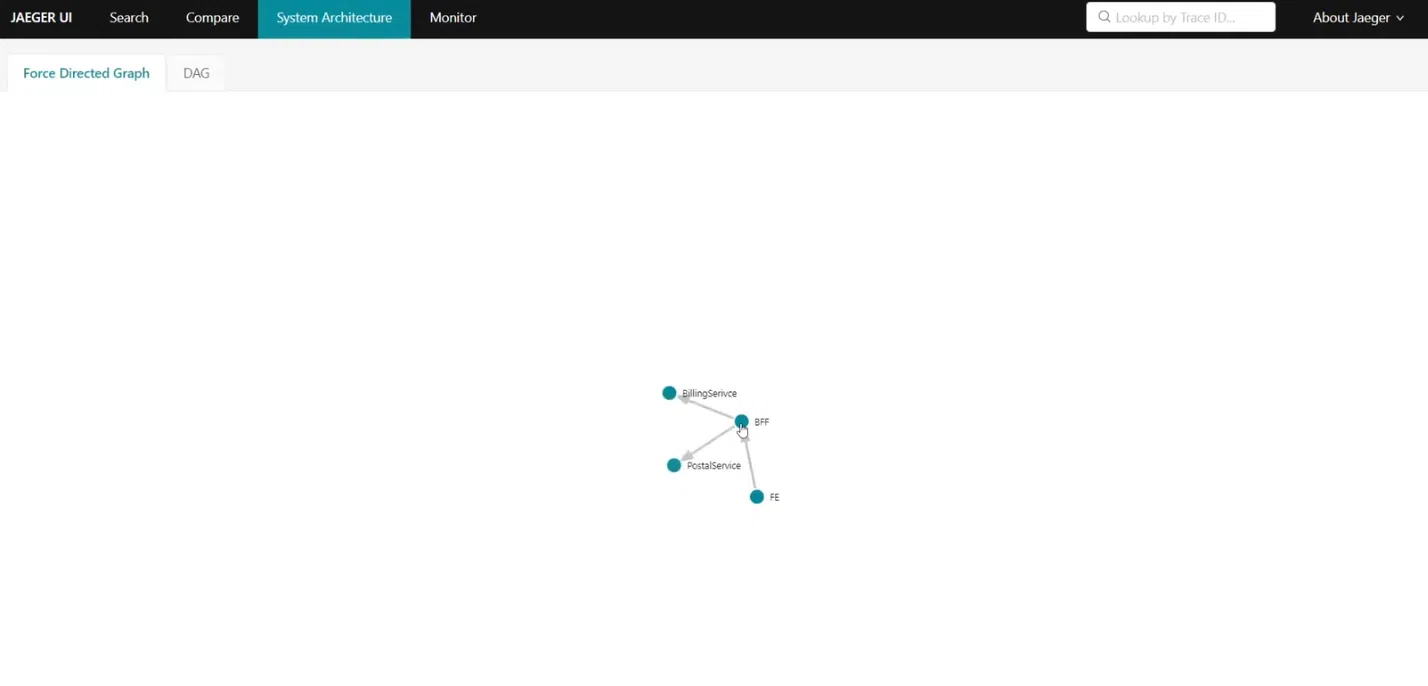
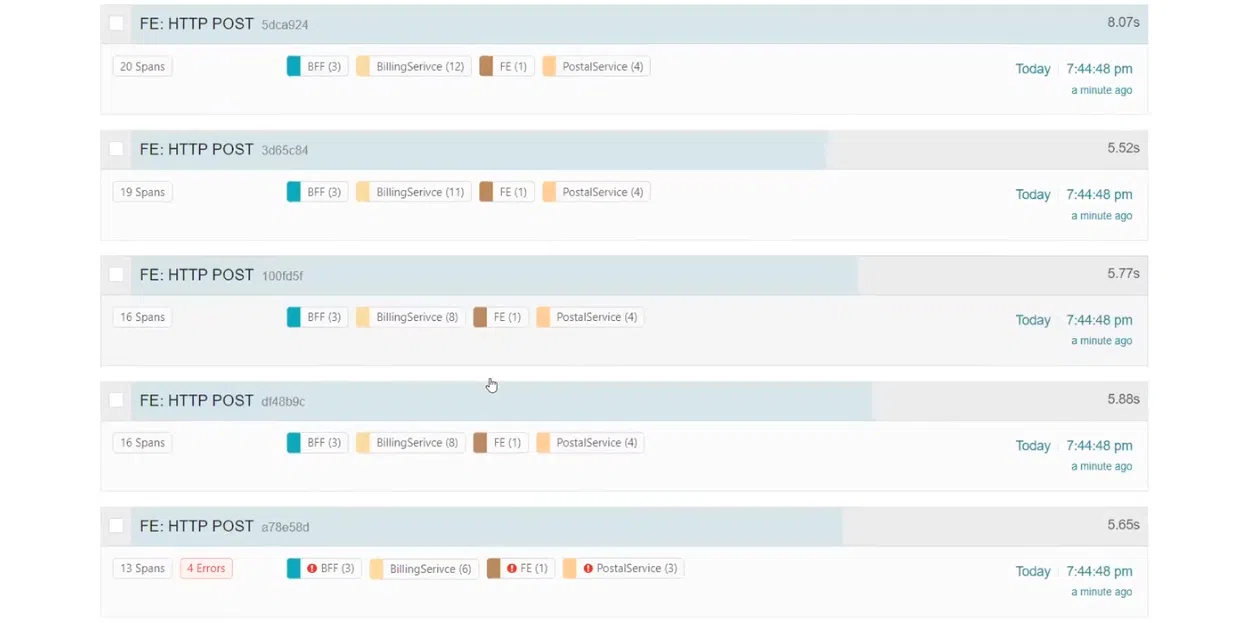 Мне нравится вкладка System Architecture, где находится граф системы. Он показывает, что все начинается с реквеста в BFF, который перенаправляется в BillingService и PostalService. Это пример того, как различные инструменты отображают данные собственным уникальным способом.
Мне нравится вкладка System Architecture, где находится граф системы. Он показывает, что все начинается с реквеста в BFF, который перенаправляется в BillingService и PostalService. Это пример того, как различные инструменты отображают данные собственным уникальным способом.
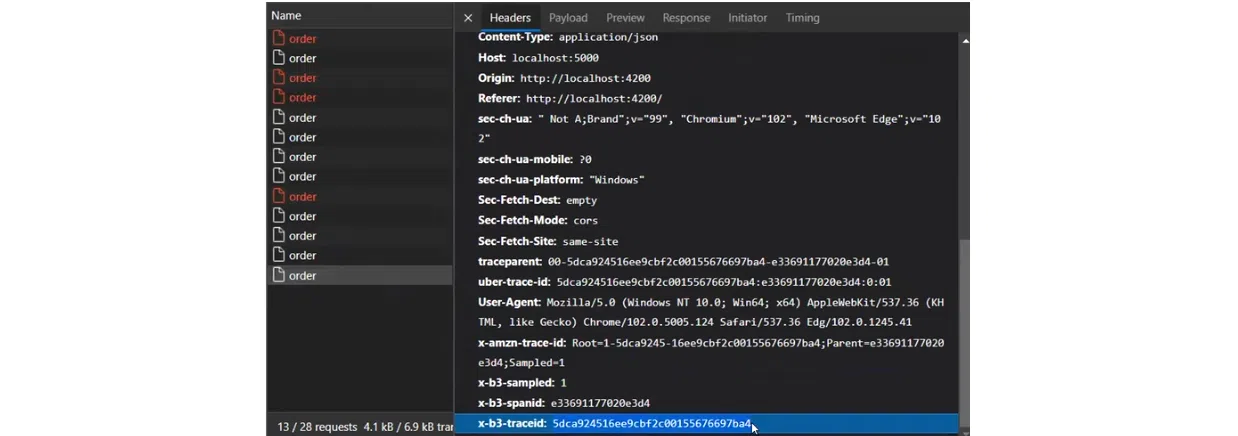
 Последнее, что разберем в этой статье – это order. В нем можно найти реквест и сгенерированный traceid. Если вы укажете его в системе, то узнаете, что произошло в реквесте, и сможете детально исследовать HTTP call. Таким образом фронтенд узнает, что он первый, кто получил User Action. Таким же образом фронтенд понимает, что нужно создать трейс, который будет передаваться по цепочке и будет посылать данные коллектора. А коллектор будет собирать их и передавать в Jaeger, Zipkin и Prometheus.
Последнее, что разберем в этой статье – это order. В нем можно найти реквест и сгенерированный traceid. Если вы укажете его в системе, то узнаете, что произошло в реквесте, и сможете детально исследовать HTTP call. Таким образом фронтенд узнает, что он первый, кто получил User Action. Таким же образом фронтенд понимает, что нужно создать трейс, который будет передаваться по цепочке и будет посылать данные коллектора. А коллектор будет собирать их и передавать в Jaeger, Zipkin и Prometheus.
Поэтому преимущества использования OpenTelemetry Protocol очевидны. Это гибкая система сбора, обработки и отправки телеметрии. Особенно удобно в сочетании с Docker, который я использовал при создании этого демо.
Однако всегда помните об ограничениях OTLP. В случае с трейсами все достаточно хорошо. А целесообразность использования этого протокола для метрик и логов зависит от готовности библиотек и SDK конкретной системы.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: