Beautiful girl with braids in her hair and hood imitating a hacker with computer, black background, selective focus.
Далеко не всі розробники знають про користь лямбда-функцій. І дарма! Адже ці хмарні функції можуть відчутно спростити роботу девелопера та підвищити ефективність створюваних застосунків. Особливо показова ця властивість на прикладі сервісу AWS Lambda від Amazon. Про це далі і піде мова.
Я розповім про принципи роботи та основні можливості лямбда-функцій. Ця стаття передусім буде корисна Junior-розробникам. Ви дізнаєтесь про базові поняття та зможете розпочати роботу з AWS Lambda.
Для початку коротко опишу, що являють собою Amazon Web Services. У роботі з Lambda вам так чи інакше доведеться мати справу зі зв’язаними хмарними сервісами Amazon. «Складові» AWS зібрані на ілюстрації нижче:
Перша група — Compute, яка об’єднує послуги для обчислень:
Друга група — це бази даних:
Третя група сервісів стосується роботи мережі та доставки контенту:
Четверта група — сховища:
П’ята група сервісів пов’язана з безпекою, ідентифікацією та управлінням вимогами:
Шоста група — про управління та адміністрування:
На цьому сервісі працює багато фреймворків для написання та деплою лямбда-функцій. Для цього створюється YAML-файл для опису необхідних ресурсів та їх властивостей. Потім за допомогою консольної утиліти AWS CLI треба один раз задеплоїти результат. І тоді під час апдейтів не потрібно деплоїти вихідний файл заново, а можна лише редагувати вихідний код для оновлення ресурсів.
Тут слід виділити декілька переваг:
Немає серверів — немає керування ними. Вам не доведеться витрачати сили на створення, виділення та обслуговування таких пристроїв.
Для збільшення продуктивності оточення не потрібно відстежувати навантаження на сервери та ресурси. Розробнику достатньо лише змінювати налаштування лямбда-функції. Ви можете збільшити обсяг пам’яті, і система сама зробить усе інше.
Платите за час, коли використовували лямбда-функції. Навіть якщо вона задеплоєна, але простоює, витрати будуть нульовими.
AWS гарантує стабільність програми, яка буде доступна в багатьох регіонах світу. Інші послуги, які використовують лямбда-функції, теж матимуть до них доступ.
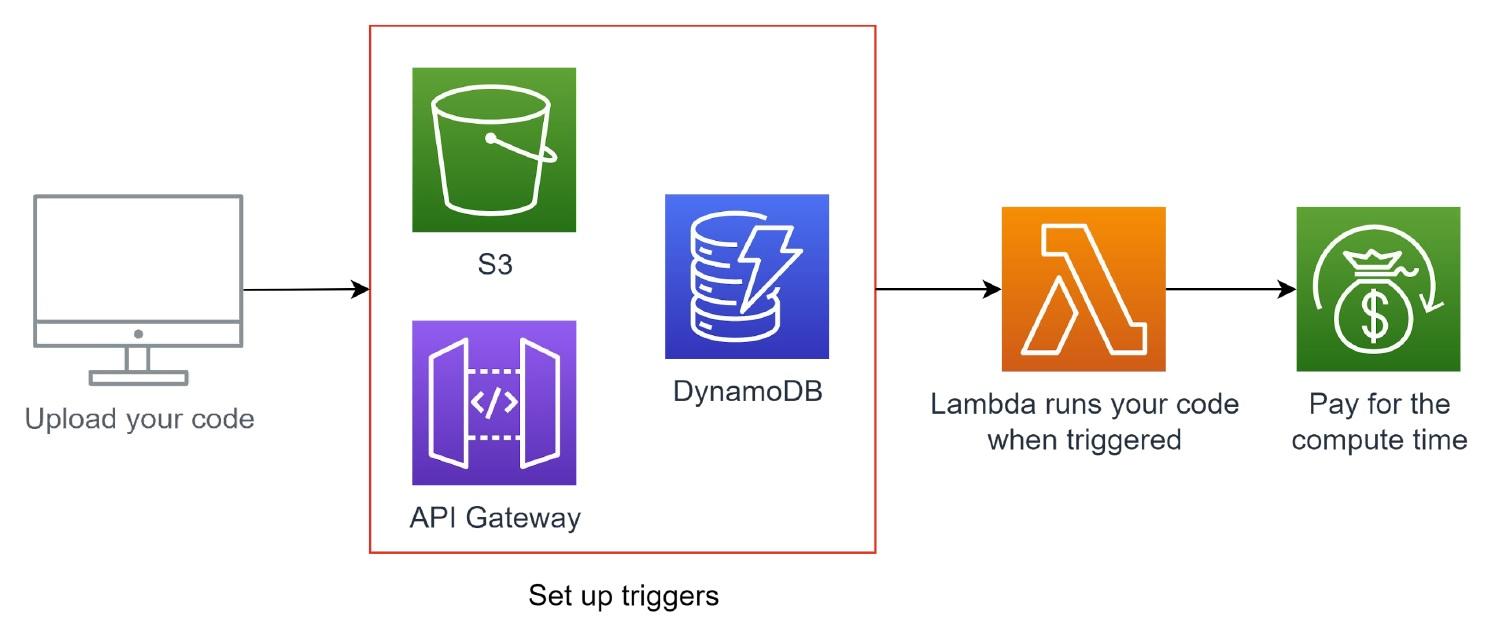
Задля наочності я крок за кроком опишу типовий сценарій запуску лямбда-функції в AWS:
Наразі лямбда-функції від Amazon підтримують чотири версії Python: від 3.6 до 3.9. Раніше була підтримка й другої версії, але зараз її призупинено. Через це старі проєкти задеплоїти неможливо. Та в Amazon з’явилися ARM-процесори Graviton. Тому у версіях Python 3.8 та 3.9 можна задеплоїти від ARM-архітектури.
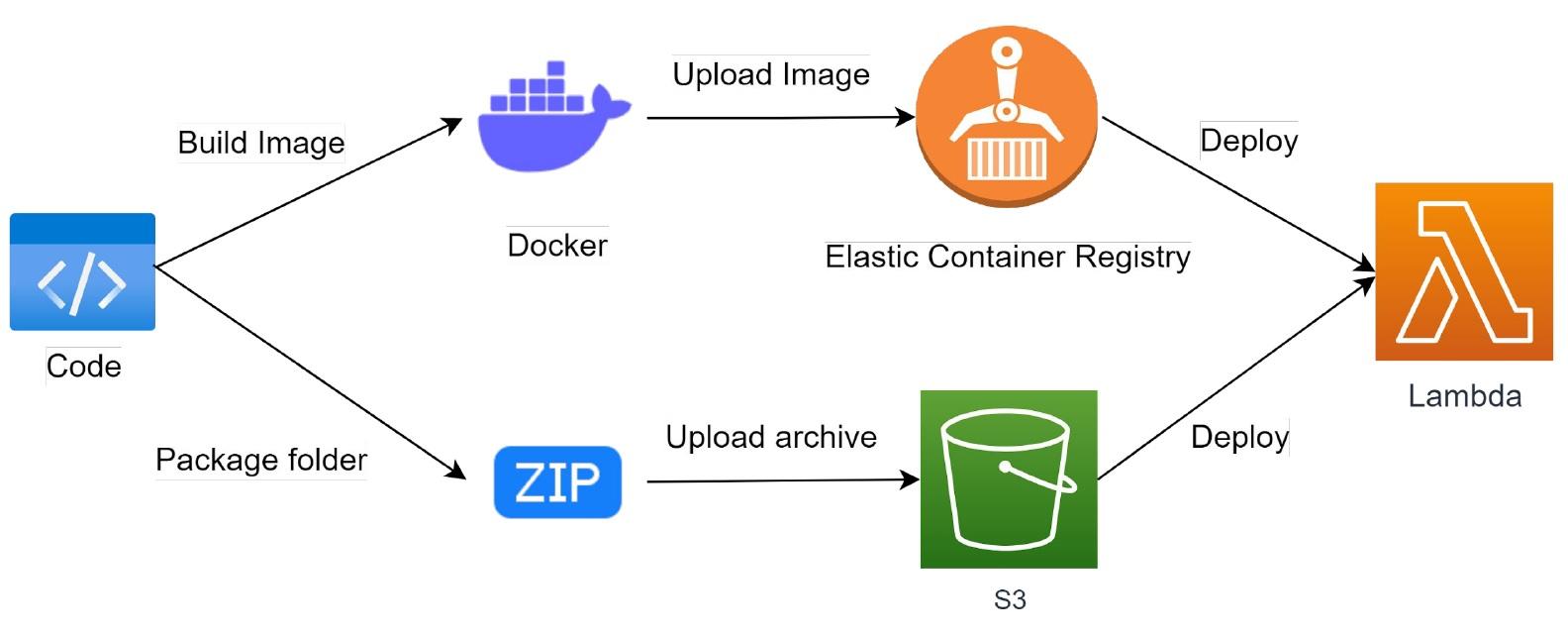
Після локального написання коду деплой лямбди може відбуватися за одним із сценаріїв:
Можете не обмежуватись локальним написанням коду. Писати його можна ще й у дашборді Amazon в онлайн-редакторі. Таким чином ви пропустите крок у типовому створенні лямбда-функції та відразу збережете код у S3.
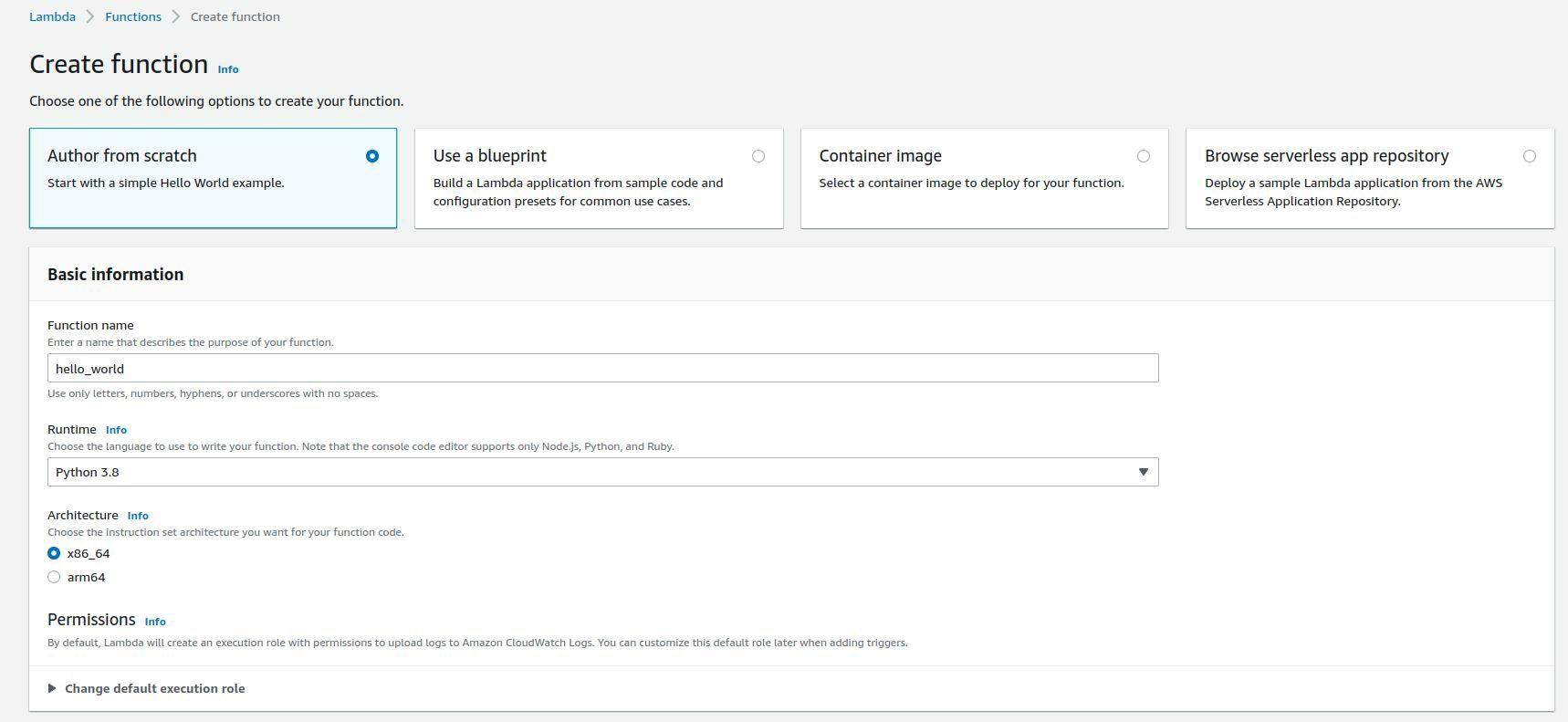
Для візуалізації такого сценарію візьмемо як приклад створення простої функції Hello World. Для цього відкриваємо відповідний розділ, задаємо ім’я лямбди, а решту параметрів залишаємо за замовчуванням: це Python 3.8 та архітектура x86.
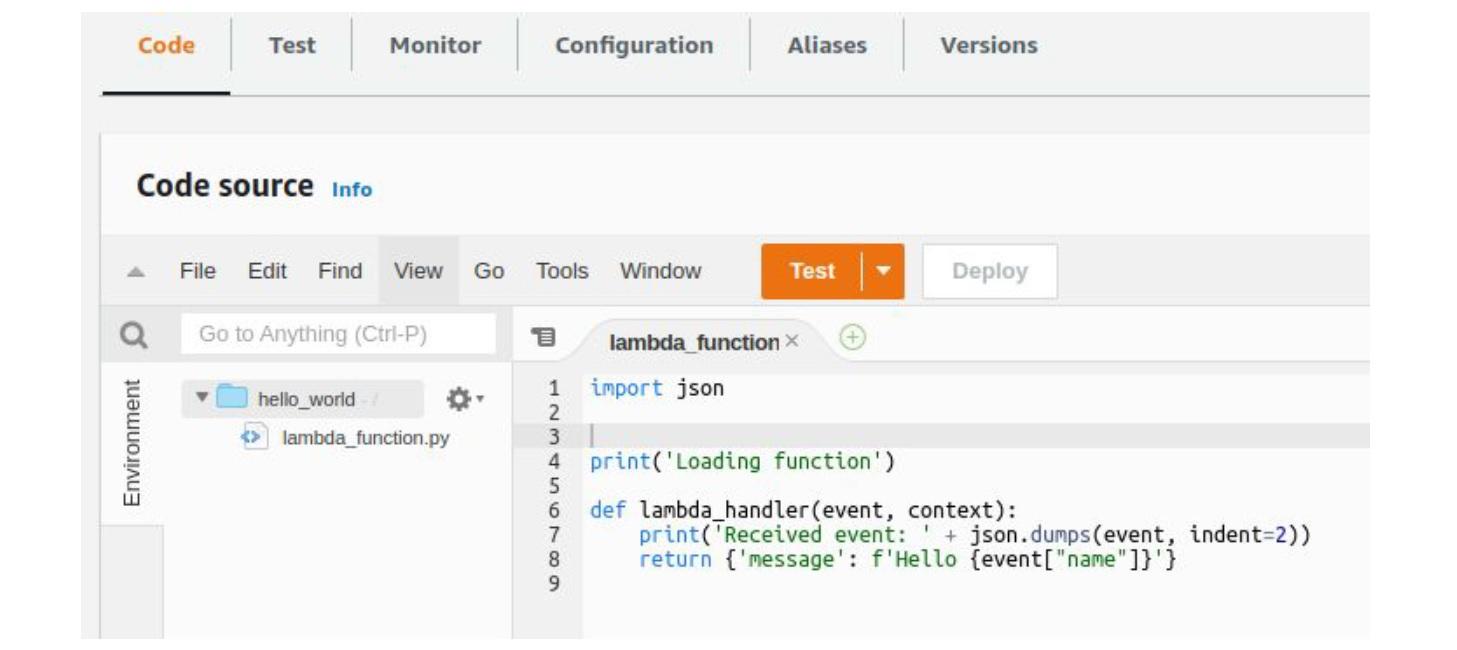
Далі пишемо саму функцію в онлайн-редакторі. Метод лямбди повинен приймати два параметри: event та context. У context міститься службова інформація про оточення лямбда-функції (ім’я та налаштування). Сама функція працює з event, звідки має отримувати якісь дані.
Наприклад, якщо це був певний HTTP-запит, усе міститься саме там. Тут ми пишемо функцію, яка вітається з користувачем та повертає результат. Також є print із самим об’єктом івенту:
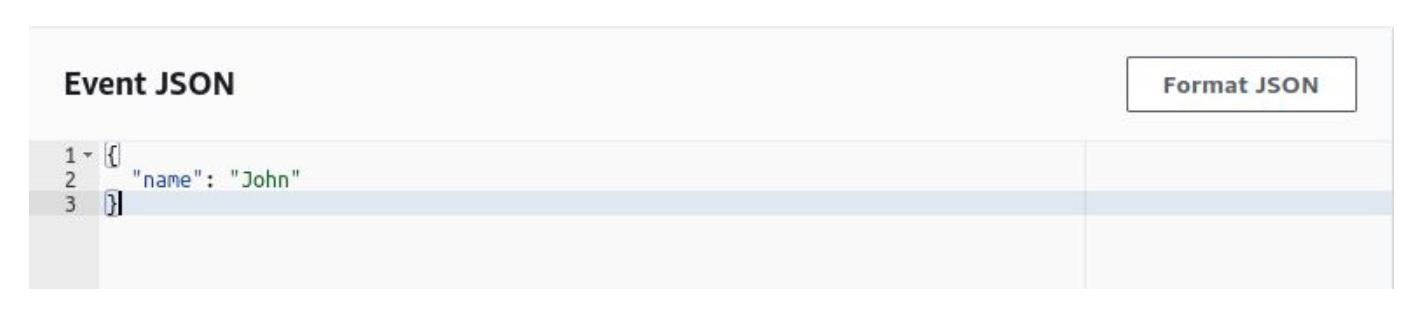
Після функції ми не будемо сетапити івент. Натомість створимо тестовий івент, в якому опишемо JSON-об’єкт — у нашому випадку ім’я користувача John. Зауважу, що всі параметри, які приймає лямбда-функція, повинні бути JSON серіалізованими. Інакше функція не запуститься:
Після написання івенту натискаємо кнопку Test і бачимо результати виконання функції. Має з’явитися блок Response з даними, що повертаються з функції.
Також ми отримаємо логи з трьома рядками службової інформації:
START. Тут наводиться унікальний ID реквесту та версія лямбда-функції. У прикладі я задеплоїв одну версію, для якої автоматично створено $LATEST — і з ним ми завжди працюємо.END. Тут повторюється той самий RequestId.REPORT. Цей блок містить дані про виконання лямбда-функції. Насамперед — скільки часу в мілісекундах зайняв весь процес. Далі розраховується оплачуваний час роботи сервісу (округляється у більшу сторону). Також вказуються об’єм пам’яті, заданий у налаштуваннях лямбда-функції, та об’єм пам’яті, використаної у процесі. Завершує блок Init Duration з витраченим на ініціалізацію функції часом.Після отримання івенту виконується наступний сценарій:
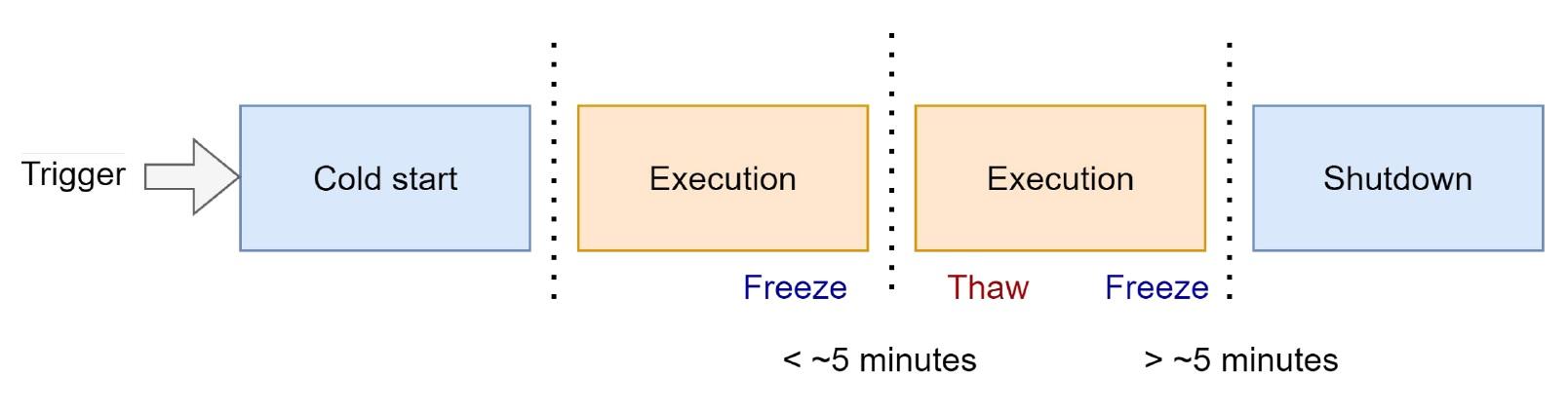
Два перші блоки пофарбовані в синій колір і відображають стадію «холодного» старту. Цей етап виконується при першому запуску лямбда-функції після довгого простою. При подальших отриманнях івентів виконуються лише блоки 3 і 4 — з імпортом бібліотек та запуском самої функції.
Щоправда, третій блок є спірним. Згідно з документацією AWS, бібліотеки імпортуються щоразу. Хоча автори сервісу вказали, що у разі простою середовище заморожується. Тому імпорт бібліотек не повторюється. Можливо, це стосується не лише Python, а й усіх мов, що підтримуються.
Нижче наведена схема повторного використання оточення лямбда-функції:
Із появою тригера відбувається холодний старт із завантаженням функції, створенням оточення та обробкою івенту. Після цього середовище, в якому виконувалася лямбда, заморожується. Зупиняються всі фонові процеси. Також заморожується директорія /tmp, створена для кожної функції. Тобто можна повторно використовувати папку для зберігання кешу. А ще зберігаються об’єкти, які були оголошені поза функцією.
Тому якщо після запуску функція не використовувалася менше п’яти хвилин, то середовище при надходженні нових івентів та тригерів розморожується. Але якщо простій триває більше п’яти хвилин — середовище видаляється, а з ним усі дані.
Окрема тема — одночасна обробка кількох івентів. При отриманні івенту механізм лямбди шукає середовище у простої — таке, що було ініціалізовано, обробило івент і заморожено. Якщо такого немає, створюється нове середовище оточення.
Саме це зображено нижче на івенті 1. Під час його обробки з’являється івент 2. Механізм лямбда-функції знову шукає вільне середовище та не знаходить його. А тому піднімає ще одне оточення: з холодним стартом, завантаженням бібліотек, ініціалізацією середовища та подальшою обробкою другої події.
Далі надходить івент 3. При цьому обробка другого ще триває, а першого вже завершилася. Тому механізм починає перевикористовувати перше середовище, що вже звільнилося.
Якби три івенти надійшли одночасно, механізм створив би три окремі середовища оточення. У цьому й полягає гнучкість концепції Serverless, де немає потреби у менеджменті серверів. Лямбда робить усе за нас.
Єдине «але» — є обмеження у 1000 лямбда-функцій, які виконуються одночасно. Про це варто пам’ятати при побудові складних продакшен-систем.
Щоправда, цей показник поступово зростає. За необхідності можна поспілкуватися з техпідтримкою Amazon та пояснити свої потреби.
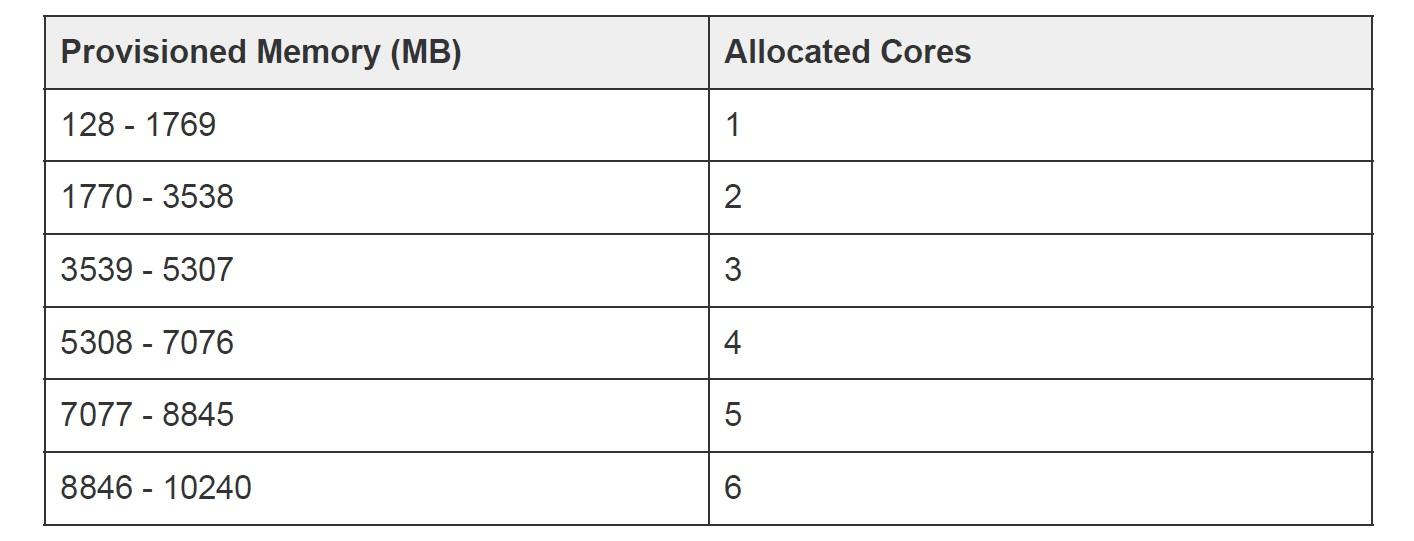
Якщо у віртуальних машинах можна налаштувати пам’ять, ядра, диск та процесор, то у лямбда-функції коригується лише об’єм оперативної пам’яті (від 128 МБ до 10 ГБ). При зміні цього параметра змінюється кількість ядер і потужність процесора, який буде задіяний для конкретного оточення. Як заявляють в Amazon, на кожні 1700 МБ оперативної пам’яті виділяється по одному ядру.
Хоча на практиці все виглядає дещо інакше і краще. Це показав досвід роботи з лямбда-функціями у нашій команді. Наприклад, при зміні пам’яті зі 128 МБ до 1 ГБ у звітах ми бачили дані про використання лише 100 МБ. Тобто продуктивність мала залишитися приблизно на тому ж рівні. Однак час на обробку скорочувався приблизно втричі! Хоча у нас так само працювало лише одне віртуальне ядро.
Продовження статті про лямбда-функції читайте згодом на Highload. Stay tuned!
Коротко про українську IT-сферу у 2024 році Це коли на одну вакансію Middle розробника по…
Формування криптовалютної галузі в Україні почалося ще у 2014 – саме тоді з'явилися перші стартапи,…
Автор цього блогу — Python-девелопер Сергій Солдатов, який вирішив створити досить унікальний продукт. І це…
Думки шукачів діляться на: «так, однозначно» і «ні, не вартує, я все і так про…
Синдром студента — це форма прокрастинації, яка полягає в тому, що людина, якій дали завдання,…
Git — це найпопулярніша CVS прямо зараз, яка дозволяє відстежувати історію розробки і спільно працювати.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}