Частий головний біль розробників — обробка сотень файлів різних форматів і типів за єдиним принципом. Та цей процес реально автоматизувати. Configuration Driven Development дозволяє створити єдиний інтерфейс з конфігураціями для кожного джерела даних.
У нашій команді ми таким чином реалізували проєкт з обробки списків опитувань. Тут стали в пригоді лямбда-функції, потужні бібліотеки та хмарні сервіси. Тож ділюся напрацюваннями.
Замовник веде аналітику опитувань серед співробітників своїх клієнтів. Нам дістався проєкт з обробки списків майбутніх респондентів. Це десятки, інколи сотні рядків.
Історично процес відбувався так:
Думаю, в якийсь момент терпіти ці «пекельні борошна» стало б неможливо. Перед нами стояла задача автоматизувати обробку всіх даних.
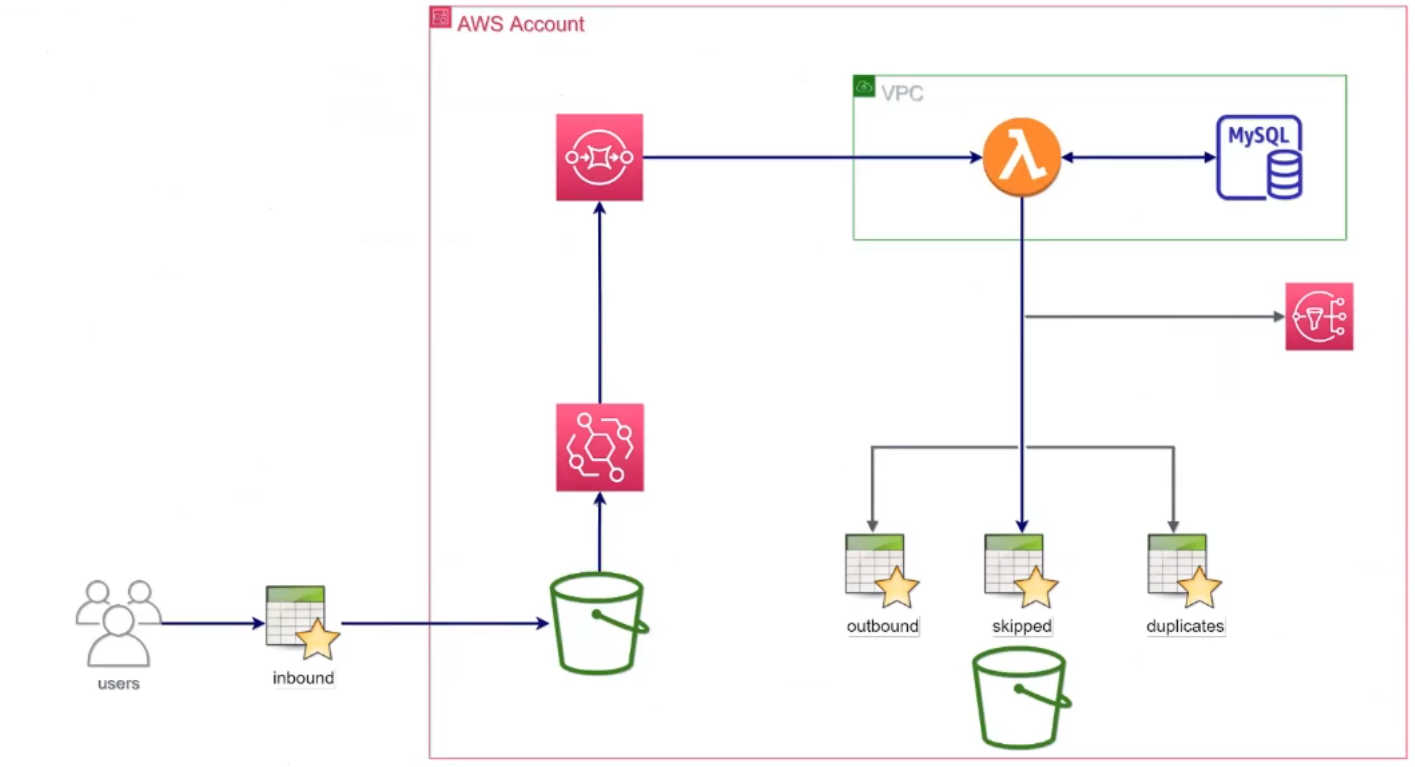
Ми розробили флоу, для користувача все виглядає просто: він завантажує inbound-файл до S3 bucket та отримує звіт у SNS topic. З нього можна дізнатися, які дані відфільтрувалися як невалідні та чому. Також побачити оброблені дані та посилання на ці файли. Під капотом для цього в EventBridge формується подія, яка стає в чергу в SQS. З цієї черги її обробляє лямбда-функція. Вона фільтрує дані, виконує перетворення і зберігає результати до бази даних та в S3 bucket.
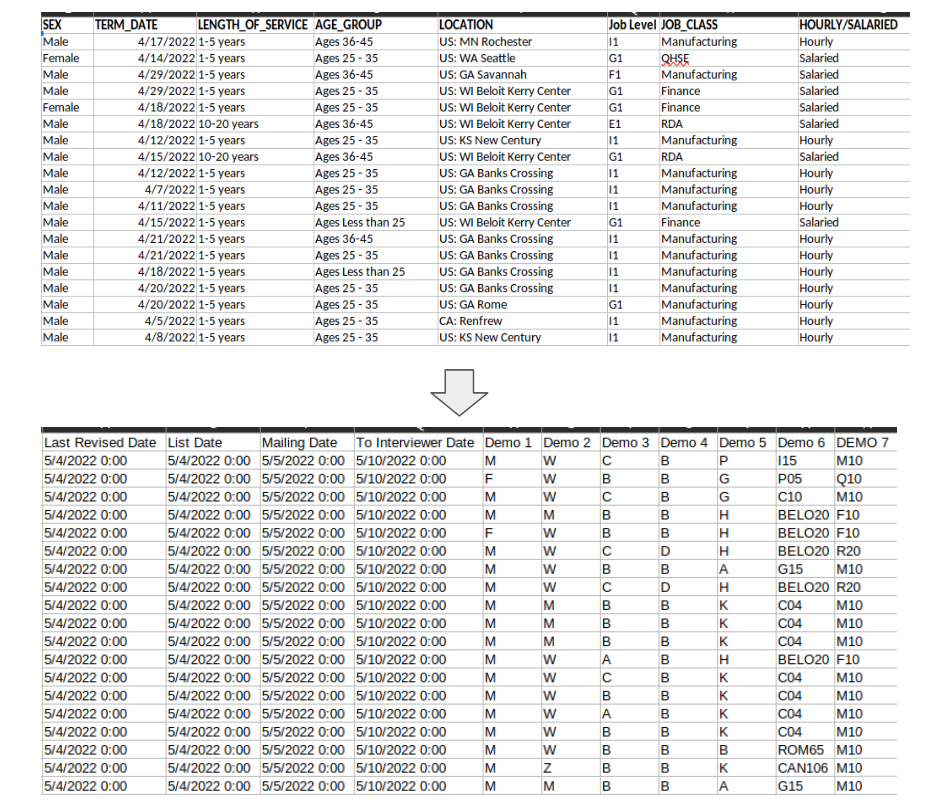
Процес досить тривіальний. Передусім треба валідувати рядки вхідного коду і генерувати нові поля. Наприклад, дати та унікальний ідентифікатор. Також потрібно обчислювати «демографічні функції» (вони ж — демофункції) на базі наявних полів. Визначаючи інтерв’юерів, враховувати їх відпустки. А для клієнтів та їх співробітників із Квебеку варто призначати інтерв’юерів, які володіють французькою.
Це те, за що я власне й полюбив цей проєкт. Хочу поділитися з вами найбільш показовими челенджами.
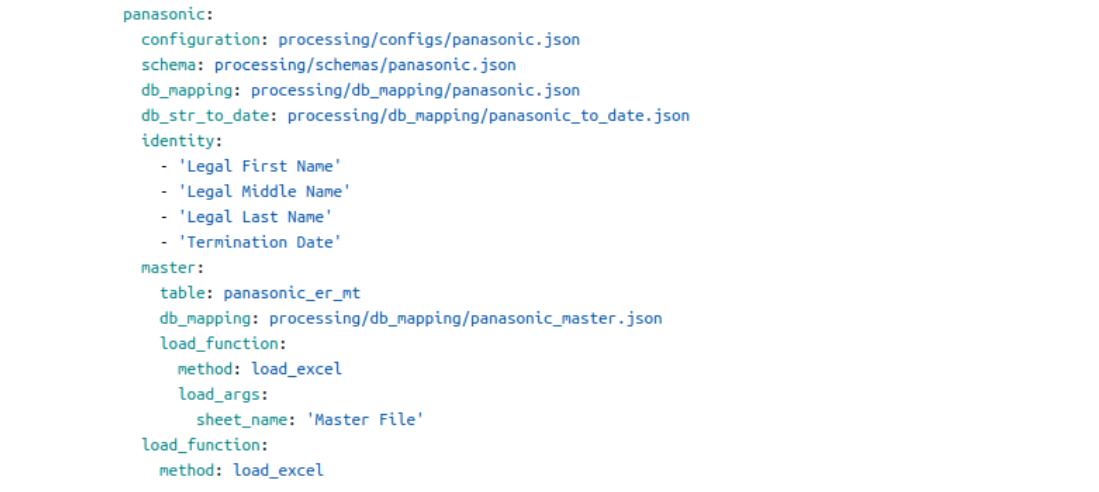
Основний виклик полягав у тому, що жодні два клієнти не мали однакової структури даних та їх форматів. Клієнтів було близько 200, і в кожного по 10-50 демофункцій. Вимагався єдиний процес, але з різними правилами. Розв’язати цю проблему вдалося на основі конфігурацій. Коли потрібно створити конфігурацію для нового клієнта, додаємо лише декілька файлів у JSON та YAML. Жодного нового рядку коду! Так, лямбда-функція виходить завеликою. Та вона одна, її легко підтримувати.
Наступна складність — поява особливих кейсів, які навіть при цій гнучкості важко хендлити. Тут ми налаштували динамічний вибір класу клієнтів.
З часом система росла, додалися ще три флоу. Вони надають змогу змінити дані, які вже оброблено. Щоб не переписувати конфігурації для кожного флоу, ми ввели теги. Тепер із базової конфігурації можна виділити підмножину конфігурацій, необхідні для певного флоу.
Не можу не згадати Mail Merge. Ця функція дозволяє генерувати листи співробітникам — запрошення пройти опитування. Йдеться про справжні паперові листи! Детальніше про впровадження цього функціоналу розповім далі.
У ході процесингу даних треба впевнитись, що при їх перетворенні немає ризику завалити систему. Тож ми впровадили декілька валідаторів. Спершу за притаманними для конкретного клієнта конфігураціями ми намагаємося зчитати дані у pandas DataFrame. Це може бути xls, csv із різними сепараторами, різна кількість хедерів тощо. Якщо вдається, валідуємо колонки відповідно до схеми. Це дозволяє переконатися, чи є всі поля. У разі позитивної відповіді можна переходити до валідації даних.
Передусім валідуємо identity-поля, які формують унікальність даних. Це може бути комбінація з прізвища, ім’я та дати звільнення співробітника. Якщо дані в рядках та полях валідні, перевіряємо унікальність цих записів у скоупі файлу та в скоупі всіх історичних даних клієнта. Всі неунікальні дані відфільтровуємо до дублікатів, а решту — знову валідуємо за схемою.
На виході маємо три фрейми: валідні та невалідні дані, дублікати. Валідні дані ми процесимо та зберігаємо далі. Інші ж зберігаються до S3 у файли, щоб клієнт міг усе перевірити та власноруч виправити помилки.
Велику кількість конфігурацій для кожного клієнта можна назвати фішкою цього проєкту. На нульовому рівні ми створили опис клієнта в YAML-файлі та посилання для нього на різні види. Це конфігурація ETL-процесу, схема валідації, допоміжні мапінги, таблиця в базі, identity-поля та методи завантаження з файлу. Я розповім детальніше про два види конфігурації.
Схема являє собою сукупність описів полів для inbound-файлу. Якщо ми не довіряємо вибір типу даних pandas, є можливість явно вказати тип для цих полів. Також можна додати різні предикати. Наприклад, позначити, чи є поле обов’язковим і провалідувати його регулярним виразом. А ще можна додати багато бізнес-валідаторів.
У прикладі нижче є такі імплементовані валідатори, ми тут нічим не обмежені. Тож все, чого потребує бізнес, можна втілити як функцію. Вона буде давати відповідь, чи є дані валідними.
Під капотом ця красива і компактна конфігурація трансформується в код, аналогічний псевдокоду (праворуч на ілюстрації). Це дає змогу ефективно валідувати дані. Для невалідних даних можна вказати, в яких колонках потрібно перевірити ті чи інші поля та виправити помилки.
По суті це масив перетворень, які виконуються над Data Frames. Ці перетворення — набір функцій, скомпонованих у декілька пакетів для обробки тексту, чисел, дата-фреймів тощо. Усі пакети ми детально документували. Якщо клієнту знадобиться ще одна форма обробки, можна додати скільки завгодно нових функцій. Весь процес нагадує збірку конструктора: беремо готові функції, певним чином комбінуємо їх — та отримуємо потрібну конфігурацію:
Ще одна цікава задача — обробка паперових листів. Цей функціонал передбачено приблизно для половини клієнтів. Тут ми створили окрему лямбда-функцію. Вона стартує вранці кожного робочого дня. Для цього в EventBridge формується подія, яка тригерить лямбда-функцію, аби та зробила запит до БД. Для кожного клієнта проходить перевірка: чи є співробітники, які мають отримати листа. Ця вибірка надсилається на Microsoft Mail Merge template. Ми отримуємо документи із заповненими даними. Таких шаблонів можна створювати безліч, та зазвичай використовуються три:
Потім ці документи пакуються в єдиний архів для клієнта і розміщуються у відповідне сховище. Окремий фахівець відкриває архіви, роздруковує потрібні листи, вкладає їх у конверти та передає до поштового сервісу.
Щоб переконатися у надійності системи, ми використовуємо юніт-тести. Всі нові функції, які додавалися в систему, було покрито тестами. Ми запускали їх при кожному білді.
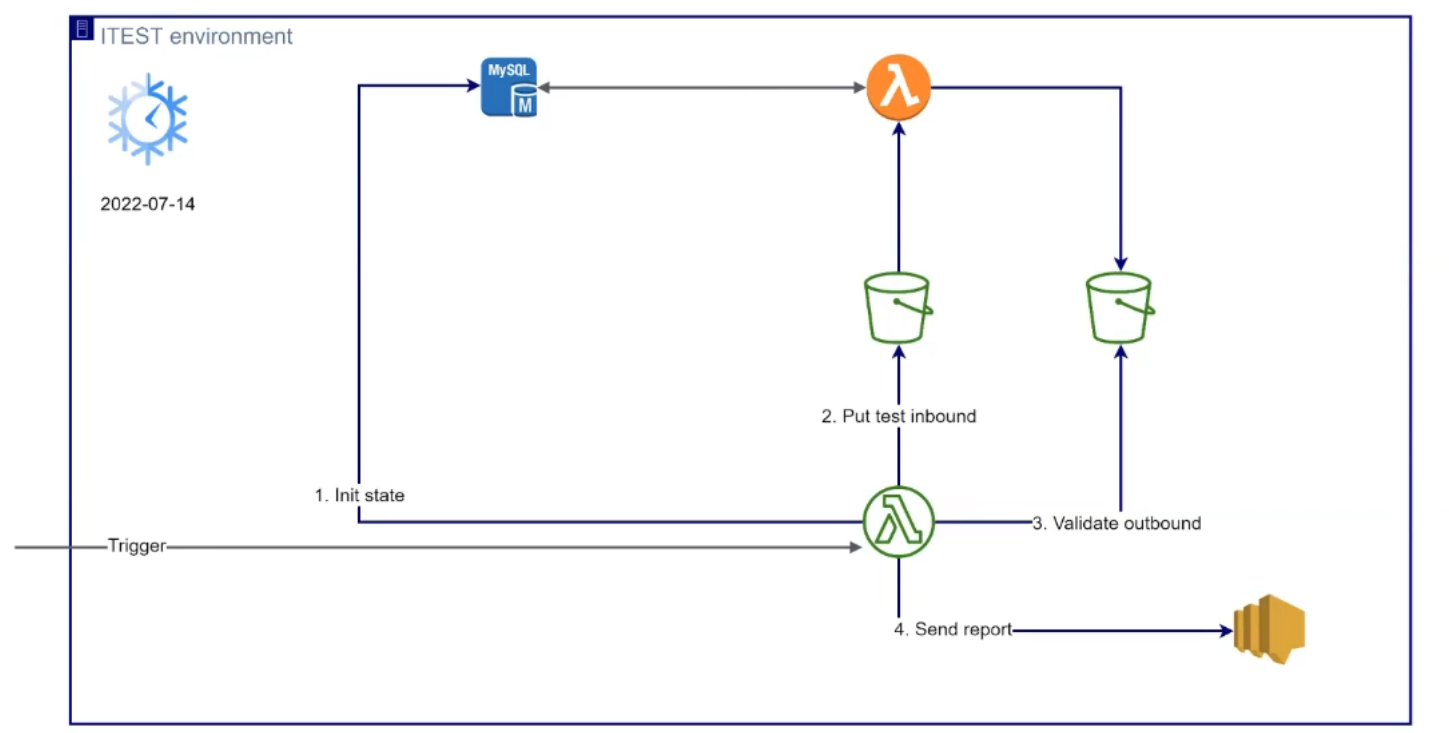
Також при білді на девелопмент перевіряємо взаємодію всіх компонентів на iTEST environment. Хочу зазначити тут маленьку хитрість. Наша функція не stateless, тобто вона залежить від стану бази та поточної дати. Тому ми наділили лямбду «супервластивістю».
Використовуючи певну змінну оточення, для тестових цілей можна задати поточний час на сервері. Так вдається перевірити результат за вказаною датою. Деплоїмо спеціальну функцію для інтеграційного тестування з пайплайну. Далі ця функція ініціює стан у базі, завантажує inbound-файли, очікує на outbound-файли та звіряє їх з еталонними відповідями. Результат буде у вигляді репорту до SNS topic:
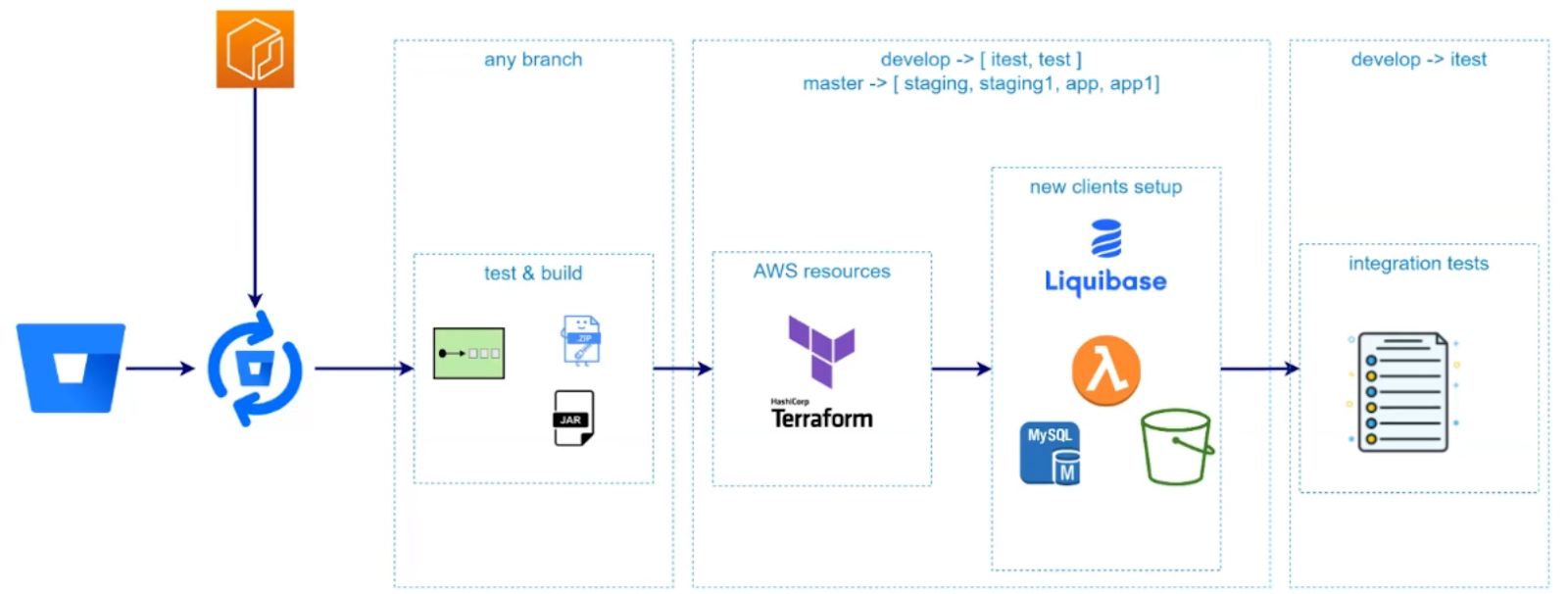
На цьому проєкті я додатково взяв на себе роль DevOps та налаштовував CI/CD процеси. Побудував усе на Bitbucket Pipelines. Основним інструментом управління ресурсами обрав Terraform.
Тут теж не обійшлося без челенджів. Наприклад, коли ми маємо сервер застосунку, то при старті сервера зазвичай відбувається ініціалізація ресурсів. Але ж у нас serverless-рішення. Тому в пригоді знову стає лямбда-функція. Вона створює в S3 bucket необхідну структуру директорії та таблиці в БД. При цьому функція деплоїться з пайплайну і звідти ж викликається:
Ми вже завершили роботу над цим проєктом і все передали клієнту. Рішення вийшло доволі просте, якісно задокументоване. До того ж я провів декілька knowledge transfer сесій, що корисно для всієї команди. Наразі замовник самостійно підтримує та розвиває проєкт. Відтак у його спеціалістів не виникає труднощів, скажімо, із заміною мапінгів або створення за день двох-трьох конфігурацій.
І головне — все це в результаті реально заощаджує час. Те, що раніше займало 40 хвилин, тепер виконується за 40 секунд! Крутий результат, чи не так?🙂
Коротко про українську IT-сферу у 2024 році Це коли на одну вакансію Middle розробника по…
Формування криптовалютної галузі в Україні почалося ще у 2014 – саме тоді з'явилися перші стартапи,…
Автор цього блогу — Python-девелопер Сергій Солдатов, який вирішив створити досить унікальний продукт. І це…
Думки шукачів діляться на: «так, однозначно» і «ні, не вартує, я все і так про…
Синдром студента — це форма прокрастинації, яка полягає в тому, що людина, якій дали завдання,…
Git — це найпопулярніша CVS прямо зараз, яка дозволяє відстежувати історію розробки і спільно працювати.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}