Валдіс Герасимяк – Lead Deep Learning Engineer в компанії Ajax Systems. Він почав займатися штучним інтелектом сім років тому за напрямом комп’ютерного зору. Зокрема, створив стартап, який поєднав AI з відеореєстратором велосипеда. Це допомагало б розпізнавати небезпеку на дорозі.
Айтівець також має значний досвід у напрямі AI для мобільних edge-пристроїв, а зараз розробляє foundation-моделі![]()
![]() моделі машинного навчання, що адаптуються до застосунків для комп’ютерного зору.
моделі машинного навчання, що адаптуються до застосунків для комп’ютерного зору.
Валдіс Герасимяк робить невеликий прогноз щодо AI, розповідає про переваги основних його напрямів і технологій і дає поради початківцям в AI-розробці.
Хайп зі штучним інтелектом
Усі напрями в AI мають потенціал, але опиняються на вершині хайпу в різний час. Прикладом може бути генерація зображень, де перейшли від техніки GAN до diffusion-моделей. Це забезпечило стрибок у використанні нейронок серед простих користувачів, тому що GAN здебільшого були популярними тільки через діпфейки.
А перехід у створенні тексту від RNN до трансформерів – це види архітектур нейронних мереж – сприяв появі таких моделей, як GPT-3, а пізніше і ChatGPT.
Зараз хайп базується на тому, що технології дозволяють генерувати майже будь-який контент – картинки, текст, музику, частково відео – на основі текстового опису, який надає людина. Це й називається Generative AI![]()
![]() Gen AI.
Gen AI.
Як опанували AI в Україні
Нещодавно мене запитали, які напрями AI будуть найбільше розвиватися в найближчі 1–5 років. Але я вважаю за доцільне прогнозувати не більше ніж на рік уперед. Ніхто не знає, що буде з AI за пʼять років – настільки все швидко змінюється.
Великий потенціал є в комп’ютерного зору, який трохи відстав від natural language processing![]()
![]() NLP – це коли машина обробляє сказане людиною. І хоча комп’ютерний зір трохи важчий, бо зображення має набагато більше деталей, ніж текст, проте має великі перспективи. Очі людей є, мабуть, найбагатшим джерелом інформації про світ навколо. Тому вважається, що в майбутньому нейромережі розумітимуть набагато більше, ніж сучасні моделі, якраз завдяки комп’ютерному зору.
NLP – це коли машина обробляє сказане людиною. І хоча комп’ютерний зір трохи важчий, бо зображення має набагато більше деталей, ніж текст, проте має великі перспективи. Очі людей є, мабуть, найбагатшим джерелом інформації про світ навколо. Тому вважається, що в майбутньому нейромережі розумітимуть набагато більше, ніж сучасні моделі, якраз завдяки комп’ютерному зору.
Якщо говорити про те, які напрями AI найкраще опанували в Україні, то можна подивитися по стартапах. У першу чергу це фото- й відеогенерація, наприклад, такі стартапи, як Reface. Також ZibraAI є прикладом розвитку AI в індустрії ігор. А Grammarly – це приклад розумного використання штучного інтелекту в роботі з текстом. Я гадаю, всі напрями AI в Україні гарно розвиваються, навіть останні з Gen AI.
Переваги і перспективи різних напрямів AI
- Моделі текст-у-зображення
Ви даєте текстовий опис – AI генерує картинку. Іноді таких картинок треба генерувати одразу багато, оскільки частина буде нереалістичною або не відповідатиме тому, що ви хочете бачити. Підбір текстових описів, або промтів, є зараз актуальним напрямом в інженерії, він називається промт-інжиніринг.
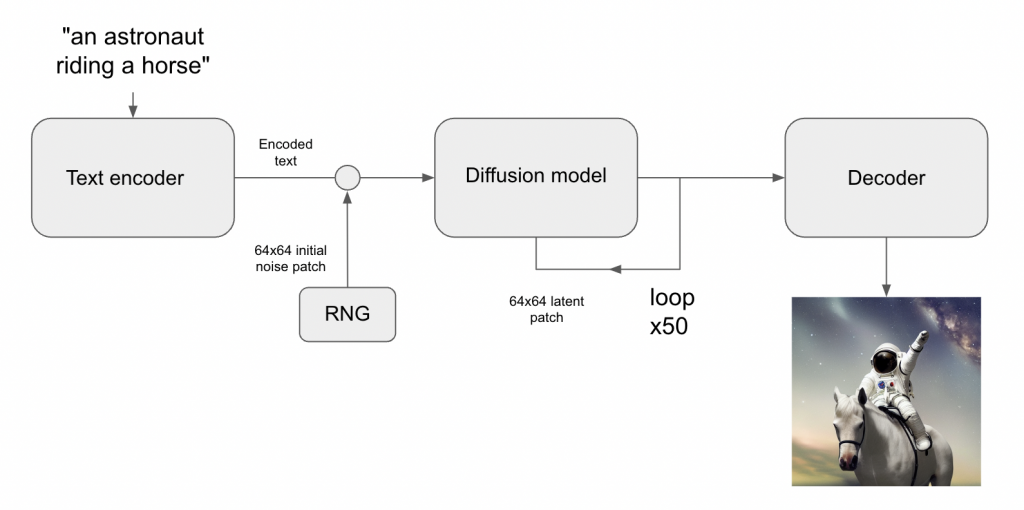
Є моделі, які доступні тільки по API, тобто вся модель запускається на сервері, а на ваш промт повертається зображення. Використовуючи промт-інжиніринг, можна швидко зробити продукти, але за кожну згенеровану картинку треба платити. Так працює Midjourney та DALL-E![]()
![]() продукт OpenAI. Моделі загальні, тобто в певних випадках вони не будуть добре генерувати саме те, що вам потрібно, наприклад специфічні кейси. У такому разі доведеться донавчати свою модель.
продукт OpenAI. Моделі загальні, тобто в певних випадках вони не будуть добре генерувати саме те, що вам потрібно, наприклад специфічні кейси. У такому разі доведеться донавчати свою модель.
Якщо говорити про донавчання таких моделей![]()
![]() fine-tuning, то тут все в основному базується на Stable Diffusion або новішій Stable Diffusion XL. Це відкрита нейронка від компанії Stable AI та найрозповсюдженіша модель такого роду. Донавчання не займає багато ресурсів, за 2–5 годин роботи GPU можна зробити свою нейронку з 20–50 ваших фото.
fine-tuning, то тут все в основному базується на Stable Diffusion або новішій Stable Diffusion XL. Це відкрита нейронка від компанії Stable AI та найрозповсюдженіша модель такого роду. Донавчання не займає багато ресурсів, за 2–5 годин роботи GPU можна зробити свою нейронку з 20–50 ваших фото.
Найбільш досвідчені інженери можуть кастомізувати Stable Diffusion, яка складається з кількох менших нейромереж. Це може або пришвидшити її, або підʼєднати до неї якусь іншу технологію – усе залежить від завдання і кругозору розробника.

На базі Stable Diffusion зараз стає популярним напрям генерації відеоконтенту. Це складніше, ніж генерація картинок: заважає, те що об’єкти постійно змінюються від кадра до кадра, виходить такий собі мультик. Наразі існує багато нерозв’язаних задач, тож попереду нас чекає ще безліч відкриттів.
- Великі мовні моделі
Їх ще називають Large Language Model![]()
![]() LLM або моделлю текст-у-текст. Велику кількість ринку займає OpenAI зі своїм продуктом ChatGPT. Вони зробили дійсно круту базову модель, яка розуміє контекст, може підсумовувати або, навпаки, роздувати текст. Добре переводить, пише листи й багато чого іншого. Доступна на сайті або через API, за кожен запит треба платити.
LLM або моделлю текст-у-текст. Велику кількість ринку займає OpenAI зі своїм продуктом ChatGPT. Вони зробили дійсно круту базову модель, яка розуміє контекст, може підсумовувати або, навпаки, роздувати текст. Добре переводить, пише листи й багато чого іншого. Доступна на сайті або через API, за кожен запит треба платити.
Багато бізнесів використовує LLM, щоб будувати свої продукти. Наприклад, можна зробити так, щоб ChatGPT користувався вашими базами даних і робив відповіді на основі цих знань.
Якщо треба донавчати моделі, зверніть увагу на моделі LLaMa від Meta. Вони зараз одні з найдоступніших, а ще до них існує багато інфраструктури й коду.
Взагалі напрям LLM перспективний тим, що цю технологію активно використовуватимуть в інтернеті. Тобто там, де панує текст.
- Комп’ютерний зір
Це, мабуть, найрозповсюдженіша технологія AI сьогодні. Вона працює майже всюди у світі: у кожному смартфоні, у більшості камер відеоспостереження, на відеоконференціях. Усюди, де треба розпізнавати об’єкти на фото або відео, а також щось робити з ними, наприклад, заблюрити фон, вирізати щось. Комп’ютерний зір здатен знайти обличчя людини, підказати правильні пози у тренуванні, ідентифікувати ракові пухлини на рентгенівському знімку, виявити ворожі танки в кущах тощо.
Розвиток цієї технології завжди стримувала потреба у великій кількості фото- й відеоданих для її тренування. Зараз відбувається перехід від supervised learning![]()
![]() навчання з розмічених даних до self-supervised learning
навчання з розмічених даних до self-supervised learning![]()
![]() коли можна не розмічати дані, тобто датасети стають більшими.
коли можна не розмічати дані, тобто датасети стають більшими.
Початківцям нескладно розвиватись у цій сфері, оскільки про computer vision вже написано багато навчальних матеріалів і гайдів. Я раджу розпочати знайомство з лайтових курсів, де буде відразу більше практики ніж теорії. Наприклад, спробувати курс від Fast AI.
- Архітектура трансформерів
Це модель, головна фішка котрої механізм уваги. Завдяки йому вона розуміє весь контекст вхідної послідовності. Наприклад, якщо вихідні дані – текст, то не треба чітко слідкувати за послідовністю слів, бо модель розуміє весь зміст. Це дало змогу робити моделі набагато більшими. Наприклад GPT-3.5 має 175 млрд параметрів, а до цього моделі мали до 1 млрд параметрів.
Більша модель може тримати в собі більше інформації і краще розуміти контекст. Недарма ChatGPT називають «розмитим фото всього інтернету», адже він вчився буквально на інформації з усього інтернету.
Архітектура трансформерів зараз виходить на перший план не тільки в мовних моделях, але й у комп’ютерному зорі. Потенційно вона здатна об’єднувати ці напрями, до того ж вона дуже добре масштабується.
Для роботи із цією моделлю на вході треба їй подавати невеличкі відрізки тексту або картинки. Це можуть бути маленькі слова або частини слів. А для комп’ютерного зору – частини зображення, наприклад, 16х16 пікселів.
Якщо в невеликих моделях комп’ютерного зору все ще панують згорткові нейронні мережі, то в найбільших моделях уже переважають трансформери. Тобто великі згорткові нейронні мережі вже насичуються та не навчаються так добре, як трансформери. Мабуть, комбінація цих підходів створить найбільший ефект.
- Кодування відео за допомогою нейронних мереж
Кодування відео й аудіо за допомогою нейромереж може потенційно зекономити місце на диску чи зменшити трафік під час відеоконференції або на стримінговому сервісі. Це зробить картинку якіснішою при такому самому трафіку.
Усе це поки що дуже нові технології, але суть наступна: не передавати саму картинку, а шифрувати вміст за допомогою нейромережі та передавати стислий опис того, що відбувається в кадрі. Далі друга нейромережа відтворює за цим описом картинку. Якщо одна й та сама людина в кадрі, то можна передавати тільки інформацію про те, що вона нахилила голову чи блимнула. І це набагато швидше передати, ніж усю картинку.
Щось подібне зараз спостерігаємо в іграх: відеокарта не рендерить кожен другий-третій фрейм, а передбачає його. Завдяки цьому збільшується FPS![]()
![]() англ. frames per second – кількість кадрів на секунду на екрані.
англ. frames per second – кількість кадрів на секунду на екрані.
- Генерування 3D-обʼєктів і контенту для метавсесвіту
Рекомендую звернути увагу на цю технологію тим, хто полюбляє VR/AR і все, що з ним пов’язано.
Зараз великі ритейлери впроваджують технології віртуальної примірки одягу. За допомогою нейромереж одяг можна генерувати набагато швидше, а також робити так, щоб він одразу ідеально підходив саме вам.
Також меблевий магазин, наприклад, може згенерувати ідеальні меблі саме для вашої кімнати. Для цього знадобиться пара фото приміщення, навіть зі старими меблями. У 3D-просторі одні нейромережі видалять зображення старих меблів, а інші нейронки згенерують нові меблі на ваш смак.
Але ще є метавсесвіт, де ви зможете, наприклад, інтегрувати 3D-модель одягу на всіх ваших аватарках чи старих світлинах. І навіть зможете бути «вдягненими» в цей одяг під час відеоконференцій.
Meta займається такими технологіями вже 5–7 років, а з виходом Apple Vision Pro, гадаю, цей напрям стрімко розвиватиметься. Поєднання віртуального та нашого світу буде мати багато послідовників, які захочуть на повну використовувати можливості генерування 3D-одягу.
Вихід Apple на ринок зі своєю гарнітурою змішаної реальності буде пришвидшувати цей перехід, оскільки бренд зробив справді проривний гаджет, з яким дійсно можна працювати й насолоджуватись усіма барвами AR-технології.
Яким стане IT під впливом AI
Якщо говорити про використання AI для написання софту, то тут усе гарно. Є статистика: коли люди використовують штучний інтелект в роботі, вони роблять її приблизно на 55% швидше. Гадаю, це допоможе якісніше працювати, писати код, генерувати контент та інше.
За втрачання робочих місць я б не турбувався. Професії будуть трансформуватися, люди займатимуться більш високорівневими задачами, ніж просто писати код чи створювати SEO текст.
Ті, хто буде активно і з розумом використовувати AI, матимуть ширший кругозір і переваги. Вони будуть швидше знаходити відповіді, правити помилки та інше. Працювати без AI буде так, наче в наші часи писати код у блокноті чи на папері, тобто безглуздо.
Говорячи про те, які напрями AI можуть об’єднатися та дати крутий ефект, я схиляюся до того, що це комп’ютерний зір + NLP, тобто зображення + мова. Зараз люди багато досліджують навколо мультимодальних моделей, які об’єднують напрями.
Наприклад, можливо буде генерувати код не тільки за текстовим запитом, але й за допомогою комбінації тексту, голосового вводу та малювання блок-схем. Якщо треба створити зображення, ви зможете використовувати комбінацію з голосового вводу й тексту, а потім на вже згенерованому зображенні домалювати якусь важливу деталь.
Якщо ви розробник і плануєте перейти в AI, то краще йти у сферу, яка найближча до того, чим ви займалися раніше. Для мене це був комп’ютерний зір у безпілотних авто, оскільки я до цього створював електромобілі та був на «ти» з усіма датчиками. Під’єднати камеру та доповнювати картину розпізнаванням об’єктів з відео – це було для мене цілком зрозумілим і логічним кроком.
Три головні поради початківцям в AI-розробці
- Навчайтесь через розробку якихось петпроєктів. Ви відразу бачите, як створювати повноцінний проєкт, виявляєте свої слабкі боки.
- Переходьте до курсів, коли ви чітко розумієте, що саме ці курси вам на 100% потрібні та гармонійно доповнять ваш власний досвід.
- Активно цікавтеся новими розробками, течіями тощо. Йдіть за ідеями наступного дня: їх можна почути на форумах, у профільних чатах, X

 колишній Twitter, на сторінках соцмереж іменитих людей тощо. Знайдіть тих, хто пише зрозумілі для вас речі.
колишній Twitter, на сторінках соцмереж іменитих людей тощо. Знайдіть тих, хто пише зрозумілі для вас речі.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: