Ще декілька років тому, щоб отримати техпідтримку, треба було чекати вільного співробітника. 53% користувачів у світі казали, що ця частина взаємодії викликала в них найбільшу досаду. Тепер на найпоширеніші запитання відповідають чат-боти на основі ШІ. Серед опитаних компаній в Америці та Європі понад 60% уже впровадили їх у бізнес і майже 20% – планували. Після впровадження чат-ботів у перших їхні продажі зросли до 70%.
Останніми роками свою ШІ-команду активно розвиває і Favbet Tech. Ця IT-компанія розробляє рішення для бетингових платформ, де можна робити ставки і грати в ігри.
У партнерському матеріалі з Favbet Tech тимлід команди data science Олександр Стратієнко розповідає, які завдання компанії тепер виконує штучний інтелект, чому ШІ – це не тільки нейромережі та чи може всю команду замінити одна людина.
Коли та як математика перетворюється на ШІ
Штучний інтелект (ШІ, AI) – це створення систем, які можуть навчатися на даних і робити на їх основі певні висновки, прогнозувати події та їхні вірогідності. Тобто полегшувати роботу людини.
ШІ часто згадують поряд з data science і big data. Але одне не замінює інше. Data science – це сукупність інструментів і підходів для створення штучного інтелекту, а big data![]()
![]() великі дані – це, власне, дані, які використовуються для навчання моделей.
великі дані – це, власне, дані, які використовуються для навчання моделей.

Олександр Стратієнко, тимлід команди data science у Favbet Tech
Data science – це інтердисциплінарне поле. Воно містить як математику (матаналіз, лінійну алгебру, теорію ймовірностей тощо), так і мови програмування, як-от Python. Data science – це також алгоритми, за допомогою яких ми навчаємо моделі для вирішення завдань.
У чому ж тоді різниця між математикою та data science і ШІ? Коли одне переходить в інше?
Простими словами, коли людина вручну чи в коді прописує всі потрібні формули та підраховує вірогідність події чи якийсь інший результат – це математика. А коли людина створює алгоритм, за яким машина сама робить ці розрахунки, – це вже штучний інтелект.
«Математичні підходи для задач Favbet Tech ми використовували вже давно, але тільки 2021-го почали впроваджувати саме ШІ», – каже Олександр.
Дізнатись більше про Favbet Tech.
Як працюють ШІ-алгоритми
Хоча багато базових алгоритмів мають реалізацію на різних мовах програмування та використовуються фахівцями по всьому світу, ШІ-інженер повинен розуміти, як працюють ці алгоритми та як їх використовувати для конкретних бізнес-завдань. Перевага ШІ в тому, що, на відміну від людини, він зможе обробити набагато більше даних і визначити, які з них найважливіші. Крім того, ШІ робить розрахунки набагато швидше.
Ось як це працює на прикладі нейронних мереж. Припустимо, у нас є алгоритм для визначення ймовірності того, чи поверне клієнт банку кредит. Спочатку нейромережу треба навчити.
- У нейромережу завантажують характеристики наявних клієнтів, що вже брали кредит. Серед характеристик можуть бути, наприклад, вік, рівень зарплатні, наявність чи відсутність вищої освіти, стать тощо. Це все стає вхідними даними нейронної мережі.
- З комбінації цих даних створюються нейрони мережі. У кожного нейрона є порядковий номер і вага

 важливість для підрахунку.
важливість для підрахунку. - Оскільки клієнтів банку дуже багато – це можуть бути мільйони людей – нейронна мережа може точно визначити, яка характеристика важлива і наскільки, тобто оновити вагу відповідного нейрона.
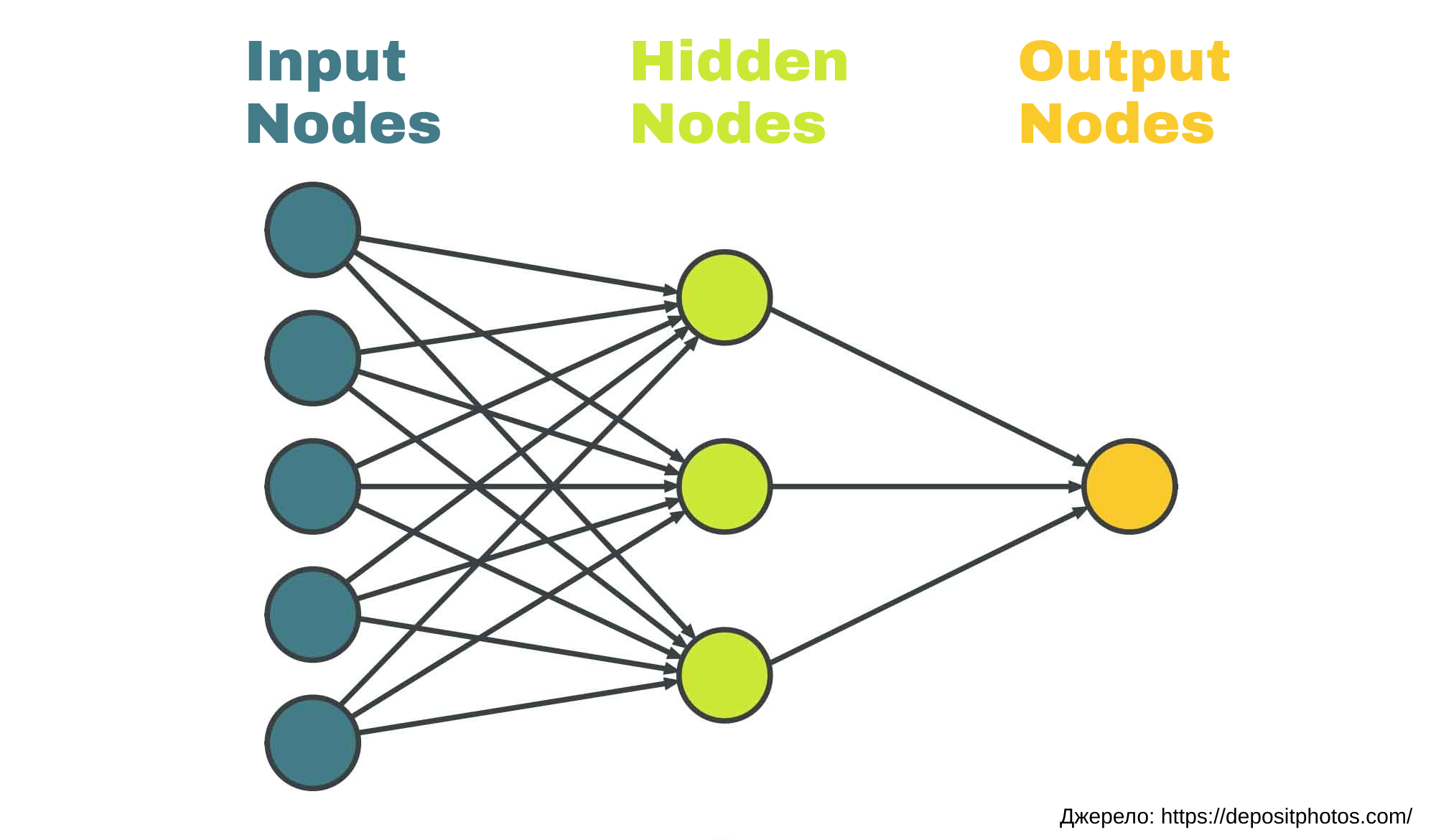
Схематичне зображення нейронної мережі
У навчену мережу подають характеристики клієнтів, за якими треба зробити розрахунок. Їхні ваги математично виглядають як матриці, які певним чином перемножуються, і результатом цього перемноження є висновок – Х% вірогідності, що клієнт поверне кредит.
Хоча під ШІ часто розуміють нейромережі, бувають й інші ШІ-алгоритми, наприклад, засновані на деревах рішень. У цих алгоритмах немає нейронів, але є ноди (вузли). Схема алгоритмів візуально виглядає як реальне дерево: тобто в кожному конкретному випадку є багато варіантів, якою гілкою піти і який результат отримати.
Дерева рішень є набором правил, у яких різні значення характеристик впливають на фінальний результат. На відміну від нейромереж, вони явно показують, яка характеристика так чи інакше вплинула на результат.
Окрім завдань кредитного скорингу, який ми згадували вище, дерева рішень використовують і для складніших моделей, наприклад, для розуміння, як зміниться поведінка користувача при певній комунікації. Як-от коли треба проаналізувати клієнта й визначити, яке заохочення йому дати.
Окрім нейромереж і дерев існує безліч інших алгоритмів. За словами Олександра, немає єдиного правильного рішення, для якого завдання який алгоритм використовувати. Зазвичай тестують кілька підходів, порівнюють швидкість і точність роботи алгоритму і тоді вирішують.
Більше про рішення для бетингових платформ тут.
Які бізнес-задачі може розв’язувати ШІ: власний досвід
ШІ розв’язує задачі різного рівня складності. Наприклад, задача визначити, чи потенційний клієнт зможе повернути кредит, є досить розповсюдженою і входить до задач класифікації.
Іншою задачею може бути створити на основі ШІ рекомендаційної системи чи системи anti-fraud.
Рекомендаційні системи
«Рекомендаційні системи, підімкнені до різних сайтів, пропонують якийсь список продуктів, підібраний індивідуально для користувача, – пояснює Олександр. – Наприклад, ігри чи фільми, які сподобаються саме вам».
Вдало підібрані ШІ рекомендації значно покращують user experience – досвід користувачів. Вони витрачатимуть менше часу на пошук цікавого їм товару чи продукту, імовірніше, що залишаться на сайті, якщо запропонований продукт зачепить їх з першого погляду, та, скоріш за все, повернуться, якщо це виявиться саме тим, чого вони хотіли.
Алгоритми Favbet Tech написані під кожний конкретний випадок: наприклад, «холодний старт» – коли користувач новий, але йому все одно треба щось порекомендувати. Тоді це може бути 20 найпопулярніших продуктів.
«Ми бачимо, що клієнт менше часу проводить у пошуку необхідного йому продукту, росте кількість клієнтів і рівень прибутку від продажів, – розповідає Олександр Стратієнко. – Ми тестували, що в рекомендаційному сервісі працює краще – рандом чи алгоритм, і ШІ перемагає».
Системи anti-fraud
Фрод (fraud – шахрайство) розповсюджений в електронній комерції, у фінтех-галузі, а також у бетингу.
«Категорій фроду у ставках на спорт дуже багато, але розбиратися в них – завдання букмекерів, – каже тимлід команди data science. – Ми займаємось розробкою алгоритму, який може визначити, чи є клієнт потенційним шахраєм».
Запобігання ігровій залежності
Ігрова залежність, або лудоманія, – це психологічний розлад, при якому людина не здатна контролювати час і гроші, які витрачає на гру. Бетингові платформи просувають ставки як розвагу, а не вид заробітку і докладають усіх зусиль, щоб допомогти людям грати відповідально.
«Відповідальна гра – це пріоритетний проєкт для нашої команди: ми вкладаємо в нього багато сил і ресурсів», – каже Олександр.
Основне завдання штучного інтелекту – визначити підозрілу активність користувача, наприклад, аномальні витрати, що можуть свідчити про розвиток залежності. Наприклад, якщо якийсь клієнт витрачав зазвичай $200 і раптово вклав $1 тис.
«Це гнучка й індивідуалізована система. Тому що для когось $200 буде звичайною системою, а для когось – аномалією, – пояснює Олександр. – Тому ШІ аналізує підозрілу активність, враховуючи різні характеристики клієнтів, їхні звичайні витрати і, головне, час, проведений на платформі, а також інші цифри, які алгоритм визначить як важливі».
Інформація про аномалії передається менеджерам, і ті вже вирішують, що із цим робити: чи то блокувати користувача, чи обмежити його ігрову активність.
Подивитися, які бізнес-задачі розв’язує Favbet Tech за допомогою ШІ, можна тут.
Впровадження штучного інтелекту в бізнес: як виглядає на практиці
Розробка
Проєкт із ШІ починається із задачі, яку можна розв’язати за допомогою цього інструменту, наголошує Олександр. Під задачу підбирають технології та команду.
До команди мають входити як ті, хто працюватиме з даними (дата-сайнтисти, дата-інженери та дата-аналітики), так і ті, хто розгортатиме проєкт (девопси) та його адмініструватиме, тобто проджект-менеджери. «На кожному проєкті свій стек технологій, – каже тимлід команди data science у Favbet Tech. – Математичну модель зазвичай розробляють на Python, але потім її треба інтегрувати у продукт за допомогою одного із хмарних рішень, наприклад AWS».
Велика команда потрібна для масштабних завдань. Якщо бізнес хоче спробувати цей інструмент на простій задачі, з таким проєктом може впоратися навіть одна людина, вважає Олександр. Але цей фахівець повинен мати навички і в дата-інжинірингу, тобто процесі збирання, обробки і зберігання даних з різних джерел, і в data science – аналізі даних і підбиранні необхідного алгоритму, а також у розробці, аби імплементувати алгоритм у конкретний продукт.
Самі ШІ-алгоритми з нуля дата-сайнтисти зазвичай не пишуть, бо базові реалізації вже існують – їх створили великі компанії на кшталт Google чи Facebook. Але бувають випадки, коли готові моделі треба модифікувати.
«Наприклад, я створював для Favbet Tech новий алгоритм для прогнозування кількості голів у різних видах спорту: футболі, баскетболі тощо, – розповідає Олександр. – Готової моделі саме під спорт не було, але я взяв за основу ідею іншого алгоритму машинного навчання».
Складність впровадження ШІ на проєкт ще й у швидкості. На складну систему, навіть якщо базовий алгоритм уже є, може піти рік-півтора. Але в середньому проєкт займає від трьох місяців до року разом з тестуванням.
Тестування
«Ми намагаємося уникати ситуацій, коли баги виявляються вже на продакшені, тому використовуємо декілька етапів перевірки», – розповідає Олександр Стратієнко.
Наприклад, для рекомендаційної системи треба перевірити релевантність персональних рекомендацій і дотримання всіх бізнес-правил. Також треба перевірити роботу сервісу під навантаженням, щоб бути впевненим, що він не впаде та час відповіді сервісу буде достатньо швидким.
Після цього можна приступати до A/B-тестування з розподілом вибірки на пілот/контроль і подальшим порівнянням відповідних бізнес-метрик.
«Звичайно, навіть з таким підходом трапляються помилки, – ділиться Олександр. – Але дуже банальні, наприклад, сервер не витримує навантаження. Були в нас помилки і в рекомендаційних системах, коли для клієнтів відображалися нерелевантні позиції. Тоді треба якнайшвидше виправляти помилку й оновлювати сервіс».
Favbet Tech планує розширяти ШІ-відділ. Серед найближчих завдань – автоматизація підтримки, бо вже є чимало цікавих готових рішень для цього, у тому числі ChatGPT. Також компанія продовжить розвиток систем anti-fraud, щоб охоплювати всі можливі схеми шахрайства, і рекомендаційного сервісу, який робить платформу зручнішою для користувачів.
БІЛЬШЕ ПРО рішення FAVBET TECH
УЧАСТЬ В АЗАРТНИХ ІГРАХ МОЖЕ ВИКЛИКАТИ ІГРОВУ ЗАЛЕЖНІСТЬ. ДОТРИМУЙТЕСЯ ПРАВИЛ (ПРИНЦИПІВ) ВІДПОВІДАЛЬНОЇ ГРИ.
Ліцензія на провадження діяльності з організації та проведення азартних ігор казино в мережі Інтернет від 20.04.2021 року, видана ТОВ «БК “ФАВБЕТ”» на підставі Рішення КРАІЛ від 05.04.2021 року за №137 із змінами та Ліцензія на провадження діяльності з організації та проведення букмекерської діяльності від 28.12.2022 року, видана ТОВ «БК “ФАВБЕТ”» на підставі Рішення КРАІЛ від 13.12.2022 року за №433.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: