Bulldog Puppy Sitting With Owner On Sofa Whilst He Works On Laptop
У цій статті я з точки зору бізнес-аналітика розповім, в яких ситуаціях краще використовувати нереляційні бази даних і з чим вони вам допоможуть.
Для початку пропоную розібратися з терміном NoSQL. Може здатися, що йдеться про відсутність SQL-запитів, але це хибна думка. З нереляційними базами даних можна спілкуватися і за допомогою таких звичних реквестів. Тому NoSQL фактично означає «Not only SQL».
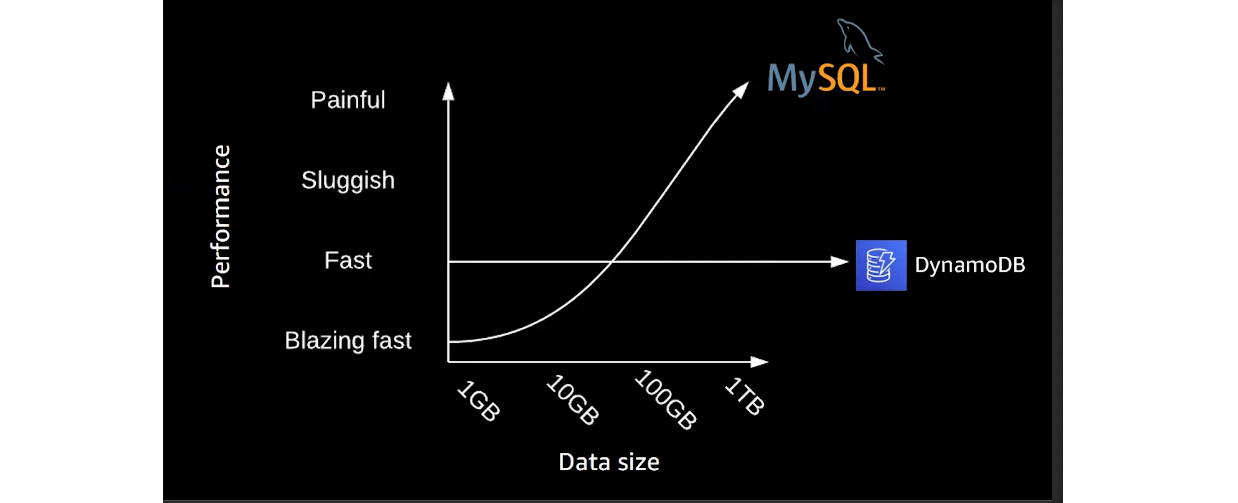
Необхідність запровадження відмінної від SQL бази даних назрівала давно. Останні 15 років об’єми даних стрімко зростають. Наприклад, Instagram свого часу вийшов на рівень завантаження близько 1000 фотографій та пересилання 8500 повідомлень за секунду. Сьогодні ці показники в рази вищі. Якщо обробляти значні ресурси даних класичними методами реляційних БД, система врешті-решт зупиниться.
У певний момент масштабування SQL-баз спробували вирішити технологією шардування. В результаті маємо фактично кілька різних БД. А це зовсім інша схема роботи. Однак гірше інше — зв’язки між утвореними шардами не працюють. Їх неможливо масштабувати в принципі. З нереляційними базами таких проблем немає. Вони стабільні з будь-яким обсягом даних.
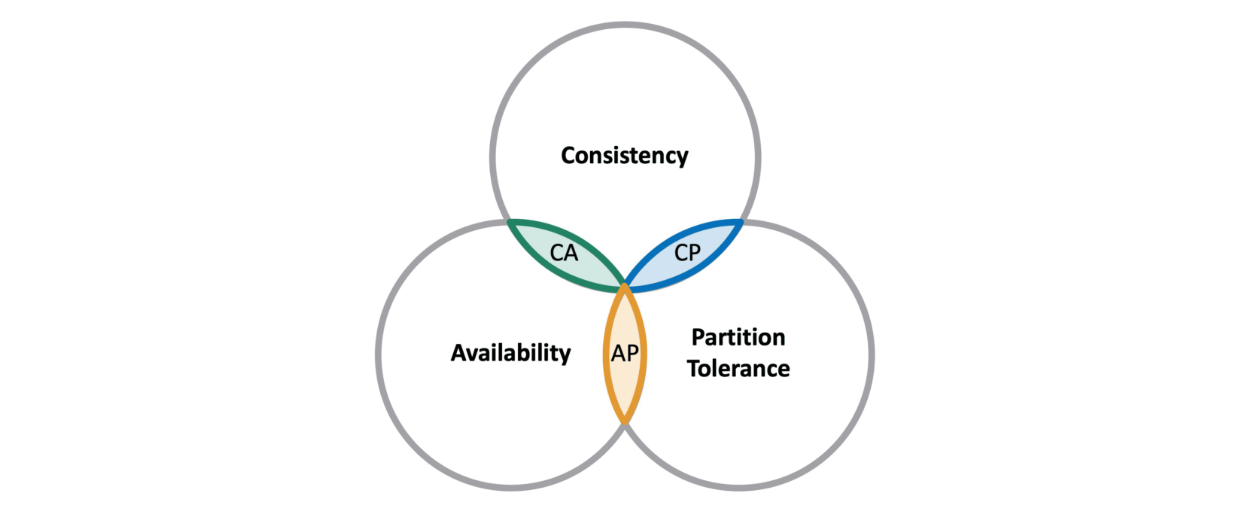
Традиційний підхід до зберігання та обробки даних описує абревіатура ACID:
У контексті порівняння з NoSQL я зробив би акцент на узгодженості. Коли ви звертаєтеся до даних у SQL, то впевнені в їх актуальності. Тут ви не зможете одночасно читати та переглядати дані. Теоретично це можливо, але нагадує читання книги паралельно з її написанням. Ви бачитимете сирі дані. Тому в реляційній моделі дані завжди узгоджені. Цей момент якраз обмежує масштабування.
В архітектурі NoSQL працює інший підхід — CAP:
Узгодженість є, без неї немає сенсу в будь-якій БД. Однак вимоги менш жорсткі.
Головний принцип нереляційної моделі — дані розподіляються між серверами. Таким чином вдається масштабування, але це призведе до порушення цілісності даних. Звертаючись до сервера, в якому дані ще не оновилися, ви ризикуєте отримати застарілу інформацію. Зрештою, лаг в актуалізації реплік є і в реляційній моделі. Досвід показує, що затримка оновлення у NoSQL вища, але з кожним днем різниця скорочується. Зараз нереляційні бази декларують Eventually Consistency. Зокрема, DynamoDB заявляє про лаг 10 мс. Такий показник доступний не завжди, та все одно відмінний.
Як виявилося, бізнес готовий піти на такі ризики заради переваг NoSQL.
Розглянемо це на прикладі банківських транзакцій. Узгодженість даних тут вважається критично важливою. Насправді ж банки йдуть на послаблення. Їхні бази даних величезні. Потрібно багато часу на обробку тисяч одночасних запитів від користувачів банкінгу. Якщо ставити їх у чергу на повне звірення (наприклад, під час видачі грошей у банкоматі), люди можуть не дочекатися реакції.
Тому банки переходять на іншу модель обробки даних. Вони звіряються з одним сервером, видають гроші та потім переконуються в узгодженості даних по всій базі. Якщо двоє людей дійсно одночасно захочуть зняти всі гроші з одного рахунку, вони їх отримають по суті двічі. Банк уже потім розбереться з цією помилкою. Адже насправді ймовірність попадання двох запитів у той мікролаг мінімальна. Банку дешевше покрити такий ризик, аніж слухати роздратування тисяч користувачів через тривалу обробку транзакції.
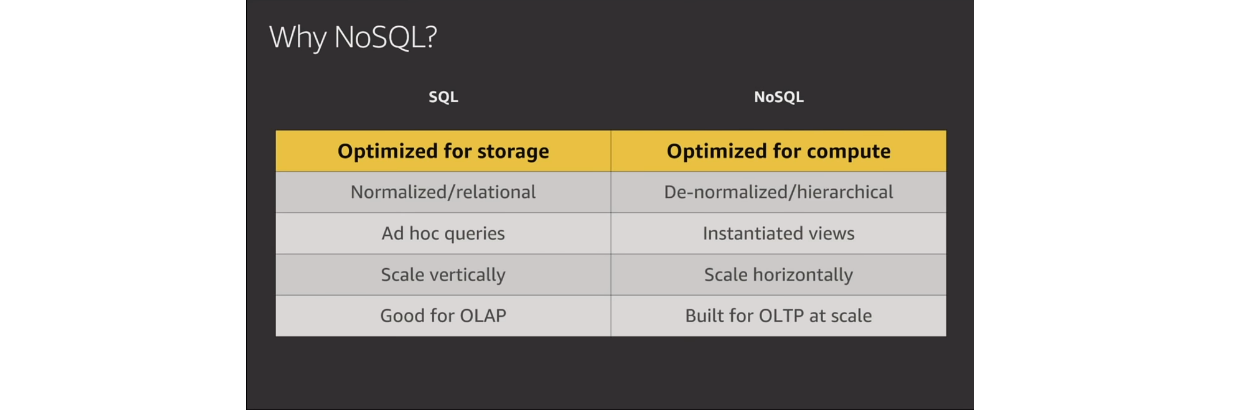
Окрім узгодженості, маємо різницю і в доступі до даних. Для бізнес-аналітика це важливий момент, зокрема, під час проведення OLAP-аналізу. Реляційна БД більше підійде для виконання складних запитів, оцінки даних з різних боків та побудови прогнозів. Хоча у бізнесі ми можемо передбачити до 80-90% шаблонів доступу, які опишуть можливі запити. Це передбачає OLTP-підхід, що відповідає нереляційній БД.
У NoSQL варто робити лише ті запити, які в принципі ефективно виконувати. Можливість запитів має бути закладена під час проєктування бази. В іншому випадку системі доведеться сканувати всю БД. Це зводить нанівець всі переваги швидкості обробки запитів.
Тож, що ми маємо: реляційні бази ідеальні для зберігання нормалізованих даних, а нереляційні — оптимальні для обчислень, особливо хмарних. Це цілком відповідає сучасним вимогам до архітектури застосунків і неабияк зручно в роботі.
Існує понад 200 NoSQL-баз п’ятнадцяти типів. Дві третини з них припадає на чотири основні категорії. Зупинюсь детальніше на кожній:
Кожен тип NoSQL має свої особливості. Я зупинюсь на Key-Value як найбільш поширеній нереляційній БД. Тим паче ця база є в одному з моїх проєктів — а саме DynamoDB. Її вибір, як і будь-якої іншої бази, складно до кінця назвати раціональним. На кінцеве рішення впливає багато факторів: від бізнес-вимог до побажань замовника. Хоча це не скасовує спроб усвідомленої оцінки проєкту.
Обравши потрібний тип БД, переходьте до проєктування. У випадку NoSQL ми обмежені у способах доступу до даних. Тому потрібно налаштувати модель під часті та важливі запити. Для цього детально розберіть Use Cases та всі вимоги до продукту. Так ви зможете правильно оцінити, як саме подивитися на ваші дані. Це і стане основою майбутньої структури даних.
У наступній частині статті я розповім, як змоделювати базу даних на прикладі DynamoDB. Тож слідкуйте за оновленнями 😉
Коротко про українську IT-сферу у 2024 році Це коли на одну вакансію Middle розробника по…
Формування криптовалютної галузі в Україні почалося ще у 2014 – саме тоді з'явилися перші стартапи,…
Автор цього блогу — Python-девелопер Сергій Солдатов, який вирішив створити досить унікальний продукт. І це…
Думки шукачів діляться на: «так, однозначно» і «ні, не вартує, я все і так про…
Синдром студента — це форма прокрастинації, яка полягає в тому, що людина, якій дали завдання,…
Git — це найпопулярніша CVS прямо зараз, яка дозволяє відстежувати історію розробки і спільно працювати.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}