


У попередній частині я розповідав найголовніше, що варто знати бізнес-аналітику про нереляційні бази даних. Ми вже трохи торкнулися теми проєктування БД. Тепер розберемо теорію на практиці.
Особливості DynamoDB
На проєктування бази даних впливає її різновид. Для прикладу візьмемо DynamoDB. Ця база розбита на partitions — осередки, які можна назвати вузлами. Кожен вузол — це SSD об’ємом 200 ГБ. Однак таких вузлів безліч. Усі дані певним чином розподіляються між ними. І тут DynamoDB дає кілька переваг:
- пропускна здатність до 7 мільйонів транзакцій за секунду (за ідеальних умов);
- Eventually Consistency на рівні 10 мс (знову ж таки за умови ідеальної організації даних);
- автоматична реплікація даних;
- автоматичне масштабування БД.
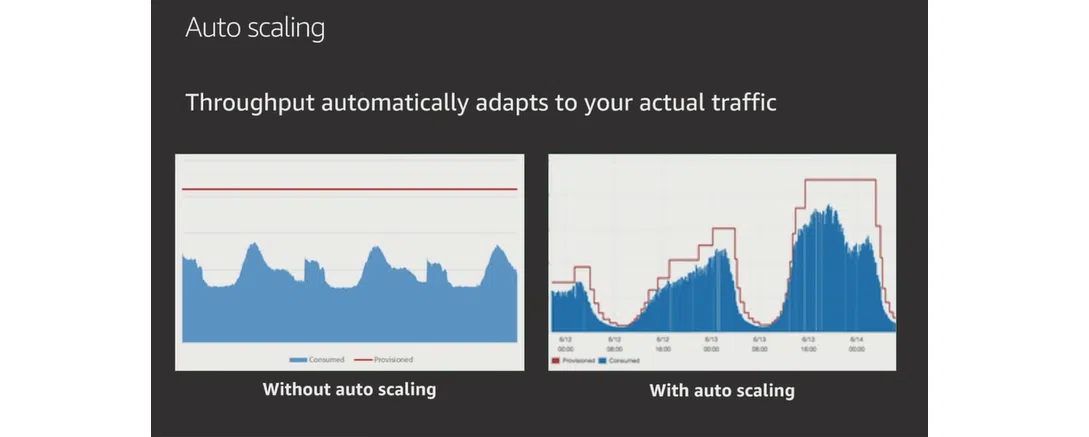
DynamoDB вирізняє оптимізована схема роботи при пікових навантаженнях. У SQL-моделі треба закласти високі обчислювальні потужності вздовж червоної лінії на графіку нижче. Хоча на практиці вони можуть і не використовуватися. DynamoDB має більш гнучкі можливості. База обирає потужності по кривій, що відповідає реальному навантаженню «тут і зараз». Це заощаджує ресурси, зменшує витрати на БД та є ідеальним підходом для проєктів з обчисленнями.
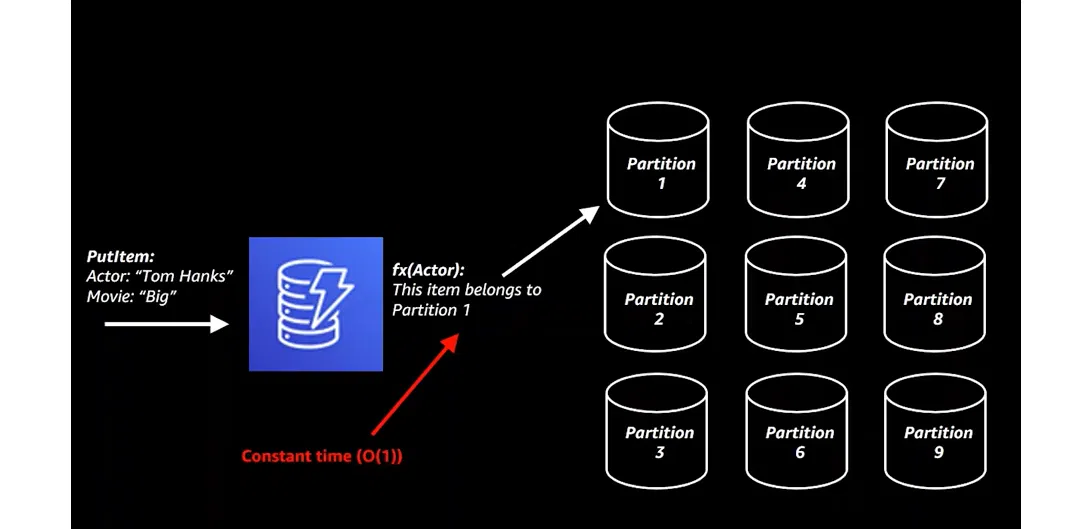
Принцип роботи DynamoDB досить простий: спочатку виконується хешування даних або розбиття на осередки. Така операція відбувається за принципом Constant Time, тобто без затримки за будь-якої кількості запитів. При зверненні до БД запит хешується з певного ключа. Так база розуміє, в якому конкретно осередку шукати необхідні дані.
 Перші кроки в моделюванні такі самі. Насамперед треба побудувати дата-модель, створити перелік сутностей і задати зв’язки між ними: один до одного, один до багатьох, багато до багатьох. Відмінності з’являються після побудови дата-моделі. На цій стадії слід описати згадані шаблони доступу.
Перші кроки в моделюванні такі самі. Насамперед треба побудувати дата-модель, створити перелік сутностей і задати зв’язки між ними: один до одного, один до багатьох, багато до багатьох. Відмінності з’являються після побудови дата-моделі. На цій стадії слід описати згадані шаблони доступу.
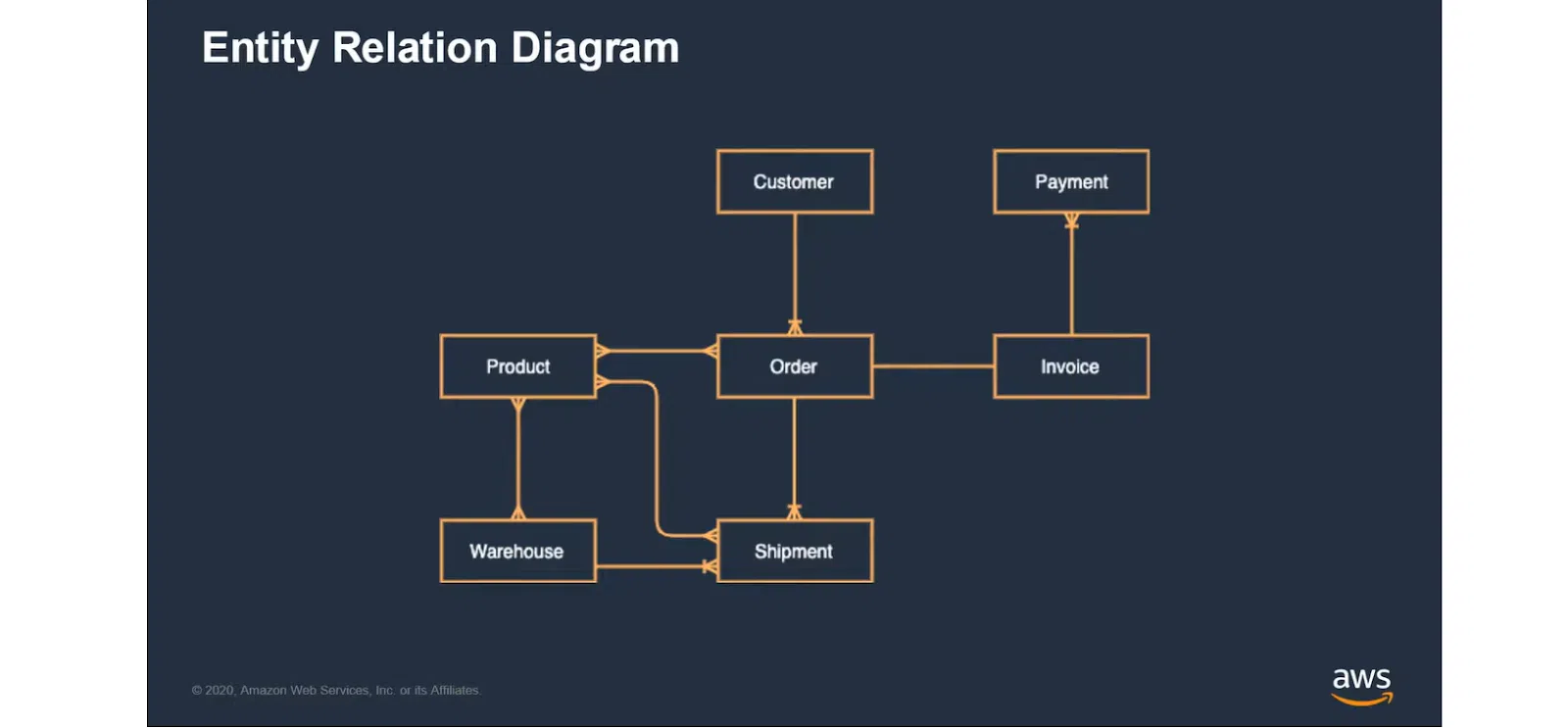
Для прикладу візьмемо інтернет-магазин із відомим Use Case. На ілюстрації виділено ключові сутності, якими йтиме проєктування моделі даних:
 Це призводить до появи звичної SQL моделі даних. Тут позначені різні типи зв’язків між сутностями.
Це призводить до появи звичної SQL моделі даних. Тут позначені різні типи зв’язків між сутностями.
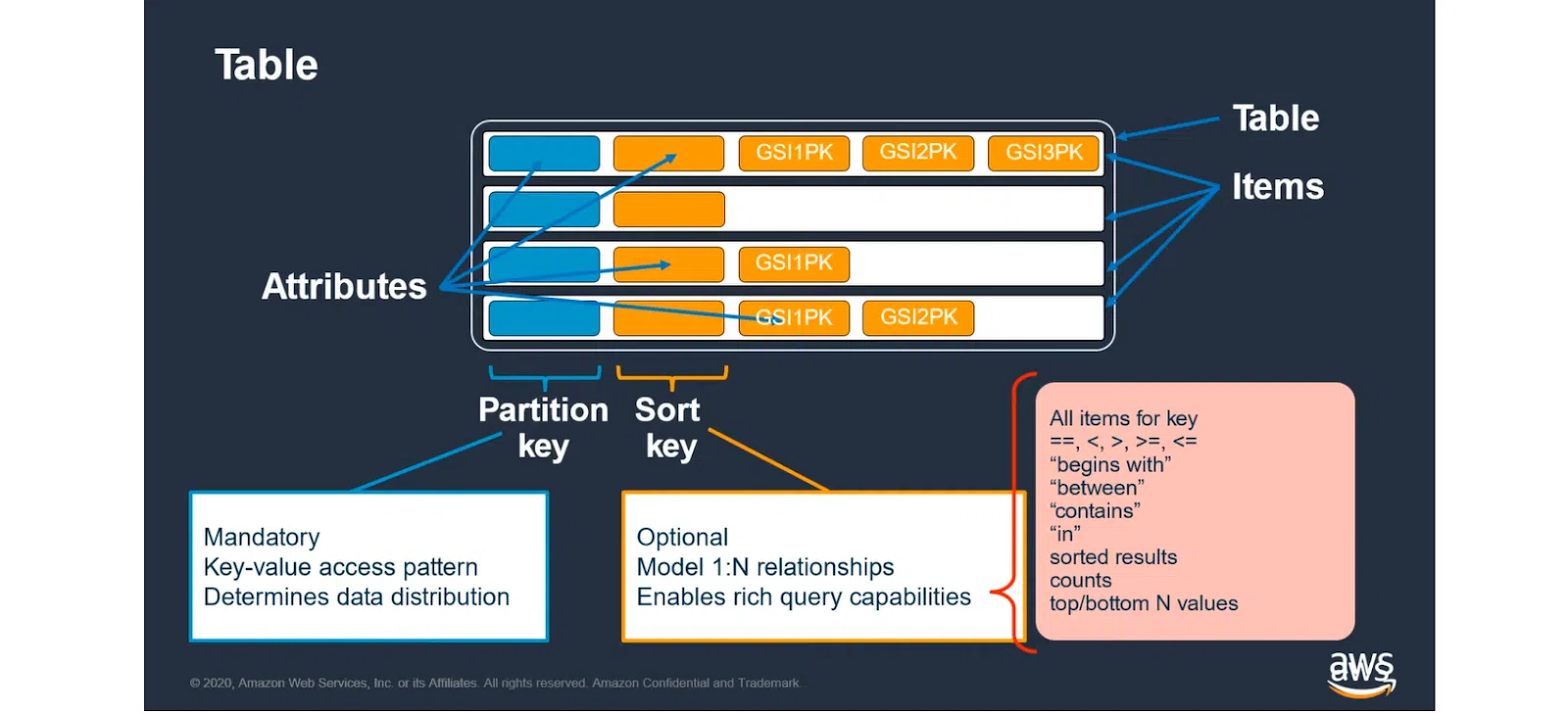
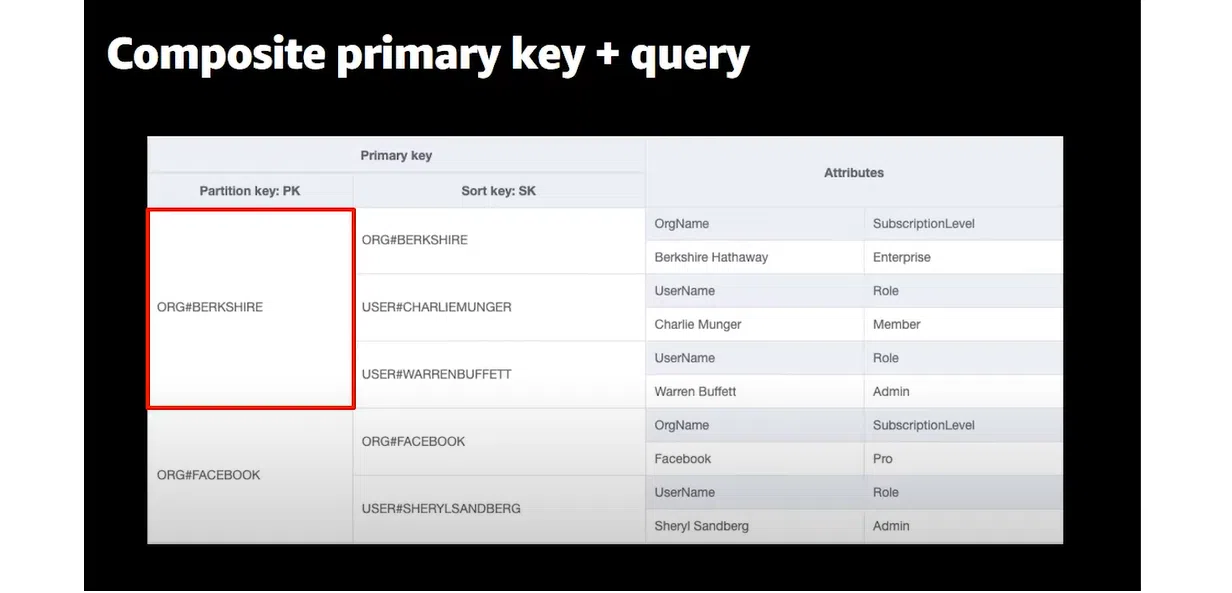
Однак далі все змінюється. Нижче можете побачити структуру DynamoDB (приблизно так влаштовані всі Key-Value). Це однотаблична БД, яка має Partition Key та Sort Key. Перший ключ обов’язковий — по ньому виконується пошук конкретного запису. Другий — опційний. Він надає додаткові можливості та дозволяє ставити складні запити.

Шаблони доступу до DynamoDB
Для роботи з таблицею необхідно прописати шаблони доступу. Наприклад, це може бути Get customer for given customerId або більш складний: Get all shipments for a given warehouseId. Потім за кожним запитом слід визначити, куди звертається БД і за якими ключами (у нашому випадку вони порожні).
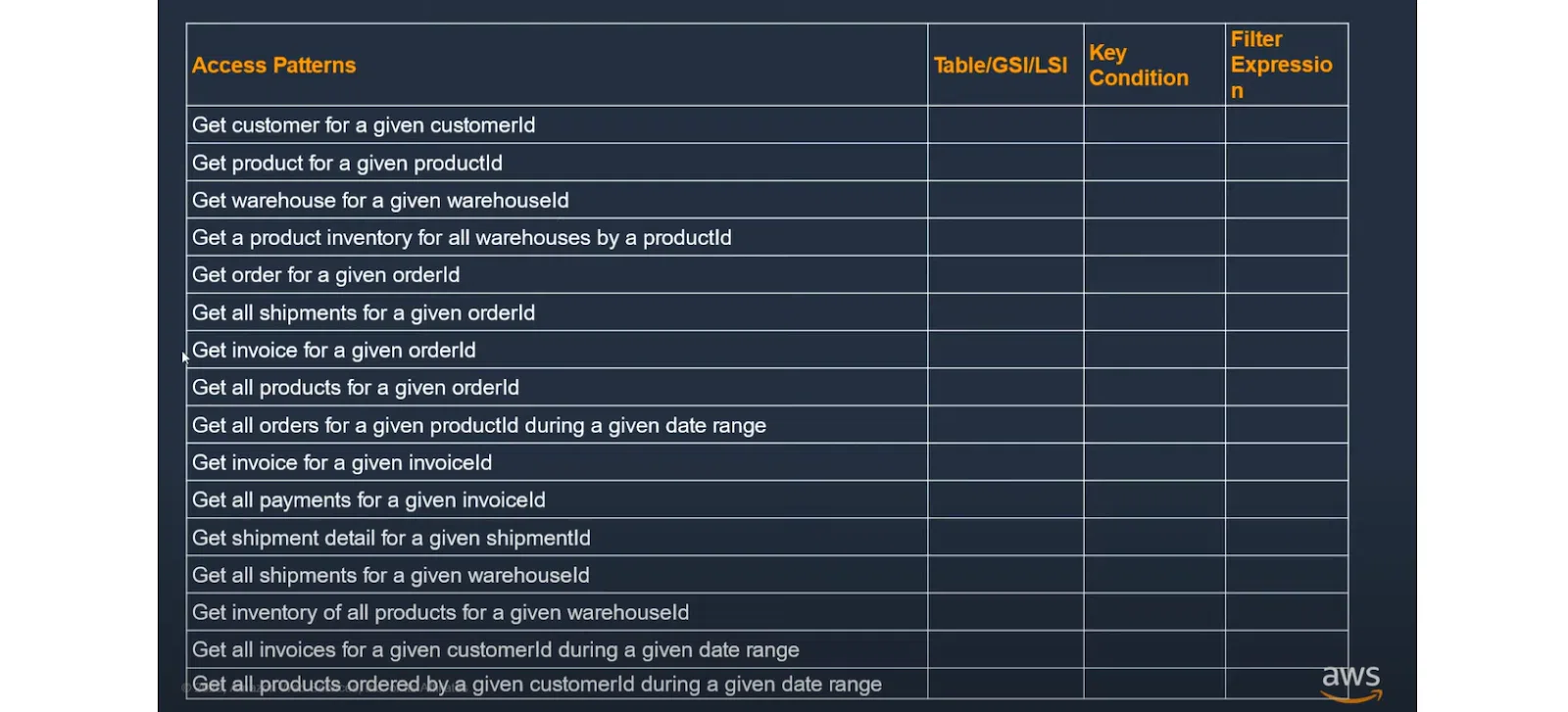
У випадку SQL-схеми ми нормалізуємо дані та можемо крутити їх за допомогою SQL-запитів. Із NoSQL варто йти іншим шляхом. Розглянемо приклад нижче. Беремо наведений запит з основної таблиці (про позначку GSI розповім згодом). Маємо Partition Key у вигляді productId. У якості Sort Key виступає другий ключ Id складу. В результаті можна виконати запит щодо конкретного продукту та дізнатися, на яких складах він наразі доступний:
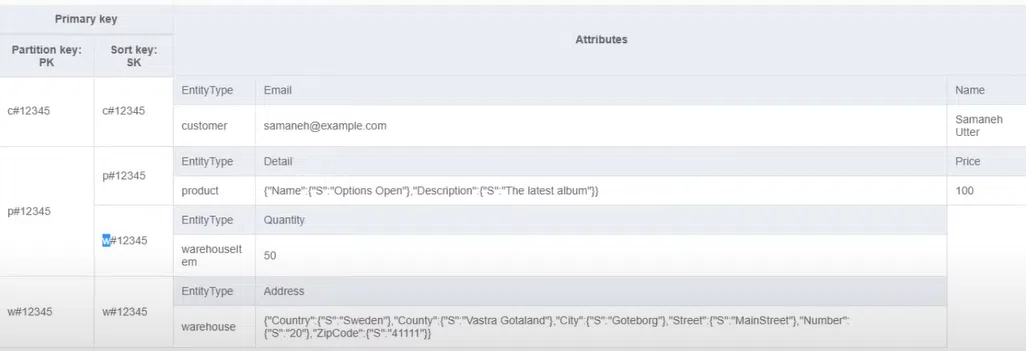
 Для роботи з даними можна використовувати Workbench від AWS. Цей NoSQL-інструмент дає наочне уявлення про всі дані та показує, від якої сутності беруться атрибути. Атрибутами може бути ім’я, пошта, адреса, кількість, вартість тощо. Workbench — це, по суті, UI для моделювання бази даних. За бажання можете все згорнути в об’єкт JSON. Та коли інформація візуалізована, працювати з нею значно зручніше.
Для роботи з даними можна використовувати Workbench від AWS. Цей NoSQL-інструмент дає наочне уявлення про всі дані та показує, від якої сутності беруться атрибути. Атрибутами може бути ім’я, пошта, адреса, кількість, вартість тощо. Workbench — це, по суті, UI для моделювання бази даних. За бажання можете все згорнути в об’єкт JSON. Та коли інформація візуалізована, працювати з нею значно зручніше.
В інтерфейсі Workbench можна бачити кожен Partition Key та пов’язані Sort Keys, які не структуровані за атрибутами. На ілюстрації у першого рядку атрибутом є customer, а в другому рядку — product. Нормалізація даних непотрібна. Достатньо написати атрибути зі значеннями. Їх можна додавати та прибирати по одному рядку або по декілька одразу:
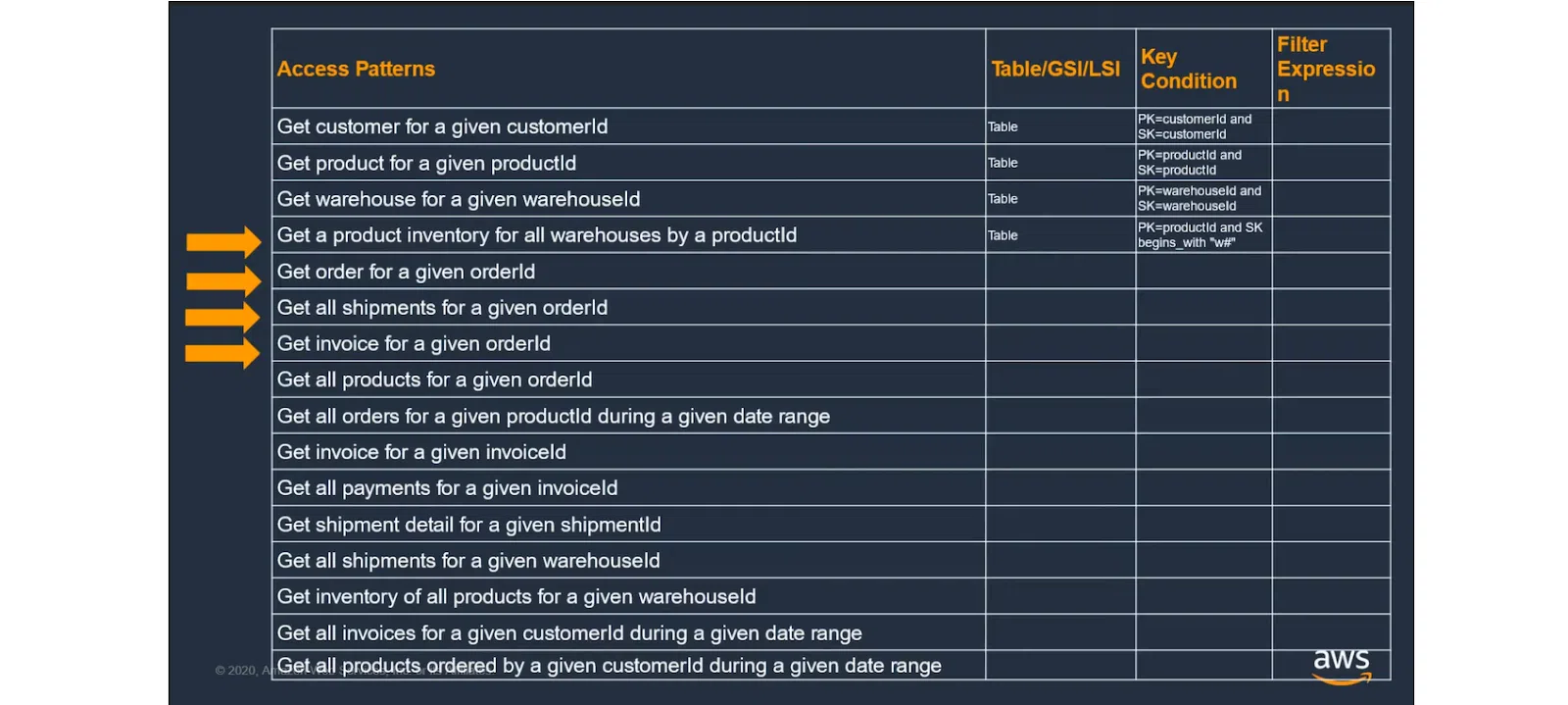
 У разі використання більш складних шаблонів доступу можуть виникнути проблеми. Варто враховувати більше параметрів. Однак Partition Key та Sort Key можуть не покрити всі ситуації, оскільки вони вибираються на всю таблицю. Тому для доступу та виконання певного запиту може не вистачити ключів.
У разі використання більш складних шаблонів доступу можуть виникнути проблеми. Варто враховувати більше параметрів. Однак Partition Key та Sort Key можуть не покрити всі ситуації, оскільки вони вибираються на всю таблицю. Тому для доступу та виконання певного запиту може не вистачити ключів.
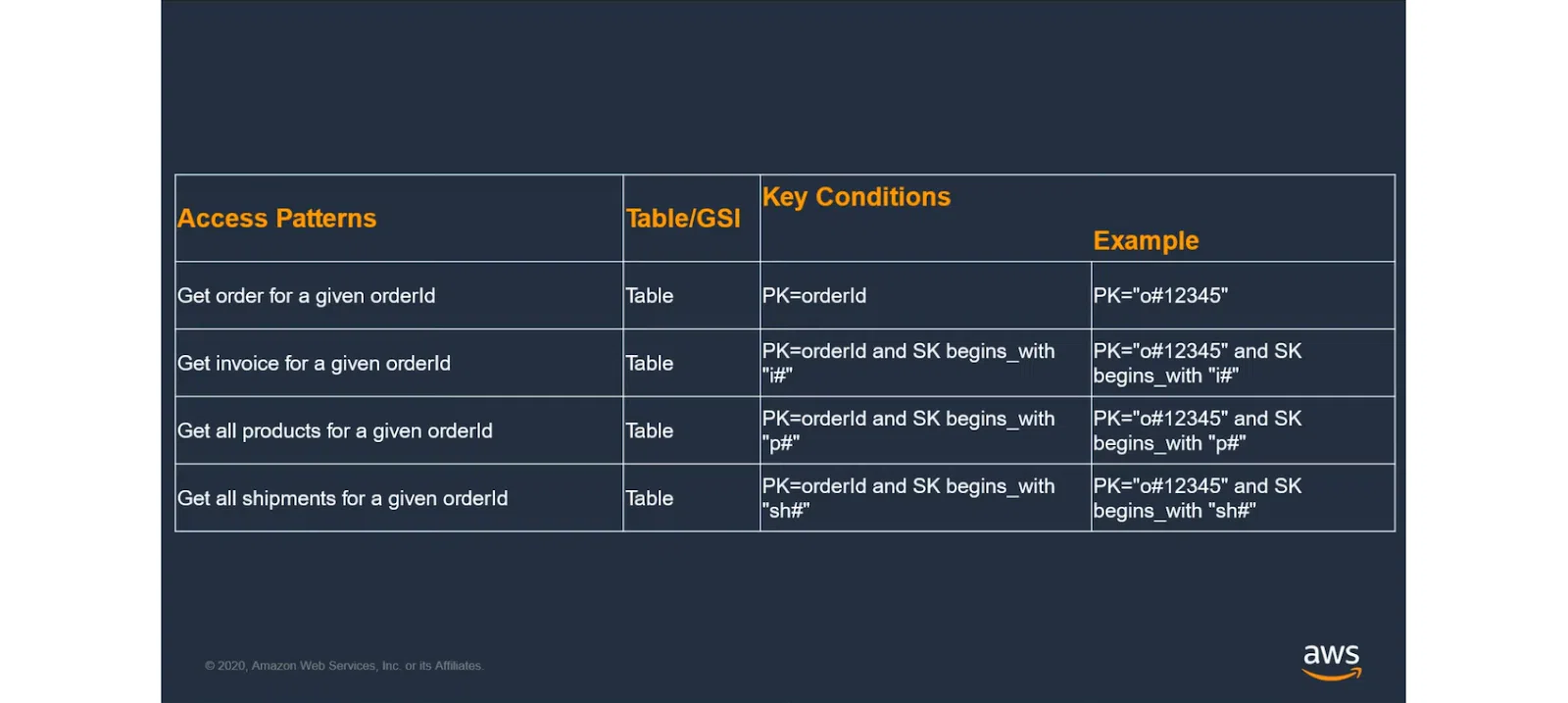
 Звичайно, завжди можна пограти зі стратегіями Partition Key та Sort Key. Це дозволяє вирішити до 80-90% бізнес-завдань. Та для решти ситуацій доведеться шукати складніший підхід.
Звичайно, завжди можна пограти зі стратегіями Partition Key та Sort Key. Це дозволяє вирішити до 80-90% бізнес-завдань. Та для решти ситуацій доведеться шукати складніший підхід.
Global Search Index
Впоратися з такою проблемою в DynamoDB допоможе Global Search Index. У цій ситуації не вистачає закладених Partition Key та Sort Key. Припустимо, ми хочемо не просто дивитися дані productId, а й сортувати їх за датою надходження товару. Такого Sort Key у нас передбачено. Тож потрібно створити Global Search Index — фактично репліку таблиці. У Partition Key буде productId, а Sort Key — та сама дата. У цьому випадку GSI виступає посередником, як JOIN. Таким чином можна створити до 20 GSI, аби покрити всі можливі шаблони.
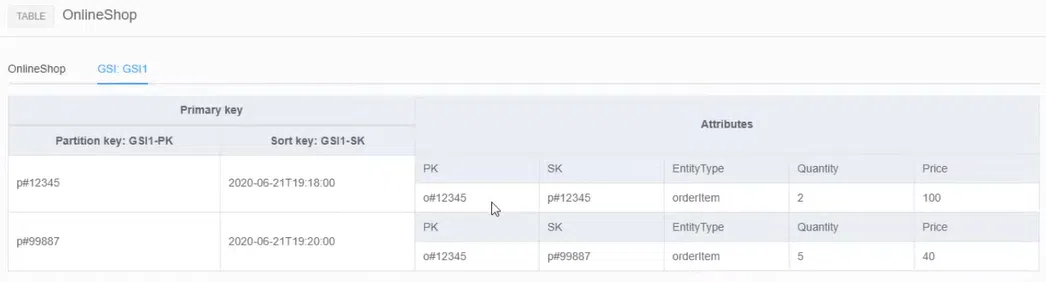

Зауважу, що з GSI є кілька проблем. По-перше, під час операції запису доводиться оновлювати основну таблицю і всі створені репліки. По-друге, на дотримання узгодженості даних потрібен час. Не можна просто оновити GSI. Спочатку йде апдейт основної таблиці, лише потім — черга реплік. У результаті лаг Eventually Consistency збільшується. Передбачити його неможливо, все перевіряється на практиці. Тому пам’ятайте про цей ризик.
Уникайте GSI, якщо неузгодженість даних може призвести до серйозних помилок у проєкті. Однак ви можете продумати й оцінити критичні сценарії. Наприклад, у системах букінгу одночасне бронювання двох номерів не є критичним. Зазвичай готелі закладають цю можливість і тримають резерв. Це явно простіше, ніж затискати та уповільнювати базу даних у межах SQL-моделі.
Реалізація стратегії «один до багатьох»
На ілюстрації зображений варіант із комплексним атрибутом. Тут зібрано багато PaymentMethod за одним акаунтом. Для реалізації такого зв’язку достатньо PaymentMethod написати в один атрибут за кожним айтемом. Шляхом цього кожен запит виконуватиметься точно та швидко. Та якщо шаблони доступу припускають, що з якогось PaymentMethod буде запит Query, то цей прийом не вдасться.
 Найпростіший спосіб реалізації «один до багатьох» — це дублювання. Припустимо, у нас є письменник, його книга та атрибут із днем народження автора. Ця дата не стосується безпосередньо книги, тому це значення доводиться повторювати в кожній книзі. Але ж день народження не змінюється, тому атрибут можна дублювати:
Найпростіший спосіб реалізації «один до багатьох» — це дублювання. Припустимо, у нас є письменник, його книга та атрибут із днем народження автора. Ця дата не стосується безпосередньо книги, тому це значення доводиться повторювати в кожній книзі. Але ж день народження не змінюється, тому атрибут можна дублювати:

Пам’ятайте: вартість зберігання даних низька, але ціна обробки значно вища. Тож дублювання має сенс лише у багатьох записах або у випадку повторюваних даних, які не будуть часто оновлюватися.
Щодо композитного Partition Key. Ви можете склеїти його та зробити складним. Це дозволить реалізувати своєрідний преджоінт та створити більш складні запити:
 Мій досвід використання DynamoDB
Мій досвід використання DynamoDB
В одному з проєктів я міг використовувати лише цю базу даних. Усе через специфічні вимоги клієнта до архітектури. Спочатку спілкувалися з БД через AppSync. Цей GraphQL-сервіс для відпрацювання мови SQL-запитів призначений для роботи з реляційними базами даних. Хоча він підходить і для DynamoDB, оскільки в нього можна завантажити звичну модель спілкування з БД.
Однак на етапі тестування у нас виникли проблеми. У проєкті було замало даних. Під час виконання застосунком певної вибірки запитів з’явилися затримки. Помилка очевидна: не варто спілкуватися з DynamoDB як із реляційною базою даних. Система для виконання запиту просто сканувала всю базу, адже не було ні жодного шаблону, ні ключа. Ми отримували відповідь, але втрати часу виявилися надто серйозними. Довелося все переналаштовувати.
Не думайте, що NoSQL колись замінить SQL. Ці підходи доповнюють один одного, причому часто у межах одного продукту. У тому ж Instagram використовується декілька реляційних і нереляційних баз даних. Усе залежить від того, які завдання виконує БД. Перш ніж обирати один із варіантів, подумайте, яка мета перед вами стоїть.
Цей матеріал – не редакційний, це – особиста думка його автора. Редакція може не поділяти цю думку.









Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: