


Прежде чем начать писать защищенные веб-приложения, нужно избавиться от иллюзий.
Иллюзия того, что ваша программа манипулирует своими данными, очень сильна. Но это иллюзия: данные контролируют вашу программу.
Как утверждает LangSec:
- Любые входящие данные (input) это программа
- Информация — это инструкции
- Все данные представляют собой поток токенов практически произвольной сложности, и этот поток токенов представляет собой последовательность инструкций для синтаксического анализатора своего языка
Зачем нам вообще внедрять какие-то практики и изменять подходы к разработке ПО, особенно если мы разрабатываем open-source-проект и наш исходный код хранится только в приватном репозитории. Как насчет старого доброго Security through obscurity? Здесь на помощь к нам приходят следствия из принципа Керкгоффса-Шеннона и закона Мерфи:
- если уязвимость может быть обнаружена, она будет обнаружена;
- если уязвимость может быть проэксплуатирована, она будет проэксплуатирована с максимальным уроном;
- если несколько уязвимостей могут быть проэксплуатированы, они будут проэксплуатированы в комбинации приводящей к максимальному урону.
Теперь, когда нам ясно, что просто оставить как было и ничего не делать — не вариант, перейдем к своду правил разработки защищенных приложений, известному как AppSec Manifesto.
Для того, чтобы написать абсолютно защищенное приложение, достаточно воспользоваться лишь первым (нулевым 🙂 ) правилом:
RULE #0
Absolute Zero
- Нет кода => Нет проблем
- Нет контролируемого пользователем ввода => Нет векторов атаки
- Нет sink’а => Нет уязвимости
Разберем по пунктам
Нет кода => Нет проблем
Действительно, программа, состоящая из нуля строчек кода, абсолютно неуязвима и… абсолютно бесполезна. Это недостижимый крайний случай, к которому нужно стремиться. В реальных проектах это означает, что нужно минимизировать объем кода и сложность пользовательского ввода, уменьшая тем самым поверхность атаки. Не все строчки кода одинаково полезны, существует целое семейство типов кода, который нужно удалять:
Всегда удаляйте obsolete, dead, unreachable, unreferenced code. Вот что это такое:
Obsolete code (устаревший код)
Код, который мог быть полезен в прошлом, но больше не используется, например, код для использования устаревшего протокола. Также может называться мертвым кодом (dead code).
Dead code (мертвый код)
Код, который выполняется, но является избыточным, либо его результаты никогда не использовались, либо он ничего не добавляет к остальной части программы. Снижает производительность процессора.
<?php
function(){
...
// мертвый код, поскольку он вычислен, но не сохраняется и не используется где-либо
$foo + $bar;
}
Unreachable code (недостижимый код)
Код, который никогда не будет выполнен независимо от логики.
<?php
function(){
return 'foobar';
// следующая строка недостижима
$a = $b + 1;
}
Unreferenced code (без ссылки)
Переменная (метод, функция и т. д.), которая определена, но никогда не используется.
<?php
class Useless {
private function foo()
{
// some code goes here
}
}
К счастью, unreachable, unreferenced и dead code можно найти с помощью статического анализа (PHPStan, Phan, Psalm). Obsolete (dead) code можно найти с помощью динамического анализа и концепции tombstone.
Приведенные типы кода не приносят пользы, а лишь добавляют сложности и вводят в заблуждение программиста. К тому же, «мертвый код» может и «ожить»!
Rise of dead code 🙂
Летом 2012 года Knight Capital Group вызвала серьезный сбой на фондовом рынке и понесла убытки в размере более $400 млн, когда неудачное развертывание программного обеспечения привело к выполнению кода обработки мертвых заказов. Код не тестировался много лет и привел к потоку ордеров, поступающих на рынок, которые нельзя было отменить.
Нет контролируемого пользователем ввода => Нет векторов атаки
В тех сценариях, когда возможно отказаться от пользовательского ввода, нужно всегда пользоваться такой возможностью. К примеру, у вас есть форма для загрузки файлов:
<form name="upload" action="upload.php" method="POST" enctype="multipart/form-data">
Select image to upload: <input type="file" name="image">
<input type="submit" name="upload" value="upload">
</form>
И соответствующий обработчик на бэкенде:
<?php
$uploaddir = 'uploads/';
$uploadfile = $uploaddir . $_FILES['image']['name'];
if (move_uploaded_file($_FILES['image']['tmp_name'], $uploadfile)) {
echo "Image successfully uploaded.";
} else {
echo "Image uploading failed.";
}
В данном случае пользователь контролирует имя файла $_FILES[‘image’][‘name’], и в качестве митигации атаки типа Path Traversal мы можем воспользоваться функцией basename:
<?php
$uploaddir = 'uploads/';
$uploadfile = $uploaddir . basename($_FILES['image']['name']);
if (move_uploaded_file($_FILES['image']['tmp_name'], $uploadfile)) {
echo "Image successfully uploaded.";
} else {
echo "Image uploading failed.";
}
А можем сделать все еще проще и безопаснее, отказавшись от пользовательского ввода:
<?php
$uploaddir = 'uploads/';
$uploadfile = $uploaddir . uniqid();
if (move_uploaded_file($_FILES['image']['tmp_name'], $uploadfile)) {
echo "Image successfully uploaded.";
} else {
echo "Image uploading failed.";
}
Когда нет возможности отказаться от пользовательского ввода, нужно стараться использовать как можно менее мощный язык ввода (не забываем, что входные данные или пользовательский ввод — это язык программирования).
Все формальные языки можно объединить в иерархию согласно их сложности, известную как иерархия Хомского.
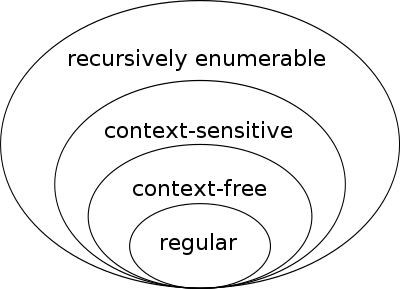
Иерархия Хомского
Нужно стремиться к тому, чтобы пользовательский ввод был regular или context-free.
Все, что делает функция basename в примере выше, по сути, лишь приводит бесконечно сложный ввод к regular.
Сюда же подпадают белый и черный списки, а также частный случай белого списка — приведение к int или bool (да-да, все проблемы, связанные с безопасностью, из-за строк).
Нет sink’а => Нет уязвимости
В taint analysis существуют такие понятия как source и sink.
Source — программная точка, которая читает внешний ресурс (вводимые пользователем или любые другие данные, которыми может манипулировать потенциальный злоумышленник):
- $_GET
- $_POST
- $_COOKIE
Sink — программная точка, которая пишет во внешний ресурс:
<div id="section_<?= $id ?>">
<?php
$pdo->exec("select * from users where name='" . $name . "'");
header('Location: ' . $location);
Если бы не было sink’ов то программа была бы защищена, но по сути представляла бы собой dead code.
Каждый Sink — это точка приложения вектора атаки и требует повышенного внимания разработчика
RULE #1
The Lord of the Sinks
Применяйте контекстно-зависимое экранирование на границе контекста.
Если мы взглянем на все многообразие уязвимостей, то заметим, что большинство из них можно отнести к инъекциям, и, по сути, они имеют одну и ту же причину возникновения. Вот неполный список:
- SQL injection
- XSS
- CRLF injection
- OS Command injection
- Email Header Injection
- LDAP Injection
- XPath injection
- XXE injection
Чтобы предотвратить инъекцию, нам нужно предотвратить интерпретацию одного языка как другого. Для этих целей можно воспользоваться экранированием или кодированием (в зависимости от ситуации).
Кодирование и экранирование — это защитные методы, предназначенные для предотвращения атак путем инъекций.
Кодирование (encoding) включает в себя перевод специальных символов в другую, но эквивалентную форму, которая больше не опасна для целевого интерпретатора.
urlencode(), base64_encode(), htmlspecialchars(),
Экранирование (escaping) включает добавление специального символа перед символом / строкой, чтобы избежать неправильной интерпретации.
addslashes(), mysql_real_escape_string()
Encoding (перевод знака < в < и т.д.):
<div><?=htmlspecialchars($content);?></div>
Escaping:
<div onclick=”alert(\”hello\”)” ></div>
Выполнять экранирование нужно как можно ближе к sink. А для этого необходимо строить архитектуру приложения таким образом, чтобы точки внедрения одного языка (пользовательского ввода) в другой язык находились как можно ближе к sink.
Помните: защищенность приложения — это всегда побочный эффект правильной архитектуры. (с)
Каждому типу уязвимости соответствует свой sink, и это стоит учитывать при экранировании. Хоть запись в базу данных и является sink, но это относится к SQL injection, и не имеет смысла производить экранирование данных от XSS перед записью в базу. Хотя многие поддаются такому соблазну — экранировать один раз перед сохранением базу, а все, что мы достаем из базы, считаем безопасным. Это обычно приводит к тем же XSS, двойному экранированию и атакам типа SQL-инъекций второго рода.
Как нам понять, возможна ли в принципе инъекция независимо от типа уязвимости? Тут нам на помощь вновь придет LangSec: инъекция невозможна, если в результате лексического разбора (парсинга) любого возможного потока данных в точке sink, на каждую точку инъекции приходится не более одного токена.
Давайте рассмотрим на это на примере старой доброй SQL-инъекции.
Допустим, у нас есть скрипт с SQL-запросом:
<?php $username = 'bob'; $password = 'secret'; $query = <<<SQL SELECT * FROM users WHERE username='$username' AND password='$password' SQL;
Если мы воспользуемся SQL-парсером, доступным в качестве библиотеки на GitHub, то для части запроса WHERE мы получим:
username - colref = - operator ‘bob’ - const (1-я точка инъекции) AND - operator password - colref = - operator ‘secret’ - cosnt (2-я точка инъекции)
Как мы видим, в каждой точке инъекции у нас по одному токену. Можно сделать вывод, что атаки тут не было.
Теперь повторим то же самое, только изменив пользовательский ввод на классическую SQL injection:
<?php $username = "' OR 1=1 --"; $password = 'secret'; $query = <<<SQL SELECT * FROM users WHERE username='$username' AND password='$password' SQL;
Вновь воспользуемся парсером и посмотрим, как изменилась наша WHERE-часть:
username - colref = - operator ‘’ - const OR - operator 1 - const = operator 1 - const --' AND password='secret' - comment
Как мы видим, теперь пользовательский ввод может быть представлен уже в виде шести токенов.
RULE #2
Least Power Principle
Доступ к вычислительной мощности — это привилегия.
Выполняйте полное распознавание в самом начале и останавливайте выполнение программы, если входные данные не соответствуют правилам вашего домена.
- Парсите, а не валидируйте входные данные как можно ближе к точке входа (source)
- Не переносите вредоносные данные из источника (source) в приемник (sink)
Парсер — это программный компонент, который принимает входные данные (часто — текст) и строит структуру данных.
<?php DirectoryName::fromString($user_input);
Валидация — это процесс, который использует процедуры, часто называемые «правилами валидации», «ограничениями валидации» или «подпрограммами валидации», которые проверяют правильность, значимость и безопасность данных, вводимых в систему.
<?php $isValid = DirectoryValidator::validate($user_input);
RULE #3
Forget-me-not
Не забывайте информацию о валидности определенного ввода.
- Не используйте строки в качестве повсеместного типа данных для неструктурированных данных. Вместо этого объявляйте собственные типы, используя ValueObjects для различения различных типов данных.
- Передавайте собственные типы (ValueObjects) от источника (source) в приемник (sink).
- Используйте сырые данные ValueObject’а только внутри отдельного контекста, всегда передавайте ValueObject через границы контекстов/областей видимости.
Это необходимо для того, чтобы не приходилось снова делать валидацию здесь и там или слепо предполагать, что валидация была сделана раньше. Другими словами, это предотвращает проблему shotgun parsing.
Существует несколько слегка отличающихся определений для ValueObject. В AppSec Manifesto под ValueObject понимается концепция близкая к доменному примитиву (DDD), то есть типизированные значения, не имеющие концептуальной идентичности в вашем домене и сохраняющие инвариант от момента создания.
Пример ValueObject на PHP:
class EmailAddress
{
private $address;
public function __construct($address)
{
if (!filter_var($address, FILTER_VALIDATE_EMAIL)) {
throw new InvalidArgumentException(sprintf('"%s" is not a valid email', $address));
}
$this->address = $address;
}
public function __toString()
{
return $this->address;
}
public function equals(EmailAddress $address)
{
return strtolower((string) $this) === strtolower((string) $address);
}
}
Использование ValueObject позволяет придерживаться всех описанных в AppSec Manifesto правил:
1. Создавайте правила парсинга строк в ValueObject, учитывая RULE #0
2. Извлекайте значение из ValueObject как можно ближе к sink, непосредственно перед экранированием, следуя RULE #1
3. Создавайте ValueObject из пользовательского ввода как можно ближе к source, тем самым обеспечивая выполнение RULE #2
4. Передавайте ValueObject от source к sink вместо оригинального строкового значения, тем самым выполняя требования RULE #3
Rule #4
Declaration of Sources Rights
Все источники (source) рождаются на уровне инфраструктуры и должны рассматриваться одинаково.
Применяйте одинаковый синтаксический анализ / проверку / экранирование / санитизацию для одних и тех же данных, поступающих из разных источников.
Взглянем на гексагональную архитектуру (Hexagonal Architecture):
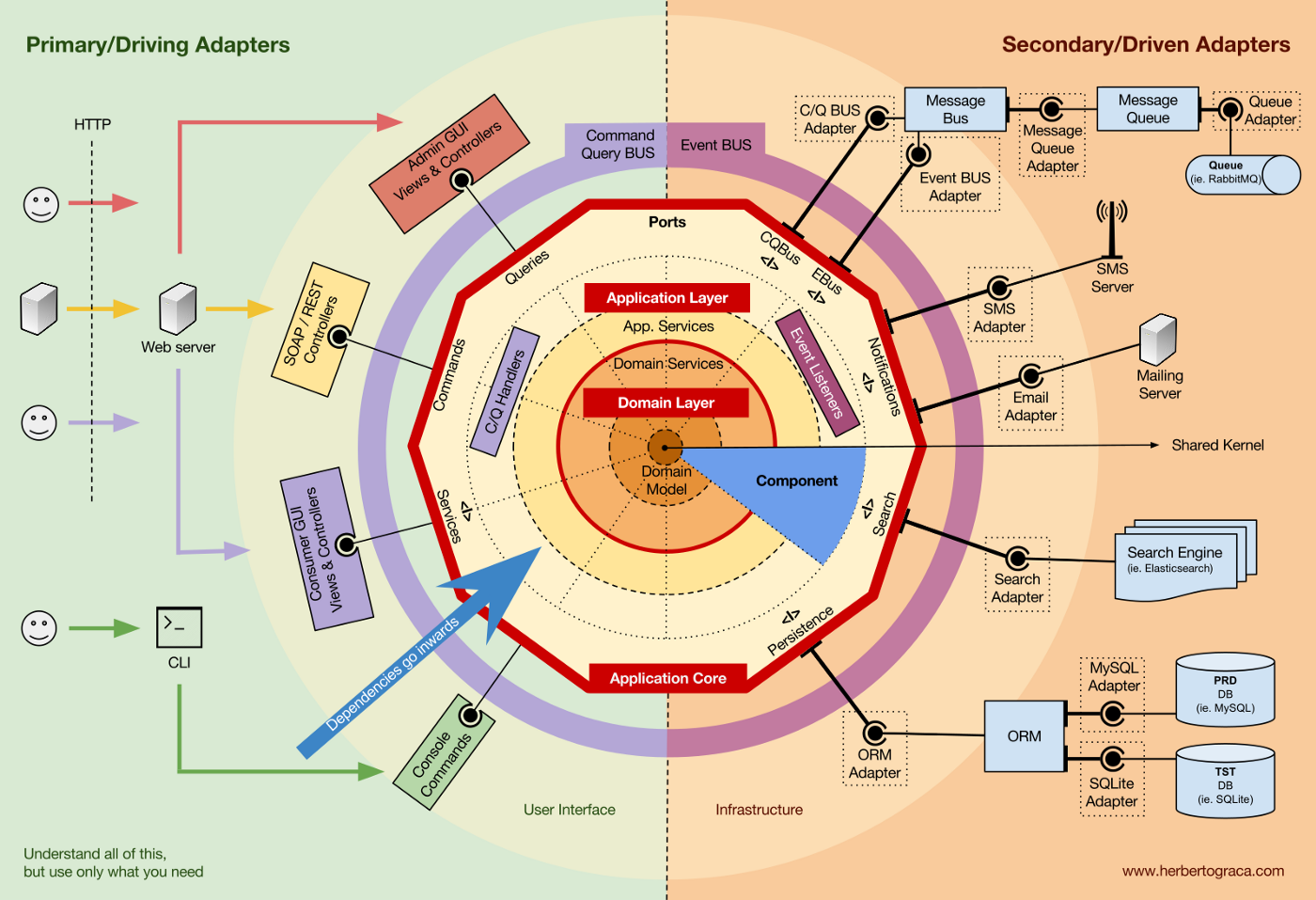
Гексагональная архитектура
Или на чистую архитектуру (Clean Architecture):
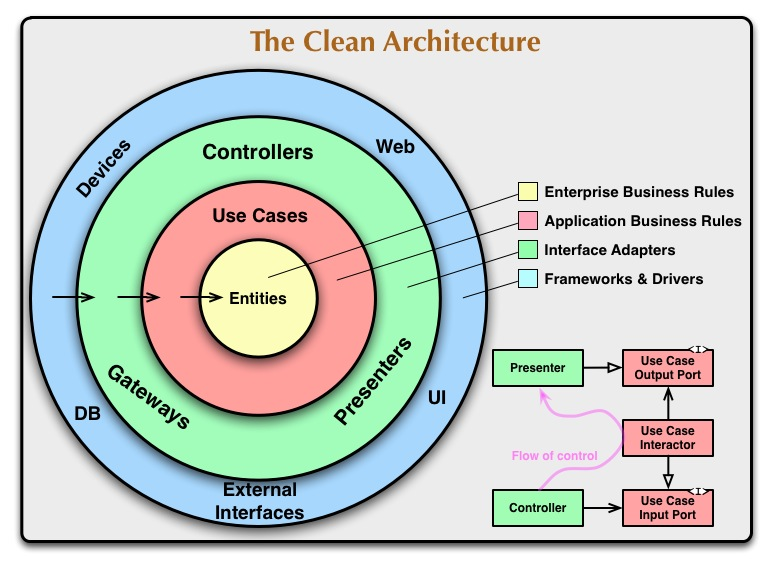
Чистая архитектура
Мы видим, что все источники (точки программы, которые считывают внешний ресурс) принадлежат одному и тому же архитектурному уровню.
Предположим, у нас есть процесс регистрации пользователя. Данные могут поступать из разных источников:
- Из интернета (пользователь отправляет регистрационную форму)
- Из CLI (php register.php -u [email protected] -p secret)
- Из вызова SOAP или REST
- и так далее
Во всех сценариях вы должны применять одни и те же правила валидации для входящих данных. В большинстве случаев вы уже делаете это, если следуете принципу DRY.
Таким образом, у вас будет служба (UseCase, Command Handler), в которой вы будете выполнять все необходимые операции, если предоставленные входные данные соответствуют соответствующим правилам. Допустим, имя пользователя должно быть адресом электронной почты длиной не более 32 символов, а пароль — строкой от восьми до 20 символов.
Но обычно люди не применяют одни и те же правила для одного и того же типа данных, когда эти данные поступают из базы данных.
Предположим, вы создали нового пользователя. Подтвердите ли вы его имя пользователя снова, когда прочтете соответствующую запись из базы данных? Если вы не используете ValueObject, я сомневаюсь, что вы это сделаете. Большинство людей полагают, что если данные были проверены перед помещением их в базу данных, они могут доверять им (рассматривать их как валидные).
Представьте себе ситуацию, когда данные были изменены в базе данных через другое приложение или администратором баз данных непосредственно в базе данных. Или бизнес-правила были изменены, например, минимальная длина пароля должна быть десять символов.
Должно ли ваше приложение выйти из строя при попытке получить запись пользователя? Если вы следуете RULE#4 и используете пользовательские типы данных (ValueObjects), то единственный возможный ответ: «Да».
Давайте также обсудим не теоретический, а реальный сценарий: одна компания хранила адреса электронной почты клиентов в базе данных MySQL, которая была настроена так, что значение для столбца, превышающее максимальную длину столбца, будет обрезано, чтобы соответствовать длине. Они поняли, что некоторые адреса были обрезаны, только после того, как получили уведомление от используемых ими почтовых служб: «Электронная почта не может быть доставлена, потому что адрес электронной почты недействителен». И это был единственный канал, по которому можно было достучаться до покупателя. Если бы они следовали RULE #4, они бы получили исключение в любом сценарии, связанном с управлением пользователями.
Справедливо сказать, что в этом примере могут быть крайние случаи: например, [email protected] валиден и [email protected] также валиден, поэтому значение остается действительным даже после обрезания и для предотвращения таких проблем вам понадобится цифровая подпись (аутентификация + целостность) как минимум для критических данных.
В Манифесте AppSec есть подсказка, о которой следует упомянуть:
Quod licet Iovi, non licet bovi
Выбрасывайте исключения (fail hard) для интерактивного ввода, придерживайтесь graceful degradation для неинтерактивного.
Хотя вы должны применять одни и те же правила проверки к одному и тому же пользовательскому вводу независимо от источника, вы можете по-разному реагировать на нарушения правил.
Вернемся к примеру с регистрацией.
Если у вас есть форма на вашем веб-сайте и вы проверяете несколько полей, ничего страшного, если вы нарушаете RULE #2 и проверяете все поля вместо того, чтобы генерировать исключение при первой ошибке, чтобы предоставить пользователю лучший UX.
Если это вызов API, то, вероятно, лучшим вариантом будет fail hard.
Оба случая являются интерактивным вводом — «автор» данных получает ответ (сообщение об ошибке), а в случае неудачи мы можем «попросить» пользователя исправить его ввод и повторно отправить.
Но что, если у нас есть страница со списком адресов электронной почты пользователей в приложении и один или несколько из них нарушают правила валидации? Это неинтерактивный ввод, и спрашивать не у кого. А как отреагировать на такую ситуацию — решать вам. ERROR 500?
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: