


У наших пользователей — терабайты данных аналитики, выгрузка которых в какой-то момент начала перегружать наши серверы. Помимо отрицательного пользовательского опыта из-за плохой работы продукта, мы получали всплески нагрузки, что могло в любой момент привести к еще большим проблемам. Решением стал сервис Amazon SQS.
Проблема
Наша компания IO Technologies развивает сервис аналитики для цифровых медиа, блогов и маркетинговых агентств. Пользователи могут получать в нем отчеты по различным показателям — например, размеру аудитории или ее вовлеченности в отдельные материалы на сайте — за выбранный период времени.
Проблема была в том, что пользователи, которые хотели получить отчет за год или больше — а это может быть около 300 млн записей, — либо вовсе не получали данные, потому что мы не могли дать им такой возможности, либо ждали их загрузки до 15 минут, теряя терпение и доверие к сервису.
Есть проекты, у которых терабайты данных, и при выгрузке за большой период серверу нужно больше времени. Иногда это время загрузки переступает черту таймаута сервера, и вместо отчета пользователь видит просто ошибку, причем после долгого ожидания.
Также дашбордами могут пользоваться несколько пользователей, которые могут запрашивать большие объемы данных одновременно. А это означает повышенную нагрузку на диск и CPU: когда сервер доходит до пиковой нагрузки, то начинает тормозить, и это влияет на все проекты на этом кластере. Проще говоря: проекты начинают медленнее работать.
Проблема была неизбежной: при обработке большого количества данных нужно больше серверного времени, а это всегда упирается в мощности железа и другие факторы, например, оптимальность распределения запросов.
Поиск решения
Мы рассматривали разные возможности решения проблемы. Можно было сделать новую группировку данных, например помесячно (сейчас у нас данные группируются по дням), но это, по сути, означало бы, что пользователи стали бы получать менее глубокую аналитику.
Другая возможность — увеличить мощности сервера, например перейдя на использование SSD-накопителей. Это хороший вариант, так как он требует минимальных изменений продукта, но дорогостоящий — наши затраты могли бы вырасти в десять раз.
Возможно было и самописное решение, которое использовало бы файлы как элементы очереди. Но его минусы — это отсутствие масштабирования и невозможность контейнеризации, а также большие затраты на разработку и сложность поддержки.
Еще одним вариантом было использование Gearman. Более подробно об этом можно почитать здесь.
Плюсы этого решения: быстрое внедрение и надежность.
Минусы: отсутствие управления временем и видимости сообщений. Кроме того, это решение не персистентное.
В итоге мы нашли вариант, который позволил нам взять под контроль проблемное место в самом продукте. Им стал механизм отложенных запросов через Amazon Simple Queue Service (SQS).
Amazon SQS — это простой сервис, который принимает очереди сообщений для хранения. Он гарантирует, что сообщения будут доставлены как минимум один раз, но не гарантирует, что сообщения будут доставлены в том порядке, в котором были отправлены.
Для наших нужд этот сервис идеально подходит, так как он прост в использовании, по нему есть хорошая документация, а вся логика хранится на серверах Amazon, что немного разгружает нашу систему.
Минусы тоже есть — это сама по себе зависимость от сервиса Amazon. Кроме того, при больших объемах сообщений это решение требует дополнительных затрат (сейчас идет бесплатно до 1 000 000 сообщений в месяц).
Что делали
По ссылке можно ознакомиться с примером нашей работы с SQS API.
Чтобы построить для пользователя полноценный дашборд с данными и аналитикой, нам нужно несколько запросов, например: фильтры, общая статистика, отчет по статьям, отчет по категориям и т.д. Все запросы делаются отдельно, их вариации могут быть произвольными.
Для решения мы добавили в код новую сущность query. Она содержит в себе список эндпоинтов с параметрами, которые должны быть выполнены.
Вот для примера псевдоструктура сущности query:
{
"queryId": "random_hash",
"status": "new",
"is_favorite": false,
"endpoints": [
{
"path": "/filters",
"params": {
"period": {
"name": "year"
}
},
"result": null
},
{
"path": "/summary",
"params": {
"period": {
"name": "year"
}
},
"result": null
},
{
"path": "/articles",
"params": {
"period": {
"name": "year"
},
"offset": 0,
"limit": 100
},
"result": null
}
]
}
После того, как мы сформировали запрос, мы берем его идентификатор queryId и отправляем в очередь Amazon SQS, при этом обновляя его статус на in_queue. Такое решение мы выбрали для уменьшения передаваемого трафика в очередях, а также из-за того, что сообщения в очередях могут потеряться, — как у нас, так и на стороне сервиса, который предоставляет нам эти возможности.
Затем происходит следующее:
- внутренние процессы (воркеры) поочередно считывают сообщения, которые приходят от Amazon SQS;
- берут сущность
queryпо идентификаторуqueryId, проверяют и обновляют статус наprocessing; - по очереди делают запросы на инстанс нашего приложения.
Ответы мы сохраняем в нашей сущности query и после всех операций переводим статус в processed. Отправляем запрос на закрытие сообщения в Amazon SQS и приступаем к такой же итерации для следующего сообщения в очереди.
На выходе у нас есть полностью обработанный отложенный запрос с такой структурой:
{
"queryId": "random_hash",
"status": "processed",
"is_favorite": false,
"endpoints": [
{
"path": "/filters",
"params": {
"period": {
"name": "year"
}
},
"result": {
"devices": {
"desktop": 4000,
"smart": 900,
"tablet": 100
}
}
},
{
"path": "/summary",
"params": {
"period": {
"name": "year"
}
},
"result": {
"views": 5000,
"sessions": 2500
}
},
{
"path": "/articles",
"params": {
"period": {
"name": "year"
},
"offset": 0,
"limit": 100
},
"result": {
"list": [
{
"url": "/article-example1.html",
"domain": "www.example.com",
"views": 3000,
"sessions": 1500
},
{
"url": "/article-example2.html",
"domain": "www.example.com",
"views": 2000,
"sessions": 1000
}
]
}
}
]
}
По этой структуре мы показываем пользователю дашборд с обработанными данными. Построение такого дашборда происходит за секунду.
Результат
В результате решения проблемы мы выделили работу с отчетами за большие периоды времени в отдельный функционал. Заодно это позволило добавить пару новых полезных функций для пользователей, а именно — историю запросов и список сохраненных запросов.
Помимо этого, мы добавили лимит максимального количества параллельных запросов для одного пользователя. Это позволило нам не забивать очередь запросов, а также нормировать нагрузку на серверы.
После внедрения решения мы смогли контролировать
- количество запросов;
- запросы, которые отпадали по таймаутам.
Это повлияло на распределение нагрузки: оно стало более плавным, отпали случаи, когда пользователи не получали необходимые данные.
И чтобы завершить историю — вот графики использования CPU на нескольких нодах за одну из недавних недель:
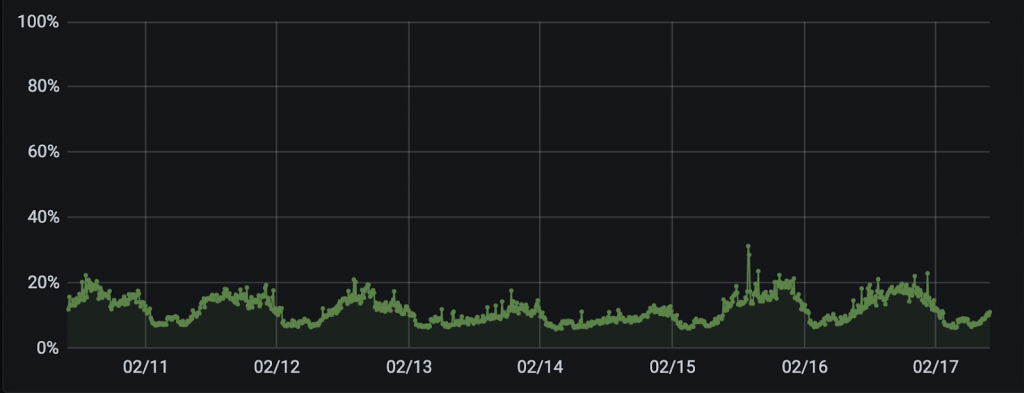
График 1. Источник: IO Technologies
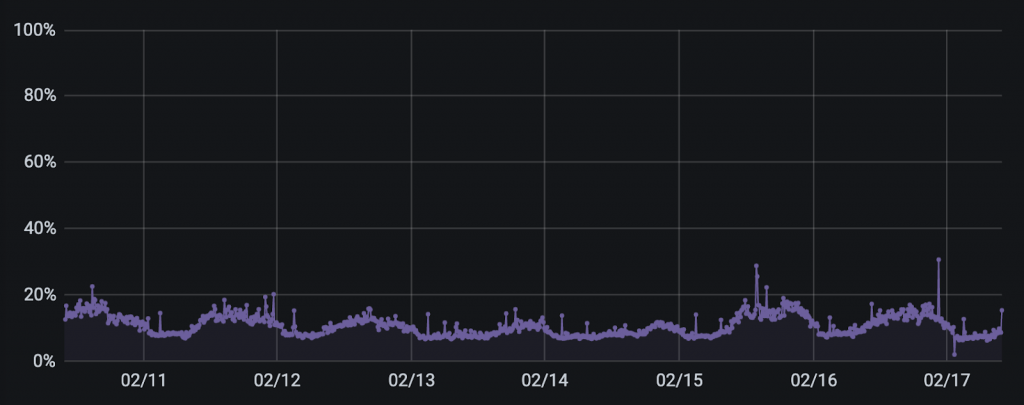
График 2. Источник: IO Technologies
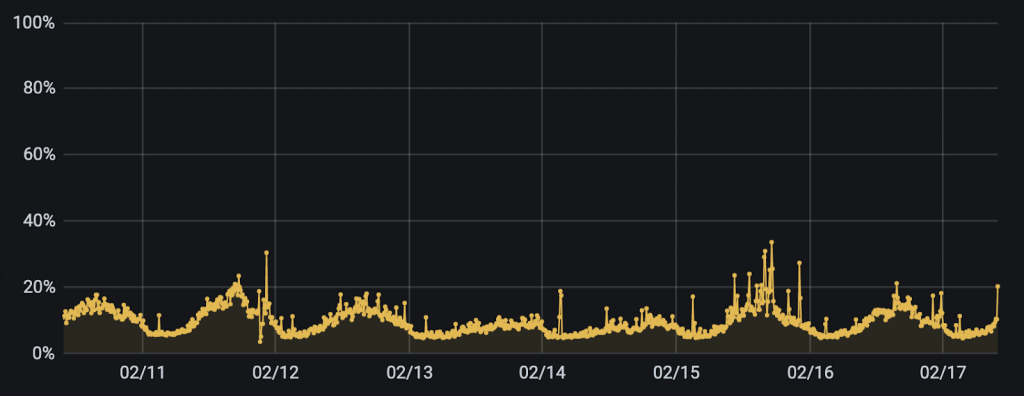
График 3. Источник: IO Technologies
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: