

Веб-архивы интернета: список действующих ресурсов

В интернете еженедельно архивируется более миллиарда страниц. Веб-архивы используются для различных целей: с их помощью можно найти уже несуществующий сайт или статью, веб-страницу, дизайн которой изменился, извлечь/загрузить данные для анализа.
Редакция Highload разобралась, что такое веб-архив, какие актуальные ресурсы есть в интернете и для чего их используют.
Содержание
- Существующие веб-архивы в интернете
- Что такое веб-архивы?
- История появления
- Назначение веб-архива
- Действующие веб-архивы
- Что делать, если удаленная страница не сохранена ни в одном из архивов?
- Как скачать сайт из веб-архива?
- Как скачать все изменения страницы из веб-архива?
- Как узнать все страницы сайта в веб-архиве?
- Как запретить добавление сайта в веб-архив
- Заключение
Существующие веб-архивы в интернете
Как и любой другой материал, собираемый библиотеками и архивами, веб-архивы нужны для того, чтобы дополнять существующие коллекции и служить разным целям.
Основная цель веб-архивирования — сохранение исходной формы собранного контента без изменений.
Что такое веб-архивы?
Поскольку интернет предоставляет доступ к самой свежей информации, сайты регулярно обновляются, постоянно развиваются и претерпевают изменения. Безусловно, это одна из сильных сторон интернета. Но она означает еще и то, что важная информация также может быть утеряна.
Веб-архивы и предназначены для того, чтобы захватывать контент в качестве «улик» в деловых или исторических целях.
Веб-архивирование — это процесс сбора данных из интернета, обеспечение их сохранности и предоставление собранной информации для будущих исследований. Этот процесс аналогичен традиционному архивированию бумажных документов. Вся информация также отбирается, сохраняется и обрабатывается.
Как и в традиционных архивах, веб-архивы собираются и обрабатываются архивистами, в этом случае «веб-архивистами».
Поскольку интернет содержит огромное количество сайтов и контента, веб-архивисты обычно используют автоматизированные методы для сбора данных. Сам процесс включает в себя «сбор» сайтов с помощью специально разработанного программного обеспечения — краулера.
Краулеры — поисковые роботы — копируют и сохраняют информацию по мере ее поступления.
Веб-архивы записывают содержимое веб-страницы, включая ее исходный HTML, встроенные изображения, таблицы стилей или исходный код JavaScript. При просмотре пользователь может взаимодействовать с заархивированной страницей, в том числе осуществлять переходы по ссылкам.
Общедоступные веб-архивы, как правило, создаются и поддерживаются независимыми организациями во избежание злонамеренных манипуляций и фальсификаций.
История появления
Большая часть раннего интернета и данные, которые он когда-то содержал, исчезли навсегда. С 1990 по 1997 годы сохранилось очень мало веб-информации.
Практика веб-архивирования была инициирована только в 1996 году, предоставляя гигантский объем исторической информации о самой сети, недавней истории и культуре, а также данные о том, как сеть изменила методы общения людей друг с другом.
Основателем архива считается Брюстер Кейл. С этого времени в нем сохранены миллионы книг, аудиофайлов, видео-контент, терабайты данных и миллиарды сайтов и веб-страниц.
Назначение веб-архива
Веб-архив — это специальный онлайн-сервис, хранящий истории сайтов, которые обошла поисковая машина. Он сохраняет как HTML-код страниц, так и другие типы файлов — медиа, zip-архивы, .pdf, .doc, css стили и не только.
Все это позволяет восстановить сайт в том первоначальном виде, в котором он когда-то работал, посмотреть его историю и авторитетность.
Существует множество причин, при которых возникает необходимость просмотра старых версий сайтов. На многих сайтах со временем многое меняется, в том числе:
- дизайн;
- данные;
- определенные удаленные или обновленные страницы.
Интернет-архивы выполняют ту же функцию, что и библиотеки, позволяя нам заглянуть в прошлое и увидеть, как все изменилось с течением времени. Веб-архивы сохраняют информацию, опубликованную в интернете или оцифрованную из печатных изданий. Большая часть этой информации уникальна и исторически ценна.
История сайтов в веб-архиве сохраняется по годам в виде скриншотов. Он полезен и при SEO-продвижении, позволяет избежать ошибки при выборе доменного имени сайта, восстановить информацию (контент, изображения), утерянную во времени.
Действующие веб-архивы
Хотя Wayback Machine — старейший и крупнейший общедоступный веб-архив, это не единственная общедоступная веб-библиотека, содержащая данные о сайтах и веб-страницах. Ниже приводим пример лишь некоторых из них.
Web.archive.org
Wayback Machine — это одна из лучших архивных библиотек, которой ежедневно пользуются миллионы людей. Многие компании полагаются на данный веб-архив при оценке конкурентов и построению стратегии развития. Он позволяет увидеть историю проиндексированного сайта и то, как он был создан.
Если вы умеете пользоваться поисковой системой, вам будет достаточно просто разобраться в вопросе поиска заархивированных веб-страниц.
Просто зайдите на Wayback Machine и введите поисковый запрос, появится список релевантных сайтов. Также можно сразу ввести адрес сайта или конкретный URL. У ресурса также есть очень подробная опция расширенного поиска, которая позволяет сузить поисковый запрос, выбрать дату и многое другое.
Wayback Machine — это платформа, которая играет жизненно важную роль в предоставлении исторической информации о любом сайте.
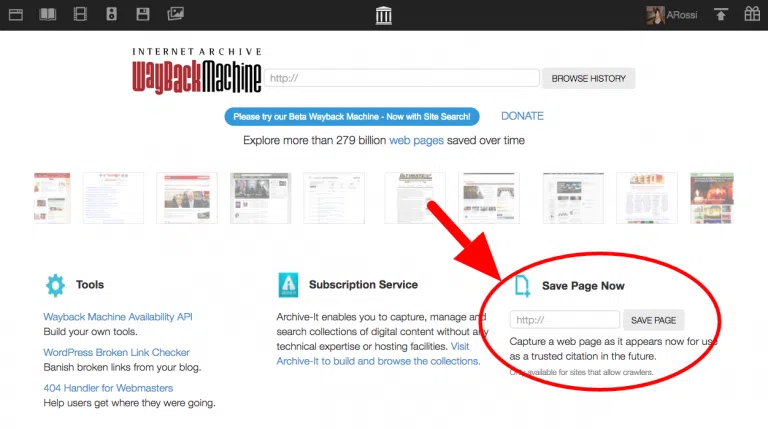
Архив существует с 1996 года. Помимо снимков и истории сайтов в нем содержатся тысячи терабайт фото- и видео контента, старых телепередач, оцифрованных книг. Чтобы найти сохраненные версии сайтов, необходимо в поле ввести адрес и нажать на кнопку поиска — Browse History.
Нажмите на сайт в результатах поиска для загрузки его последней заархивированной версии с ползунком в верхней части страницы, который позволяет выбрать дату. Выберите время, и архив загрузит снимок сайта с этой датой и временем.
На сайте доступны инструменты:
- Календарь/Calendar — показывает, когда производилось архивирование указанной в поиске страницы;
- Коллекции/Collections — раздел доступен по подписке, а также для тех, кто зарегистрируется в сервисе;
- Изменения/Changes — показывает изменения в содержимом адреса URL;
- Статистика/Summary — сводка об изменениях типов данных с применением стандарта MIME;
- Карта сайта/Site Map — полный список страниц сайта.
Веб-архив также доступен в качестве расширения для браузеров Chrome, Firefox и Safari. Также разработаны приложения для Android и iOS.
Archive.md
Архив archive.md доступен по адресам http://archive.today/ и http://archive.ph/.
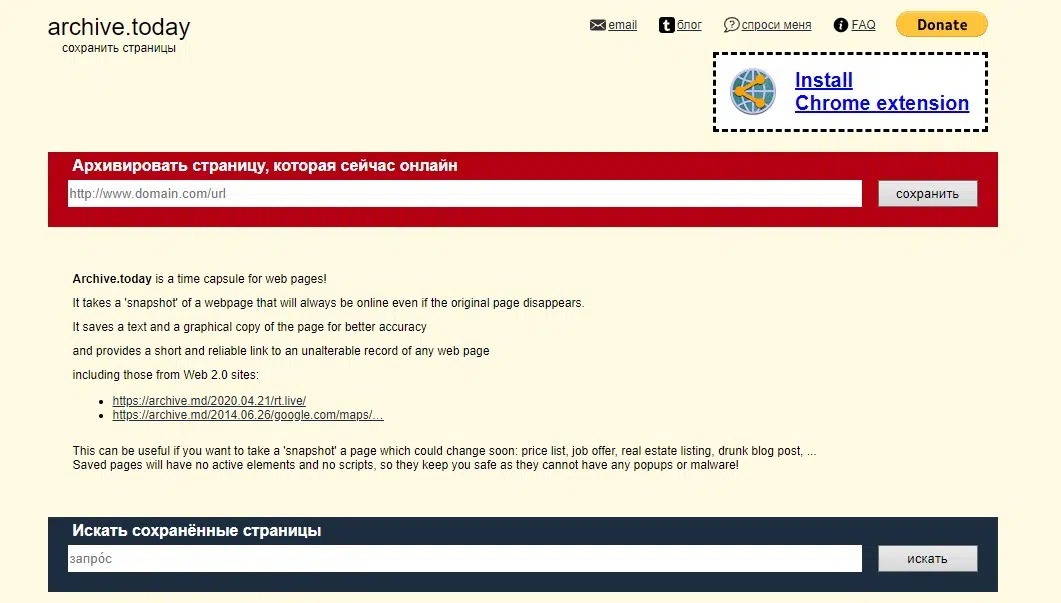
Сервис позволяет находить сохраненные страницы, а также осуществлять архивирование существующих. Для того чтобы найти сохраненную ранее веб-страницу, нужно ввести конкретный URL или указать домен сайта.
Архив не хранит аудио и видео с сайтов, RSS, документы в формате .pdf, flash-страницы.
Доступно сохранение:
- картинок;
- фреймов;
- текста;
- контента с сайтов Web 2.0;
Web-arhive.ru
Сервис web-arhive.ru хранит копии страниц сайтов. Он полностью бесплатный.
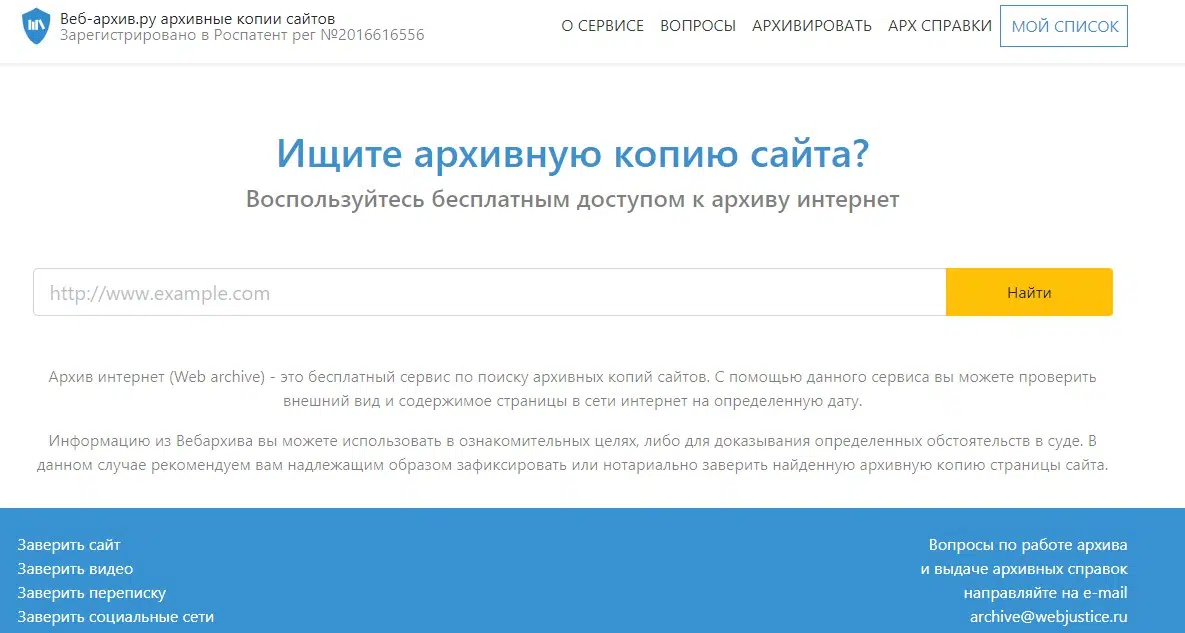
Доступны функции:
- отображение копии страницы сайта с указанием даты и времени ее создания;
- ввода пользователем адреса сайта для архивирования;
- заверенные нотариально копии архивов веб-ресурсов активно используются в качестве разрешения споров через суд.
Что делать, если удаленная страница не сохранена ни в одном из архивов?
Встречаются случаи, когда пользователь для просмотра истории не может найти в веб-архиве нужную веб-страницу, документ или файл.
Что делать? Первым делом необходимо обратиться к нескольким веб-архивам и поискать там. Если ничего так и не нашлось, скорее всего, страница была удалена еще до обработки ее поисковыми инструментами архивов.
В этом случае можно обратиться к кэшу поисковика Google. Для этого в поле поиска нужно ввести: cache:URL/имя сайта.
Например: cache:https://mysite.ua/?p=3027
Откроется кэшированная поисковиком указанная страница сайта.
Важно отметить, что в кэше поисковой системы Google содержится последняя актуальная перезаписанная страница. С каждым новым обходом этой страницы поисковым роботом данные будут перезаписываться на актуальные.
Помните, для обновления кэша в Google необходимо в среднем до 15 дней.
Как скачать сайт из веб-архива?
Как находить архивные копии страниц сайтов, используя для этого специальные онлайн-сервисы — мы обсудили. Но как полностью скачать и восстановить сайт из архива?
Wayback Machine Downloader — это онлайн-сервис, который поможет загрузить веб-ресурс со всеми внутренними страницами и вложенными файлами из интернет-архива.
Он осуществит загрузку самых последних версий каждого из архивных файлов, которые имеются на Wayback Machine, в директорию ./websites/mysite.ua. Заново создаст структуру каталогов и страницы index.html. Это необходимо для стабильной работы с Apache и Nginx.
Все загружаемые файлы не будут перезаписаны с Wayback Machine как есть, они будут полностью оригинальными, а потому урлы и структура ссылок останутся такими же, как и были когда-то.
Чтобы запустить Wayback Machine Downloader и приступить к скачиванию полной версии сайта, необходимо ввести: wayback_machine_downloader https://mysite.ua
Обозначения:
-d |
--directory. Папка по умолчанию: ./websites/mysite.ua/. |
-s |
--all-timestamps. Загрузка меток времени сайта. |
-f |
--from TIMESTAMP. Загрузка файлов на указанную или более позднюю временную метку. |
-t |
--to TIMESTAMP. Загрузка файлов на указанную или более раннюю временную метку. |
-e |
--exact-url. Загрузка исключительно указанных URL-адресов. |
-o |
--only ТОЛЬКО_ПО_ФИЛЬТРУ. Загрузка URL относительно фильтра. |
-x |
--exclude ФИЛЬТР_ИСКЛЮЧЕНИЯ. Не загружать URL, указанные в фильтре. |
-a |
--all. Загрузка также файлов редиректов и ошибок. |
-c |
--concurrency ЧИСЛО. Число загружаемых файлов. |
-p |
--maximum-snapshot ЧИСЛО. Максимальное число скринов страниц (100), которые будут рассмотрены. |
-l |
--list. Вывод списка URL в JSON формате. |
-v |
--version. Вывод версии. |
Например:
Вывод из архива исключительно ссылок на файлы > mysite-urls.json —
wayback_machine_downloader https://mysite.ua -l > mysite-urls.json
Список ссылок будет сохранен в файл.
Как скачать все изменения страницы из веб-архива?
Предположим, перед нами стоит задача скачать архивную копию сайта не целиком, а лишь его отдельную веб-страницу. Для такой цели необходимо задействовать программу Waybackpack.
Waybackpack — это небольшая утилита командной строки, позволяющая по заданному URL-адресу скачать архив из Wayback Machine целиком.
Например, чтобы загрузить все веб-копии главной страницы сайта до 2019 года (год, когда сайт был впервые заархивирован), вы должны запустить: waybackpack http://www.mysite.ua/ -d ~/Downloads/dol-wayback --to-date 2019
Обозначения:
| URL | URL, который нужно загрузить. Обязательный аргумент. |
|
Необязательные аргументы |
|
-h |
--help. Вывод справки. |
--version |
Вывод версии. |
-d DIR |
Создание директории для сохранения файлов. |
--list |
Вывод списка всех копий. |
--raw |
Загрузка исходных файлов без каких-либо изменений. |
--root ROOT |
URL для обработки архива данных (по умолчанию https://web.archive.org). |
--from-date |
Метка времени для загрузки самого раннего архива. |
--to-date |
Метка времени для загрузки самого последнего архива. |
--user-agent USER_AGENT |
Отправка вместе с запросами к Wayback Machine. |
--follow-redirects |
Следование редиректам. |
--uniques-only |
Загрузка первой версии копий файлов. |
--collapse COLLAPSE |
Параметр для archive.org. |
--ignore-errors |
Продолжать работу при ошибках не http. |
--quiet |
Не сообщать о прогрессе в stderr. |
Например:
Загрузка из архива всех копий домашних страниц ресурса, начиная с 2020 года (--to-date 2020), размещение их в директории -d /home/my/test с наследуемыми редиректами (--follow-redirects) — waybackpack mysite.ua -d /home/my/test --to-date 2020 --follow-redirects
Как узнать все страницы сайта в веб-архиве?
Сервис Wayback Machine может осуществлять вывод всех копий веб-страниц сайта. Для того, чтобы это сделать, необходимо в адресную строку ввести: https://web.archive.org/web/*/[URL]/*.
Для этого также можно использовать инструмент Waybackurls — принимает домены с разделителями строк, извлекает все известные адреса URL из Wayback Machine для *.domain.
Для того, чтобы из Wayback Machine получить полный список всех страниц сайта mysite.ua, необходимо ввести: echo mysite.ua | waybackurls
Для того, чтобы из Wayback Machine получить список страниц сразу нескольких сайтов, необходимо ввести: cat домены.txt | waybackurls
Обозначения:
-dates |
Вывод первого столбца с датой архивирования веб-страницы. |
-no-subs |
Не выводить субдомены. |
Например:
Получение из Wayback Machine полного списка страниц с адресами для сайта mysite.ua — echo mysite.ua | waybackurls -dates (c показом даты архивирования (-dates).
Как запретить добавление сайта в веб-архив
Чтобы обезопасить себя от несанкционированного использования контента с вашего сайта после его удаления, добавления ресурса в веб-архив можно запретить.
Самый простой способ — изменение настроек в robots.txt и блокировка доступа к сайту поисковых роботов с целью сканирования всех его страниц с последующим добавлением в архив. Но произведенные ранее сканирования и выгрузка данных в архивах будут доступны все равно.
Чтобы удалить информацию окончательно, следует воспользоваться официальной почтой веб-архива — [email protected] — для отправки запроса на удаление. Важно, чтобы это письмо было отправлено с вашего домена. Только в этом случае в течение трех дней сайт полностью исчезнет из Wayback Machine.
Чтобы восстановить сайт в веб-архиве, необходимо также отправить запрос на указанный выше имейл веб-архива.
Заключение
Интернет — один из основных средств коммуникации. В нем содержится информация о недавних событиях, описываемая людьми разных точек зрения. Сеть — ценный ресурс для современных исторических исследований.
Так, например, историк Ян Миллиган использовал веб-архивы для изучения онлайн-сообществ GeoCities, популярных в конце 1990-х годов. Ему удалось изучить вопросы формирования пользователями собственных сообществ и их взаимодействий во времена, когда еще не было социальных сетей. Сетевые веб-архивы помогают углубиться в изучение важных культурных и исторических событий последних 20 лет.
Веб-архивирование направлено на получение, сохранение и предоставление доступа к исторической информации, опубликованной в интернете. По веб-архивированию реализовано множество инициатив. Архивные коллекции веб-документов образуют полную картину нашей культурной, коммерческой, научной и социальной истории.
В будущем веб-архивы, вероятно, станут для многих одним из источников личных воспоминаний.
Также на тему работы с веб-архивом есть отличное видео на английском языке:
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: