


В моей предыдущей статье мы познакомились с основными терминами облачных вычислений. Теперь поговорим об их интеграции в систему. Рассмотрим Cloud Adoption Framework и Well-Architected Framework, необходимые при проектировании систем в облаке.
Выбирая вместо собственного дата-центра облачного провайдера любой бизнес получает как свои преимущества, так и определенные риски.
Преимущества для бизнеса
Capacity planning
Речь идет о планировании производственных мощностей. Так компания оценивает свои ресурсы, необходимые для того, чтобы продукт отвечал требованиям рынка и переменным нагрузкам. Здесь возможны две проблемы. Первая — over provisioning, когда компания закупила мощные и дорогие серверы, простаивающие без дела. Вот, например, на графике изображено соотношение затрат на инфраструктуру и время ее использования (Opportunity Cost):
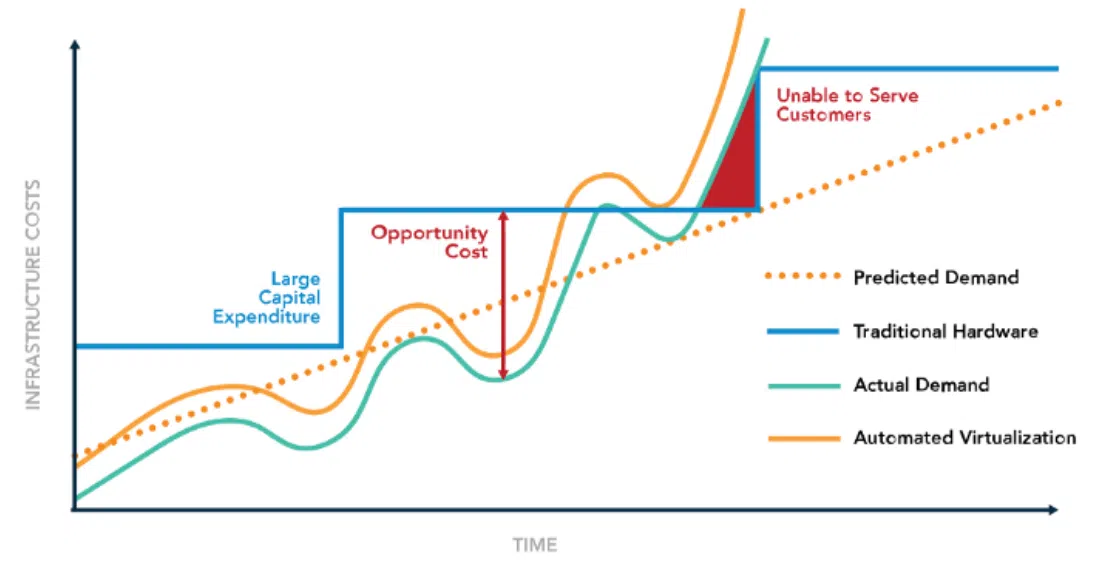
Вторая проблема — under provisioning, когда приобретенные серверы не справляются с нагрузкой. На графике это обозначено как Unable to Serve Customers. В обоих случаях ошибки в планировании мощностей приводят к потере денег, клиентов и ухудшению репутации самой компании. Клауд-провайдер поможет здесь гибко выбирать ресурсы под необходимую нагрузку.
Cost reduction
Это процесс сокращения ненужных издержек в бизнесе. Предположим, компания фокусируется на продукте и не видит смысла поддерживать свой дата-центр. Услуги клауд-провайдера, конечно же, стоят денег. Но существует много практик и инструментов управления финансами в клауде для сокращения затрат. Фактически на их основе сформировалась культура финансового менеджмента в облаке – FinOps. Детальнее об этом можете почитать по ссылке.
Organization agility
Это гибкая адаптация к внезапным изменениям из-за внутренних или внешних факторов. В качестве примера — пандемия COVID-19 и вызванный ею массовый переход на удаленную работу. Из-за этого нагрузка на сеть и IT-инфраструктуру резко возросла. Компании, которые не были гибкими в решении этих вопросов, пострадали больше всего. Именно оснащение собственного дата-центра или настройка инфраструктуры в клауде могли помочь ситуации.
Риски при использовании облачных технологий
Регуляторные риски
Каждый облачный провайдер должен отвечать стандартам и политикам страны или региона, на который распространяется бизнес-клиент. Особенно строгие стандарты в таких бизнес-доменах, как медицина, страхование, телеметрия. Здесь действуют конкретные стандарты безопасности для чувствительных данных.
Чтобы избежать проблем с регулятором, клиент должен понимать, какой облачный провайдер позволит соблюдать все возможные политики.
Гибридная клауд-интеграция
Сочетание частных и публичных облаков может стать вызовом с рядом потенциальных угроз. Компании нужно разделить на сервисы, политики и роли, и настроить эффективную и безопасную коммуникацию двух клаудов. При этом процесс интеграции двух и более облаков — комплексная задача. Но только так можно получить лучшее из этих двух моделей.
Vendor lock-in
Учитывая некоторые технологии или подписанные контракты, компании могут попасть в зависимость их продукта от конкретного провайдера.
Какие проблемы могут возникнуть? Например, с Service Level Agreement — когда после масштабирования среднее время ответа сервиса не такое, как прогнозировали. Также возможно снижение пропускной способности, стойкости под нагрузкой, истощение памяти базы данных и т.д. На все это нужно дополнительно обращать внимание.
Отсутствие экспертизы инженеров
Любой клауд — это специфический инструмент с массой нюансов. На стороне клиента должны быть специалисты по опыту работы с конкретным провайдером и его технологиями. Без достаточной экспертизы могут возникнуть дополнительные риски безопасности или увеличиться стоимость услуг провайдера.
Пора мигрировать в облако
Рассмотрим вопрос о целесообразности миграции с On premises на облачные решения с технической стороны.
1 Нехватка DevOps-специалистов
Если в крупных продуктовых компаниях часто есть отдельная команда для обслуживания инфраструктуры и деплоя приложений, то в среднем, малом бизнесе и стартапах такой возможности обычно нет. Клауд легко возьмет на себя подобные задачи.
Облачные инструменты становятся все более простыми и доступными. Чаще появляются решения «из коробки», растет популярность no code/low code. В принципе, для работы с этими инструментами не нужно быть девопсом.
2 Работа с геораспределенными данными
Согласно требованиям отдельных регуляторов, данные местных пользователей должны храниться именно в этих регионах. Традиционно компании пришлось бы разворачивать свою локальную инфраструктуру, но можно использовать «местный» клауд.
3 Наличие распределенных услуг
Выбор клауда в непосредственной близости к пользователям помогает сократить время на обработку запросов. Это важно не только для улучшения опыта пользователя. Компания может генерировать много сырых данных в отдаленном регионе. Заливать их в домашний дата-центр для дальнейшей обработки может оказаться дорого и долго. Поэтому можно отправить их на локальный клауд, обработать и отправить в базу готовые данные в уменьшенном в сотни раз объеме.
4 Потребность в точной оценке затрат
В работе с On premises обычно известна только общая стоимость инфраструктуры и отдельных компонентов. Но сложно сосчитать, сколько стоит конкретная операция. В случае с клаудом заказчик услуги точно знает стоимость каждого действия.
5 Ускорение циклов разработки
Работая с клаудом, команды становятся более автономными. Поиск, настройка и запуск серверов в локальном дата-центре сокращается в разы. А это уже позволяет снизить общее время на разработку продукта.
6 Безопасность «из коробки»
Стандартный провайдер по умолчанию предоставляет достаточно высокий уровень защиты данных. Здесь все построено на ролях и не требует длительной, сложной и стоимостной настройки.
7 Интеграция продуктов
В основной продукт компании можно относительно быстро интегрировать дополнительные сервисы из экосистемы провайдера. Это улучшает работу программы и расширяет ее функционал. При этом интеграция будет постоянно поддерживаться и обновляться.
Прежде чем мигрировать в клауд, следует учитывать одну важную деталь. Это довольно долгий и ресурсоемкий процесс. Он требует стратегии и пошагового плана, чтобы упростить переезд и избежать возможных потерь.
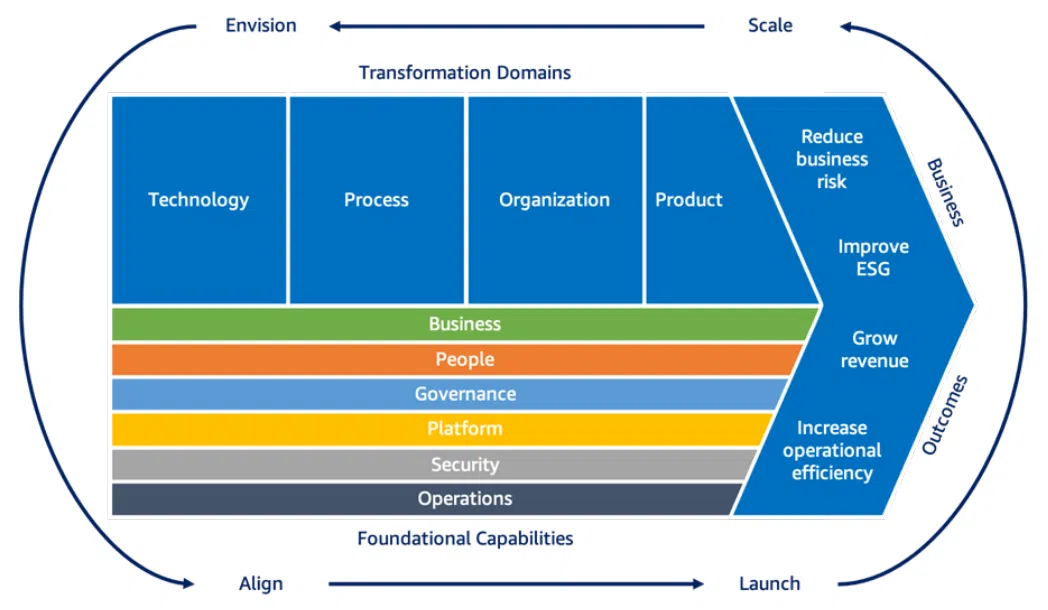
В контексте этой темы следует еще упомянуть Cloud Adoption Framework (CAF). Он позволяет упростить процесс передвижения. Но это достаточно сложный для понимания фреймворк, поднимающий немало вопросов вокруг бизнеса, управления, безопасности и операционной эффективности.
Подробно на CAF не буду останавливаться, и вы можете самостоятельно ознакомиться с ним по ссылкам:
- AWS Cloud Adoption Framework. Accelerating your cloud-powered digital business transformation;
- Cloud Adoption Framework guidance;
- How to use the Google Cloud Adoption Framework;
- Google Cloud Architecture Framework.
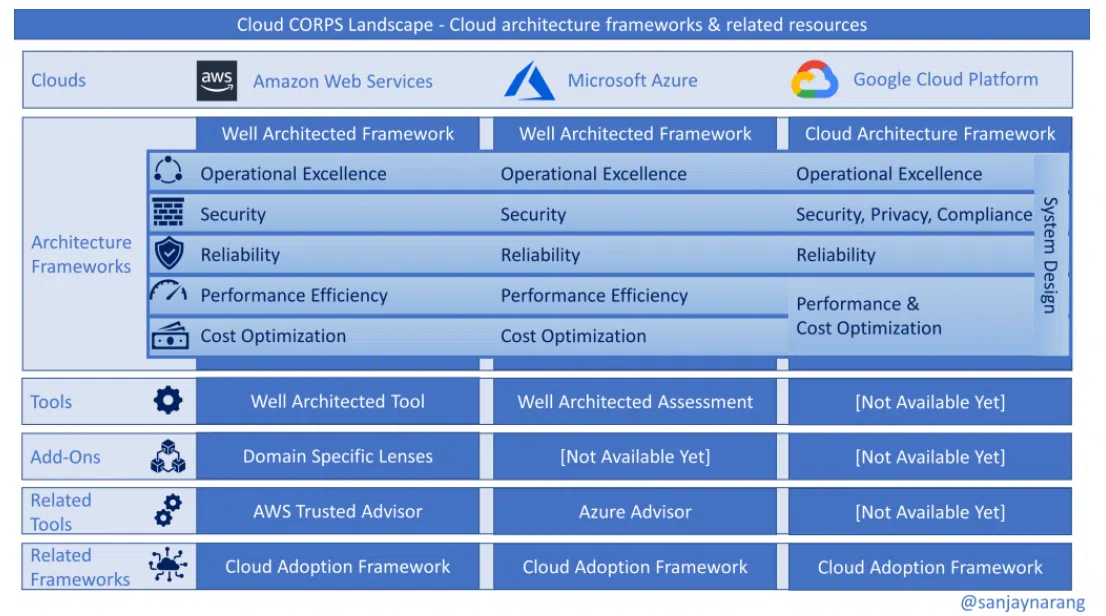
Облачные системы и Well-Architected Framework
Перейдем к вопросу разработки и проектирования систем. Есть много подходов и практик разработки систем (12/15 Factor App, TOGAF, Zachman framework, Enterprise patterns). Так или иначе, все это разворачивается в одной из моделей облака. В этой статье я сфокусируюсь на общих практиках использования Well-Architected Framework.
WAF был создан, чтобы помочь архитекторам создать более безопасную, высокопроизводительную, устойчивую и эффективную инфраструктуру приложения в облаке. Фреймворк обеспечивает консистентный подход для клиентов и партнеров по оценке собственной архитектуры. Также он дает рекомендации по внедрению дизайна, который будет со временем масштабироваться под потребности приложений.
Свое видение WAF имеют все облачные провайдеры: AWS WAF, Azure WAF и GCP WAF. Каждый из приведенных по ссылкам столпов фреймворка — это отдельная тема, выходящая за пределы этой статьи. Но в качестве примера рассмотрим общие принципы проектирования от лидера рынка — AWS.
Эти советы — универсальные при разработке системы и встречаются у разных облачных провайдеров. Хотя полезны они будут и тем, кто работает не только с клауд-технологиями.
Хватит угадывать потребность в ресурсах
Этот принцип касается Capacity Planning. Клауд должен позволять автоматически масштабироваться в зависимости от уменьшения или увеличения нагрузки. Как вертикально, так и горизонтально. Правило действует как для серверов, так и, скажем, для количества запросов в базу данных.
Тестируйте систему под ожидаемую нагрузку
Обычно это касается тестирования продакшена. Облако позволяет достаточно легко создавать тестовое окружение для тестирования нагрузки и проверять, соответствуют ли все лимиты системы предполагаемым оценкам. После тестирования это окружение можно без проблем удалить.
Все подобные инструменты лучше запускать через Infrastructure as Code — как продакшенную реплику. Так вы можете протестировать и удалить систему в любой момент.
Автоматизируйте для упрощения архитектурных экспериментов
В большей степени речь идет об инфраструктуре: организации ее как кода, хранении в системе контроля версий и изменений небольшими имплементациями (при необходимости возвращать изменения).
Рекомендуется придерживаться best practices и пропагандируемой культуры в зависимости от типа самого продукта (DevOps, DataOps, MLOps и т.п.).
Допускайте эволюцию архитектуры
В отличие от традиционных On premise решений, когда изменения в архитектуре происходит значительные, но не часто, в клауде лучше прибегать к изменениям чаще, но небольшими итерациями.
Управляйте дизайном архитектуры с помощью данных
Для оптимизации процессов системы в клауде нужно регулярно мониторить и анализировать множество параметров. Имеется в виду отслеживание данных о погрузке, отказах, ошибках, метрике безопасности, количестве тикетов в саппорте и т.д.
Улучшайте архитектуру с помощью Game days
Во время Game days моделируется проблемное событие в клауде, подготовленное по соответствующему сценарию, и прогоняется в рамках специальных ивентов.
Можно проработать ситуацию, когда, скажем, кто-то получил доступ к админ-аккаунту и начал вносить изменения в инфраструктуру. Тогда у команды должна быть пошаговая инструкция (runbook), как себя вести в такой ситуации. Отработка сценария дает понять, как хорошо и быстро все справились с решением проблемы.
Вот пример такого сценария:
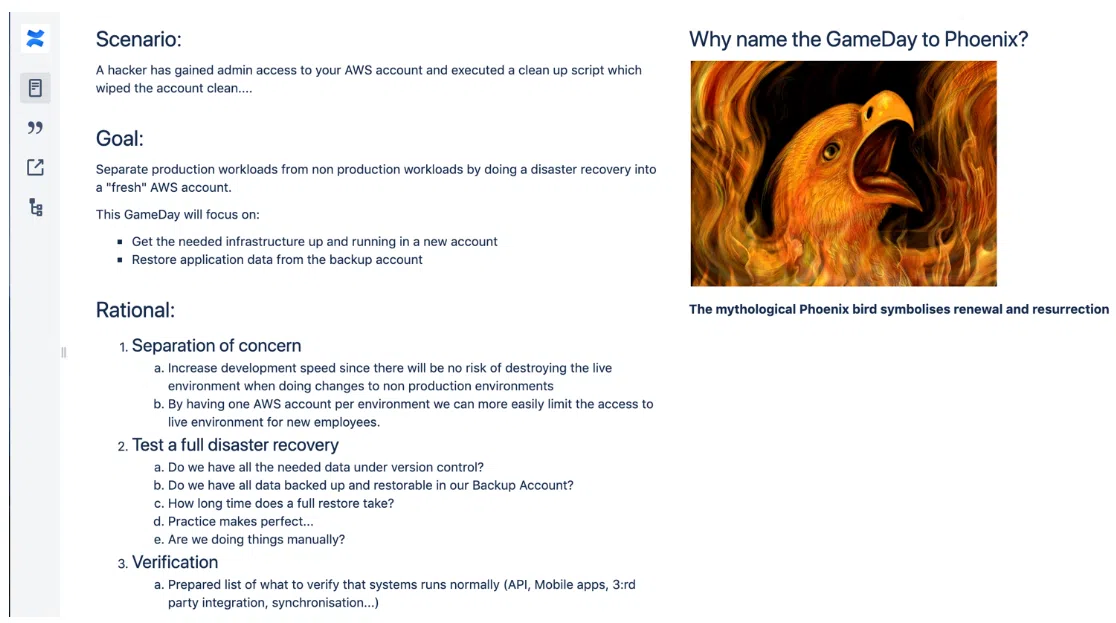
… и шаблон документации на Game days:
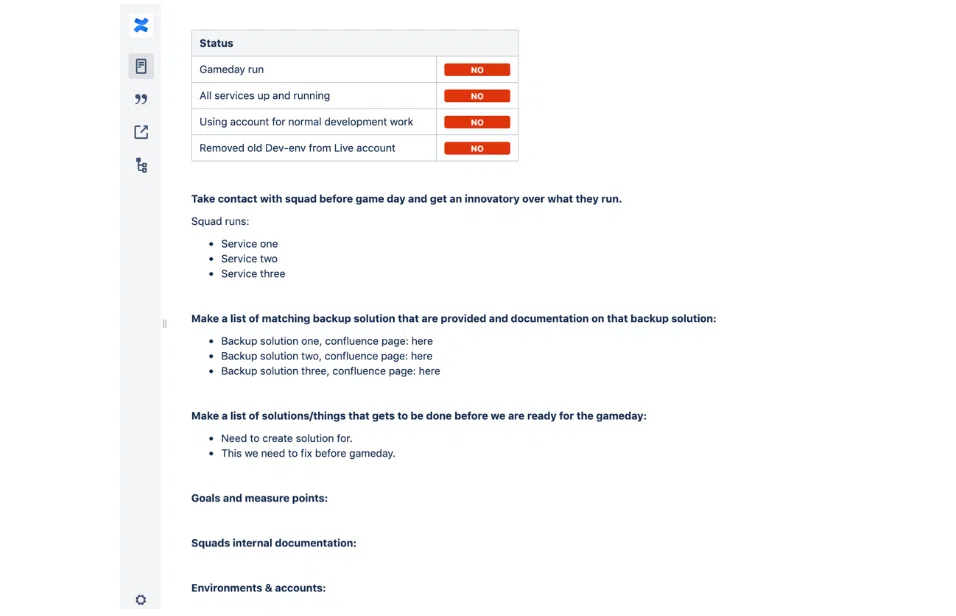
Использование WAF и CAF в облаке не ограничивается. В каждой экосистеме есть свои инструменты по улучшению разработки приложений в клауде. Впрочем, это уже тема отдельной статьи.
Подробнее о применении Well-Architected Framework читайте по ссылкам:
- AWS Well-Architected Framework;
- AWS Well-Architected. Learn, measure, and build using architectural best practices;
- Microsoft Azure Well-Architected Framework.
 Spotify: история успешной миграции в клауд
Spotify: история успешной миграции в клауд
Напоследок приведу пример — переезд в облако сервиса Spotify. В 2015 году его команда решила отказаться от своей инфраструктуры.
Причина — желание сосредоточиться на повышении удобства сервисов и доставки музыки, а не на обслуживании собственной инфраструктуры, как это принято в IT-компаниях (Spotify позиционируют себя как продуктовую компанию). В этом случае поддержка дата-центров не влияет на ценность конечного продукта. А еще, по прогнозу, на использовании клауда должно сэкономить немалые средства.
В качестве новой платформы выбрали тогда еще начинающих Google Cloud Platform. Таким образом Spotify отошли от вопросов поддержки, масштабирования и балансировки кластеров Kafka. Все это заменили Pub/Sub сервисом на стороне клауда. То же касалось и Spark в связке с Hadoop. Отдельно Spotify оценили один из самых популярных гугловых сервисов — BigQuery и BigTable. С ними удалось быстро доставлять пользователям рекомендации по масштабу терабайтов данных.
Миграция для Spotify оказалась настоящим челленджем. В 2015 году у сервиса было 120 распределенных команд и 170 млн пользователей. Это был крупнейший Hadoop-кластер в Европе — 2500 нодов, 1200 сервисов, 20000 джобов на кластере и 100 ПБ данных. Если бы компания остановила генерацию данных, переезд в облако на доступной тогда скорости 20 ГБ/с занял бы два месяца. В действительности миграция продолжалась около двух лет. Только на перенос данных понадобился год…
В течение этого времени Spotify много экспериментировали. Разработчики любили Scala и функциональное программирование, потому создали свой Scala-фреймворк для работы с кластером. Более подробно об этом опыте миграции можете узнать из этого видео:
В результате переезд полностью оправдал себя. Отказ от инфраструктурных проблем позволил Spotify сосредоточиться на новых, более значимых для компании задачах и дальше развивать бизнес. Сегодня у сервиса более 450 млн пользователей. На него приходится треть мирового аудиостриминга. Уверен, эти показатели были бы невозможны без мощной клауд-платформы.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: