


Известный физик Нильс Бор говорил: «Проблемы важнее решения. Последние могут устареть, а проблемы остаются». Я полностью согласен с этим утверждением. Особенно, если говорить о моделировании и организации данных в приложениях. Эта проблема до сих пор с нами.
С одной стороны, реляционные базы данных неидеальны для современного мира с его безграничным масштабированием. С другой – у новых NoSQL-моделей тоже есть недостатки как минимум с дублированием данных. Поэтому почти каждый разработчик ищет лучший способ организации базы данных. Иногда задача решается объединением реляционных и нереляционных схем.
В этой статье я объясню на примерах, как применить NoSQL-подходы в реляционных базах данных и когда это будет уместно. На многих теоретических моментах я не буду заострять внимание. Надеюсь, опытные читатели понимают, о чем идет речь.
Содержание
1. Особенности реляционных баз данных
2. Проблемы реляционных БД
3. Что такое NoSQL
3.1 Key-Value Store
3.2 Column Family
3.3 Graph Databases
3.4 Document Databases
4. MongoDB на практике
5. Преимущества и недостатки NoSQL
6. Использование JSON в реляционных базах данных
7. Преимущества и недостатки JSON в реляционных БД
8. Выводы
Особенности реляционных баз данных
Большинство разработчиков хорошо знают концепцию реляционных БД и пользуются ею почти в каждом проекте. Существованию этой модели мы обязаны ее основателю Эдгару Кодду. В 1970 году он выпустил статью A Relational Model of Data for Large Shared Data Banks, где впервые описал концепцию, построенную на реляционной алгебре. В то время его идею, откровенно говоря, не совсем поняли. Поэтому впоследствии Эгар для более детальной формализации своей теории опубликовал 12 правил Кодда.
Что же делает реляционную БД именно реляционной?
- Схема БД. В нее входят набор таблиц, их атрибуты и отношения между ними. Также здесь есть Primary Key, Foreign Key и т.д. Эту схему важно знать заранее, потому что без этого невозможно положить в БД какие-либо данные.
- Нормальные формы. Если сделать базу данных как одну огромную таблицу со всеми данными, то это будет работать очень плохо. Данные нужно разбить на меньшие таблицы и создать связи между ними. Для этого и есть обычные формы. На них строятся реляционные базы данных.
- ACID-транзакции. Осмелюсь сказать, что это самое важное в описанном типе баз данных. Название ACID происходит от Atomicity (атомарность), Consistency (последовательность), Isolation (отделенность) и Durability (долговечность). В реляционной системе БД существует транзакционный механизм, в результате которого набор запросов или набор операций по БД по истечении сохранит все эти данные. При этом только тогда все данные будут согласованы между собой, а доступ к ним будет даже при падении всей системы.
Эти принципы помогают хорошо организовать работу с базами данных, сделать ее проще и понятнее. Именно поэтому реляционные базы данных так популярны.
Проблемы реляционных БД
Но к таким базам данных со временем начали появляться вопросы. Первым неудобством, из-за которого разработчики стали искать альтернативу, стало Object-relational impedance mismatch — несоответствие объектно-реляционного импеданса. Объясню этот термин на примере.
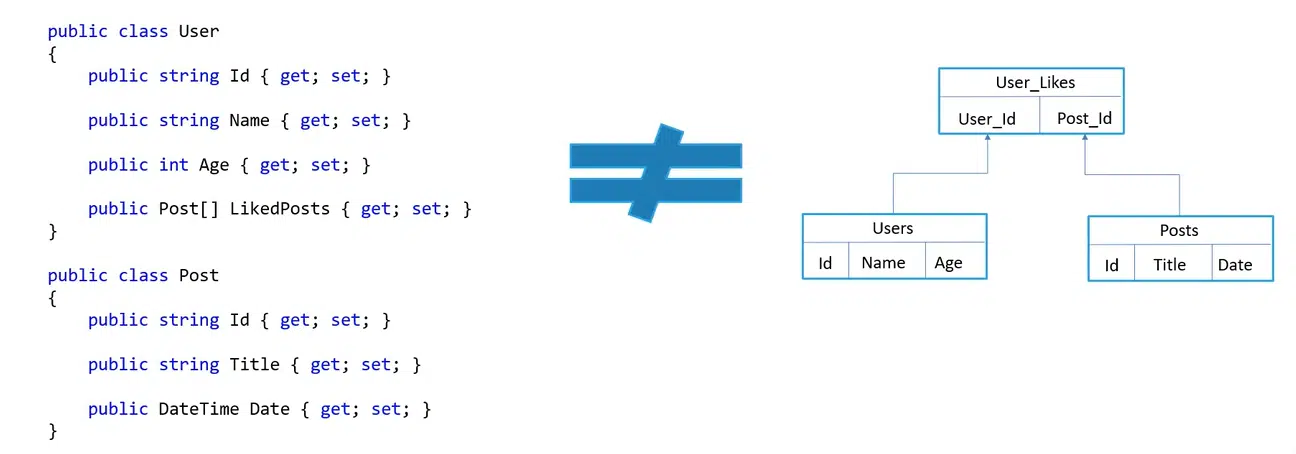
Представьте, что есть класс User со своими полями, а в нем — коллекция постов, которые он, настоящий пользователь, лайкнул. Но если начать по описанным правилам строить схему БД и размещать эти данные, они будут храниться в несколько ином или вообще не таком формате, который есть в памяти. Поэтому разработчики должны придумывать механизмы для получения снапшота данных, писать query с join, знать отношения между таблицами, возвращать соответствие назад после получения — и все это доставляет немало хлопот.
Нажмите, чтобы рассмотреть
Для преодоления этой проблемы были попытки создать объектно-ориентированные базы данных. Но идея не прижилась, ведь это были те же реляционные БД со встроенным механизмом мапинга. Настоящие проблемы начались с выходом на новые масштабы: когда в каждом доме появился скоростной интернет, а крупные бизнесы начали операционную деятельность по всему миру. Именно тогда разработчики задумались о горизонтальном масштабировании, когда система масштабируется благодаря простому добавлению инстансов.
Идея проста: один реквест должен обрабатываться одной нодой. Чем больше нод, тем больше реквестов можно делать. Но это не кейс реляционных баз данных.
Предположим, в БД есть Users и Posts. Мы решили масштабировать базу, но могут возникнуть некоторые вопросы:
- во-первых, пользователи могут быть на разных нодах;
- во-вторых, посты для пользователя на одной ноде могут оказаться на другой.
Поэтому для выполнения запроса, например, select from users joins post, нужно сходить уже на две ноды. К тому же, данные могут быть распределены неравномерно. В результате скорость обработки данных падает, а система выходит слишком сложной. Поэтому потребовалась другая альтернатива.
Что такое NoSQL
Как это часто бывает, первые успехи в создании нового типа БД получили крупные компании — Google и Amazon. Они одни из первых решили отойти от реляционности и обрести новую парадигму. В течение 2006-2007 годов появились статьи Big Table от Google и Dynamo от Amazon об их облачных базах данных. Озвученные в публикациях идеи не были соединены с реляционной теорией. Там не было табличек, связей, джойнов, а главное — разработчики этих систем достигли подлинного масштабирования.
Этот опыт вдохновил многих программистов развивать подобные идеи. Так, в 2009 году несколько разработчиков организовали митап на эту тему. К событию присоединились серьезные бренды, в том числе MongoDB, CouchDB и другие. Инициаторы мероприятия искали не столько лозунг к нему, а что-то вроде хэштега, чтобы привлечь внимание сообщества в Twitter. Так и возникло название NoSQL.
Основных моделей несколько, и у каждой есть свои особенности, преимущества и недостатки. Поэтому немного расскажу о каждой из них.
Key-Value Store
Это самая простая NoSQL-парадигма. В хранилище хранится ключ и value — и все. Нет никаких сложных филдов, связей между key-value, нет вообще ничего. Главное преимущество — такая структура масштабируется безгранично. Ее самый яркий пример — Redis, который многие используют как кэш.

Нажмите, чтобы рассмотреть
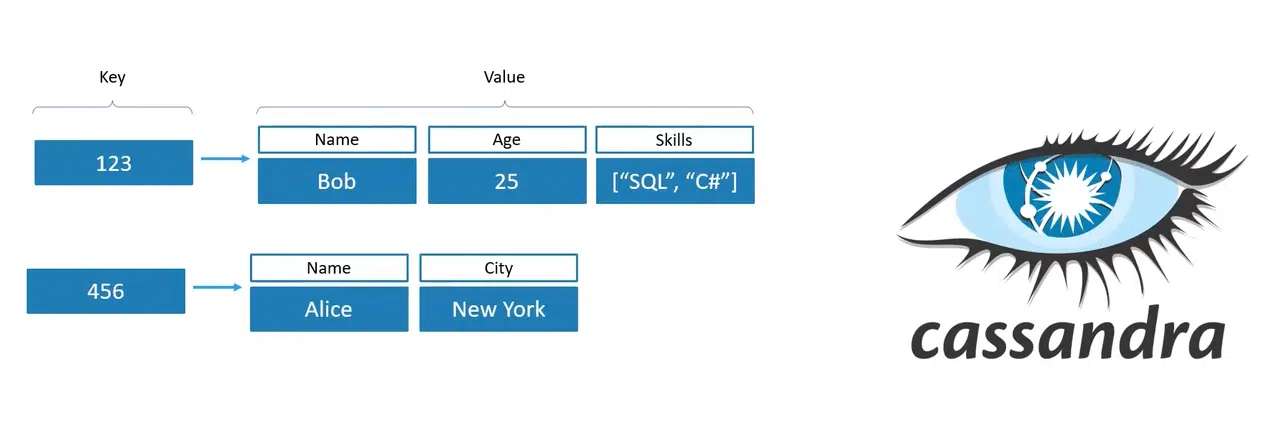
Column Family
Эта модель взяла key-value и подвинула ее дальше. Здесь также есть key, но value уже не простая строка, а набор из собственных пар key-value. То ест это уже система колонок со значением, где каждая строка может иметь свои наборы. Пример такой БД — Cassandra.
Нажмите, чтобы рассмотреть
Graph Databases
Этот вариант несколько экзотичен и основан на концепции графов. Согласно идее, связь между данными — это тоже определенные данные. Построение таких связей-данных и будет напоминать граф. Таким образом можно получить широкие возможности создания иерархии или запутанных связей. Так работают практически все соцсети.
Один пользователь связан с другим как друг, тот, в свою очередь, подписан на какую-то группу, а первый лайкает какие-то посты — и это все примеры связей, являющихся данными. На этой модели создан Neo4j. У него есть даже очень интересный синтаксис для написания запросов к столь необычной БД.

Нажмите, чтобы рассмотреть
Document Databases
У многих разработчиков NoSQL ассоциируется, прежде всего, с Document Databases — документными БД. Их принцип выглядит следующим образом: по какому-то ключу хранится целый документ в виде набора из key-value-значений бесконечной вложенности и неожиданной структуры, которая только может понадобиться. Один из популярных примеров реализации этой парадигмы — MongoDB.

Нажмите, чтобы рассмотреть
MongoDB на практике
О MongoDB мне хотелось бы рассказать поподробнее. Представим проект, в котором нужно построить Google Forms с простой функциональностью: пользователь может создавать форму со свободным набором полей, любого количества.
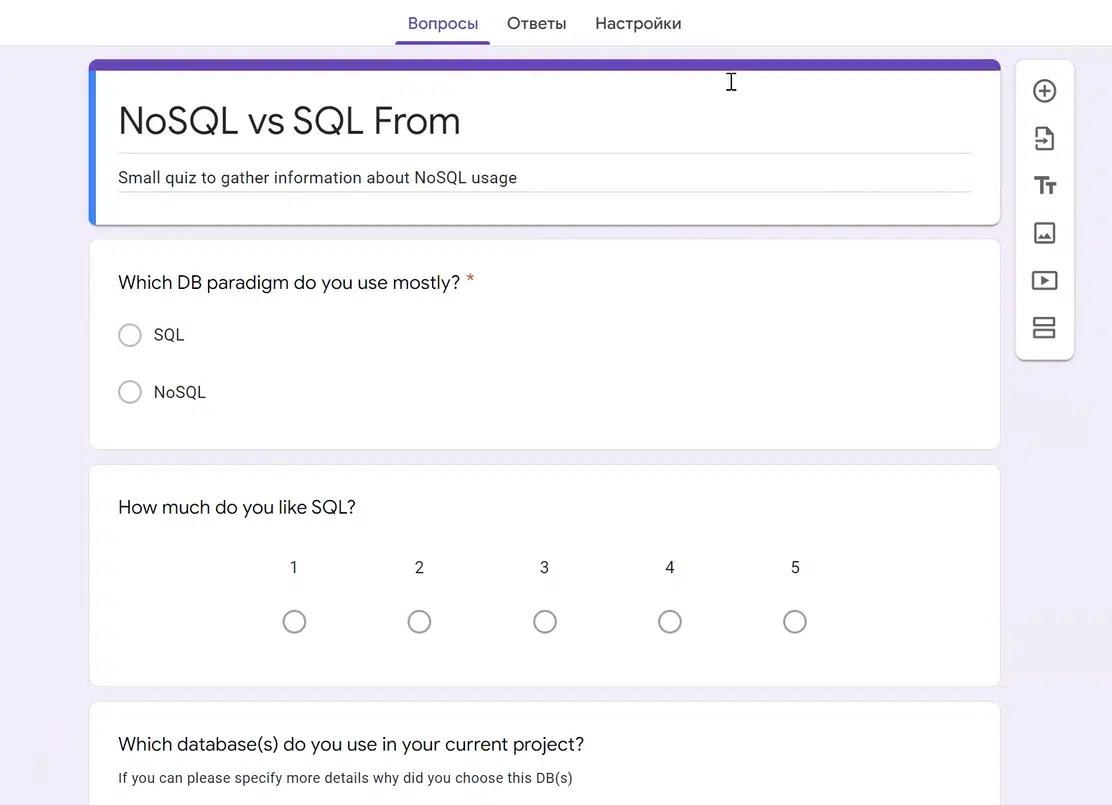
Моя форма «NoSQL vs SQL» проста: поля с радиобаттоном, со шкалой и free-text. Но пользователь может создать сложную форму. Например, из Personal Information или Employee Details, где есть табы: ФИО, дата рождения, опыт работы, технологии и т.д.
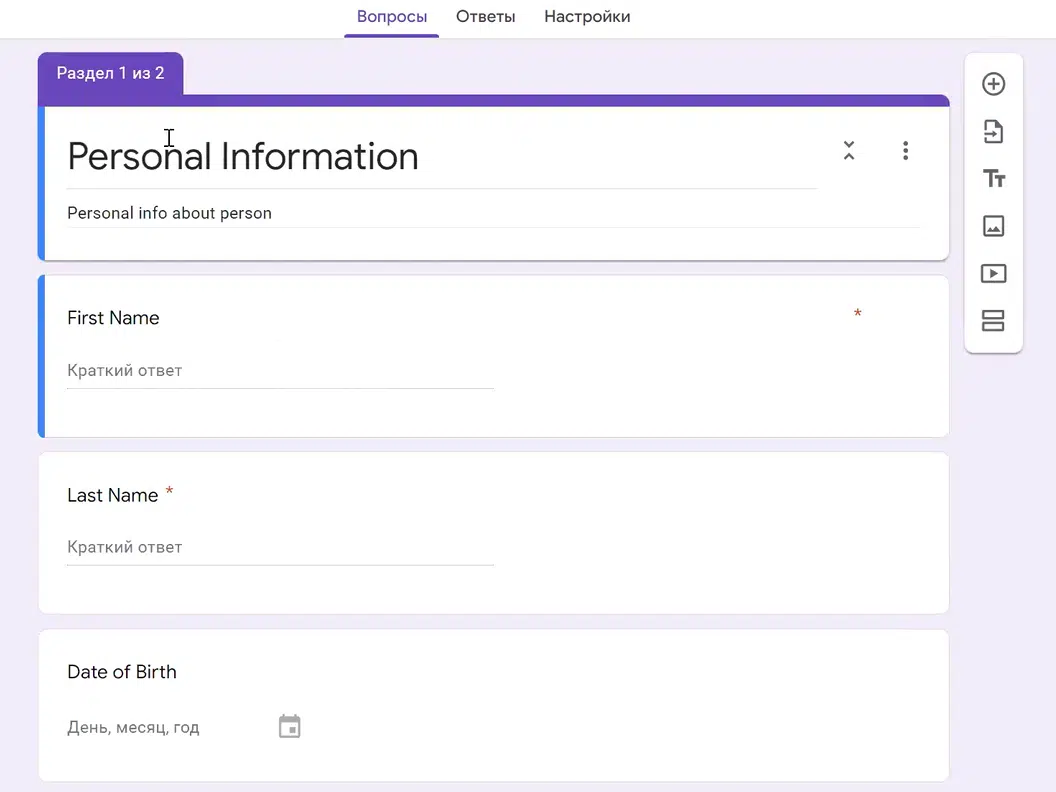
Если бы мы решали эту задачу в реляционной парадигме, было бы очень сложно создать схему БД. Вы ведь не знаете, сколько филдов будет, какие филды будут созданы в будущем, как будет расширяться их функционал и т.д. Именно здесь пригодится MongoDB.
Нажмите, чтобы рассмотреть
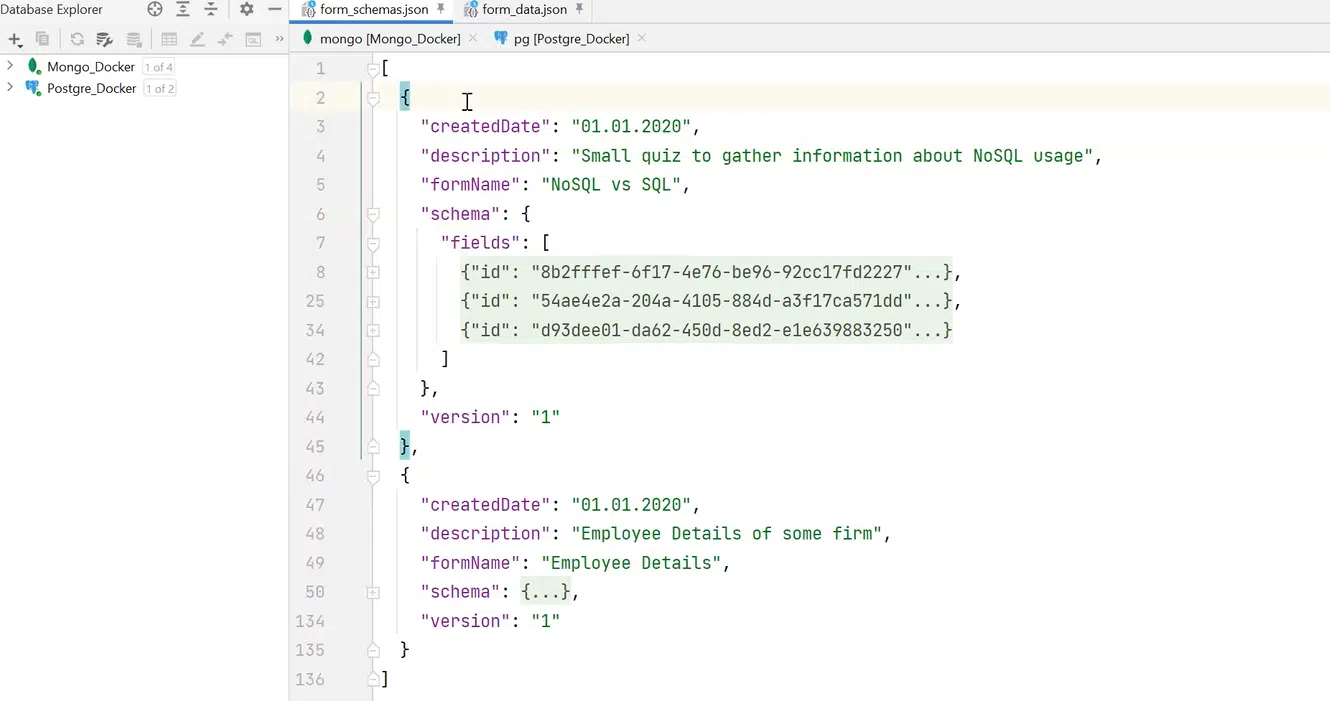
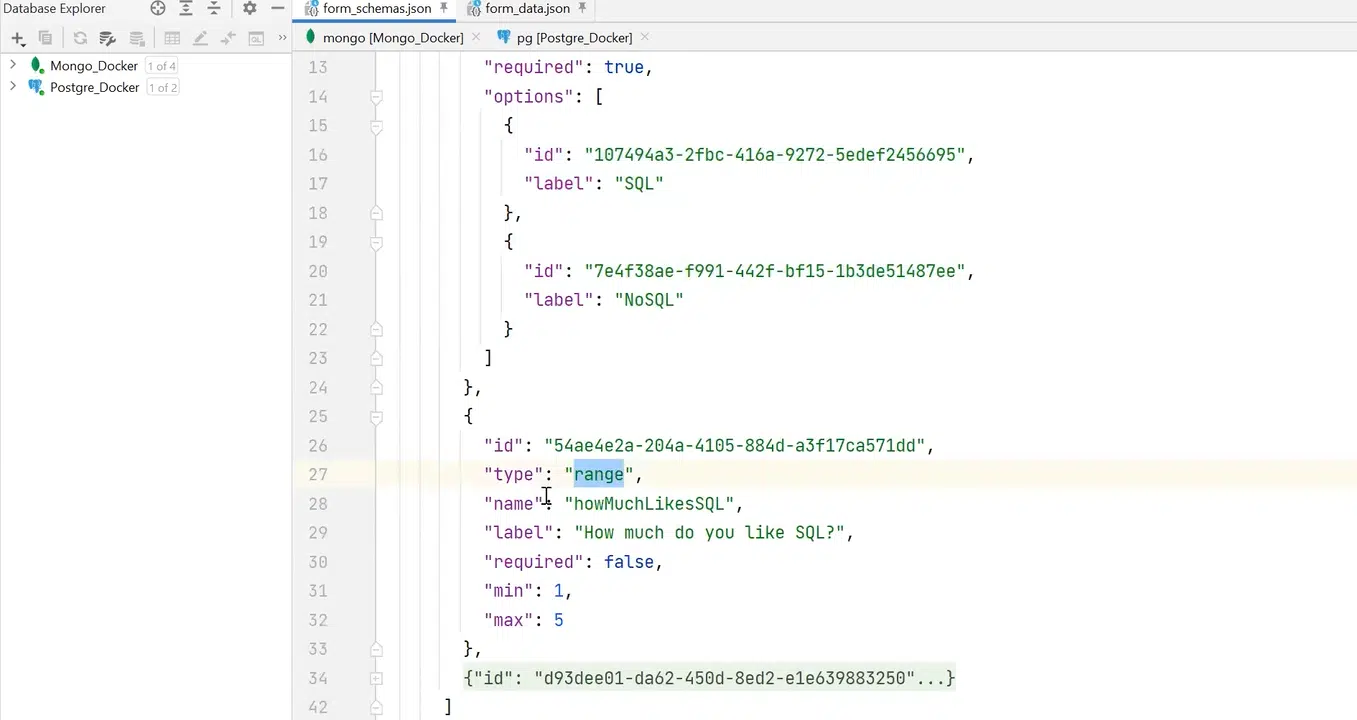
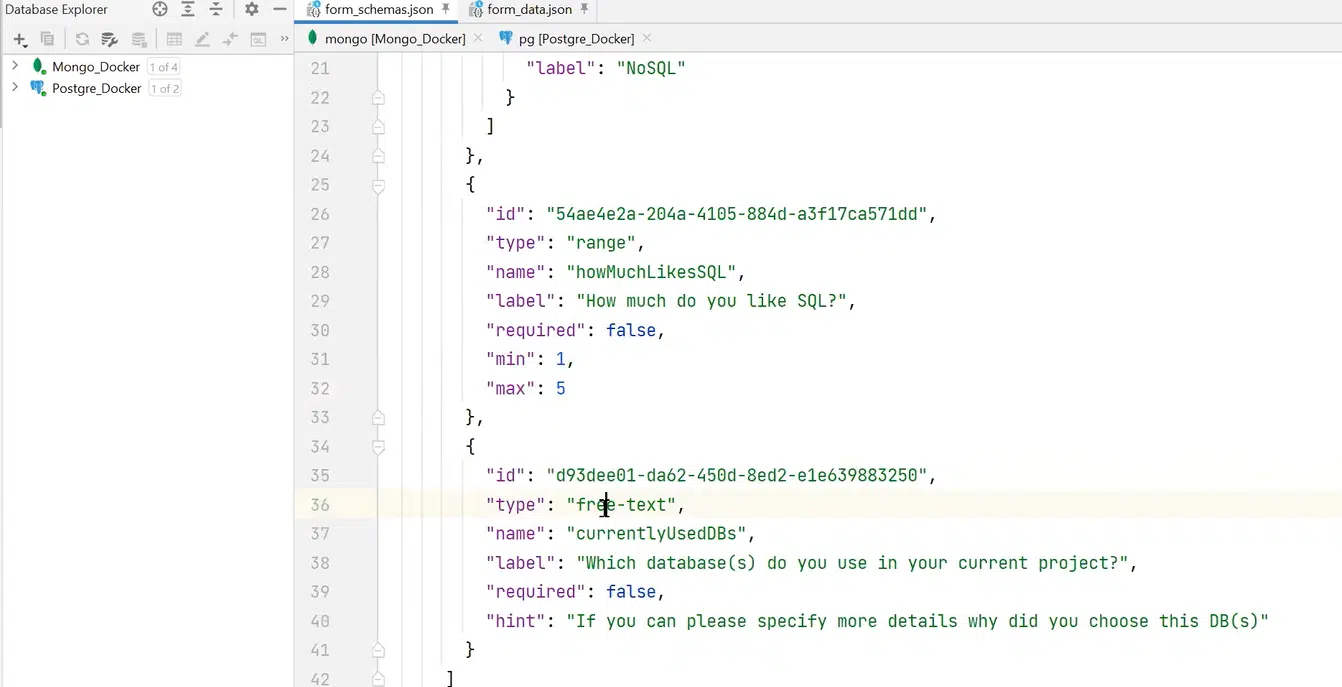
Для решения проблемы можно создать form schema, описывающую структуру и возможные данные. К примеру, в form schema есть служебные поля: createdDate, description, название формы. В поле schema будет набор филдов, которые описывает схема. К примеру, есть филд single-choice с полями name и options. При этом последний — это массив объектов. Также есть филд типа range с метками min и max, с простым числом, и филд free-text с каким-то hint.
Нажмите, чтобы рассмотреть
Нажмите, чтобы рассмотреть
Предположим, что нам нужна не столь сложная форма Employee Details. Можно создать field type с названием field-group, у которого будут свои филды — это будет эдакая рекурсивная структура. Там может быть free-text, number, date — и так же со вторым табом.

Нажмите, чтобы рассмотреть
Идеально все это хранить в JSON, а ответы — в другом формате. К примеру, у нас есть fillDate, информация о том, что мы заполнили, и поле data, где все нужные данные заполняется в соответствии с описанной схемой.
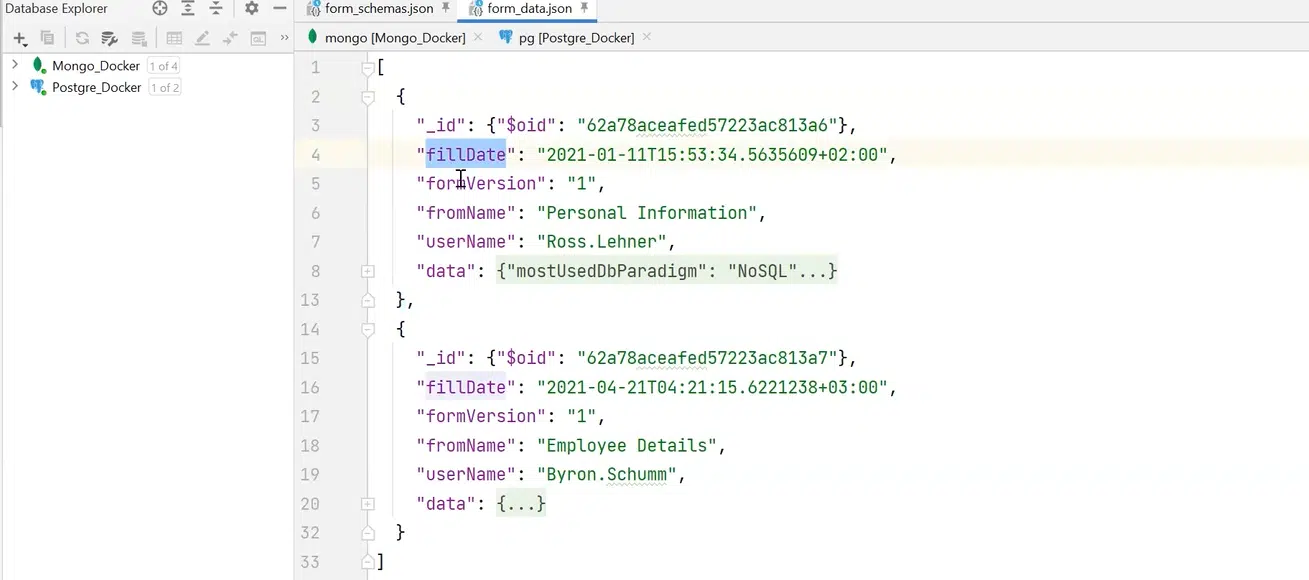
Нажмите, чтобы рассмотреть
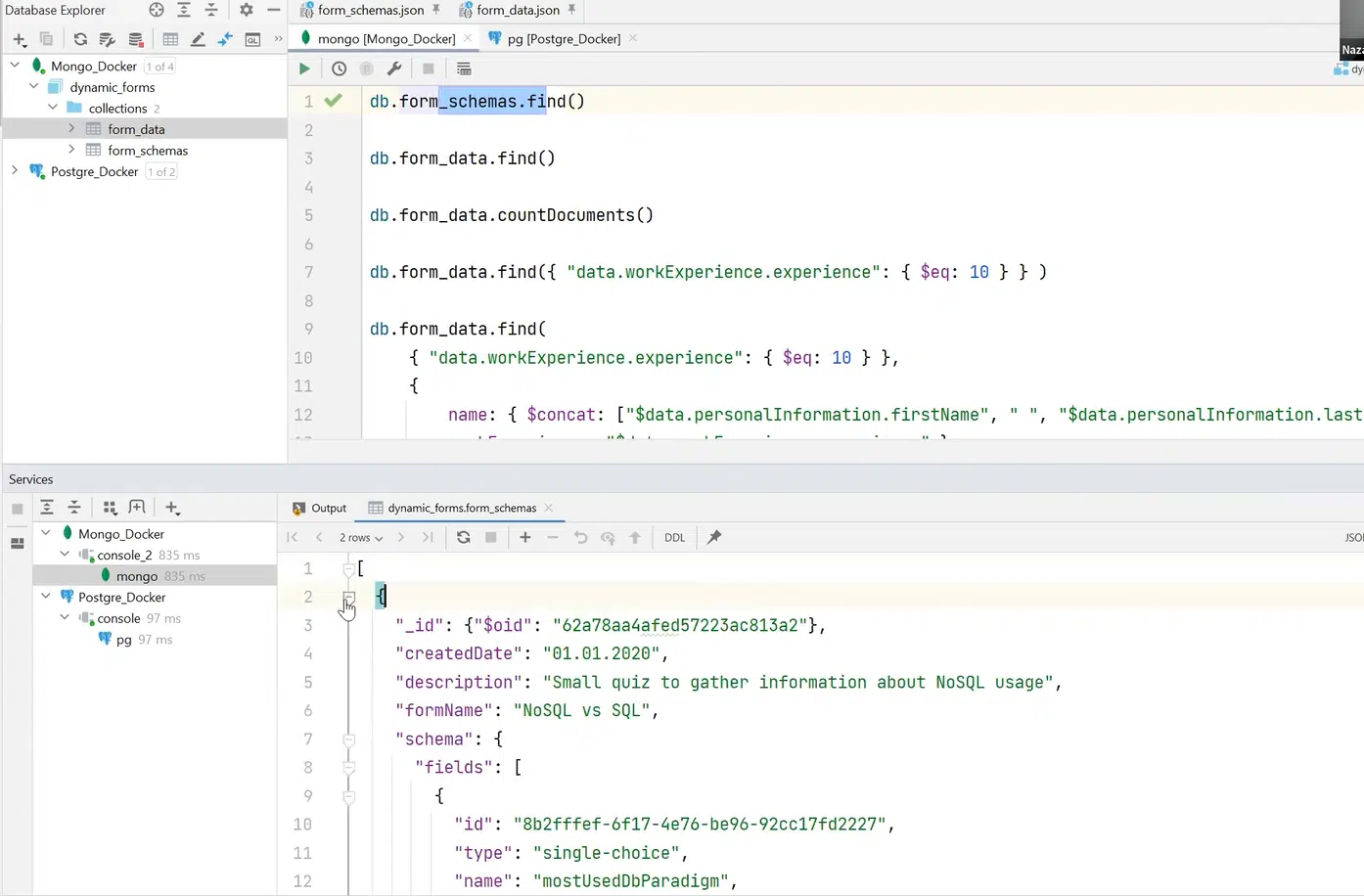
Как это реализовать в MongoDB? В этой БД есть такое понятие, как коллекции. Если сравнить это с реляционным миром, то это таблицы, но с одним очень важным отличием. В коллекции может лежать что угодно. Например, я создал коллекции form_schemas и form_data для одного и другого JSON-файлов соответственно.
Нажмите, чтобы рассмотреть
Также с помощью API и Query-синтаксиса в Mongo я могу задать поиск всех имеющихся form_schema и получить список документов. В нашем случае их два. Это те же определенные выше form_schema.
Нажмите, чтобы рассмотреть
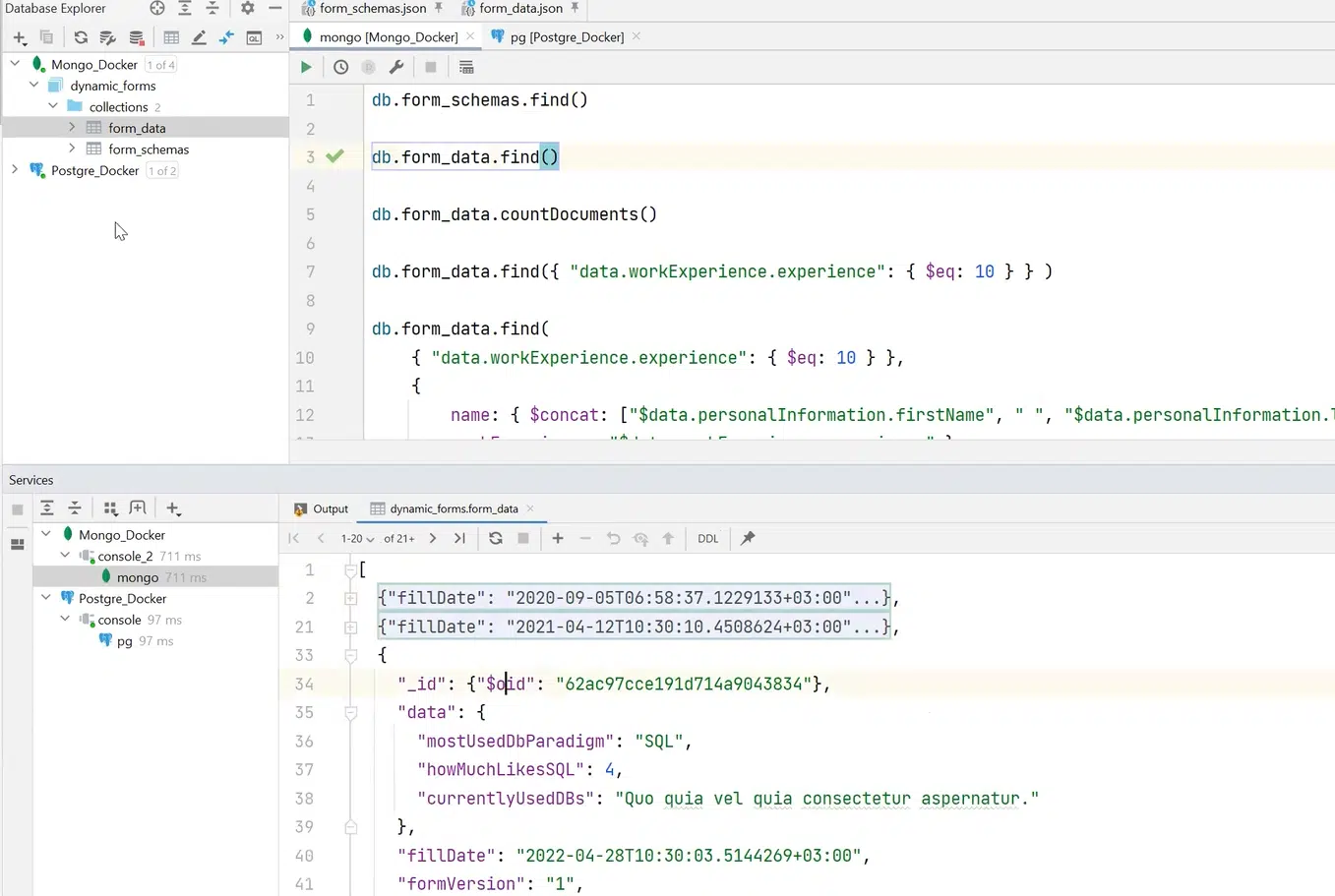
Также я могу получить все form_data и документы, относящиеся к этой коллекции.
Нажмите, чтобы рассмотреть
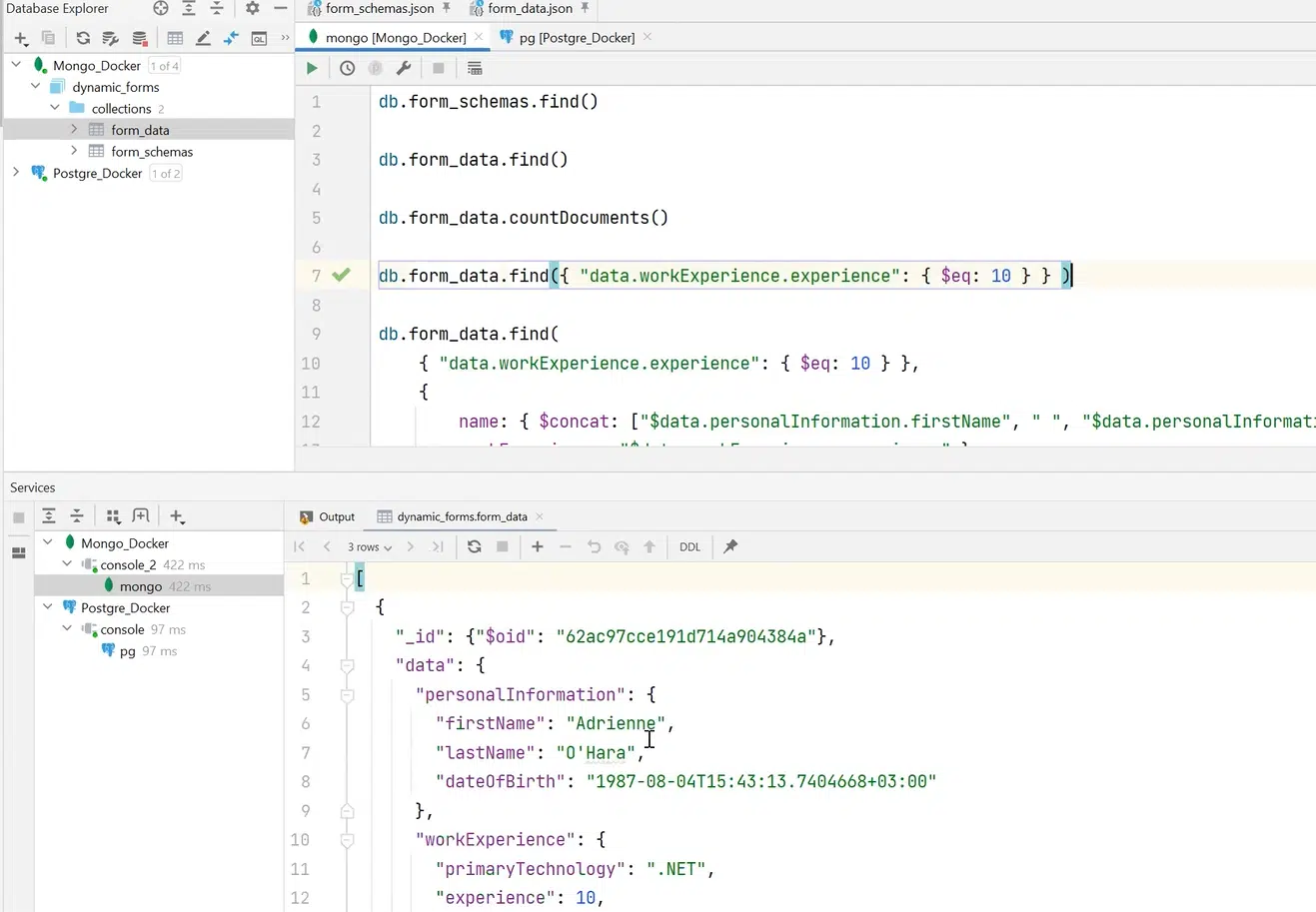
Кроме того, можно создавать и запросы. К примеру, нужно выбрать специфическую form_data — только те данные, где workExperience 10 лет. С помощью специального синтаксиса и инструментов MongoDB можно найти людей с опытом 10 лет.

Нажмите, чтобы рассмотреть
Если эти филды не нужны, можно расширить запрос и сделать выборку нужных полей. К примеру, name и workExperience.
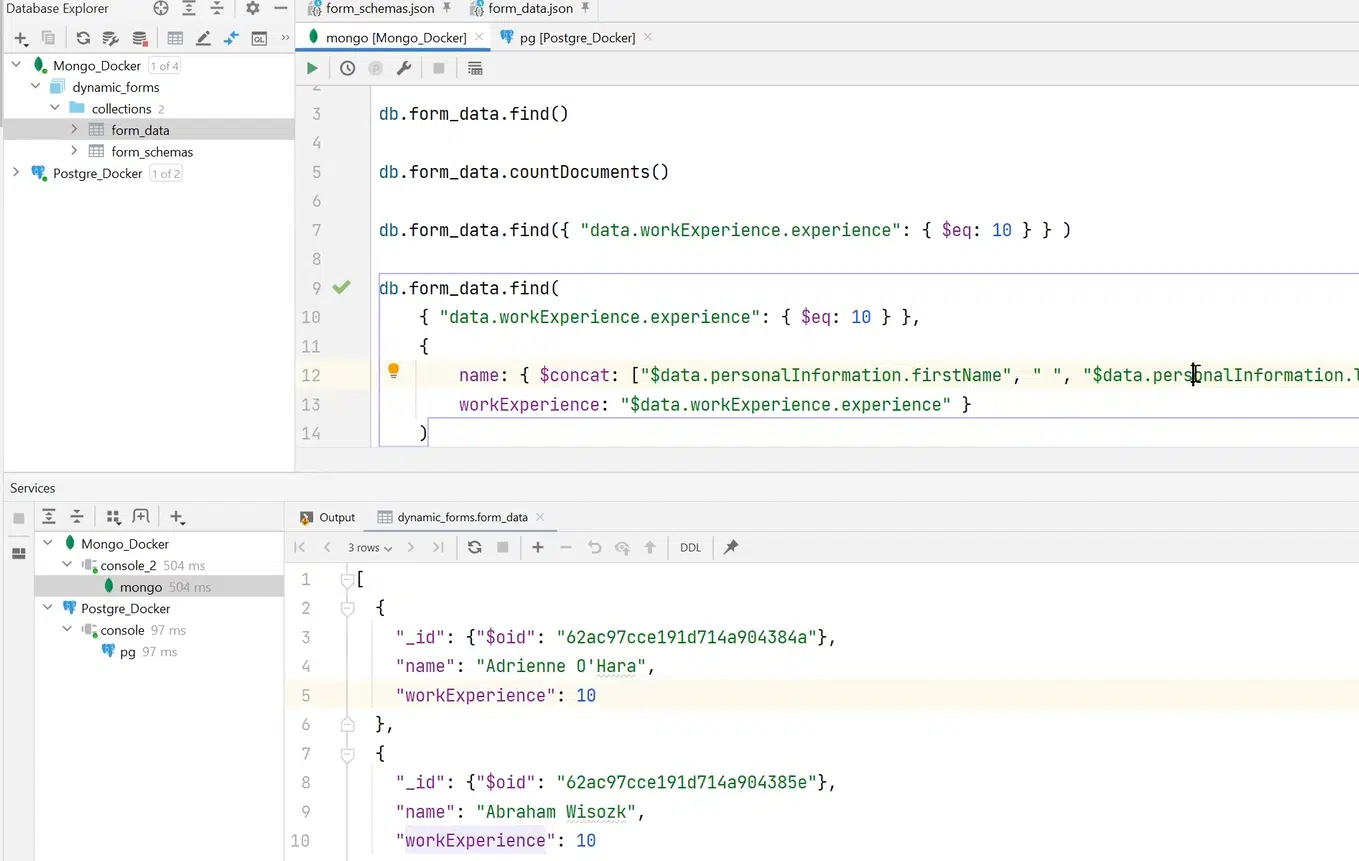
Нажмите, чтобы рассмотреть
Важно помнить, что коллекции — schemaless. Вам не нужно инсертить данные, подпадающие под схему. Это может быть рандом. К примеру, как объект на иллюстрации ниже. Такой запрос выполняется без проблем:
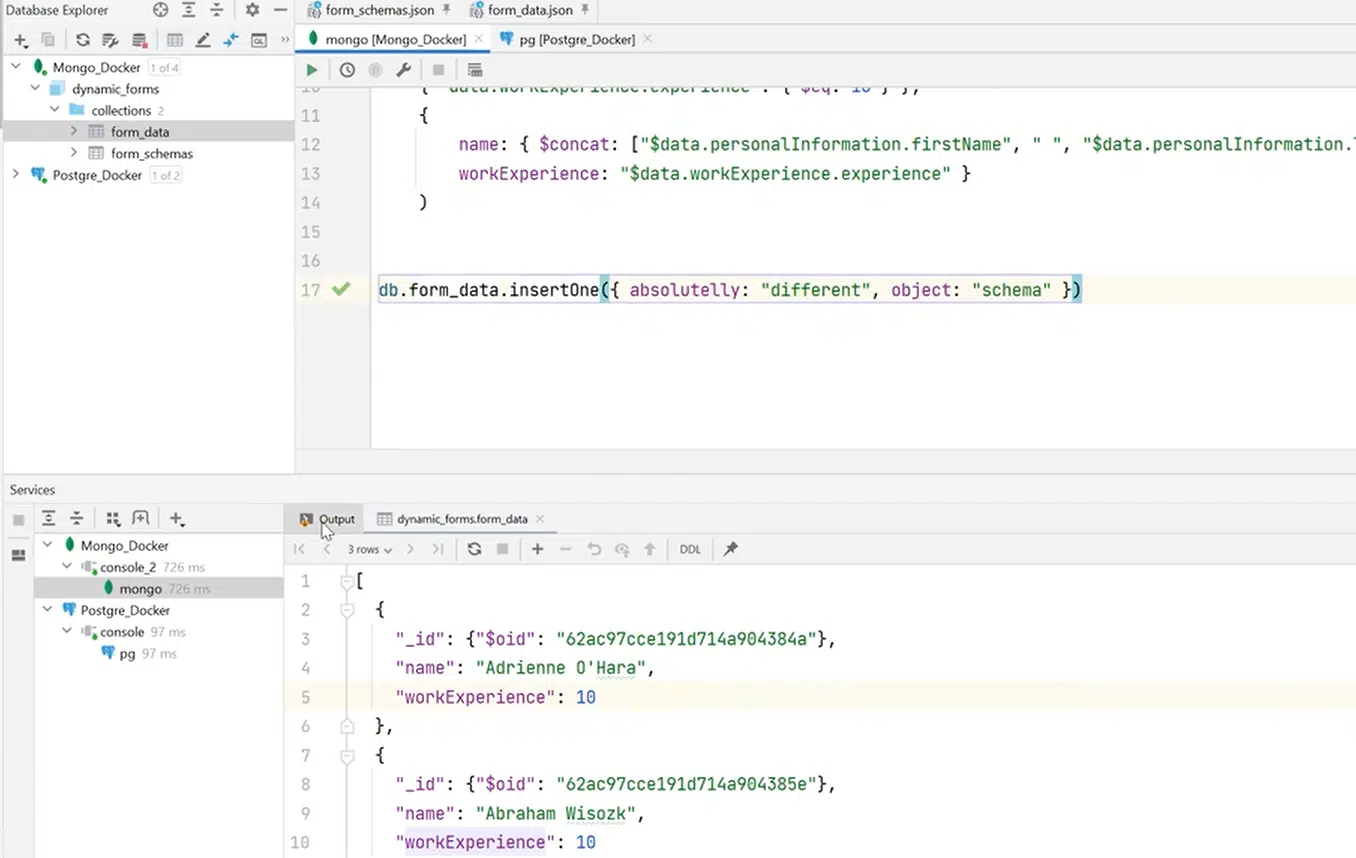
Нажмите, чтобы посмотреть
Преимущества и недостатки NoSQL
Как и любое другое решение, у нереляционных баз данных есть положительные и отрицательные черты. Если обобщить разные модели NoSQL, то среди их преимуществ можно выделить:
- Масштабирование. Обычно выполняется благодаря PartitionKey. Это фрагмент данных, о котором известно, что он находится в одном месте. В этом сущность горизонтального масштабирования. Если мы кладем данные заранее, потому что мы знаем PartitionKey, масштабирование будет почти безграничным.
- Лишение Object-relational impedance mismatch. На примерах MongoDB я показал, что у данных может быть нужная схема и структура. Для этого не нужно писать сложные джойны или моделировать данные не так, как вы их используете.
- Schemaless. В одну коллекцию можно инсертить объекты любой формы так, как вам удобно. Хотя, конечно, это может быть и недостатком NoSQL.
По-моему, главные недостатки нереляционных баз данных таковы:
- Частичная поддержка транзакций. Различные парадигмы NoSQL и отдельные базы данных частично поддерживают концепты ACID, но в целом их нет. Ими пожертвовали ради масштабирования системы.
- Отказ от реляционности. Если у вас нет джойнов, то у вас появляется… дублирование данных. Здесь важно понимать: это норма для подобной системы — не баг, а фича, как говорится. Поэтому нужно моделировать данные так, чтобы подобная система была настолько эффективна, насколько это реально.
- Ограничены возможности поиска по сложным критериям. У NoSQL есть find, как я упоминал в примере. Но в глобальном концепте масштабирования есть проблемы. Если данные лежат на большом количестве нод, то для поиска по определенному критерию без Partition нужно обойти буквально все ноды. Это фактически нивелирует масштабирование как таковое.
Что касается концептов нереляционных баз данных, здесь следует учитывать, где вы будете использовать ту или иную базу. Ведь что хорошо для одного разработчика не всегда хорошо для другого. Это ярко показывает использование NoSQL-моделей теми или иными компаниями.
К примеру, на Key-Value Store базируется Redis, стандарт для fileload-систем. Column Based встречается в продуктах Facebook, Instagram и Netflix для предикшенов, улучшения Machine Learning и фильтрации контента. На Graph Databases построен каталог eBay. Document Databases — наиболее распространенный тип NoSQL-баз. С ним можно смоделировать любую структуру данных и CMS.
Использование JSON в реляционных базах данных
Благодаря своим возможностям масштабирования нереляционные базы данных достаточно популярны, но они не могут стать идеальным решением. В свое время разработчики задумались: можно ли использовать наработку из мира NoSQL и решить задачу именно в реляционной форме?
В нижеприведенном примере имеем реальные данные в поле data, которые заполняет пользователь, и схема формы в конкретном документе, а также данные-дубликаты: _id, fillDate, formVersion, fromName.
Создается впечатление, будто данные могут существовать в виде обычной таблицы в SQL, ведь их количество и качество одинаковы. Но что тогда делать с причудливым полем data?
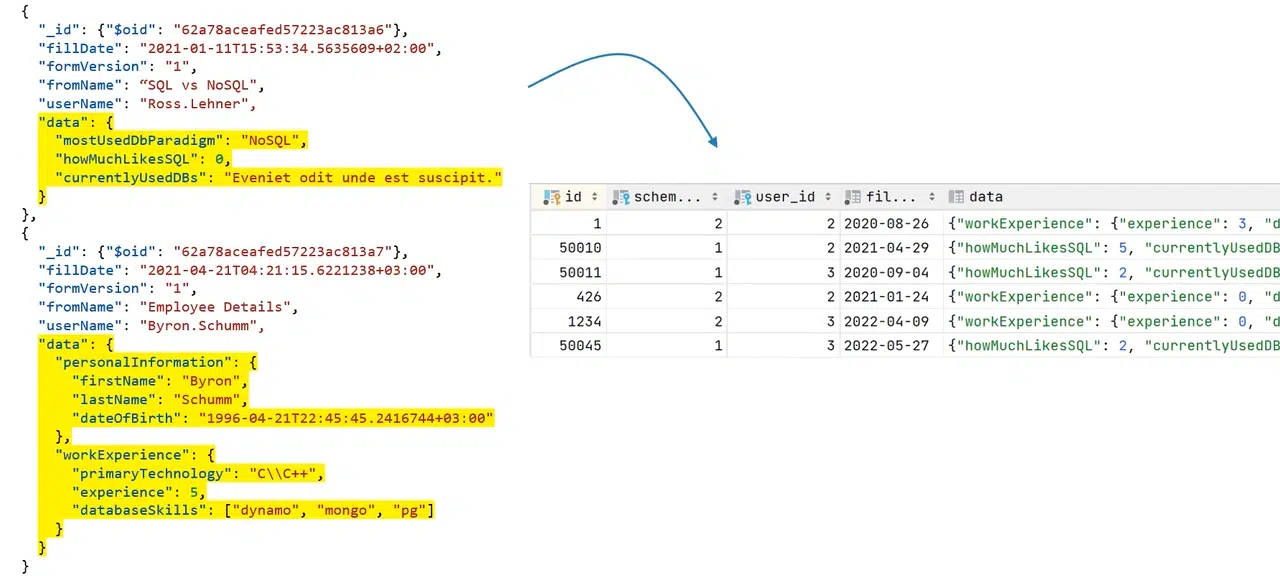
Нажмите, чтобы рассмотреть
Первое, что приходит в голову — сделать колонку data в SQL, NVARCHAR(MAX). По сути это стринга, и можно размещать все, что заблагорассудится. Но на Application Layer нужно бы валидировать, что это JSON. Если требуется поиск, это вызывает некоторые проблемы. Поэтому сегодня большинство баз данных предоставляют специальный тип данных или инструменты, которые помогают манипулировать JSON в самой базе.
Например, я возьму PostgreSQL, где такой тип данных называется jsonb. Он бинарный и поддерживает такие же операции над собой, как JSON: валидацию формата, гибкие инструменты поиска по вложенным филдам и возможность создания индекса. Давайте рассмотрим его способности на практике.
В PostgreSQL у меня есть три таблицы: users, form_schemas и form_data. Это та же структура, как и в MongoDB. По факту form_schemas — это дефиниция формы, а form_data — заполненные пользователем данные.
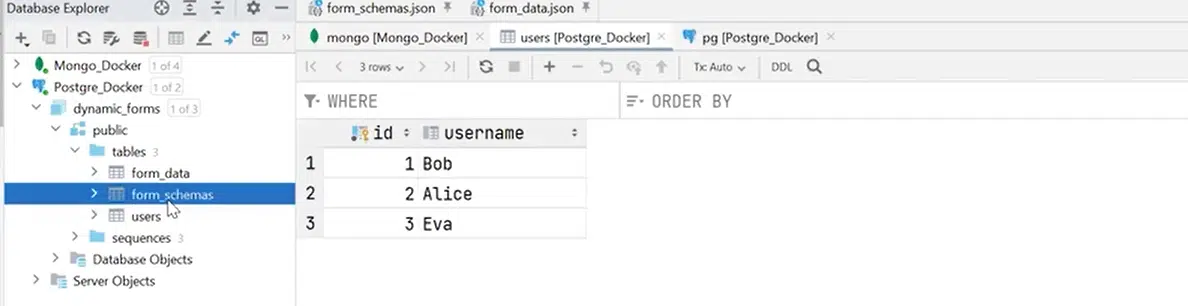
Нажмите, чтобы рассмотреть
Также можете увидеть, что у form_schemas общие поля разбиты на собственные колонки, а schema — это уже JSON.
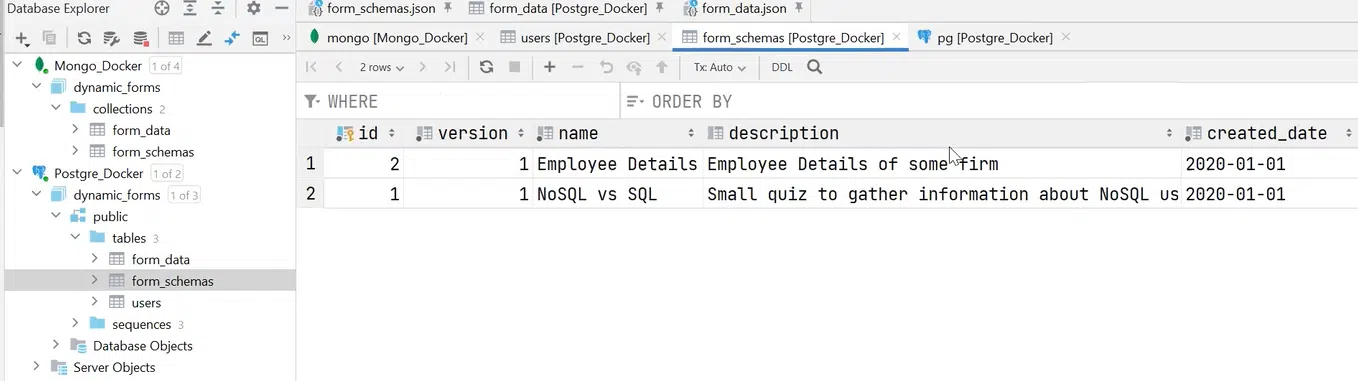
Нажмите, чтобы рассмотреть
То же можно сказать и о form_data.
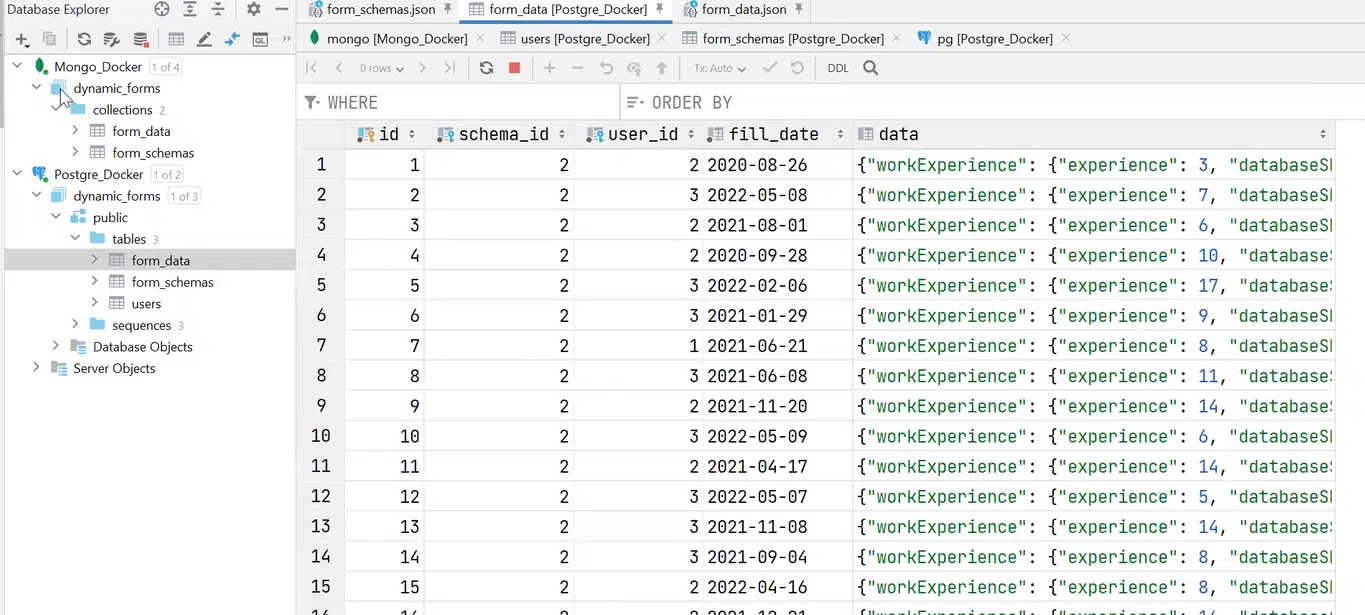
Нажмите, чтобы рассмотреть
Обратите внимание: здесь есть отдельные поля и связи — валидные foreign keys. Например, после открытия определения таблицы обнаруживается data (такой же jsonb), а в foreign keys увидеть schema_id (она указывает, к какой схеме принадлежит jsonb) и user_id (указывает на пользователя, заполнившего таблицу). Это все и обеспечивает согласованность данных.
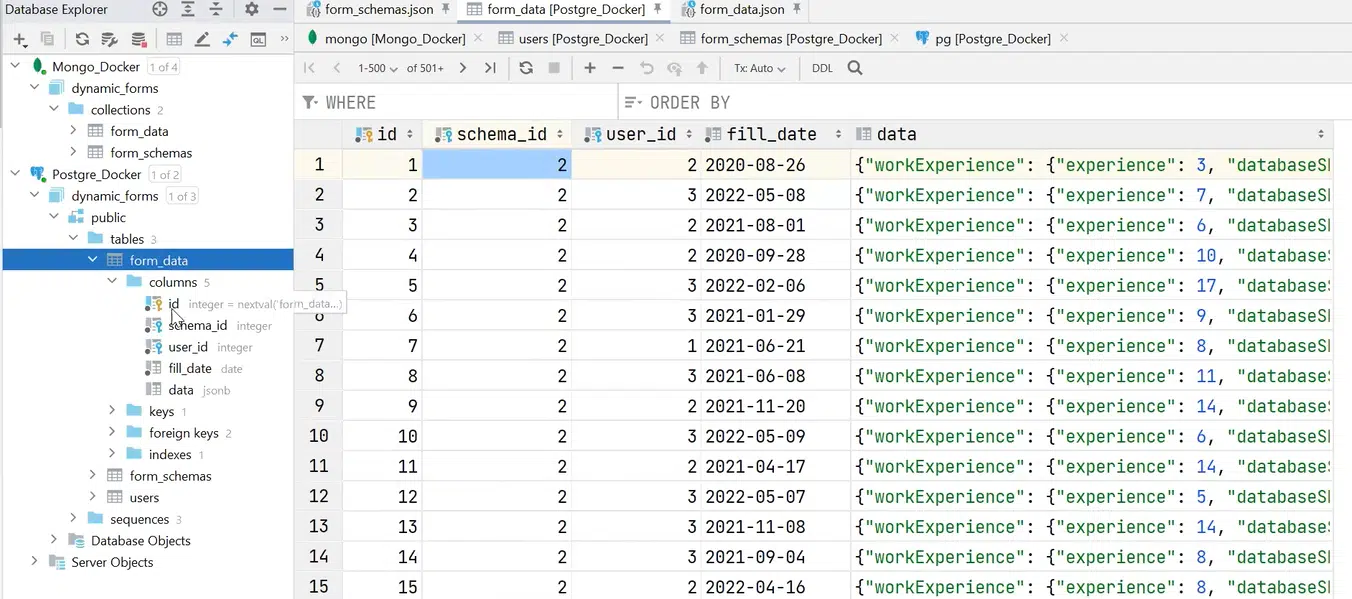
Нажмите, чтобы рассмотреть
Это также предоставляет инструменты для манипулирования датой. Прежде всего следует понять, что можно извлечь из JSON. Специальным синтаксисом со стрелкой -> можно обращаться к полям любой вложенности. Разница между одинарной и двойной стрелками в том, что две действуют как терминальная операция. То есть мы select делаем как текст, и это такая стринга.

Нажмите, чтобы рассмотреть
Можно использовать и более маленький синтаксис. Например, чтобы достучаться до personalInformation firstName, сделать это кратко и получить данные из этого поля data. К тому же это происходит очень быстро, хотя здесь 100 тыс. запросов:
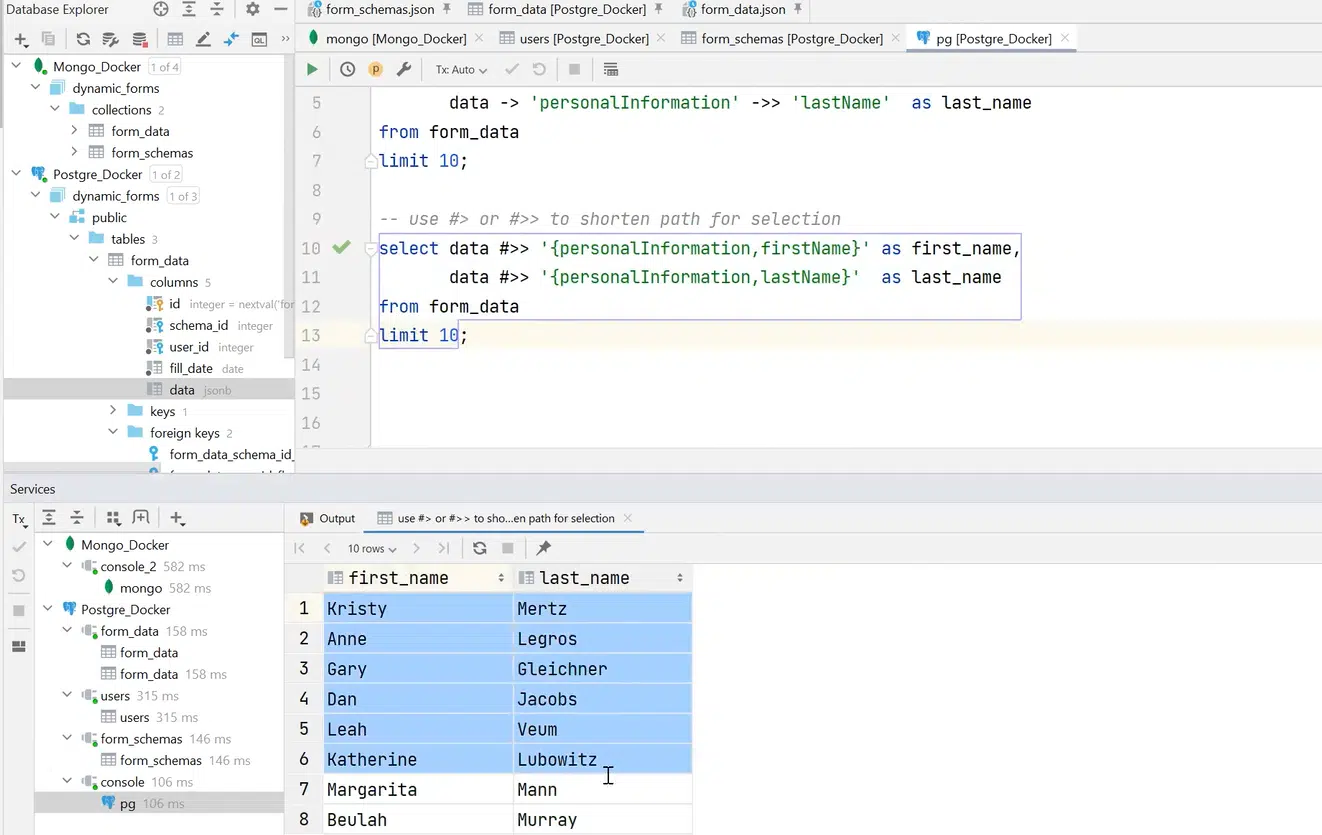
Нажмите, чтобы рассмотреть
Также можно использовать этот expression не только в select, но и в where. К примеру, нам нужно выбрать пользователей с workExperience более 10 лет. Поскольку возвращается текст, нужно конвертировать его в виде числа, но в конце концов мы получим всех пользователей с опытом работы более 10 лет.
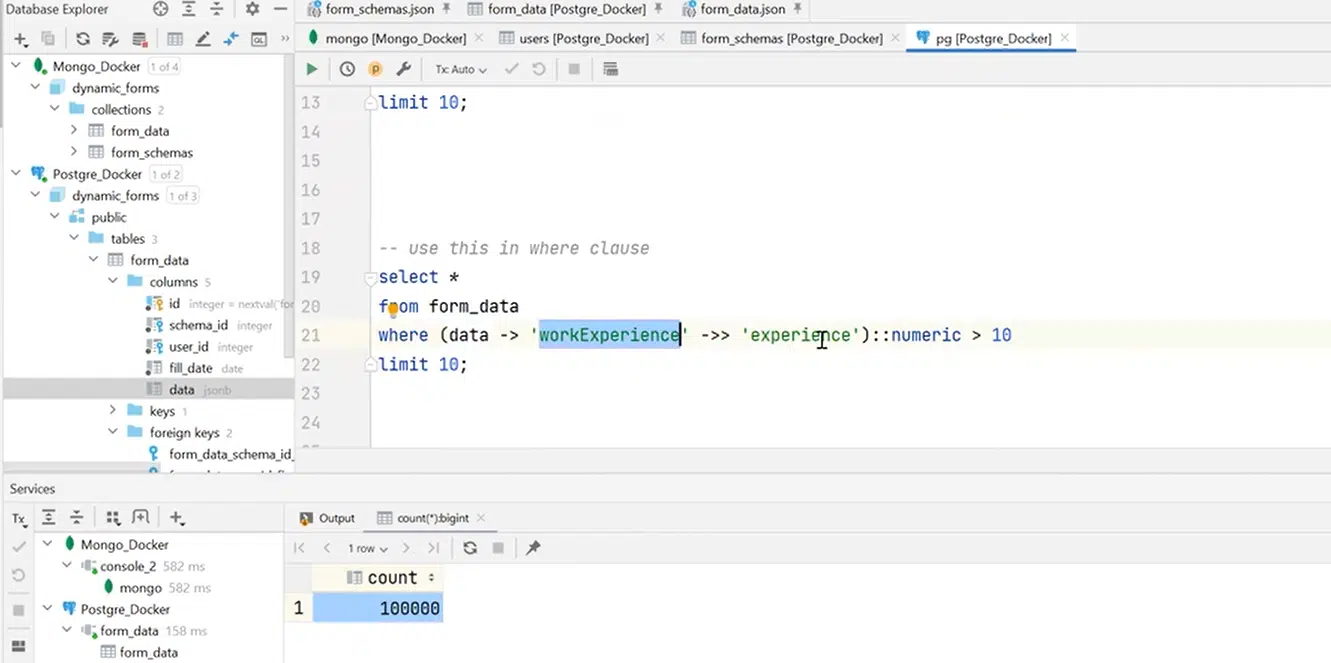
Нажмите, чтобы рассмотреть
Теперь хочу рассказать о довольно интересном операторе, который может определить contains в самих данных, в JSON. К примеру, у меня есть workExperience и databaseSkills, со знаниями конкретных БД. Я могу написать запрос, который покажет всех пользователей, знающих PostgreSQL. Это очень кстати при поиске информации по массиву.
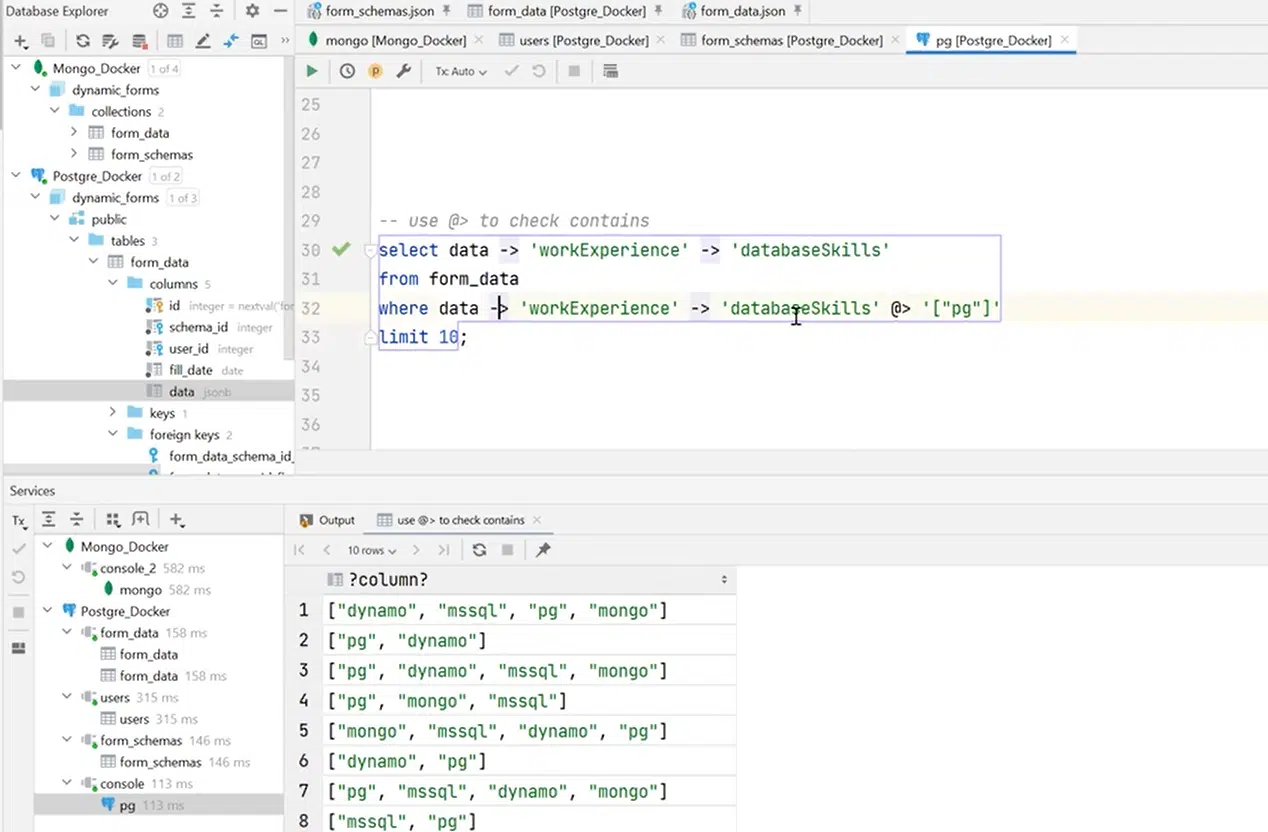
Нажмите, чтобы рассмотреть
А еще не могу не упомянуть JSONPath. Это язык запросов к JSON, подобный аналогичному концепту XMLPath в XML. Здесь есть стринг, где мы говорим, что $ – это root. Далее делаем запрос к полям в JSON.
Допустим, нужно выбрать firstName, lastName, databaseSkills у тех пользователей, у которых в databaseSkills более двух скиллов. Если мы не хотим выбирать значение стрелочками, можно обратиться в синтаксис и ввести оператор @@, чтобы использовать where. А все потому, что jsonb_path_query — это и есть наши функции:
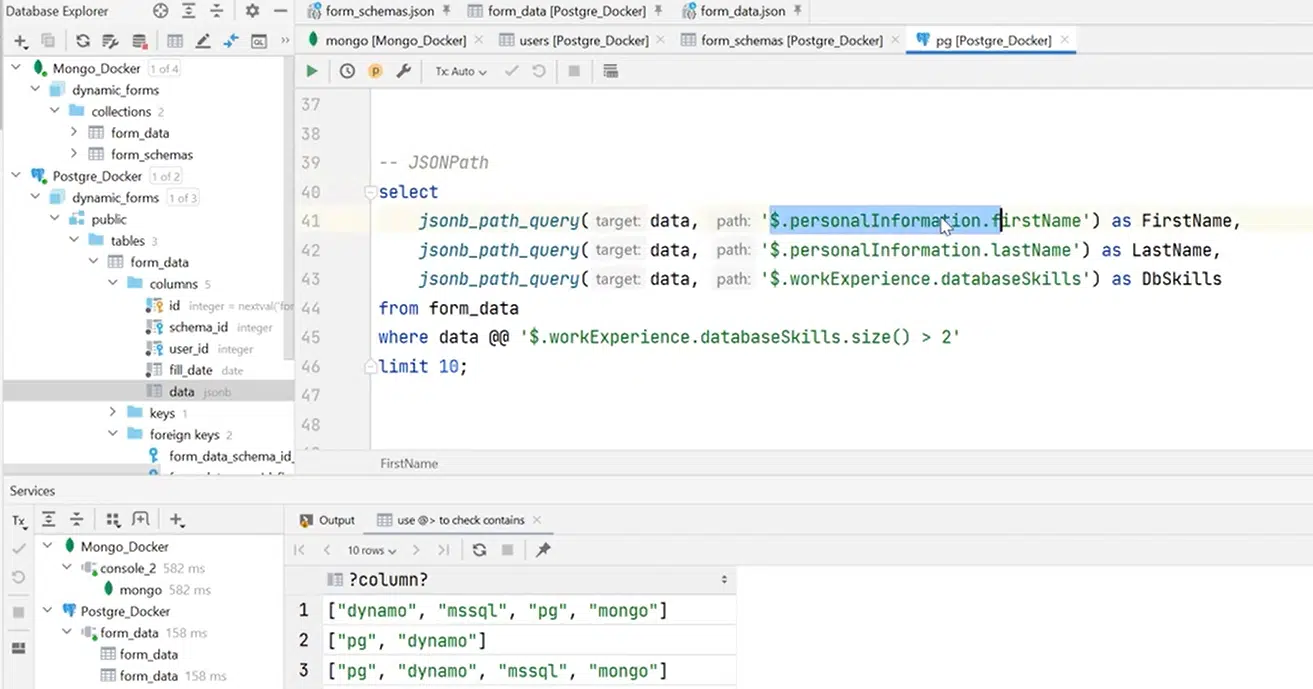
Нажмите, чтобы рассмотреть
Как видите, внутри стринги у меня есть функция size. Она встроена в спецификацию JSONPath и может выдать количество частей в массиве. Для этого добавлен оператор >, больше, чем какое-либо число. В нашем случае это 2. В результате именно благодаря этому PostgreSQL обработал эту стрингу, понял, что от него хотят, и вытащил нужные данные.
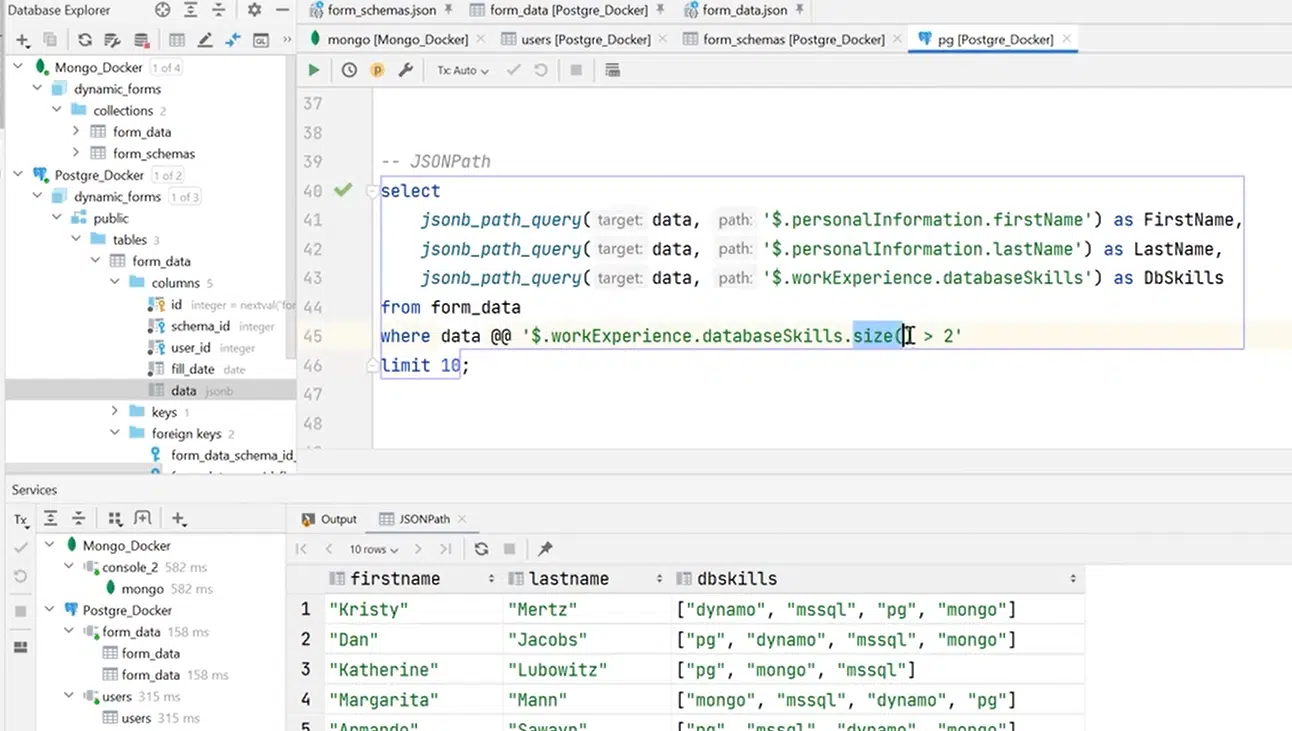
Нажмите, чтобы рассмотреть
И напоследок — индексы. Их можно создавать на данные внутри JSON для того, чтобы обработка запросов к такому файлу проходила быстрее.
К примеру, добавляю индекс на workExperience и потом хочу найти всех пользователей, у которых этот параметр составляет 10 лет. Это достаточно просто, но подчеркну: индекс создается на стринге, а не на число. Иначе индекс вообще не будет проработан. Это хорошо отображается на execution plan. На иллюстрации ниже можете видеть, что PostgreSQL для поиска пользователей сделал Seq Scan. Это заняло чуть больше 129 миллисекунд:
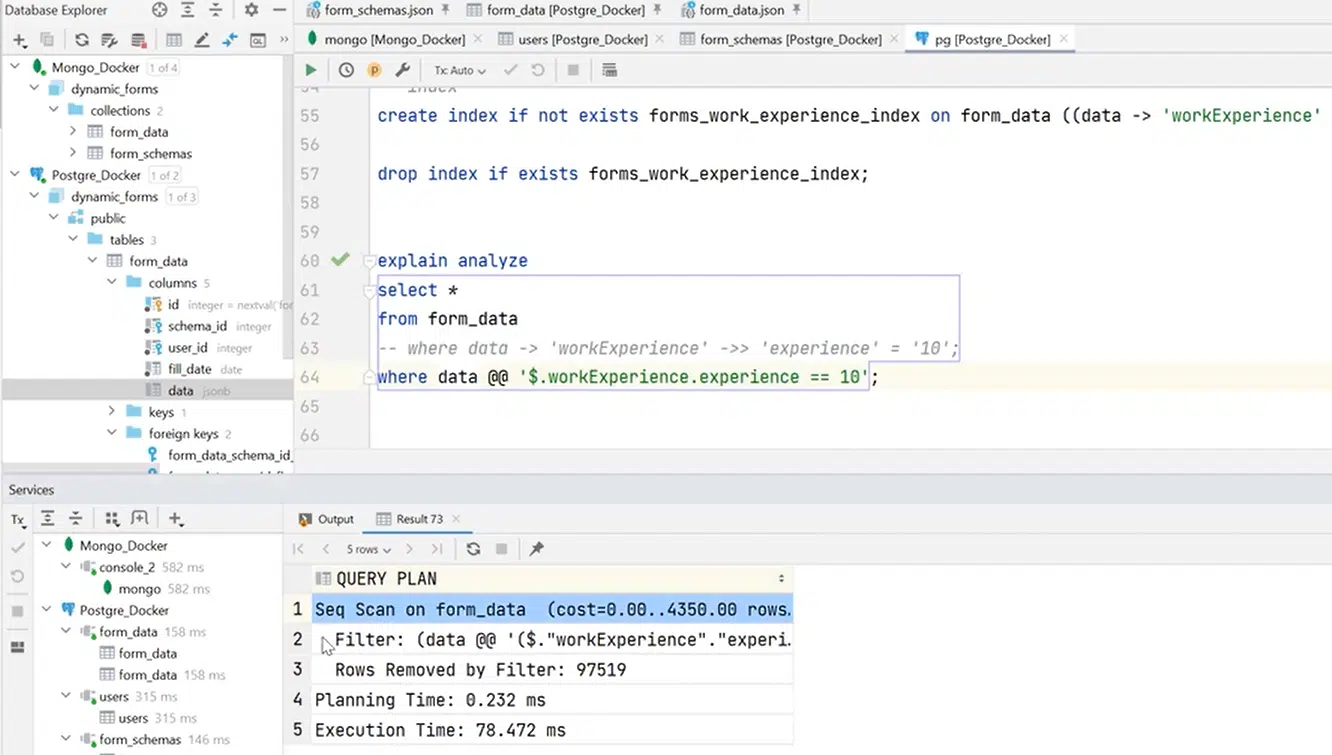
Нажмите, чтобы рассмотреть
Если добавить индекс и выполнить тот же запрос, то все пройдет как Bitmap Heap Scan и данные будут получены за 9 миллисекунд. Выигрыш в скорости больше, чем в 10 раз!
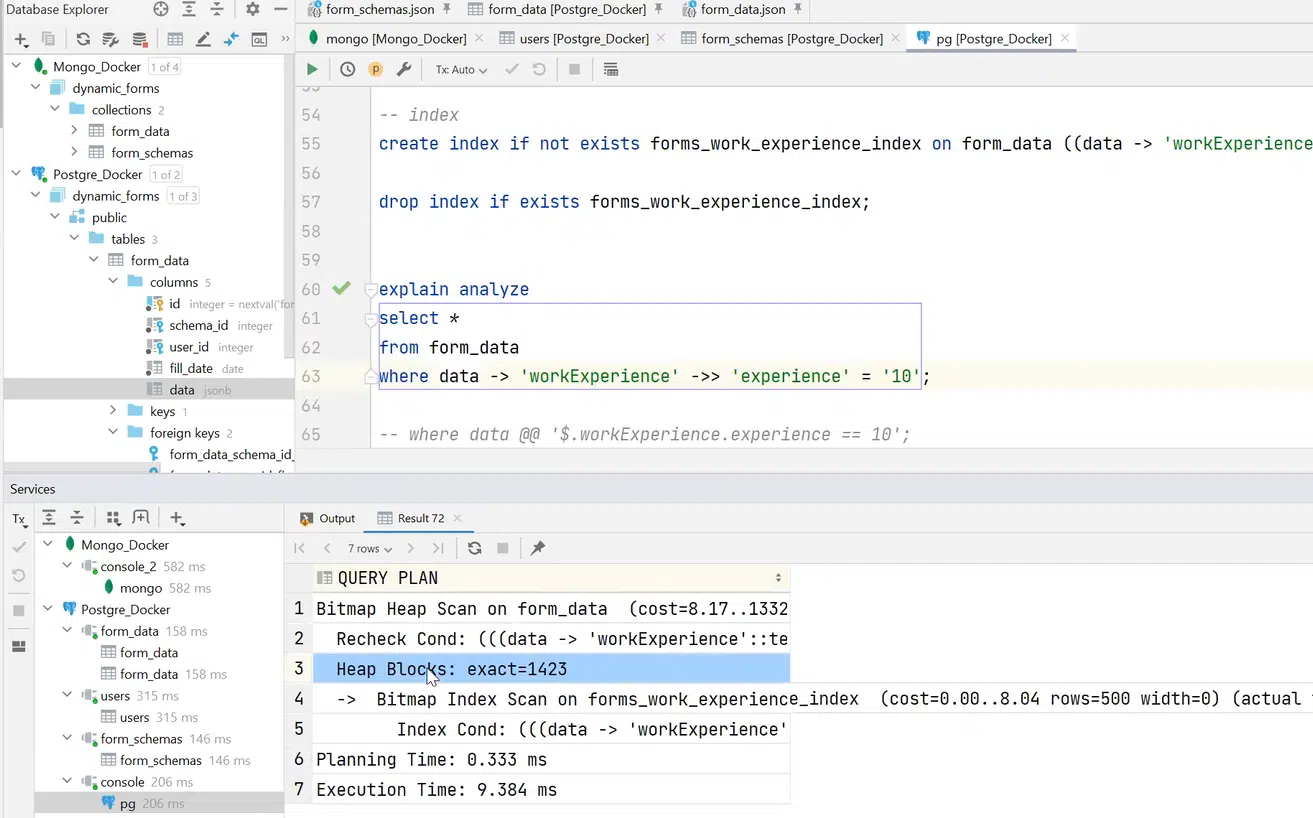
Нажмите, чтобы посмотреть
К сожалению, это не работает с хорошим JSONPath-синтаксисом. С ним запрос будет поступать через Seq Scan за 78 миллисекунд. То есть улучшение есть, но уже не столь значительно.

Нажмите, чтобы рассмотреть
Чтобы индекс заработал на таком экспершене, нужно создать другой тип — на все поле JSON. В PostgreSQL это gin-индекс. Указанные экспершны по факту работают как Full-Text Search. При их выполнении запускается Bitmap Heap Scan, а затраты времени будут составлять всего 21 миллисекунду.

Нажмите, чтобы рассмотреть
И хотя это все я показал на примере PostgreSQL, все большие вендоры баз данных так или иначе поддерживают этот подход. Они ведь видят спрос со стороны разработчиков на адаптацию JSON в некоторых кейсах.
Например, в коде ниже приведен синтаксис MsSQL. Здесь также есть функции OPENJSON и JSON_QUERY с использованием JSONPath. Похожие решения присутствуют в MicrosoftSQL и Oracle.
Преимущества и недостатки JSON в реляционных БД
NoSQL-подход для реляционных баз данных обладает полезными свойствами, среди которых:
- Старый-добрый SQL. Мы можем не отходить от принципов и методов, к которым мы привыкли в работе и которые нам нравятся.
- «Совместимость» с реляционной моделью. Можем производить джойны и селекты, использовать в Query where и внутренние JSON-поля.
- Больше инструментов для моделирования данных. Новый подход позволяет взять все лучшее от SQL и NoSQL.
Относительно недостатков использования JSON описанным способом:
- Снижение эффективности в некоторых случаях. Для использования типа данных, подобного jsonb, и добавления индекса требуется больше ресурсов. NoSQL-БД, как MongoDB, будет более производительным для такой задачи.
- Не добавляет масштабирование. Главное преимущество мира NoSQL не ложится в новую модель — мы остаемся в реляционной парадигме. Однако теперь способны делать в нем немного больше.
Выводы
Подводя итоги, скажу, что использование JSON в реляционной модели будет оправдано в нескольких случаях:
- Существующие проекты на SQL. Если в вашем приложении с реляционной БД появляется фича, нуждающаяся в динамических данных, NoSQL-методы точно пригодятся.
- Динамические конструкторы чего-либо с учетом масштабирования. Если вы не знаете, какими объектами будет оперировать пользователь и какие связи будут между ними, попробуйте следующие принципы. Как правило, это те же формы, рабочие флоу и прочее из того, что пользователь может создавать с помощью вашего инструмента.
- Оптимизация, когда реляционная модель является проблемой. Иногда разработчики могут так заиграться с нормализацией данных в SQL, что количество таблиц и связей станет слишком большим. Это может привести к остановке некоторых операций по записи или чтению. В таком случае из-за множества джойнов не спасут никакие индексы. Поэтому для денормализации данных нужно обратиться к NoSQL-подходу. Вместо миллионов связей вы будете иметь форму JSON в одной колонке. При этом, если у вас были фильтрации, они останутся благодаря новым функциям и синтаксисам БД.
Существует еще множество примеров задач, которые можно решать по следующему подходу:
- во-первых, это Metadata Forms — сложные динамические формы;
- во-вторых, BPMN Workflows, где все степи описаны в JSON;
- и в-третьих, это CMS.
Здесь вы обеспечите пользователю приложения возможность создания любого динамического контента. Во всяком случае всегда помните: то, что хорошо сработало для кого-то, не факт, что подойдет в вашем случае. Внимательно рассматривайте разные кейсы, экспериментируйте, и все у вас получится.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: