


В предыдущей части я рассказал самое главное, что следует знать бизнес-аналитику о нереляционных базах данных. Мы уже немного затронули тему проектирования БД. Теперь разберем теорию на практике.
Особенности DynamoDB
На проектирование базы данных оказывает влияние ее разновидность. Для примера возьмем DynamoDB. Эта база разбита на partitions – ячейки, которые можно назвать узлами. Каждый узел – это SSD объемом 200 ГБ. Однако таких узлов множество. Все данные определенным образом распределяются между ними. И здесь DynamoDB дает несколько преимуществ:
- пропускная способность до 7 миллионов транзакций в секунду (при идеальных условиях);
- Eventually Consistency на уровне 10 мс (опять же, при условии идеальной организации данных);
- автоматическая репликация данных;
- автоматическое масштабирование БД.
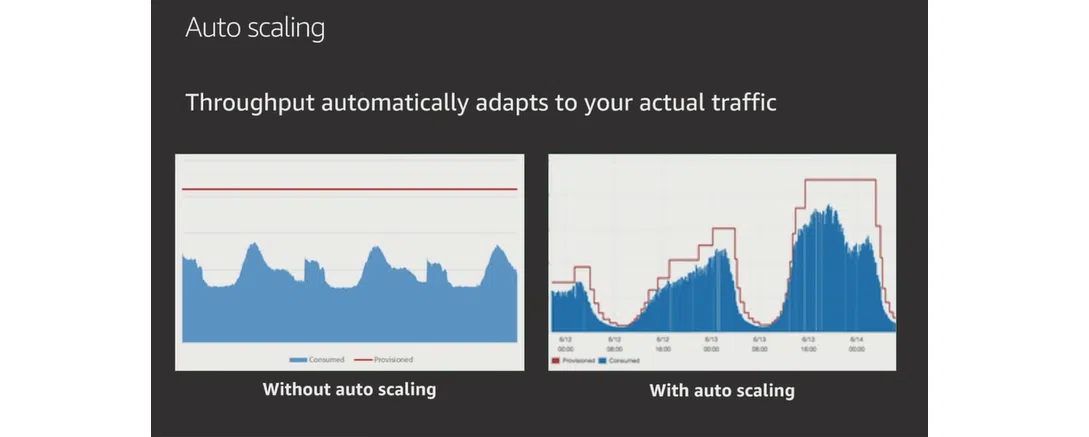
DynamoDB отличает оптимизированная схема работы при пиковых нагрузках. В SQL-модели следует заложить высокие вычислительные мощности вдоль красной линии на графике ниже. Хотя на практике они могут и не использоваться. DynamoDB обладает более гибкими возможностями. База выбирает мощности по кривой, что соответствует реальной нагрузке «здесь и сейчас». Это экономит ресурсы, уменьшает затраты на базу данных и является идеальным подходом для проектов с вычислениями.
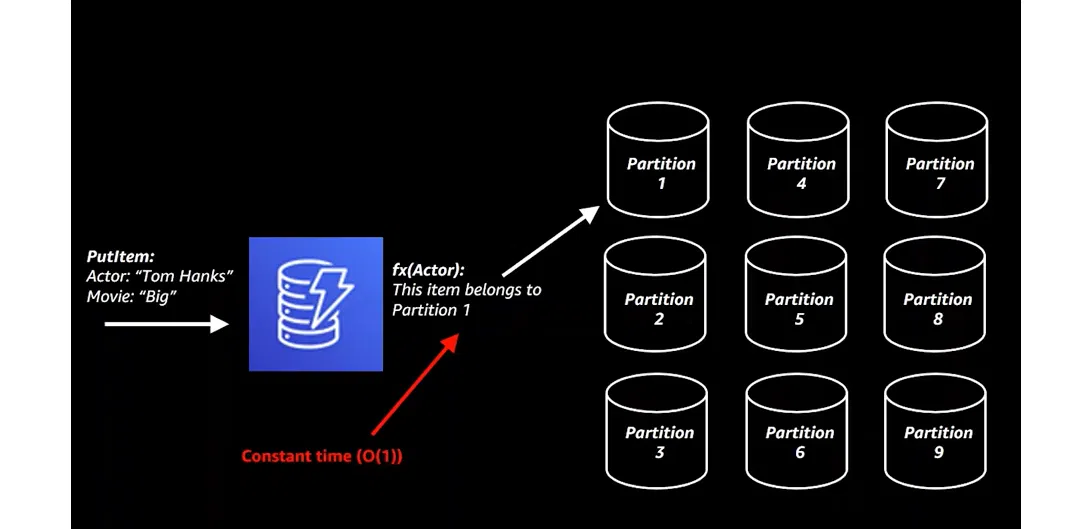
Принцип работы DynamoDB достаточно прост: сначала выполняется хеширование данных или разбивание на ячейки. Такая операция проходит по принципу Constant Time, то есть без задержки при любом количестве запросов. При обращении в БД запрос хешируется с определенного ключа. Так база понимает, в какой конкретно ячейке искать необходимые данные.
 Первые шаги в моделировании такие же. Прежде всего, нужно построить дата-модель, создать перечень сущностей и задать связи между ними: друг к другу, один ко множеству, множество ко множеству. Различия возникают после построения дата-модели. На данной стадии следует обрисовать упомянутые шаблоны доступа.
Первые шаги в моделировании такие же. Прежде всего, нужно построить дата-модель, создать перечень сущностей и задать связи между ними: друг к другу, один ко множеству, множество ко множеству. Различия возникают после построения дата-модели. На данной стадии следует обрисовать упомянутые шаблоны доступа.
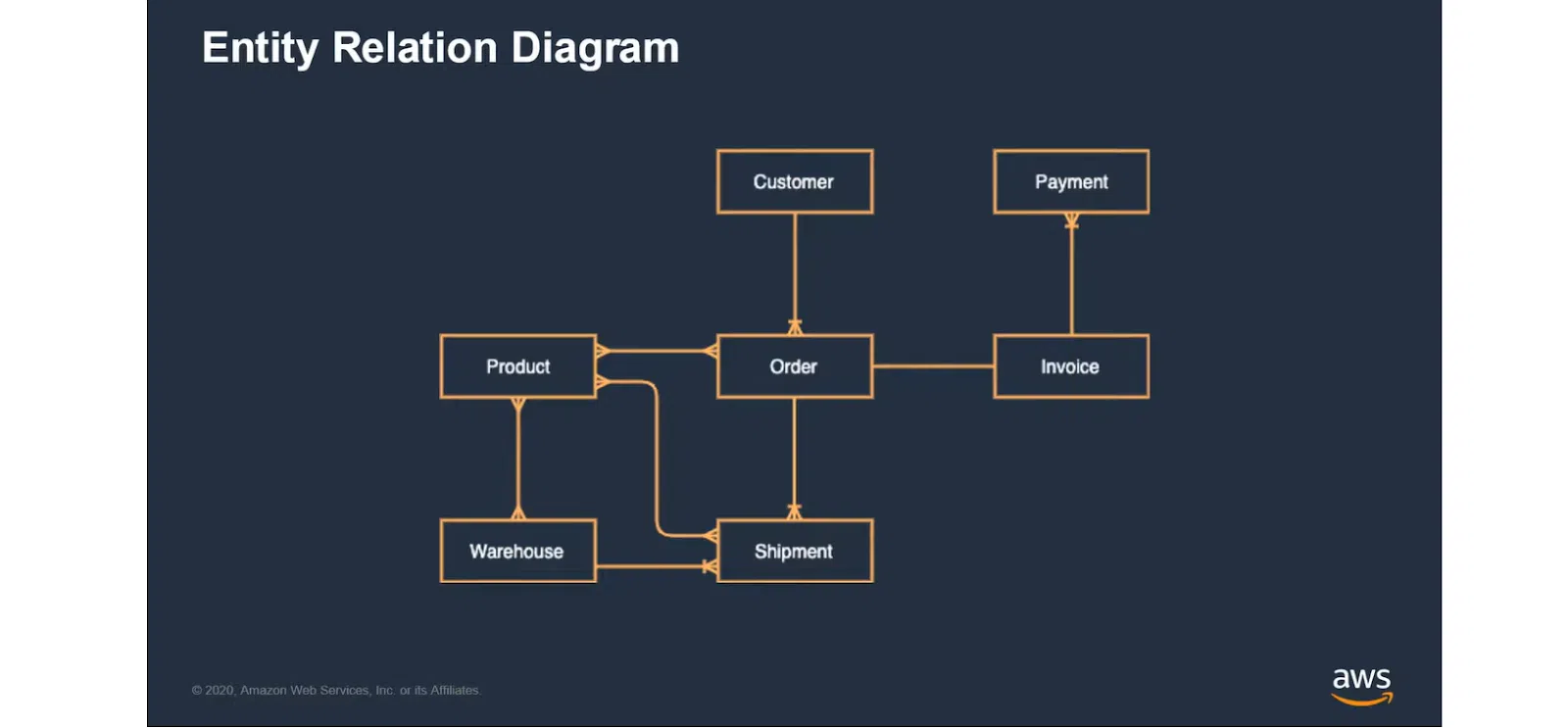
В качестве примера возьмем интернет-магазин с известным Use Case. На иллюстрации выделены ключевые сущности, по которым будет идти проектирование модели данных:
 Это приводит к появлению обычной SQL-модели данных. Здесь обозначены разные типы связей между сущностями.
Это приводит к появлению обычной SQL-модели данных. Здесь обозначены разные типы связей между сущностями.
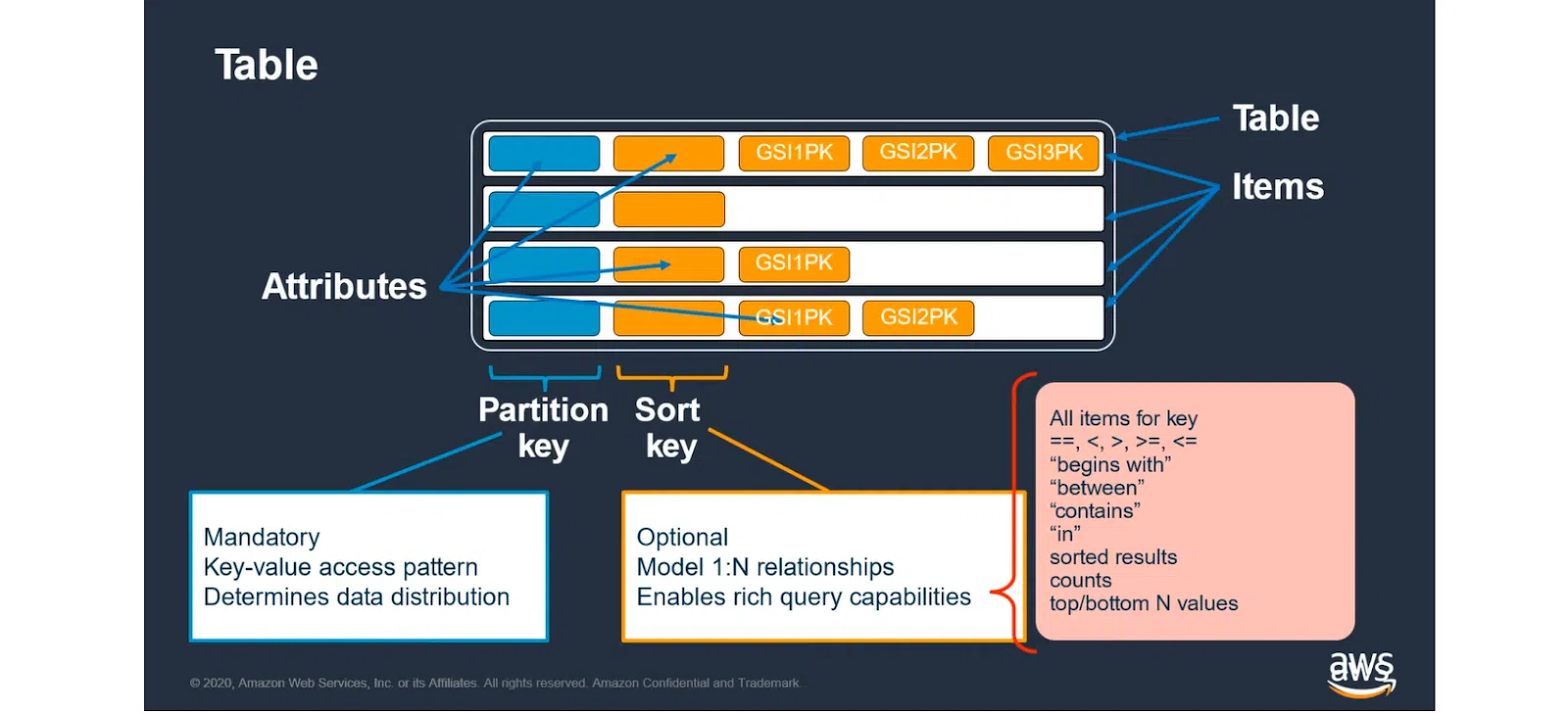
Однако дальше все меняется. Ниже можно увидеть структуру DynamoDB (приблизительно так устроены все Key-Value). Это однотабличная БД, имеющая Partition Key и Sort Key. Первый ключ обязателен – по нему выполняется поиск конкретной записи. Второй – опционный. Он предоставляет дополнительные возможности и позволяет задавать сложные запросы.

Шаблоны доступа к DynamoDB
Для работы с таблицей нужно прописать шаблоны доступа. Например, это может быть Get customer for given customerIdили более сложное:Get all shipments for a given warehouseId. Затем по каждому запросу следует определить, куда обращается БД и по каким ключам (в нашем случае они пусты).
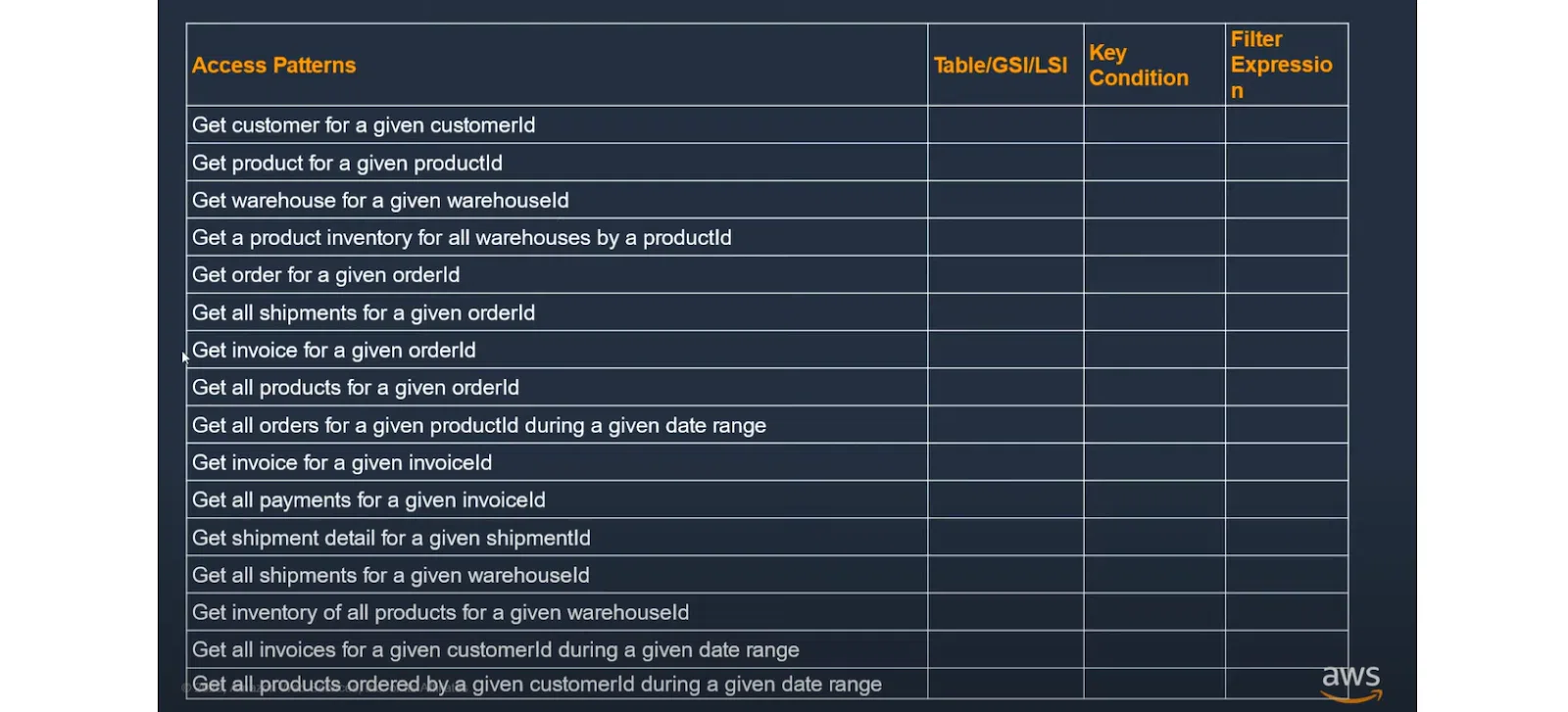
В случае SQL-схемы мы нормализуем данные и можем крутить их с помощью SQL-запросов. С NoSQL следует идти другим путем. Рассмотрим пример ниже. Берем приведенный запрос из основной таблицы (о пометке GSI расскажу впоследствии). Есть Partition Key в виде productId. В качестве Sort Key выступает второй ключ Id склада. В результате можно выполнить запрос относительно конкретного продукта и узнать, на каких складах он доступен:
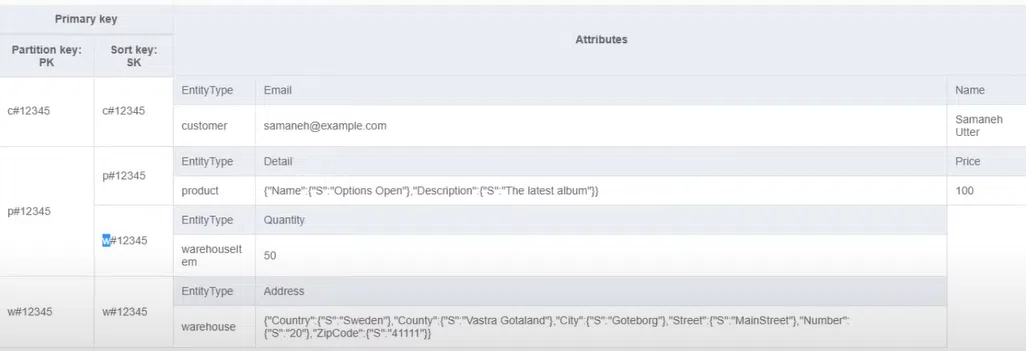
 Для работы с данными можно использовать Workbench от AWS. Этот NoSQL инструмент дает наглядное представление обо всех данных и показывает, от какой сущности берутся атрибуты. Атрибутами могут быть имя, почта, адрес, количество, стоимость и т.д. Workbench – это, в сущности, UI для моделирования базы данных. При желании можете все свернуть в объект JSON. Но когда информация визуализирована, работать с ней гораздо удобнее.
Для работы с данными можно использовать Workbench от AWS. Этот NoSQL инструмент дает наглядное представление обо всех данных и показывает, от какой сущности берутся атрибуты. Атрибутами могут быть имя, почта, адрес, количество, стоимость и т.д. Workbench – это, в сущности, UI для моделирования базы данных. При желании можете все свернуть в объект JSON. Но когда информация визуализирована, работать с ней гораздо удобнее.
В интерфейсе Workbench можно видеть каждый Partition Key и связанные Sort Keys, не структурированные по атрибутам. На иллюстрации у первой строки атрибутом есть customer, а во второй строке — product. Нормализация данных не требуется. Достаточно написать атрибуты со значениями. Их можно добавлять и убирать по одной строке или несколько сразу:
 При использовании более сложных шаблонов доступа могут возникнуть проблемы. Следует учитывать больше параметров. Однако Partition Key и Sort Key могут не покрыть все ситуации, поскольку они выбираются на всю таблицу. Поэтому для доступа и выполнения определенного запроса может не хватить ключей.
При использовании более сложных шаблонов доступа могут возникнуть проблемы. Следует учитывать больше параметров. Однако Partition Key и Sort Key могут не покрыть все ситуации, поскольку они выбираются на всю таблицу. Поэтому для доступа и выполнения определенного запроса может не хватить ключей.
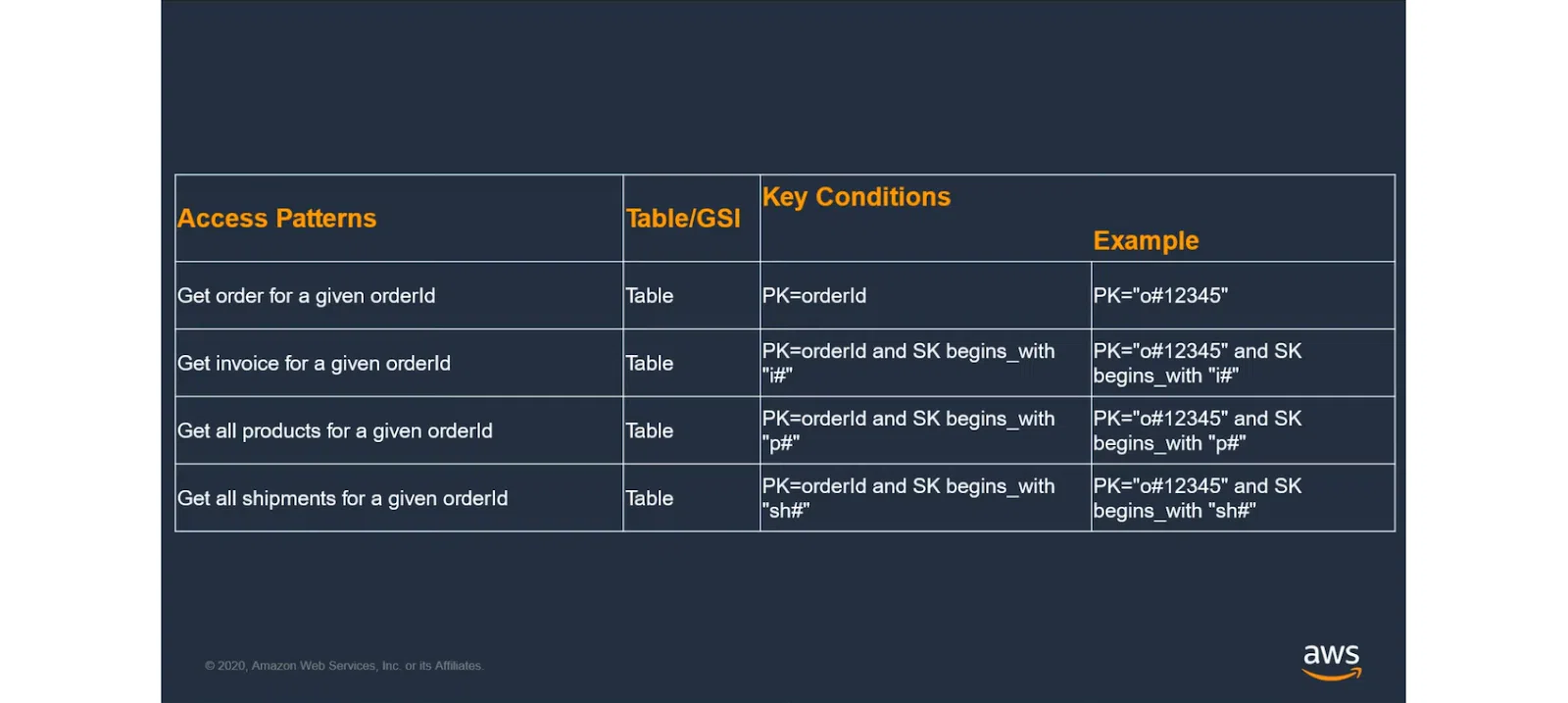
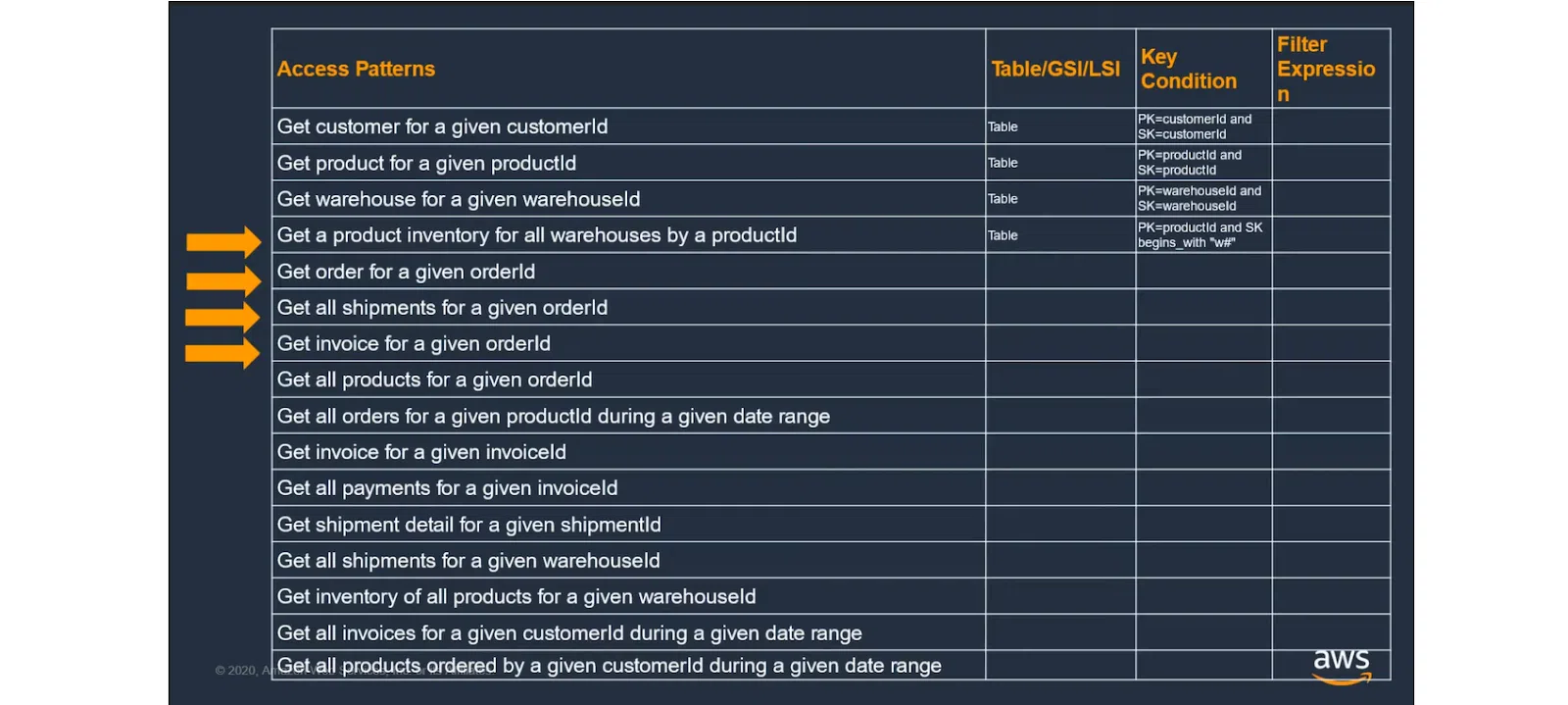 Конечно, всегда можно поиграть со стратегиями Partition Key и Sort Key. Это позволяет решить до 80-90% бизнес-задач. Но для остальных ситуаций придется искать более сложный подход.
Конечно, всегда можно поиграть со стратегиями Partition Key и Sort Key. Это позволяет решить до 80-90% бизнес-задач. Но для остальных ситуаций придется искать более сложный подход.
Индекс глобального поиска
Справиться с такой проблемой в DynamoDB поможет Global Search Index. В этой ситуации не хватает заложенных Partition Key и Sort Key. Предположим, мы хотим не просто смотреть данные productId, но и сортировать их по дате поступления товара. Такой Sort Key у нас предусмотрен. Так что нужно создать Global Search Index — фактически реплику таблицы. В Partition Key будет productId, а Sort Key – та же дата. В этом случае GSI выступает посредником, как JOIN. Таким образом, можно создать до 20 GSI, чтобы покрыть все возможные шаблоны.
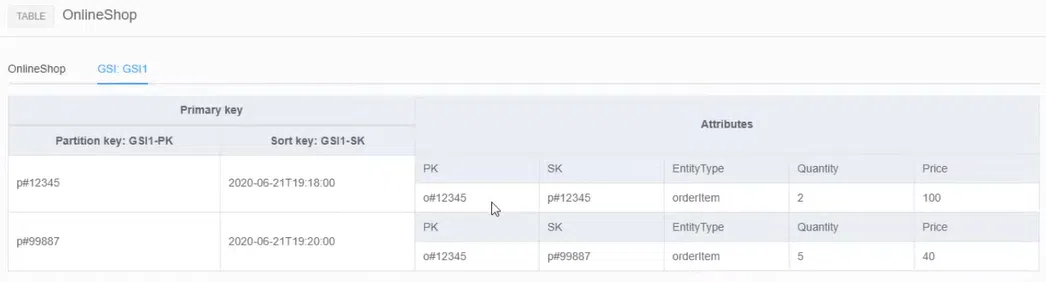

Замечу, что у GSI есть несколько проблем. Во-первых, при операции записи приходится обновлять основную таблицу и все созданные реплики. Во-вторых, на соблюдение согласованности данных требуется время. Нельзя просто обновить GSI. Сначала идет апдейт основной таблицы, а потом — очередь реплик. В результате лаг Eventually Consistency увеличивается. Предугадать его невозможно, все проверяется на практике. Поэтому помните об этом риске.
Избегайте GSI, если несогласованность данных может привести к серьезным ошибкам в проекте. Однако вы можете продумать и оценить критические сценарии. Например, в системах букинга одновременное бронирование двух номеров не является критическим. Обычно гостиницы закладывают эту возможность и держат резерв. Это очевидно проще, чем зажимать и замедлять базу данных в рамках SQL-модели.
Реализация стратегии «один ко многим»
На иллюстрации представлен вариант с комплексным атрибутом. Здесь собрано много PaymentMethod по одному аккаунту. Для реализации такой связи достаточно PaymentMethod написать в один атрибут по каждому айтему. Каждый запрос будет выполняться точно и быстро. Но если шаблоны доступа предполагают, что у какого-то PaymentMethod будет запрос Query, то этот прием не получится.
 Самый простой способ реализации «один ко множеству» – это дублирование. Предположим, у нас писатель, его книга и атрибут с днем рождения автора. Эта дата не относится непосредственно к книге, поэтому это значение приходится повторять в каждой книге. Но ведь день рождения не меняется, поэтому атрибут можно дублировать:
Самый простой способ реализации «один ко множеству» – это дублирование. Предположим, у нас писатель, его книга и атрибут с днем рождения автора. Эта дата не относится непосредственно к книге, поэтому это значение приходится повторять в каждой книге. Но ведь день рождения не меняется, поэтому атрибут можно дублировать:

Помните: стоимость хранения данных низкая, но цена обработки значительно выше. Так что дублирование имеет смысл только во многих записях или в случае повторяющихся данных, которые не будут часто обновляться.
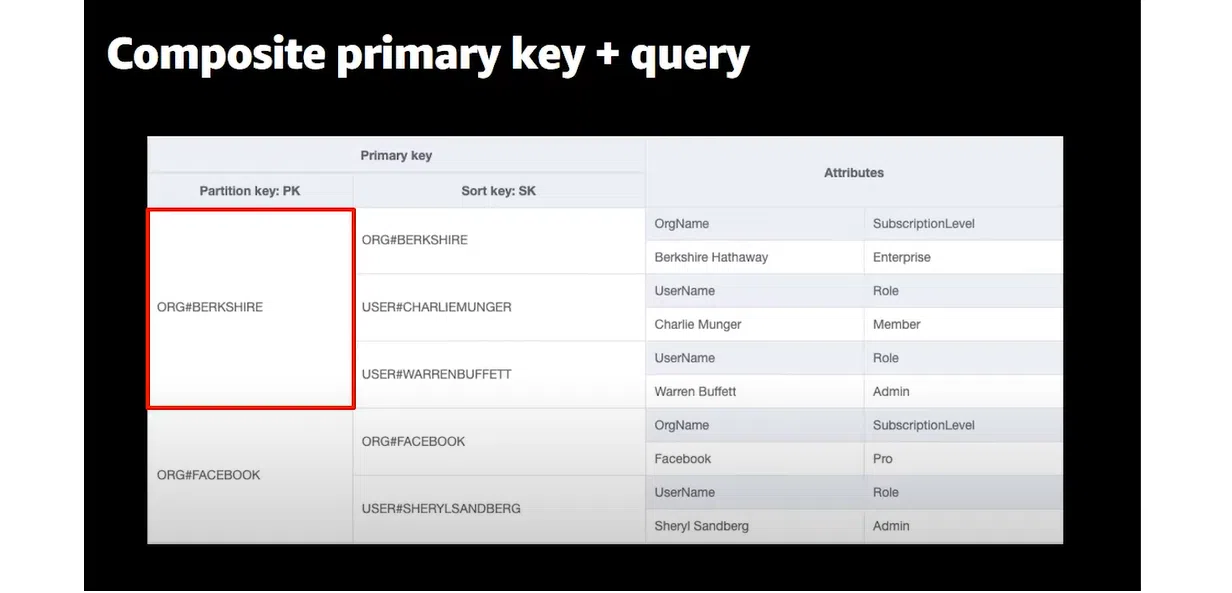
Относительно композитного Partition Key. Вы можете склеить его и сделать сложным. Это позволит реализовать своеобразный преджоинт и создать более сложные запросы:
 Мой опыт использования DynamoDB
Мой опыт использования DynamoDB
В одном из проектов я мог использовать только эту базу данных. Все из-за специфических требований клиента к архитектуре. Сначала общались с БД через AppSync. Этот GraphQL-сервис для отработки языка SQL-запросов предназначен для работы с реляционными базами данных. Хотя он подходит и для DynamoDB, поскольку в него можно скачать привычную модель общения с БД.
Однако на этапе тестирования у нас возникли проблемы. В проекте было мало данных. При выполнении приложения определенной выборки запросов появились задержки. Ошибка очевидна: не следует общаться с DynamoDB как с реляционной базой данных. Система для выполнения запроса просто сканировала всю базу, ведь не было ни шаблона, ни ключа. Мы получали ответ, но потери времени оказались слишком серьезными. Пришлось все перенастраивать.
Не думайте, что NoSQL когда-нибудь заменит SQL. Эти подходы дополняют друг друга, причем часто в пределах одного продукта. В том же Instagram используется несколько реляционных и нереляционных баз данных. Все зависит от того, какие задачи выполняет БД. Прежде чем выбирать один из вариантов, подумайте, какая цель стоит перед вами.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: