


Далеко не все разработчики знают о пользе лямбда-функций. И зря! Ведь эти облачные функции могут значительно упростить работу девелопера и повысить эффективность создаваемых приложений. Особенно показательно это свойство на примере сервиса AWS Lambda от Amazon. Об этом дальше и поговорим.
Я расскажу о принципах работы и основных возможностях лямбда-функций. Эта статья, прежде всего, будет полезна Junior-разработчикам. Вы узнаете о базовых понятиях и сможете начать работу с AWS Lambda.
Что предлагает AWS
Для начала кратко опишу, что представляют собой Amazon Web Services. В работе с Lambda вам так или иначе придется столкнуться со связанными облачными сервисами Amazon. Составляющие AWS собраны на иллюстрации ниже:
 Их можно разделить на несколько групп.
Их можно разделить на несколько групп.
Первая группа — Compute, объединяющая услуги для вычислений:
- Elastic Compute Cloud — виртуальный сервер в облаке для аренды инстансов;
- Elastic Container Service — сервис координирования контейнеров;
- Lambda — функции для запуска кода в облаке без предоставления выделенного сервера.
Вторая группа — это базы данных:
- реляционная база RDS с поддержкой Oracle, PostgreSQL, MySQL и MariaDB;
- DynamoDB, предоставляющая NoSQL базы данных от Amazon;
- ElastiCache — сервис кэширования, совместимый с Memcached и Redis.
Третья группа сервисов касается работы сети и доставки контента:
- API Gateway для разработки, интеграции и управления API в эндпойнтах;
- Route 53 — система доменных имен DNS;
- Virtual Private Cloud, позволяющий создавать и управлять виртуальными приватными сетями.
Четвертая группа — хранилища:
- Simple Storage Service — сервис объектного хранения файлов в облаке;
- Elastic Block Store — облачное хранилище для инстансов; выступает как SDD- или HDD-диски, которые могут быть подключены только к виртуальным машинам;
- Elastic File System — управляемая файловая система для EC2, виртуальных машин и контейнеров; сетевая файловая система, которую можно расшарить между несколькими клиентами.
Пятая группа сервисов связана с безопасностью, идентификацией и управлением требованиями:
- Cognito — используется для управления пользователями в приложении;
- Secrets Manager — для хранения в облаке в открытом или зашифрованном виде переменных и секретов, а также предоставления к ним доступа авторизованным пользователям и приложениям;
- Identity & Access Management — управляет доступом к ресурсам согласно описанным ролям.
Шестая группа — об управлении и администрировании:
- CloudWatch используется для мониторинга ресурсов и приложений, а также сбора логов и статистики с других сервисов AWS;
- CloudTrail отслеживает действия пользователей и API;
- CloudFormation — для моделирования и распределения ресурсов в облачной инфраструктуре.
На этом сервисе работает множество фреймворков для написания и деплоя лямбда-функций. Для этого создается YAML-файл для описания необходимых ресурсов и их свойств. Затем с помощью консольной утилиты AWS CLI нужно один раз задеплоить результат. И тогда во время апдейтов не нужно деплоить исходный файл заново, а можно редактировать исходный код для обновления ресурсов.
Лямбда-функции относятся к serverless-концепции
Здесь следует выделить несколько преимуществ:
- Отсутствие управления сервером
Нет серверов — нет управления ими. Вам не придется тратить силы на создание, выделение и обслуживание таких устройств.
- Гибкость масштабирования
Для увеличения производительности окружения не требуется отслеживать нагрузку на серверы и ресурсы. Разработчику достаточно только менять настройки лямбда-функции. Вы можете увеличить объем памяти, и система сама сделает все остальное.
- Оплата объема потребленных ресурсов
Платите за время использования лямбда-функций. Даже если она задеплоена, но простаивает, расходы будут нулевыми.
- Доступность и отказоустойчивость
AWS гарантирует стабильность программы, которая будет доступна во многих регионах мира. Другие услуги, использующие лямбда-функции, тоже будут иметь к ним доступ.
Как работает лямбда-функция
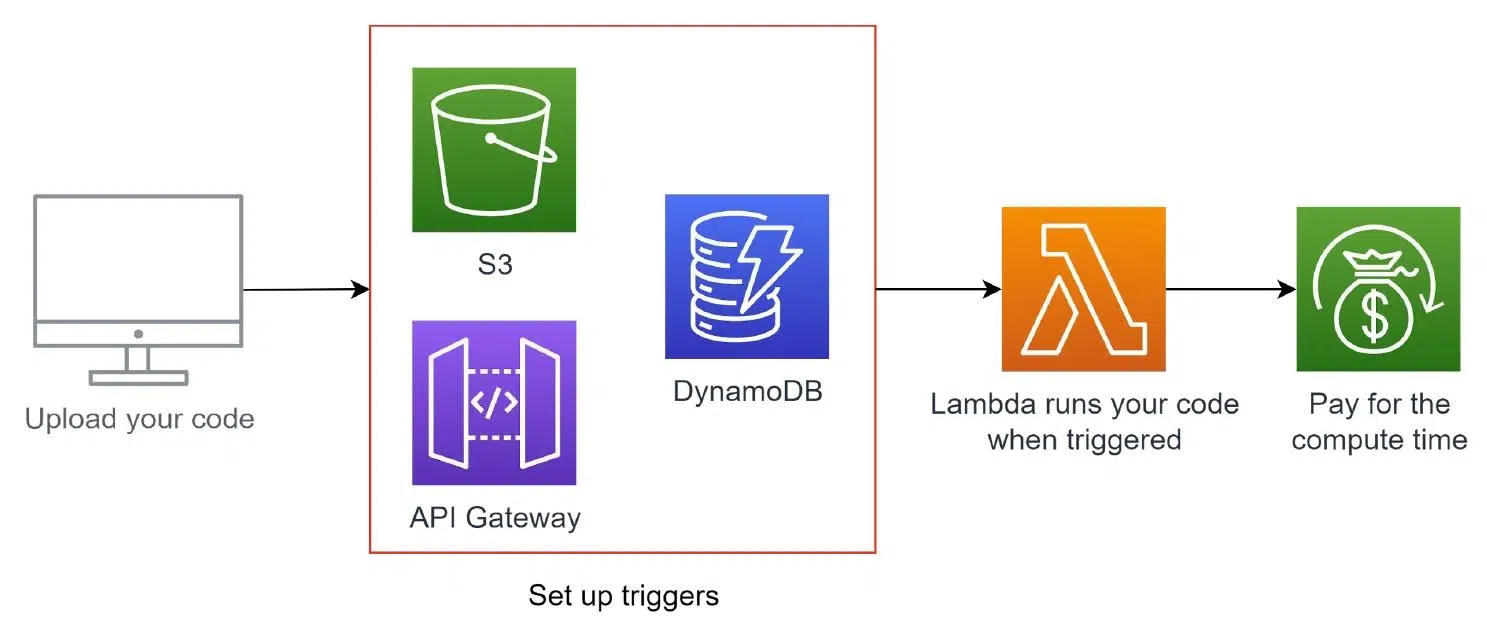
Для наглядности я шаг за шагом опишу типичный сценарий запуска лямбда-функции в AWS:
- Сначала вы пишете код локально и загружаете его в сервис лямбда-функции.
- Затем настраиваете триггер, который должен стать источником ивента.
- Тот приведет к появлению новой функции. Это могут быть, например, трекинг изменений файла в хранилище S3, HTTP-запрос к созданному через API Gateway эндпойнту или созданию, апдейту и удалению записей в DynamoDB.
- При получении такого ивента лямбда-функция начнет выполнять заданные действия.
- По завершению вы получите счет за время выполнения функции:
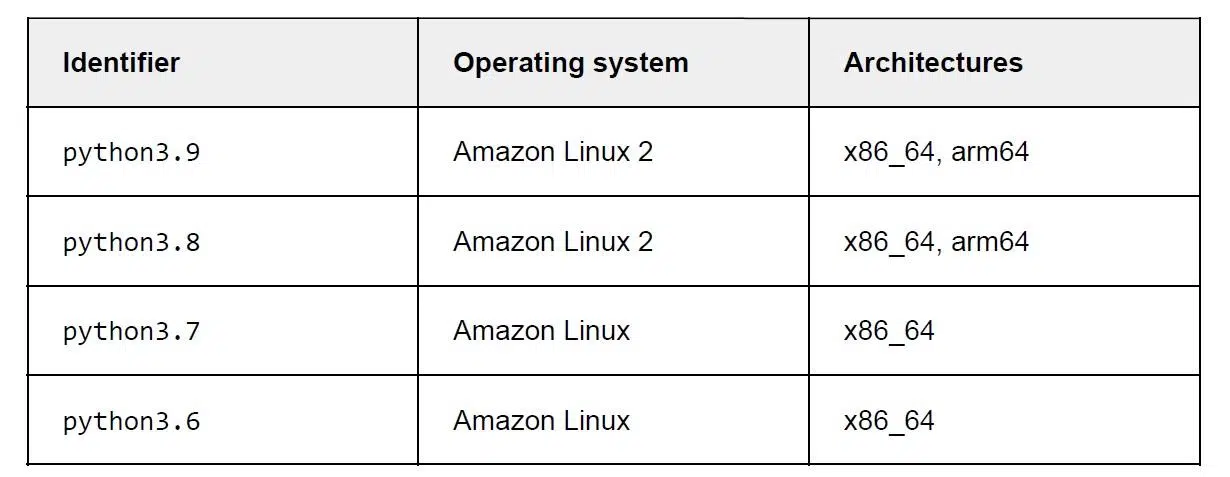
Теперь лямбда-функции от Amazon поддерживают четыре версии Python: от 3.6 до 3.9. Раньше была поддержка и второй версии, но сейчас она приостановлена. Поэтому старые проекты задеплоить невозможно. Но у Amazon появились ARM-процессоры Graviton. Поэтому в версиях Python 3.8 и 3.9 можно задеплоить от архитектуры ARM.
Выполняем деплой AWS Lambda
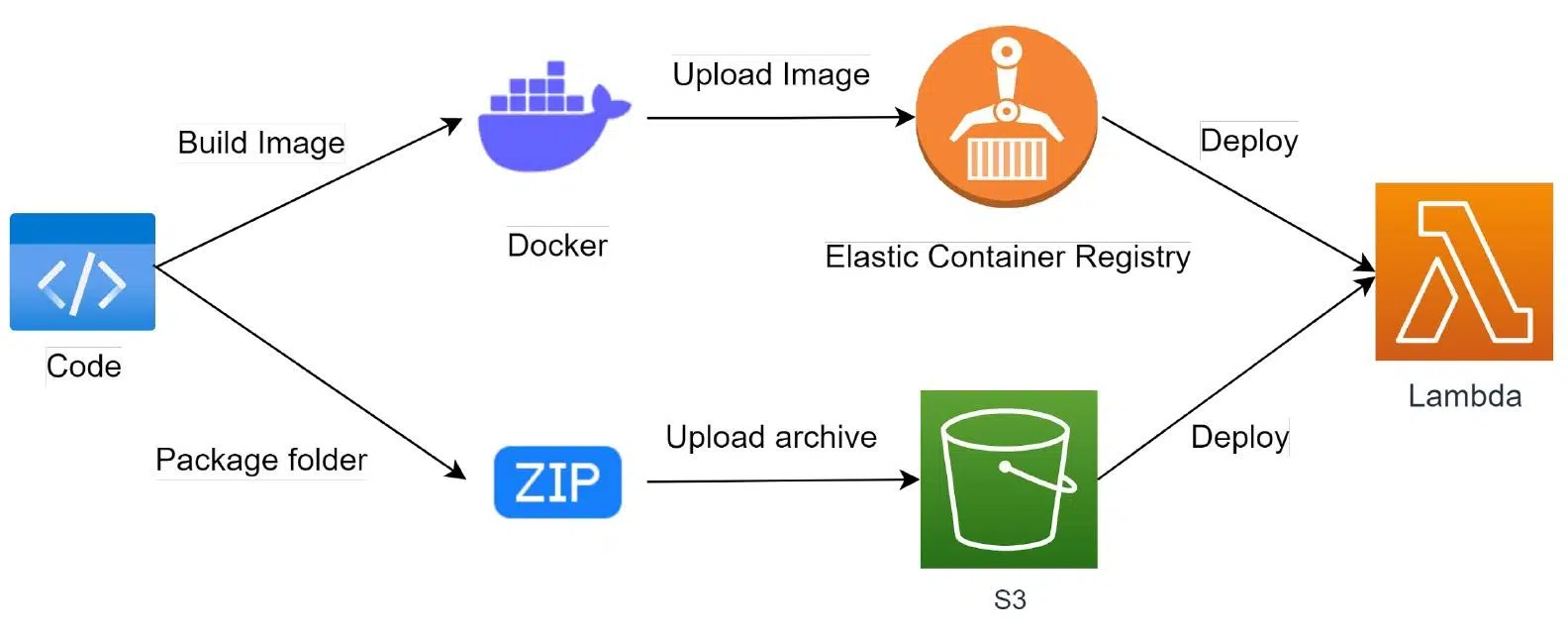
После локального написания кода деплой лямбды может происходить по одному из сценариев:
- Код упаковываем в ZIP-архив и загружаем в S3, откуда деплоим отдельно на сервис Lambda. Именно так работают практически все фреймворки и консольные утилиты для разработки лямбд.
- Код собираем в Docker-контейнер и загружаем в репозиторий Elastic Container Registry. Именно из этого реестра контейнеров происходит деплой в сервисе Lambda.
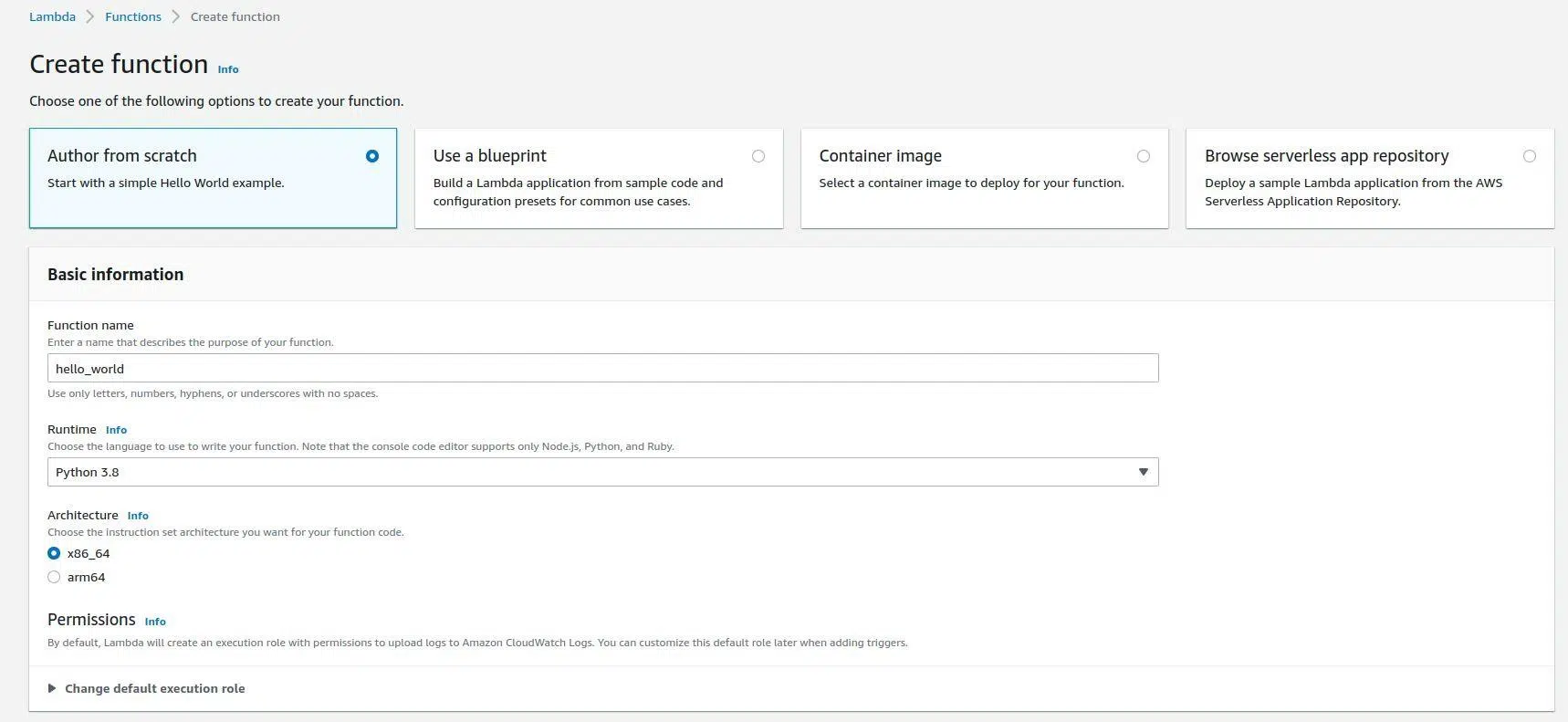
Создание новой функции
Можете не ограничиваться локальным написанием кода. Писать его можно в дашборде Amazon в онлайн-редакторе. Таким образом вы пропустите шаг в типичном создании лямбда-функции и сразу сохраните код в S3.
Для визуализации такого сценария возьмем в качестве примера создание простой функции Hello World. Для этого открываем соответствующий раздел, задаем имя лямбды, а остальные параметры оставляем по умолчанию: это Python 3.8 и архитектура x86.
Далее пишем саму функцию в онлайн-редакторе. Метод лямбды должен принимать два параметра: event и context. В context содержится служебная информация об окружении лямбда-функции (имя и настройки). Сама функция работает с event, откуда должны поступать какие-то данные.
К примеру, если это был определенный HTTP-запрос, все содержится именно там. Здесь мы пишем функцию, которая здоровается с пользователем и возвращает результат. Также есть print с самим объектом ивента:
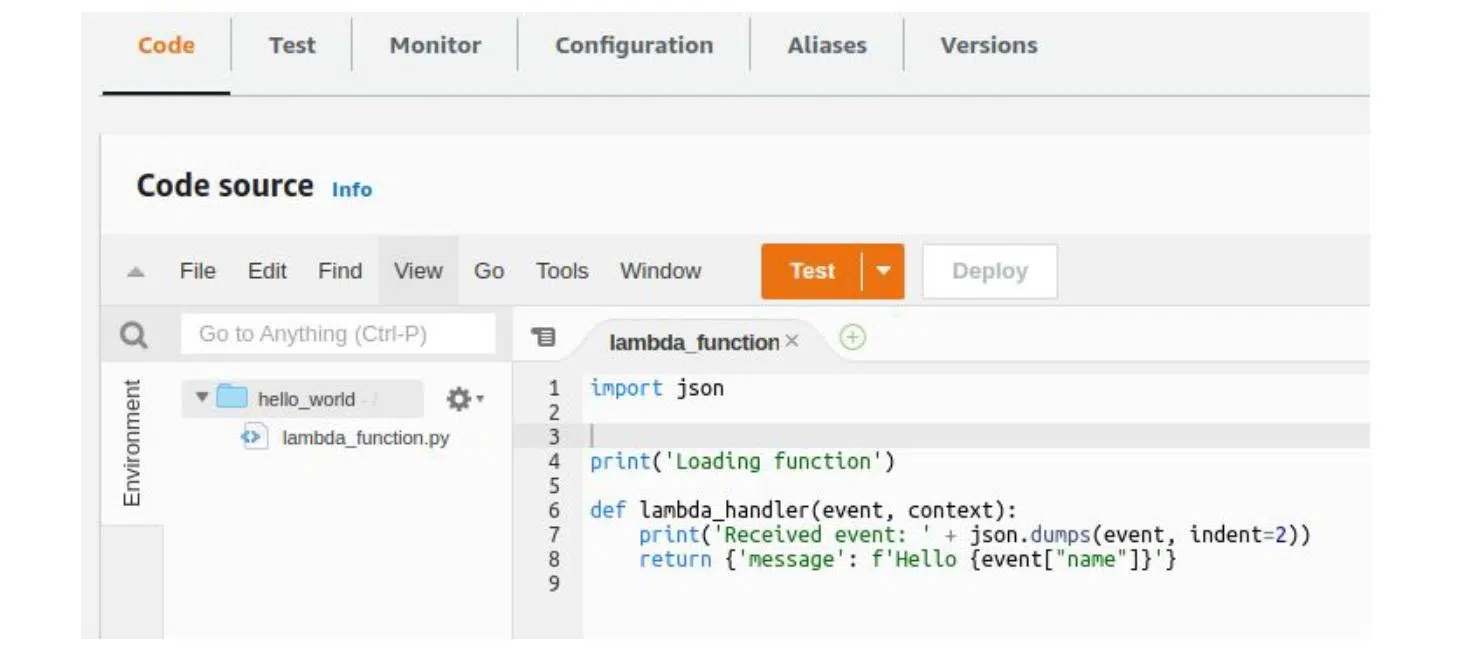
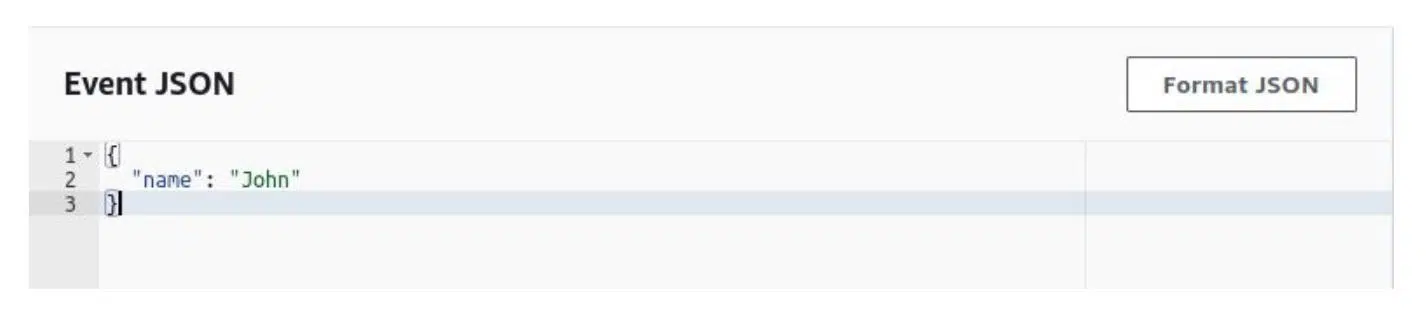
После функции мы не будем сетить ивент. Создадим тестовый ивент, в котором опишем JSON-объект — в нашем случае имя пользователя John. Замечу, что все параметры, принимаемые лямбда-функцией, должны быть JSON сериализированными. В противном случае функция не запустится:
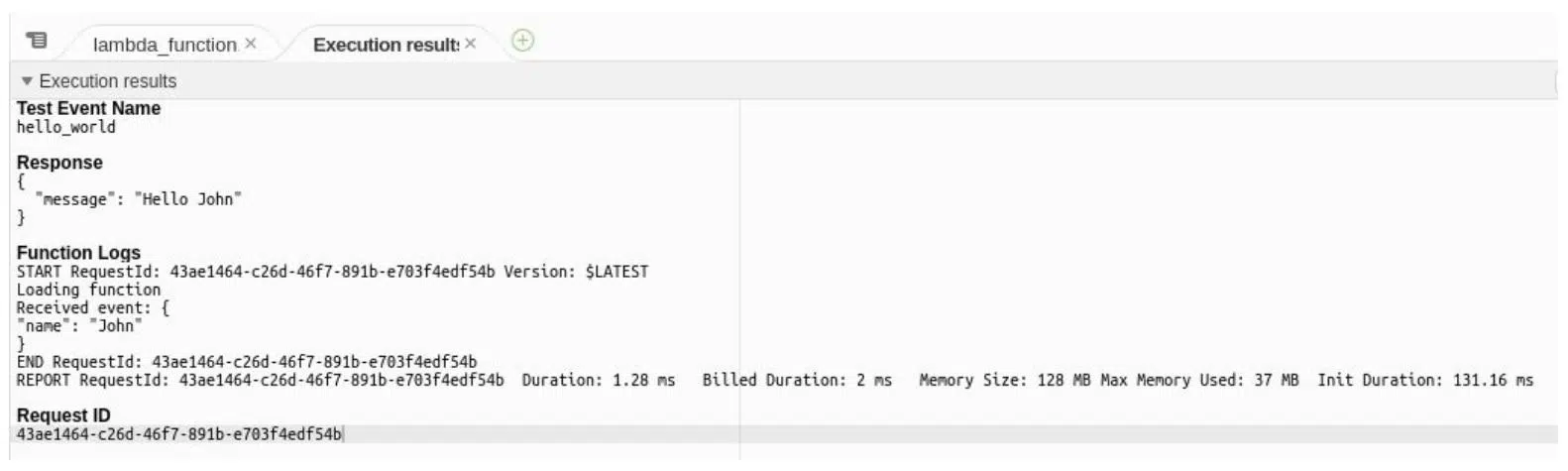
После написания ивента нажимаем кнопку Test и видим результаты выполнения функции. Должен появится блок Response с возвращаемыми из функции данными.
Также мы получим логи с тремя строчками служебной информации:
START. Здесь приводится уникальное ID реквеста и версия лямбда-функции. В примере я задеплоил одну версию, для которой автоматически создан$LATEST— и с ним мы всегда работаем.END. Здесь повторяется тот же самый RequestId.REPORT. Этот блок содержит сведения о выполнении лямбда-функции. Прежде всего — сколько времени в миллисекундах занял весь процесс. Далее рассчитывается оплачиваемое время работы сервиса (округляется в большую сторону). Также указывается объем памяти, заданный в настройках лямбда-функции, и объем памяти, используемой в процессе. Завершает блок Init Duration с потраченным на инициализацию функции временем.
После получения ивента выполняется следующий сценарий:
- Сначала сервис загружает код из S3 или реестра контейнеров. Если для создания лямбды используете какую-либо утилиту, то она загружает код в S3 в созданный ею бакет. А если код написан в онлайн-редакторе, то он отправляется во внутренний бакет, скрытый от пользователя.
- После загрузки кода сервис создает окружение с указанными настройками: объем памяти, переменная окружения и т.д.
- Затем запускается инициализация кода, а дальше — и сама функция.

Два первых блока окрашены в синий цвет и отражают стадию холодного старта. Этот этап выполняется при первом запуске лямбда-функции после долгого простоя. При последующих получениях ивентов выполняются только блоки 3 и 4 — с импортом библиотек и запуском самой функции.
Правда, третий блок спорный. Согласно документации AWS, библиотеки импортируются каждый раз. Хотя авторы сервиса указали, что в случае простоя среда замораживается. Потому импорт библиотек не повторяется. Возможно, это касается не только Python, но и всех поддерживаемых языков.
Ниже приведена схема повторного использования окружения лямбда-функции:
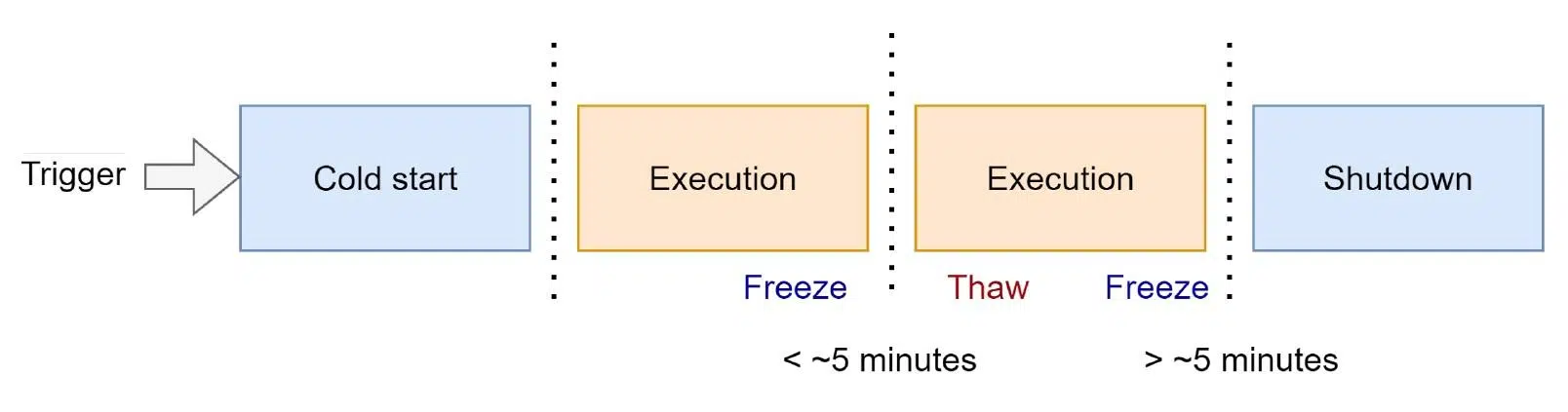
С появлением триггера происходит холодный старт с загрузкой функции, созданием оцепления и обработкой ивента. После этого среда, в которой выполнялась лямбда, замораживается. Останавливаются все фоновые процессы. Также замораживается директория /tmp, созданная для каждой функции. То есть можно повторно использовать папку для хранения кэша. А еще хранятся объекты, которые были объявлены вне функции.
Поэтому если после запуска функция не использовалась менее пяти минут, среда при поступлении новых ивентов и триггеров размораживается. Но если простой длится больше пяти минут — среда удаляется, а с ней — все данные.
Обработка нескольких ивентов
Отдельная тема — одновременная обработка нескольких ивентов. При получении ивента механизм лямбды ищет среду в простое — инициализированную, обработавшую ивент и замороженную. Если таковой нет, создается новая среда окружения.
Именно это показано ниже на ивенте 1. При его обработке появляется ивент 2. Механизм лямбда-функции снова ищет свободную среду и не находит ее. Поэтому поднимает еще одно окружение: с холодным стартом, загрузкой библиотек, инициализацией среды и последующей обработкой второго события.
Далее поступает ивент 3. При этом обработка второго продолжается, а первого уже завершилась. Поэтому механизм начинает переиспользовать освободившуюся первую среду.
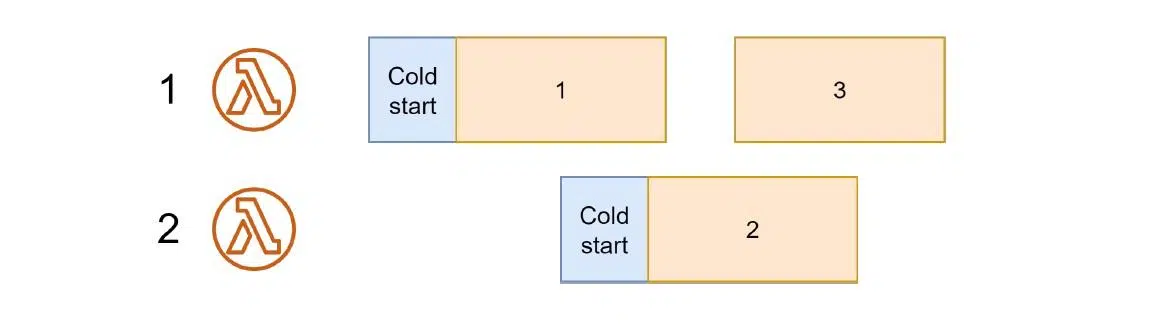
Если бы три ивента поступили одновременно, механизм создал бы три отдельных среды окружения. В этом и состоит гибкость концепции Serverless, где нет необходимости в менеджменте серверов. Лямбда делает все за нас.
Единственное «но» — ограничение в 1000 лямбда-функций, которые выполняются одновременно. Об этом следует помнить при построении сложных продакшен-систем.
Правда, этот показатель постепенно растет. При необходимости можно пообщаться с техподдержкой Amazon и объяснить свои потребности.
Перфоманс лямбда-функции
Если в виртуальных машинах можно настроить память, ядра, диск и процессор, то в лямбда-функции корректируется только объем оперативной памяти (от 128 МБ до 10 ГБ). При изменении этого параметра изменяется количество ядер и мощность процессора, задействованного для конкретного окружения. Как заявляют в Amazon, на каждые 1700 МБ оперативной памяти выделяется по одному ядру.
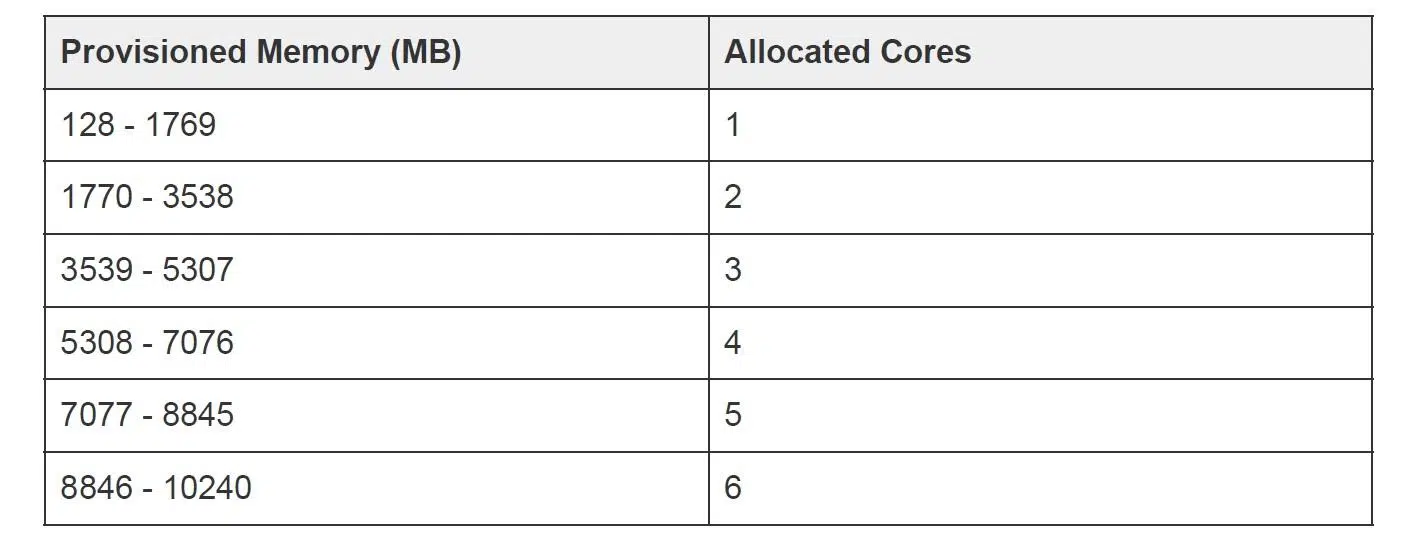
Хотя на практике все выглядит несколько иначе и лучше. Это показало опыт работы с лямбда-функциями в нашей команде. К примеру, при изменении памяти со 128 МБ до 1 ГБ в отчетах мы видели данные об использовании только 100 МБ. То есть производительность должна была остаться примерно на том же уровне. Но время на обработку сокращалось примерно втрое! Хотя у нас так же работало только одно виртуальное ядро.
Продолжение статьи о лямбда-функциях скоро читайте на Highload. Stay tuned!
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: