


Привет! Наша команда SPD-Ukraine хочет поделиться своим опытом парсинга огромного количества данных на примере одного из наших проектов.
Итак, представим, что нам необходимо парсить колоссальное количество данных в день: скажем, порядка 20 000 новостей из сферы финансов. У нас в базе есть более 8 млн компаний, которых могут касаться эти новости.
Как нам самим понять, о чем идет речь в конкретной новости, с какими компаниями связана новость, какие происходили события (поглощение, банкротство, увеличение ревенью и т.д)? Кроме того, у компаний может быть достаточно большое количество вариаций имен, например, Facebook, The Facebook, Facebook Inc, FB.
Проверять каждую новость с помощью человеческих ресурсов не вариант. Так как же быть?
Предобученные NER-модели как решение проблемы
Первую часть проблемы, а именно распознавание имен компаний и событий в тексте новостей, мы решаем с помощью named-entity recognition (NER) — распознавания именованных сущностей. Оно выглядит примерно так:
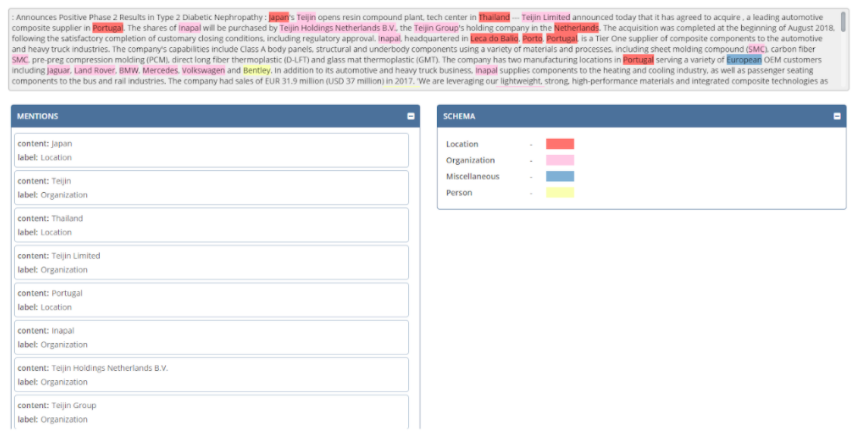
Named-entity recognition (NER)
В примере видно, что в тексте новости мы определяем четыре типа сущности:
- location;
- organization;
- miscellaneous;
- person.
В общей постановке задачи мы пытаемся разметить наш входной текст новости и выделить саму сущность, ее расположение, людей связанных с этой сущностью.
Все это нам необходимо для того, чтобы потом искать в тексте новости определенные события и пытаться связать их с соответствующими компаниями.
Для задач NER на рынке существует несколько готовых решений. Дальше коротко расскажем о некоторых из предобученных моделей.
spaCy
На сегодня библиотека spaCy — стандарт де-факто, и у нее существует огромное количество моделей для 16 языков. Но здесь и дальше мы будем говорить о моделях именно для английского языка.
В библиотеке spaCy существует три модели для большинства языков, включая английский: small, medium, large. Все эти модели умеют распознавать 18 типов сущностей. Базой для это модели был корпус OntoNote 5 с возможностью визуализации. Выглядит все довольно просто:
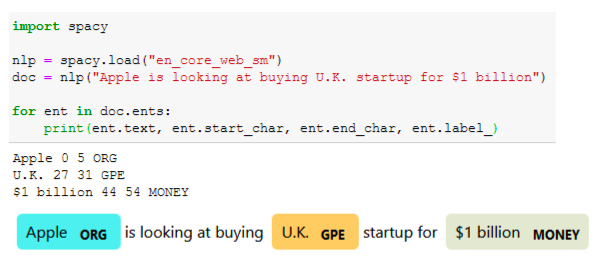
Пример работы с библиотекой spaCy
В этом случае мы используем маленькую модель для решения задачи NER. Например, есть у нас какой-то текст, и из него предтренированная модель выдает нам три типа сущностей: компания Apple, UK как геолокация и 1 миллиард денег. Она уже дала нам определенное понимание того, о чем в этой новости идет речь.
CoreNLP
Следующая модель, которая также умеет распознавать сущности, — это модель Стэнфордского университета CoreNLP. У нее пять языков, для английского также есть три модели, которые умеют распознавать соответственно три, четыре и семь классов. Эта модель натренирована уже на CoNLL 2003. Работать с ней не сложнее, чем с spaCY:
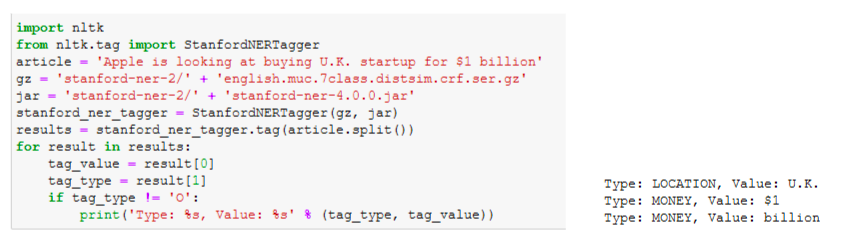
Работа с CoreNLP
Но в примере эта модель почему-то не смогла определить компанию Apple.
Stanza
Как развитие модели CoreNLP Стэнфордский университет также предложил модель Stanza. Ее можно назвать некой надстройкой над PyTorch. Для английского языка также существуют две модели, которые определяют четыре и восемь классов:
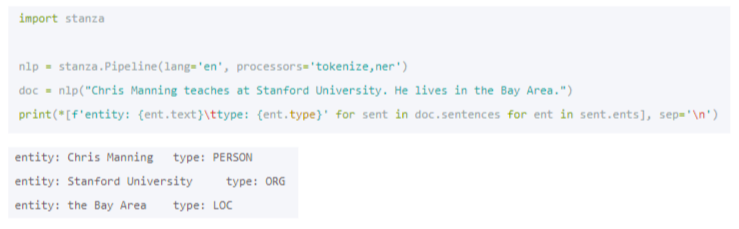
Работа со Stanza
Казалось бы, все просто — нужно взять одну из этих трех моделей или найти любую другую и использовать ее для решения своих задач. Но предобученные модели некоторые вещи не распознают. Например, CoNLP скорее всего распознал компанию Apple как фрукт.
Все предтренированные модели для тренировки использую общие корпуса (CoNLL, OntoNotes), которые имеют контекст общего характера. А нас конкретно интересует финансовый контекст, и мы использует только финансовые события.
Поэтому нам очень важно рассматривать все эти сущности и все, что с ними происходит, конкретно в финансовом контексте. Поэтому было принято решение тренировать свою модель. Как мы это делали?
Тренировка собственной модели NER
Существует множество подходов, но все их можно объединить в два типа:
- методы классического обучения;
- методы, которые используют глубокое обучение.
Классические методы машинного обучения до сих пор не потеряли свою актуальность и работают они не хуже нейронных сетей. Также классические методы машинного обучения гораздо проще интерпретировать — найти, что конкретно повлияло на тот или иной результат, и сделать корректировки в соответствующую сторону.
Основная задача NER — это supervised learning. Другими словами, у нас есть большой скоуп текста, который надо разметить. Задача NER — классифицировать этот текст на уровне токена — выставить каждому токену определенные метки.
Как размечается текст?
Существует несколько видов разметок. Один из основных методов — так называемая BIOES-схема.
Например, Карл Фридрих Иероним фон Мюнхгаузен родился в Боденвердере.
Чтобы разметить этот текст, мы используем две метки: PER (person) и LOC (location). Чтобы понять, где начинается сама сущность и где она заканчивается, в BIOES-схеме существуют определенные префиксы:
- B — beginning, первый токен в спане сущности;
- I — inside, токены в середине спана сущности;
- E — ending, последний токен в спане сущности;
- S — single, сущность состоит из одного слов.
И вот что получается.

Результат разметки текста
Когда мы таким образом разметили наш документ, мы можем поверх разметки тренировать классическую модель. Но перед этим мы можем в эту классическую модель машинного обучение добавить еще какие-то определенные фичи. Они бывают двух типов:
- контекстно-зависимые:
n_grams,word[:n],word[-n:]; - контекстно-независимые:
is_upper,is_lower,is_camelcase,postag (Part-of-speach),lemma,stem.
Мы можем генерить огромное количество других признаков в дополнение к этой разметке, таким образом тренируя модель.
Классической моделью для тренировки задачи NER является CRF (conditional random fields). По сути эта модель на нашем размеченном датасете пытается предсказать вероятность метки следующего токена по цепочке меток.
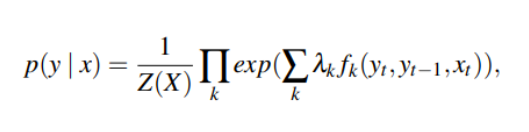
Эта модель показывает достаточно неплохие результаты конкретно по нашей задаче. Потому что у нас существует большой размеченный датасет. Кроме того, точность у нас достаточно высока — мы распознаем около 90% сущности с помощью этой модели.
Естественно, мы не могли обойти стороной попытку обучить нейронные сети для решения задачи по NER. Одним из таких решений является архитектура CharCNN-BLSTM-CRF. По сути это тот же CRF, только как последний слой, натренерованный поверху выхода архитектуры нейронной сети.
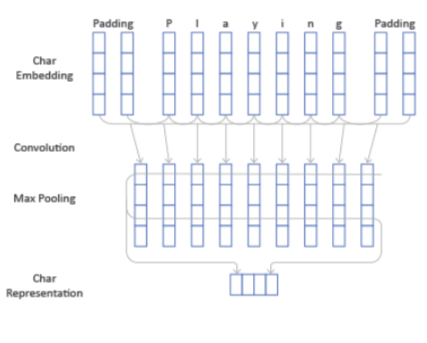
Одно из базовых явлений в этой архитектуре — генерация дополнительного вида признаков для каждого токена, то есть контекстно-независимых признаков. Другими словами, это попытка представления каждого токена вектором меньшей размерности, который выделяет наиболее значимые символы из этого токена.
Например, у нас есть какой-то токен — playing. У него есть начало и конец. Мы с помощью небольшого сверточного окна проходимся по эмбедингу каждого символа. С использованием max pooling мы выделяем наиболее значимые его признаки. И делаем такой вектор гораздо меньшей размерности, который в принципе нам однозначно как-то репрезентируем этот токен.
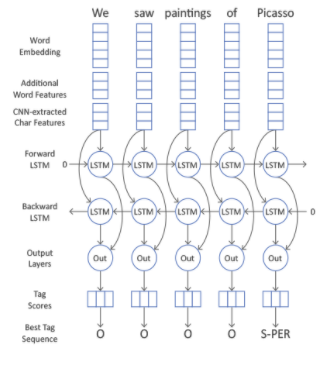
Теперь возьмем какое-нибудь предложение. Текст нам абсолютно неважен. Помимо каких-то word-embeddings, у нас есть additional features. Мы еще добавляем слой представления наших токенов в виде char representation и запускаем все на бидирекшинал, например LSTM. И в каждый момент времени помимо представления токена в виде совокупности признаков, у нас также есть информация как о предыдущих токенах, так и о последующих благодаря двунаправленной архитектуре сети.
И после того, как это все натренировалось, в конце мы делаем тот же CRF, который на основании просчитанных признаков пытается предугадать нам метку:
Entity resolution (entity linking)
Когда мы пропустили текст новости через нашу модель NER, мы получили какой-то список сущностей. Следующая задача — мы должны понять, существуют ли эти сущности у нас в базе данных, и связать их.
Как мы решали эту задачу раньше и как в принципе она сейчас до сих пор решается? Мы использовали такую структуру как нагруженное префиксное дерево. По сути это вариация на тему деревьев, которая выглядит примерно так:
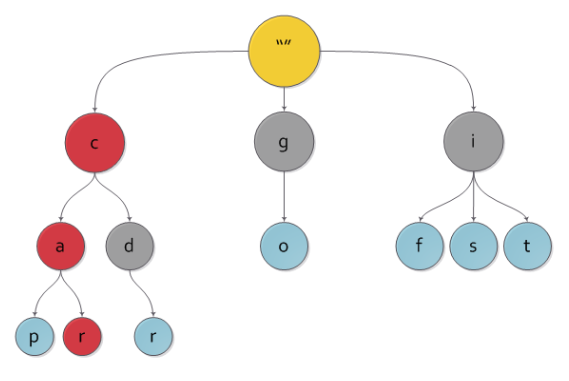
Корень у нас не имеет никакого символа. А дальше мы просто идем по цепочке — берем какой-то первый символ «с», идем влево — видим символ «а», идем вправо — видим «r». Значит это слово car.
Здесь могло быть слово Facebook или Google. Соответственно, с этой цепочкой связан какой-то индекс. И запуская нашу сущность, полученную из модели NER, пропуская через синтаксическое дерево, мы находим эту совокупность символов.
Несмотря на то, что по этой структуре данных достаточно быстро можно найти ту или иную сущность, мы задумались об альтернативных решениях этой задачи. Почему?
Если у нас 8 млн компаний, у каждой из которых порядка десятка каких-то имен, то это уже 80 млн. С добавлением каких-то новых сущностей, новых вариаций имен это дерево разрослось до огромных размеров, и в определенный момент у нас возникли вопросы с оптимизацией памяти наших облачных серверов для того, чтобы держать всю эту структуру в памяти.
К тому же очень проблематично использовать эту структуру для поиска опечаток. Если вы напишете Facebok — то такой последовательности в дереве нет, и придется придумывать какие-то дополнительные махинации.
И опять-таки, говоря о различных вариантах написания: это все очень сложно хранить и все очень сложно отслеживать. Чем больше кейсов, тем больше надо придумывать дополнительных моментов, чтобы из этого дерева доставать нужную информацию.
Поэтому одной из попыток решения этой проблемы стало использование так называемых similarity queries. Но это уже тема другой статьи.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: