


Привет! Наша команда ML-специалистов из SPD-Ukraine продолжает делиться своим опытом парсинга данных, разметки текста и машинного обучения.
В предыдущей статье мы говорили о том, как для одного из наших проектов из сферы финансов мы парсим новости рынка и определяем, о чем конкретно идет речь в тексте, ориентируясь на названия компаний и конкретные события (поглощение, банкротство и так далее).
Также мы упоминали об использовании такой структуры как нагруженное префиксное дерево. Но там возникла проблема с опечатками и вариациями с написанием названий компаний. С использованием такой структуры будет сложно все отслеживать и хранить. Чем больше различных кейсов, тем шире будет дерево.
Один из вариантов решения этой проблемы — использование similarity queries, которые представлены в библиотеке Gensim, почти полностью посвященной решению задач тематического моделирования. Сегодня попробуем разобраться, какой из методов будет самым удобным.
Возможности similarity queries
У библиотеки Gensim есть один единый интерфейс для всех своих моделей и она апеллирует с четырьмя видами сущностей:
1) Document — любой наш текст:
![]()
2) Corpus — совокупность всех наших документов:

3) Vector — любое векторное представление наших документов (TF-IDF, word2vec, doc2vec, fastText, GloVe, BERT):
Мы, например, работаем с word2vec, потому что он очень хорошо определяет контекстные зависимости — тренируем на финансовых новостях и получаем хороший embedding в сфере финансов.
Также используем fastText — он не зависит от контекста, а тренируется на символьном представлении токенов. И он очень хорош для таких задач как кластеризация, потому что результат предсказуем — векторы не меняются от контекста. То есть при добавлении какого-то скоупа новостей или любой другой информации векторы будут примерно те же самые.
4) Model — TF-IDF, Latent Semantic Indexing, LSI, Latent Dirichlet Allocation (LDA), Random Projection (RP), Hierarchical Dirichlet Process (HDP):
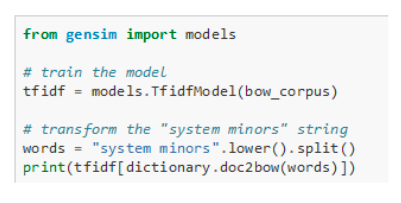
С помощью модели мы преобразуем наше векторное представление в то, что нам нужно.
Очень интересный Latent Dirichlet Allocation, который пытается представить текст новости как смесь некоторых топиков, а топик — как смесь некоторых значимых ключевых слов.
Это эффективное решение, для того чтобы без использования человеческих ресурсов пытаться определить смысл новости. То, к чему мы и стремимся!
Сравнение с помощью косинусного сходства (Cosine Similarity)
Чтобы сравнить, насколько один текст похож на другой, можно использовать метод измерение угла между их векторными представлениями — так называемое косинусное сходство.

Например, у нас есть две статьи о двух игроках в крикет, и существует третья статья, которая является небольшим сниппетом ![]()
![]() «анонс», краткое содержание одной из статей. Если мы будем считать количество вхождений слов и частоту слов, получится, что первая статья намного больше похожа на вторую, просто потому что там больше контекста.
«анонс», краткое содержание одной из статей. Если мы будем считать количество вхождений слов и частоту слов, получится, что первая статья намного больше похожа на вторую, просто потому что там больше контекста.
Но если мы перейдем к векторному представлению и к косинусной мере, мы увидим, что вектор маленькой статьи намного ближе по углу и смотрит в ту же самую сторону, что и вектор статьи, с которой был взят этот сниппет:
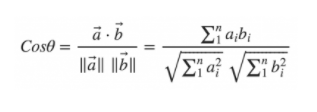
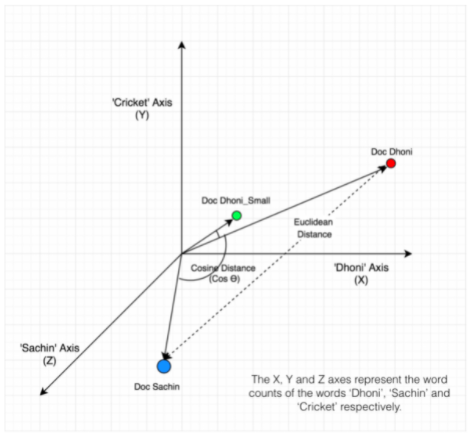
Сравнение статей с помощью Cosine Similarity
Проблема такого подхода в том, что нам необходимо строить вектор для каждого текста, каждой сущности, которая у нас есть в базе данных. Если у нас несколько десятков миллионов вариаций имен, нам нужно строить столько же векторов, и потом, получая из модели NER какую-то сущность, переобразовывать ее в векторную форму и сравнивать ее с тем десятком миллионов векторов, которые у нас есть. Это очень долго.
Идея similarity query
Similarity query можно назвать попыткой оптимизации процесса, описанного выше.
Основная идея — переход от векторного представления больших текстов к векторному представлению конкретных токенов.
Понятно, что самих токенов (слов, из которых состоят новости) намного меньше, чем сущностей. Если мы возьмем компанию Facebook и какие-то вариации на тему имен, то токен будет один — Facebook. Наши десятки миллионов векторов ужимаются в несколько раз и повышается быстродействие.
Также строится определенная матрица похожести токенов, поверх которой строится индекс. Он связывает токены с сущностями, с которых эти токены были взяты. Формируя similarity query, мы в этой матрице индексов ищем похожие токены. А потом на уровне этих похожих токенов мы ищем те сущности, которые у нас уже есть, и смотрим, насколько результаты по модели NER соответствует тому, что у нас есть в базе.
Существует три основных вида таких запросов. Давайте рассмотрим их подробнее.
Cosine Similarity
Этот подход считается классическим. Кроме того, он самый быстрый. И в библиотеке Gensim с его помощью можно строить матрицы и индексы похожести не только в памяти, а есть еще возможность хранить их в файле на жестком диске. Даже если у вас не хватит ресурсов по оперативной памяти, все будет упираться в место на жестком диске. Этот подход все равно будет оставаться достаточно быстрым, чтобы использовать его в real-time-решениях. Например, если нужно на уровне сайта очень быстро показать пользователю какие-то предварительные результаты запросов.
Но существуют определенные ограничения. Если у нас есть какие-то близкие по смыслу предложения (даже синонимы), их векторные представления могут быть кардинально противоположны.
Hi, world и hello, world — фразы вроде бы похожи, но косинусное сходство нам этого результата не покажет:
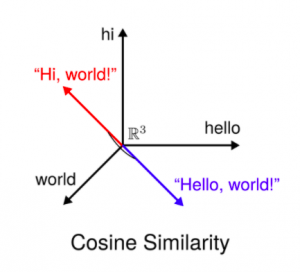
Сравнение фраз с помощью косинусного сходства
Как один из вариантов решения была предложена так называемая Soft Cosine Similarity.
Soft Cosine Similarity
Модель Soft Cosine Similarity можно назвать попыткой сделать семантический анализ перед тем, как считать матрицы схожести. Например, натренировав дополнительно модель word2vec, которая из контекста может определить близкие токены. Если две сущности будут находиться близко друг к другу, Soft Cosine Similarity нам покажет результат с достаточно высокой метрикой:
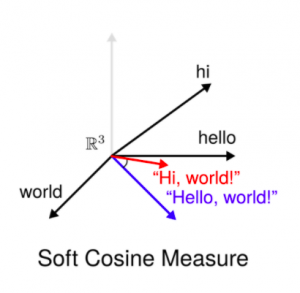
Сравнение фраз с помощью Soft Cosine Similarity
Еще одно преимущество этого подхода в том, что помимо тренировки word2vec-модели, мы можем построить поверх всего любой другой индекс фичей. Таким образом мы можем отлавливать опечатки, неправильно или неполностью введенные слова просто на уровне Similarity Query.
Но Soft Cosine не решает еще одной проблемы. Например, есть два предложения об одном и том же, но они состоят из абсолютно разных слов:
1. Obama speaks to the media in Illinois.
2. The president greets the press in Chicago.
Даже при тренировке вордовых моделей, скорее всего, Иллинойс никак не будет похож на Чикаго, поскольку Иллинойс — штат, а Чикаго — город. Эти два слова не могут быть синонимами.
Поэтому был предложен еще один алгоритм, который называется Word Mover’s Distance.
Word Mover’s Distance Similarity (WMD)
Word Mover’s Distance — это попытка измерить дистанцию, сколько одному предложению нужно условных единиц, чтобы преобразоваться в другое.
Мы определяем, насколько по смыслу одно предложение переходит в другое. Все просто: чем эта дистанция меньше, чем эти два предложения похожи.
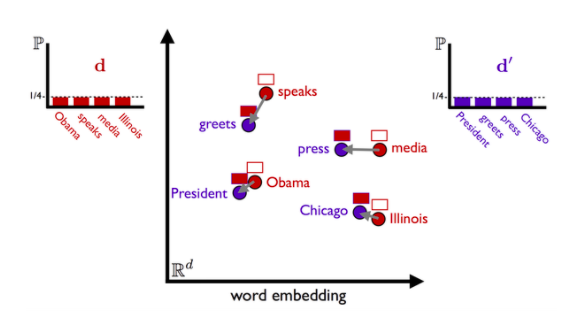
Сравнение предложений с помощью метода Word Mover’s Distance
Cosine Similarity, Soft Cosine Similarity и WMD Similarity: сравнение
Хотелось бы представить результаты работы всех трех видов сходств. И поскольку наш проект очень большой (ему больше 10 лет), так исторически сложилось, что у нас существует огромное количество keywords. Давайте посмотрим на таблицу и сравнивним ключевые слова:
| Query | Similar keywords by
Cosine similarity |
Similar keywords by
Soft Cosine similarity |
Similar keywords by
WMD similarity |
| 000 squares foot car dealership | 000 squares foot car dealership,
17000 squares foot, 16987 squares foot, squares foot, 9631 squares foot complex, buildable squares foot, squares foot facility, 50599 squares foot stores, 820000 squares foot facility, car dealership, car dealership service, used car dealership, 2 car dealership, new car dealership, squares, 78000 squares foot data center, foot, dealership information |
000 squares foot car dealership,
beds die cutter, beds liners, hot wedges welder, indoor heated beds, truck beds liners, double beds rooms, double beds occupancy, brass beds restoration, hot rolled billets, hot rolled angles, retractable truck beds, fluid beds dryers, beds shaker, forged grinding balls, medical beds wedge, beds springs, bed-spring distributor, beds surfaces cleaners, hot rolled rings |
000 squares foot car dealership,
toyota car dealership, bmw car dealership, honda car dealership, ford car dealership, chevrolet car dealership, franchised car dealership, citroen car dealership, rain repellent car washing, car shuttle train loaders, car carpet & upholstery detailing, car dealership showroom, citroen car dealership franchise, car seating dealership, car washing brushes, convertible car dealer, waterless car washing, hopper car vibrators, pre-owned cars dealership, rearing trunk dealership plaques |
Из таблички видно, что у нас keyword иногда состоит из пяти слов и также встречаются не совсем понятные вариации на тему этого keyword. Но также видно, как тот или иной вид similarity query находит похожие keywords.
Что еще заметно? Cosine Similarity больше сконцентрировался на квадратных футах (squares foot). В WMD сразу бросается в глаза, что можно сделать отдельные ключевые слова: car dealership, toyota car dealership.
Давайте теперь рассмотрим запрос/скорость выдачи:
| Cosine Similarity | Soft Cosine Similarity | WMD Similarity | |
| Inference time | 1.23 s | 158 ms | 59 ms |
| Query time | 1.03 ms | 24 ms | 100 ms |
Как видим, самые быстрые similarity, которые мы можем использовать — это Сosine Similarity. Он и подходит для решений в реальном времени. WMD similarity — самый долгий процесс.
Надеюсь, вам понравился наш разбор. Желаем приятных приключений!
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: