


С необходимостью отладки программ периодически сталкивается каждый PHP-разработчик. Как показывает практика, далеко не у каждого достаточно знаний для выполнения этой задачи. Некоторые даже более или менее опытные специалисты не всегда понимают суть отладки приложения, зачем это нужно и какие подходы существуют. Без этих знаний решить проблемы, возникающие время от времени на любом проекте, будет просто невозможно. Поэтому если вы PHP-разработчик, предлагаю вам уже сейчас разобраться в этой теме.
В этой статье я подробно раскрою понятие отладки и дебагинга, объясню, для чего могут потребоваться логи, профилирование и несколько других методов. Также опишу самые популярные инструменты отладки. И все это — на приближенном к реальному проекту примере.
Содержание
1. Что такое отладка
2. Добавление логов — как это работает
3. Что всегда нужно логировать
4. Коммуникация между сервисами
5. Opentracing / Opentelemetry — базовый инструмент для работы с логами
6. Способы хранения логов
7. Где можно использовать дебаг-возможности PhpStorm
8 .«Метод уточки» для дебагинга
9. Интересные возможности PhpStorm
10. Зачем вам профилирование?
11. Куда двигаться дальше
Что такое отладка
Начну с аналогии, далекой от IT, но очень показательной в нашей теме. На ранних этапах развития люди с любыми заболеваниями обращались к шаманам с просьбой излечить их. Те могли провести определенный обряд и предложить выпить зелье из травы или корешка. Помогло — отлично! А если нет — пробуем дальше. Да, перебирая зелья, можно со временем понять, что помогает при конкретной болезни.
Мне эта история напоминает разработчика, не умеющего пользоваться инструментами отладки.
Он может писать вроде бы работающий код, но не в состоянии разобраться с проблемой и понять, что же происходит в его проекте.
Сравните шаманов с современными врачами. Сегодня у них много устройств для первичной и вторичной оценки организма. Специалисты собирают множество данных о состоянии пациента и на основании результатов анализов пытаются понять, как сейчас работает организм, какие показатели в норме, а какие нет.
Все это становится основанием для постановки диагноза и вариантов лечения. У разработчиков все так же.
Девелопер использует инструменты отладки для анализа поведения программы, чтения логов, измерения параметров и т.д. Это позволяет определить место возникновения проблемы и решить, как ее «лечить».
Чтобы лучше представить себе организацию этого процесса на практике, разберем распространенный пример. Предположим, вы разработали онлайн-площадку для запуска интернет-магазинов. На сайте предприниматели регистрируют свои страницы, выкладывают товары, принимают заказы.
Таких сервисов в настоящее время много, вы сами их знаете. Сначала все хорошо: ваша площадка работает, продажи идут, бизнес зарабатывает деньги. Но однажды пользователи системы, те же предприниматели, просят добавить новый функционал — отправку на email отчетов о ежедневных продажах с перечнем товаров и сумм. Не выглядит как сложная задача, правда? В таком случае разработчики могут предложить подобную схему реализации функционала:
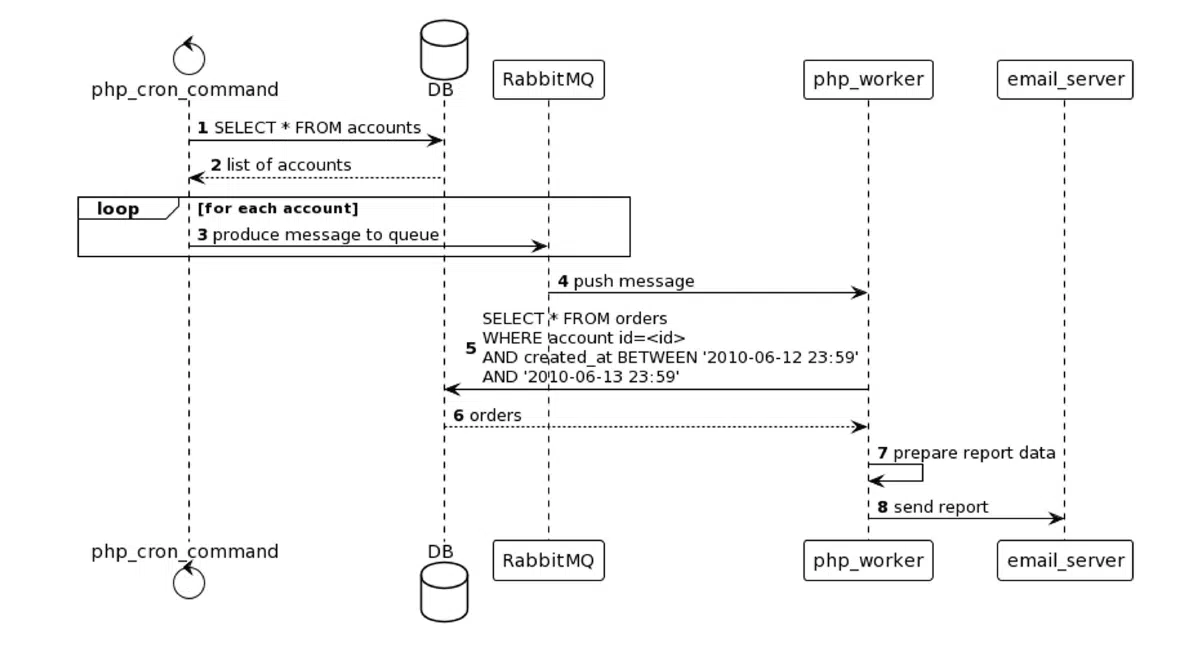
Рисунок 1. Схема процесса генерации и отправки отчетов
В первую очередь здесь есть cron, который запускает команду PHP CLI, которая со своей стороны выбирает пользователей-предпринимателей и по каждому из них публикует сообщения в очередь в RabbitMQ. Также предусмотрен обработчик, он же консюмер очереди RabbitMQ, который для каждого отдельного пользователя выбирает все данные о его заказе, рассчитывает прибыль конкретного предпринимателя, формирует текст сообщения и отправляет его на почту. Все работает корректно, пользователи довольны. Но впоследствии одному предпринимателю перестают поступать отчеты. Вы можете обратиться к коду крон-команды и обработчика в поиске источника проблемы и проверить базу данных, но это может ничего не дать.
В коде все выглядит правильным, и ситуацию можно описать классической фразой «Должно работать…». Именно так и говорят при недостатке инструментария для понимания, как работает система.
Вариантов проблемных мест много. Например, email мог не двинуться дальше из-за проблем с сетью. Также мог упасть обработчик очереди из-за ошибки в коде. А еще обработчик мог не получить сообщение от RabbitMQ, а крон-команда — не опубликовать сообщение в очередь. И это, не говоря о сбое в запуске крона. Как же быть?
Добавление логов — как это работает
Я советую начинать с добавления в систему логов, чтобы решить или предупредить описанную ситуацию. На рисунке 2 изображена схема, на которой я обозначил синими стрелками, где можно добавить логи в вышеупомянутую схему.
Кстати, отсутствие логов — это тоже полезная информация, помогающая оценить качество построения сервиса в целом:
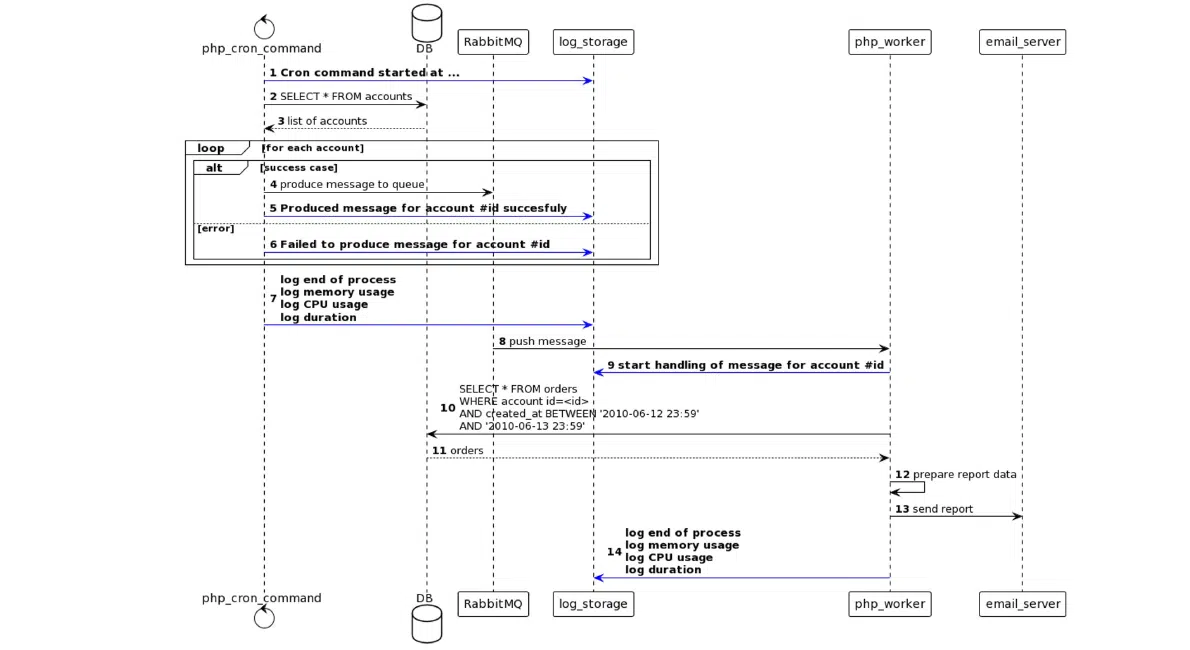
Рисунок 2. Схема процесса генерации и отправки отчетов с учетом логов
С помощью добавления логов при старте крон-команды можно понять, запускается ли она вообще. В логах при публикации сообщений видно, что оно точно был опубликовано RabbitMQи как минимум доставлено. Логи об ошибке публикации сообщения укажут на проблему с подключением к этой части системы из-за отсутствия сети или ошибки в настройках. Также следует залогировать продолжительность команды, оперативную память и CPU для исключения слишком долгой работы крона. Из-за этого пользователь просто не дождется публикации и обработки сообщения.
Вариантов, где встраивать логи, много. Обычно я добавляю запись логов в начале работы команды PHP: название команды, время запуска команды и другая дополнительная информация. Также обязательно добавляю запись логов в конце работы PHP-команды. Это позволяет убедиться, что она закончила работу.
К логам о завершении работы команды советую добавлять информацию об объеме использованной оперативной памяти, пиковом использовании процессорного времени и продолжительности выполнения самой команды. Это просто и наглядно. А когда вы видите, что и где происходит, решить задачу уже немного легче. Более того, для пользователей фреймворков Laravel или Symphony есть готовые инструменты для создания команд PHP CLI. То есть все уже настроено и протестировано сотни раз. Вам остается только понять: или проблема с настройкой тайминга крона, или вы сам крон забыли куда-то добавить. Такая ситуация может произойти во время деплоя на разные окружения, если у вас не настроен автоматический процесс деплоя. Описанный лог поможет быстро найти ошибку и понять, приступила ли программа к работе.
Отмечу, что ошибки тоже нужно логировать. Такие логи можно записывать в try…catch-конструкции.
Произошла ошибка? Логируется сообщение, где она произошла, в каком файле и в какой строке. Еще лучше логировать весь trace ошибки — то есть все передаваемые вверх эксэппшены. Ведь эта цепочка во фреймворках Symphony или Laravel может быть очень длинной. То же следует делать и с обработчиком.
Прежде всего нужен лог о том, что обработчик начал успешно читать сообщения. Здесь обязательно добавьте опознавательные знаки: обработчик получил уведомление пользователя с id=10. Так вы точно поймете, что его прочитали. Отдельно хочу упомянуть почту и другую коммуникацию с посторонними сервисами. Я рекомендую обертывать код в try…catch и писать в конце трая, что сообщение успешно отправлено. В кетче можно логовать, если что-то не было отправлено. Скажем, из-за сетевой ошибки или проблем с конфигурацией. Далее я еще расскажу более подробно о местах, где логирование крайне важно. А теперь вернемся к нашему примеру и оценим ситуацию после добавления логов.
Представим, что мы видим в хранилище логов только лог старта крон-команды. То есть крон запускается, но нет логов о начале обработки информации для пришедшего с жалобой пользователя. Многих разработчиков ситуация может поставить в тупик. В таком случае помогут дебаг-логи.
Один из их видов я бы отнес в категорию мастхев — речь идет о дебаг-логах для работы с базой и с возможностью включения и выключения этой функции. Это позволит писать запрос, который отправляется в базу, и возвращаемые ответы (последнее — опционально). Ведь результат может быть очень громоздким и его не всегда нужно логировать. Хотя иногда полезно видеть логи с результатом: что вернулось из базы, а что потом отдала ORM.
После внедрения таких логов вы, например, можете увидеть отправку запроса в базу данных с добавлением условия, что поле deleted_at должно быть null. Такое может случиться при использовании функции для работы с «мягким» удалением, которое встроено во фреймворк. На такую неочевидность довольно легко наткнуться. Часто фильтрация добавляется где-нибудь внутри фреймворка или ORM, но в коде построения запроса этого описано не будет. Поэтому в коде все выглядит понятно, а по сути это не так.
Логи помогут локализовать проблему. Они выделяют в скоупе сервисов, команд и обработчиков тот этап, на котором что-то пошло не так. Дебаг-логи позволяют более подробно посмотреть на дополнительную информацию о работе: с базой, сетью, с коммуникациями между сервисами и т.д. Бывает сложно понять, какой запрос был построен и отправлен в БД и увидеть реальную картину.
Вам может показаться, что логировать нужно все. Прежде всего, делать это надо сознательно. Вы можете залогировать так много всего, что на запись логов будет тратиться больше времени, чем на работу программы. При этом хранение логов в виде терабайтов текста может стоить столько, что прибыль от проекта сойдет на нет. Поэтому следите за балансом логов в вашем сервисе. Да и вообще писать логи в файлы, мне кажется, очень плохая практика. Для тех, кто до сих пор так делает, советую ознакомиться с 11-м фактором в методологии создания SaaS-приложений.
Что всегда нужно логировать
Я выделю основные случаи логирования. Остальные ситуации зависят от конкретных реализаций и архитектуры вашего сервиса.
- Основные этапы бизнес-логики
Нужно понимать, по какой именно ветке ветвления выполнялся код. Если в нем очень много разветвлений и нужно добавлять немало логов, то, пожалуй, пора задуматься над рефакторингом.
- Ошибки
Нужно логировать все ошибки, которые могут произойти в коде: ошибки работы с базой, сетевые ошибки и т.д. Убедитесь, что сервис корректно логирует runtime-ошибки. Проверяйте, корректно ли он записывает ошибки о недостаточном количестве оперативной памяти или о вызове несуществующей функции. Часто это уже реализовано в современных фреймворках. Помните: catch, который нацелен на класс \Exception в PHP, не покрывает весь список ошибок. Поэтому лучше использовать интерфейс \Throwable.
- Последовательность действий
Если какая-либо сущность обрабатывается поочередно несколькими обработчиками или крон-командами, ее следует логировать. В логах обязательно должна быть вся цепочка. Так вы поймете, где и какая команда отработала для каждой сущности, а где она даже не стартовала.
- Использованные ресурсы
Я имею в виду RAMи CPU. Это касается обработчиков типа консюмеров RabbitMQ или Kafka. Также советую отслеживать крон-команду. При постоянном добавлении логики в команду PHP CLI, сначала работающую несколько секунд, через год она может выйти на полчаса. При этом команда будет стартовать каждые 5 минут — и все из-за неуемного потребления памяти и процессорного времени.
- Продолжительность процессов
Здесь все просто: эти процессы правда помогают увидеть общую картину.
- Дебаг-информация
Речь идет о работе с базой, сетью и т.д.
Коммуникация между сервисами
Отдельно хочу немного рассказать о логировании между сервисами. Это важно во многих случаях. К примеру, монолит распилили на микросервисы. Или монолит — ядро, но в него приходят запросы, которые перенаправляются в один сервис, тот перенаправляет в другой — и образуется длинная цепь. В таких случаях бывает сложно разобраться, достался ли запрос от одного звена к другому. Пример такой коммуникации показан ниже — на рисунке 3.
Для решения проблемы можно применить идентификатор процесса. К примеру, UUID или случайная строка для определения идентификатора. Это необязательно будут отдельные сервисы. Могут быть и подблоки в коде, если бизнес-логика предполагает тысячи строчек и десятки классов. Тогда можно выделять процессы идентификаторами блока:
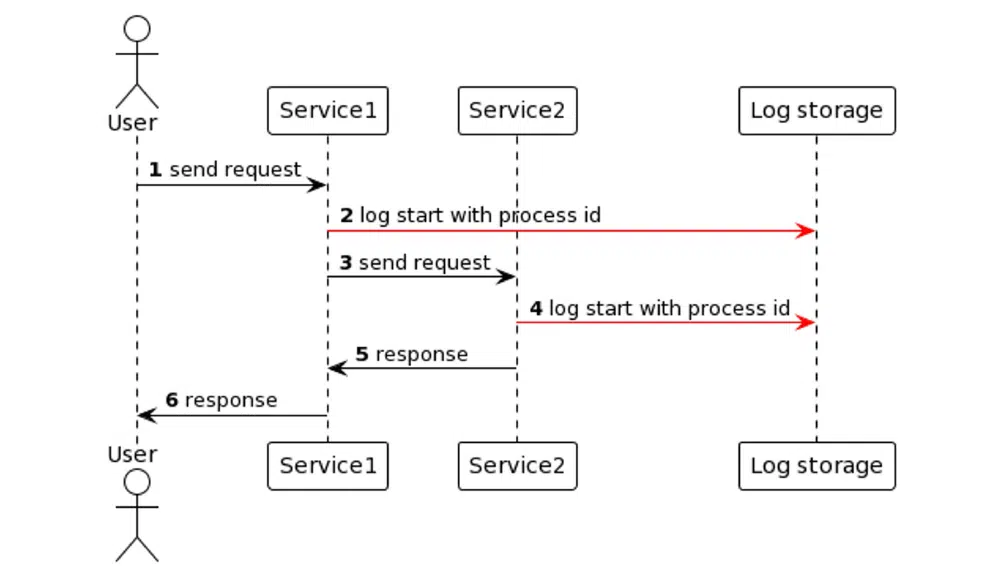
Рисунок 3. Схема коммуникации между разными сервисами
Я рекомендую передавать информацию в кастомных заголовках, например, через заголовок x-request-id. Когда второй сервис будет принимать такой запрос, он увидит заголовок x-request-id и переиспользует его в логах. Зная один x-request-id, вы сможете смотреть цепочку логов даже в случае коммуникации с несколькими сервисами поочередно.
Аналогичная ситуация с RabbitMQ и Kafka. Вы можете добавлять к публикуемому сообщению метаинформацию из x-request-id. После получения этого идентификатора консьюмером вы прочтете его и будете записывать следующие логи с использованием этого идентификатора — и вся цепочка действий сохранится. Это отлично помогает разобраться, на каком этапе остановится процесс обработки сообщения или запроса.
Opentracing / Opentelemetry — базовый инструмент для работы с логами
Поскольку логи нужны в каждом проекте, для работы с ними сделали очень удобные тулзы, значительно облегчающие работу. В Opentelemetry (или Opentracing, как он назывался раньше) есть SDK для около 10 языков программирования, включая PHP. Ознакомиться с тем, как работать с логами в Opentelemetry, можно по этой ссылке.
Способы хранения логов
Самый простой вариант — в сыром виде на сервере. Если у вас один сервер и невысокая нагрузка на уровне одного-двух тысяч логов в день, то вам вряд ли понадобится отдельное хранилище. Это легко реализовать и в Laravel, и у Symphony.
Но этот подход перестает работать при масштабировании проектов. Представьте, что у вас настроен автоскейлинг в AWS и количество серверов зависит от нагрузки. Или еще хуже: монолит разделен на микросервисы, поэтому есть 10 инстансов из монолита и 10 — для каждого сервиса. Собрать все воедино невозможно. Поэтому нужно хранить логи другим способом, и их здесь существует несколько.
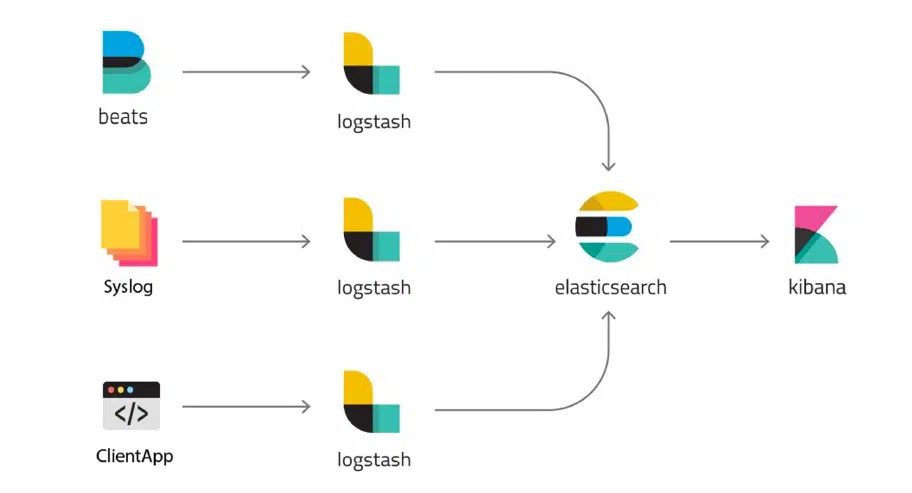
Рисунок 4. Варианты хранения логов
Первый — для работы с обычными файлами есть инструмент Filebeat. Он работает как демон на сервере, то есть это фоновый процесс. С помощью стека ELK, Elasticsearch, Logstash и Kibana он помогает хранить и отображать логи. Сценарий работы таков: Filebeat читает файлы, трекает изменения и пуше в Logstash. Тот, со своей стороны, хранит все в индексе Elasticsearch. Далее вы через UI в Kibana можете работать с индексами логов и производить по ним выборки.
Другой способ пригодится, когда у вас много файлов и логов, что приводит к большим затратам времени на запись и работу с файловой системой. Здесь поможет Syslog, который агрегирует поток логов и помещает их в память пачками. В этой статье я не буду подробно описывать, как работает эта тулза. При необходимости гуглите syslon-ng. Но скажу главное: этот процесс тоже настраивается со стеком ELK.
Следующий кейс — логи от клиентских программ. Вариантов их реализации множество, но основное все то же: Android, iOS и фронтенд могут пушить логи в Elasticsearch, используя Logstash.
Думаю, вы поняли основное содержание этой части: ELK покрывает широкое поле задач по работе с логами и ускоряет работу. Хотя Kibana неидеальна. В ней встречаются проблемы с разграничением пермиссий между пользователями и ролями, и по работе с конкретным индексом (особенно когда некоторые пользователи могут видеть определенные логи). Поэтому всегда держите в уме альтернативы. К примеру, Graylog. Он напрямую решает проблемы с пермиссиями: кто и какие логи может смотреть. В любом случае базовым хранилищем чаще всего будет Elasticsearch, а упомянутые тулзы заменят Kibana. Также советую посмотреть и в сторону Opentelemetry, которая тоже может выступать как хранилище логов.
И тут некоторые из разработчиков могут спросить: мы что, девопсы, чтобы это все настраивать? Мой ответ: да, иногда девелоперам приходится разбираться и в таких темах.
Если у вас возникла проблема с интеграцией логов и приложений, а девопса на проекте нет или сейчас он недоступен, программист обычно сам сетапит такую систему. Считайте, что это добавляет вам большее понимание, как работает ваша система.
Где можно использовать дебаг-возможности PhpStorm
Вернемся к схеме на рисунке 2, но допустим, что мы получили лог не только старта крон-команды, но и другие логи. Например, у вас может быть что-то вроде этого:

Рисунок 5. Пример возможных логов
Что мы видим: сообщение для определенного аккаунта продюсится, консьюмер начинает обрабатывать информацию из аккаунта, но появляется ошибка. Она связана с \RuntimeException, поэтому email не может быть отправлен на указанный аккаунт. Это уже полезно: видим место сбоя и можем углубляться в код, пример которого изображен ниже:
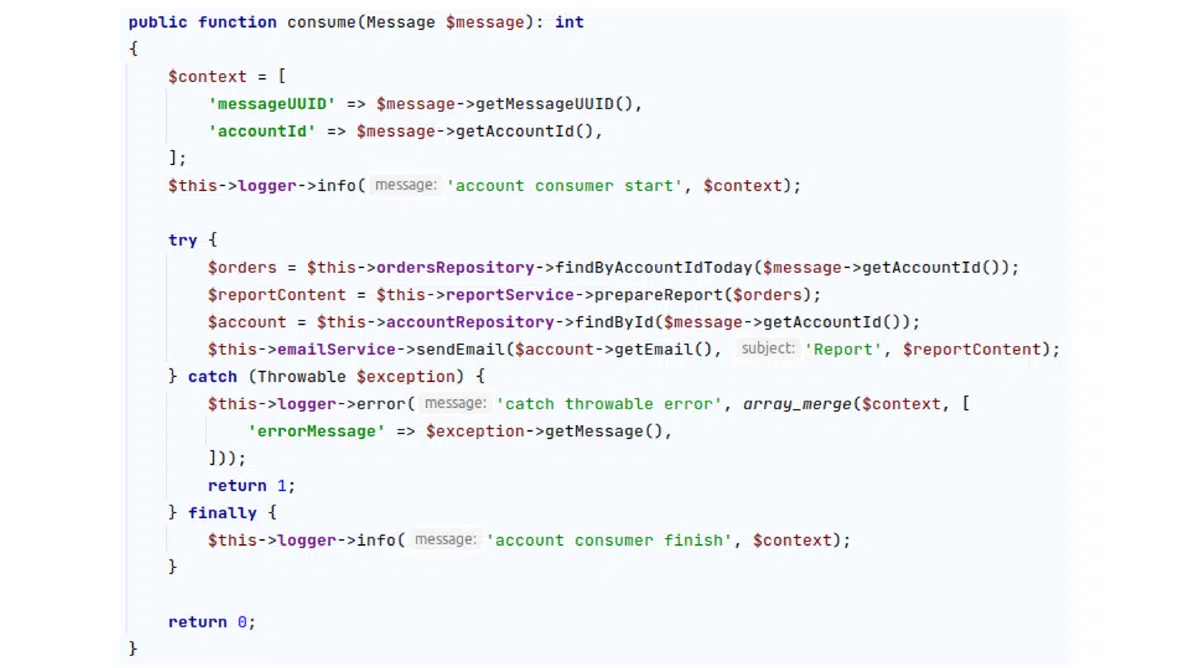
Рисунок 6. Пример кода консьюмера
Здесь есть какие-то try…catch, работа с репозиторием и сервисами и многое другое. Вы можете разбираться во всем, что называется, вручную, но я предлагаю упростить себе жизнь. В этом помогут Xdebug и PhpStorm. Учитывая, что проблема здесь связана с \RuntimeException, можно настроить PhpStorm на остановку во время дебагинга сразу в том месте, где выбрасывается ошибка.
На рисунке 7 изображено окно дебага PhpStorm. Оно позволяет посмотреть, скажем, Stack Trace, и поставить брейкпойнт при запуске кода в дебаг-режиме. Зачем их здесь ставить, если можно в коде ткнуть возле номера? Но ведь мы хотим поставить брейкпойнт на эксэпшен. Для этого заходите в View Breakpoints, где будет список активных брейкпойнтов — и к ним добавляйте свой:
Малюнок 7. Блок Debug в PhpStorm
Можете добавить PHP Exception Breakpoints, как показано далее:
Рисунок 8. Окно настройки брейкпойнтов
В нашем случае это \RuntimeException. Добавляем его и ставим галочку Suspend execution для остановки выполнения, когда система наткнется на такую ошибку. Остается сохранить настройки и запустить код.
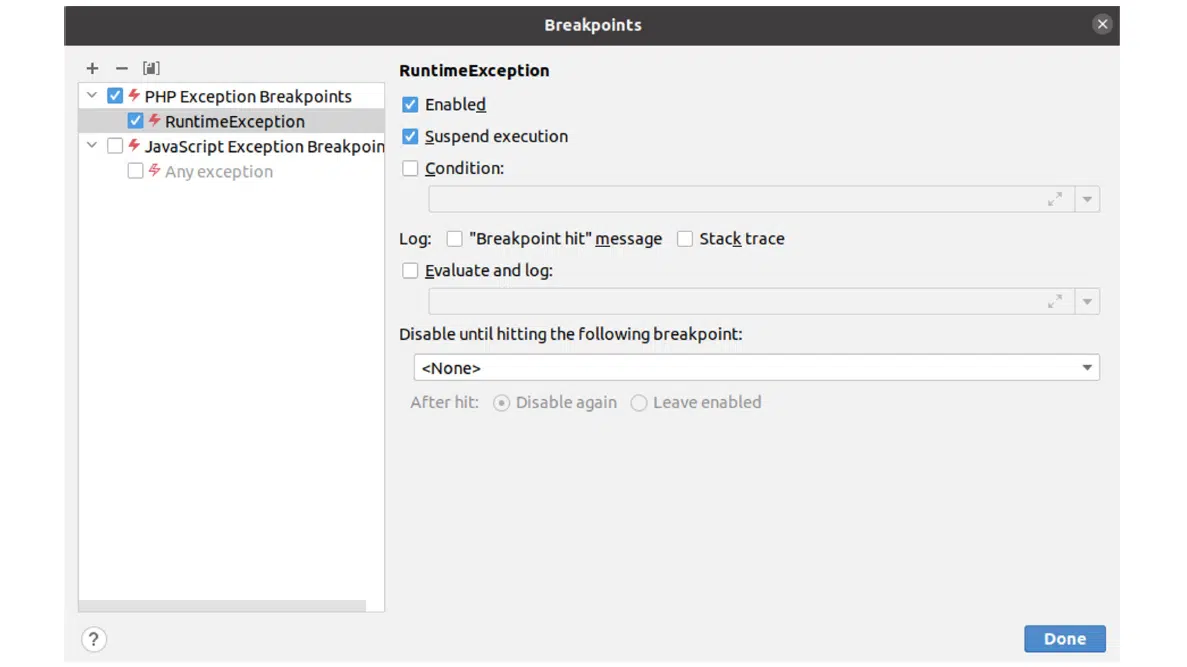
Рисунок 9. Окно настройки брейкпойнтов с добавлением \RuntimeException
На рисунке 10 видим, что к тестовому примеру добавлена проверка на длину репорта для пользователя. Это очень удобно. В нижней левой части экрана PhpStorm виден весь трейс вызова последовательности экспшена.
Также можно просмотреть доступные в области видимости переменные. Также есть проверка на длину контента: она не должна превышать 20 символов. А главное: вы видите, где скрыт эксэппшен — и уже вроде бы готовы решать проблему с ненаправлением сообщений:
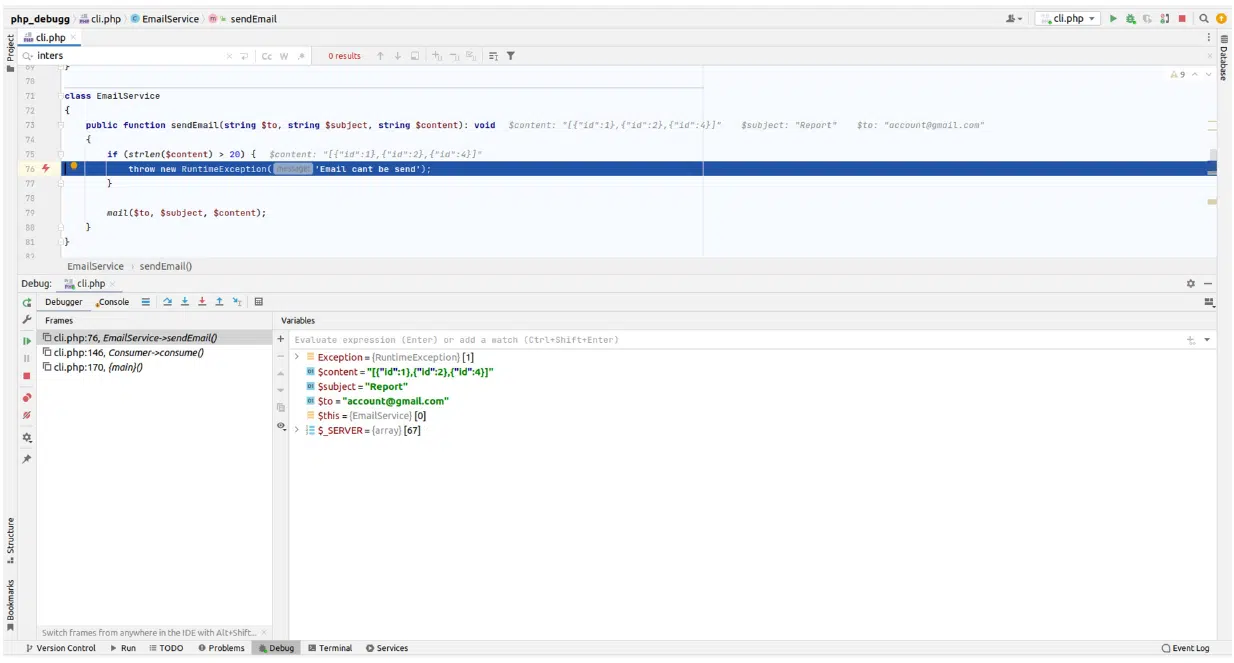
Рисунок 10. Пример остановки кода перед выдачей ошибки
Спрашивается: как понять, насколько именно длина контента превышает записанное значение? Мы видим, что это более 20 символов, но считать каждый из них неудобно. Здесь обратите внимание на наличие strlen для переменной content и на то, что дебаг-инструменты PhpStorm позволяют в рантайме выполнять код. Поэтому просто выделяем функцию strlen вместе с аргументами и нажимаем кнопку калькулятора, как это показано на рисунке 11.
После этого система покажет, что наш текущий отчет содержит 28 символов. Благодаря этому, постепенно идя от логирования к дебагингу и дальше, можно узнать, где произошла ошибка, из-за чего, и каким было условие, насколько были превышены тестовые ограничения.
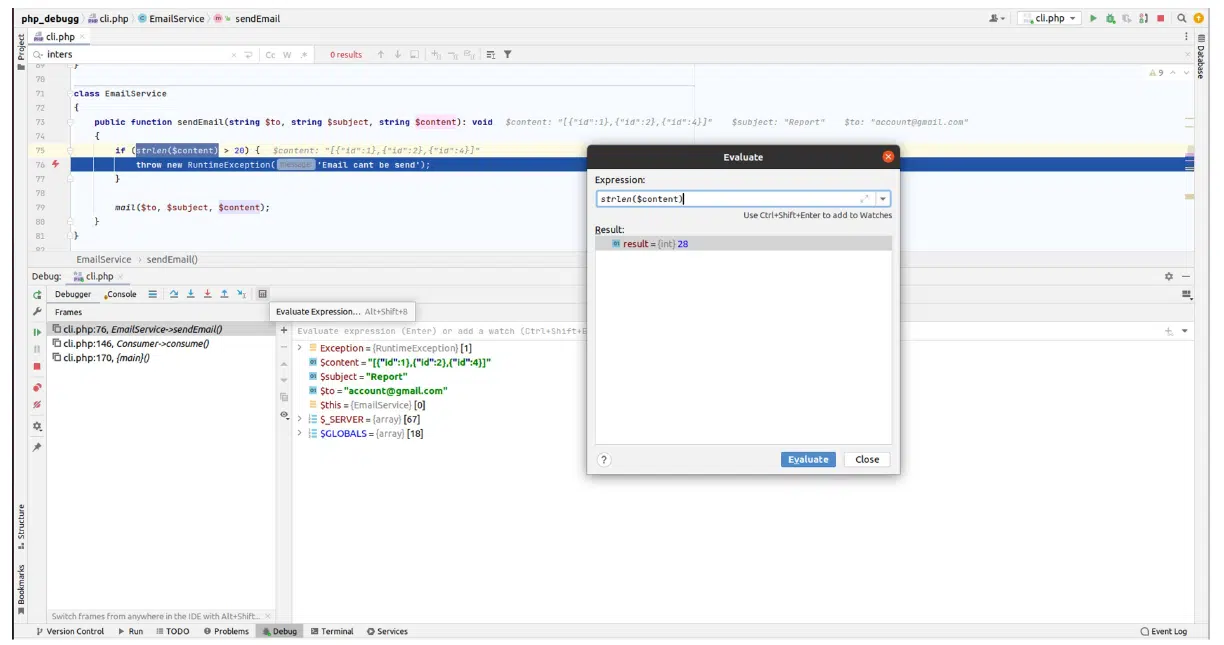
Рисунок 11. Окно выполнения кода во время дебагинга
В результате будни разработчика, который при отладке пытается по логам понять суть всех процессов, идеально описывается мемом:

«Метод уточки» для дебагинга
Дебагинг — это процесс поиска ошибок в программе. Для этого далеко не всегда нужны дебагеры и Xdebug. Иногда отлично может помочь так называемый «метод уточки». Я считаю его одним из самых полезных способов поиска источника проблемы в любом проекте.
Представьте, что кодите сложную бизнес-логику, но появляются ошибки, сбои в базе и т.д. Вы обращаетесь за советом к коллеге и описываете ему ситуацию: нужно вот это, я делаю такой запрос к базе, получаю такие данные, потом делаю вот это… В определенный момент вас озаряет: вот здесь при обработке запроса вы делаете что-то не так, как написано в таске. Именно благодаря описанию деталей проблемы и формулировке вопроса коллеги нередко удается самому найти ответ.
Почему этот способ называется «методом уточки»? Потому что здесь вам не нужен даже коллега — его заменит игрушечная уточка у монитора, с которой вы мысленно начинаете обсуждать проблему на проекте.
Как ни странно, такой «дебаг» очень действенный. Это доказано мной и многими знакомыми — попробуйте и сами. Изучение деталей реализации процесса — это и есть отладка в широком смысле этого слова. Неважно, что именно вы анализируете. Это может быть чтение кода, просмотр логов или описание степов в заметках. Все это пригодится не только для устранения проблем, но и при знакомстве с новым кодом, проектом или командой.
За счет этого, а также подключения Xdebug и «метода уточки» вы быстрее поймете, что происходит под капотом, разберетесь с логикой процессов и будете иметь полноценное представление о сервисе. Как результат, вы сможете быстрее и эффективнее создавать новые фичи.
Интересные возможности PhpStorm
Этот инструмент скрывает множество опций настроек программ. Я выделю несколько, на мой взгляд, наиболее полезных:
- Условные брейкпоинты
Представьте, что в цикле есть 1000 итераций, но нужно остановиться на 403-й, потому что именно в ней выбирается плохой ID и что-то идет не так. Для этого в брейкпойнте нужно нажать правой кнопкой мыши и указать конкретное условие для остановки процесса.
- Брейкпоинты с логированием
Эти брейкпоинты могут не останавливаться, а просто писать информацию о проблемах. Такое решение позволит, например, в Laravel и Symphony не добавлять логи для дебагинга, которые понадобятся только разово. Также подобная функция пригодится при дебагинге библиотеки, где не особо напишешь код. В таком случае добавленный в коде брейкпоинт залогирует нужный текст и переменные.
- Брейкпоинты для эксэпшенов
Раньше в тексте я уже рассматривал пример, когда много кода, но выбрасывается непонятный эксепшен, и ничего нет. Здесь вам и поможет этот тип брейкпоинта.
- Брейкпоинты, которые не останавливаются
Благодаря таким брейкпоинтам, чтобы не переписывать код программы и библиотеку, можно вставить фрагменты кода PHP, которые немного изменят логику. Это идеальное решение, когда вам нужно просто посмотреть, что даст другое выполнение кода.
- Изменения значений переменных в рантайме
Обычно при появлении ошибки в длительном процессе нужно сетить много моментов, чистить базу, заново все настроить и сбросить для повторного запуска. За счет изменения значения или строки буквально в одном месте вы экономите время. Правда, это работает не со всеми значениями.
- Выполнение фрагментов кода во время дебагинга
Подобно процессу определения длины отчета.
Зачем вам профилирование?
 Этот мем – красноречивая иллюстрация о разработчиках, которые влезают глубже в программу, пытаясь понять, что с ней происходит.
Этот мем – красноречивая иллюстрация о разработчиках, которые влезают глубже в программу, пытаясь понять, что с ней происходит.
Один из этапов такого погружения – профилирование. Чтобы разобраться, что это и где используется, обратимся к примеру. Ниже приведена ошибка из-за проблем с памятью (рисунок 14). Вы еще не знаете, где она и почему возникла. В логах картинка проста, но неочевидна: сообщение продюсируется, обработчик начинает работу, но все падает по памяти:

Рисунок 14. Пример логов
Поможет профилирование программы. Начать его можно с обычного профайлера, встроенного в PHP-дебагер (его нужно только настроить в php.ini). Для визуализации процесса рекомендую использовать KCachegrind. Ниже — репорт в этой тулзе по профайлингу:
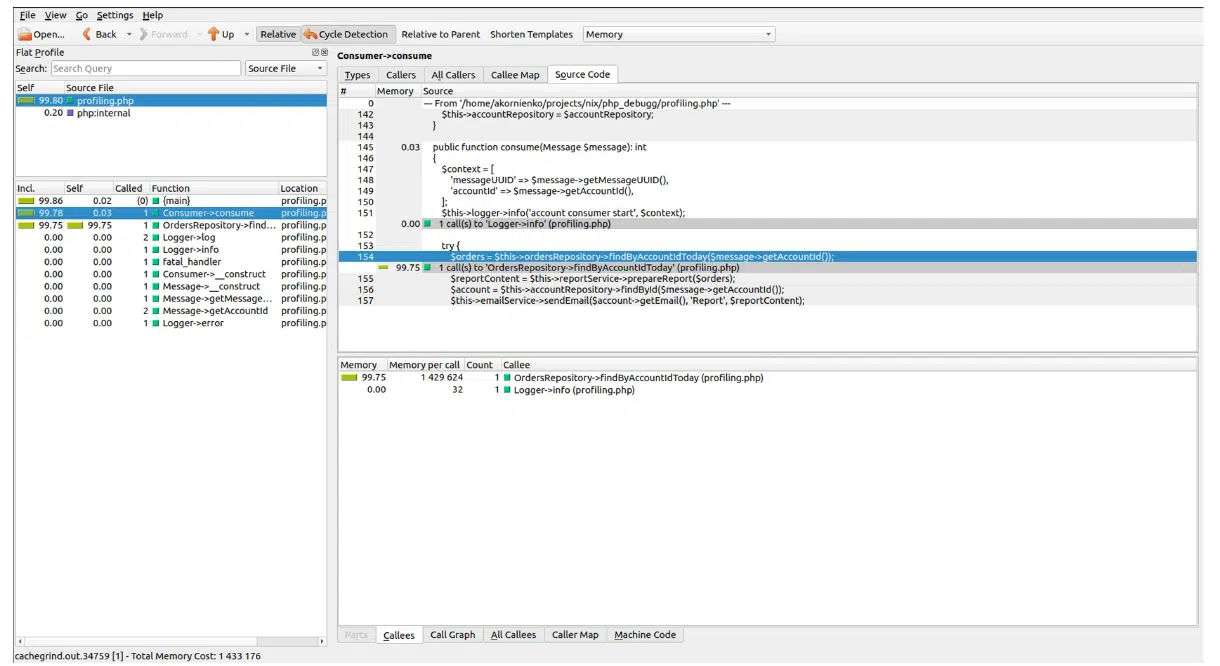
Рисунок 15. Пример открытого отчета профилирования в KCachegrind
Здесь много возможностей для отображения собранной информации. К примеру, можно выбрать данные памяти или процессорного времени. В моем случае после запуска тестового консьюмера кода в начале трая видна работа с репозиторием, занимающим 99,75% памяти. Это сразу указывает на проблему.
Причины и варианты решения могут быть разными. Предположим, по контексту программы может выбираться большое количество записей. Приходится конфигурировать доктрину, чтобы она не переводила все в сущности. И можно сделать лимиты и чанкование выборки или использовать курсоры. Но это уже детали реализаций. Главное, что следует запомнить: профилирование показало нам место повышенного потребления памяти. Причем я запускал это на кейсе, когда мы получаем ошибку. Несмотря на то, что программа была прервана, полученная до падения информация все равно достаточна для принятия решения.
Помимо этого профайлер может строить дерево вызовов (рисунок 16). Здесь изображен процент использования памяти и CPU, и показано, что и где было вызвано. Этот функционал пригодится не только для поиска сбоев, но и при изучении кода нового вам консюмера с десятками вложенных сервисов.
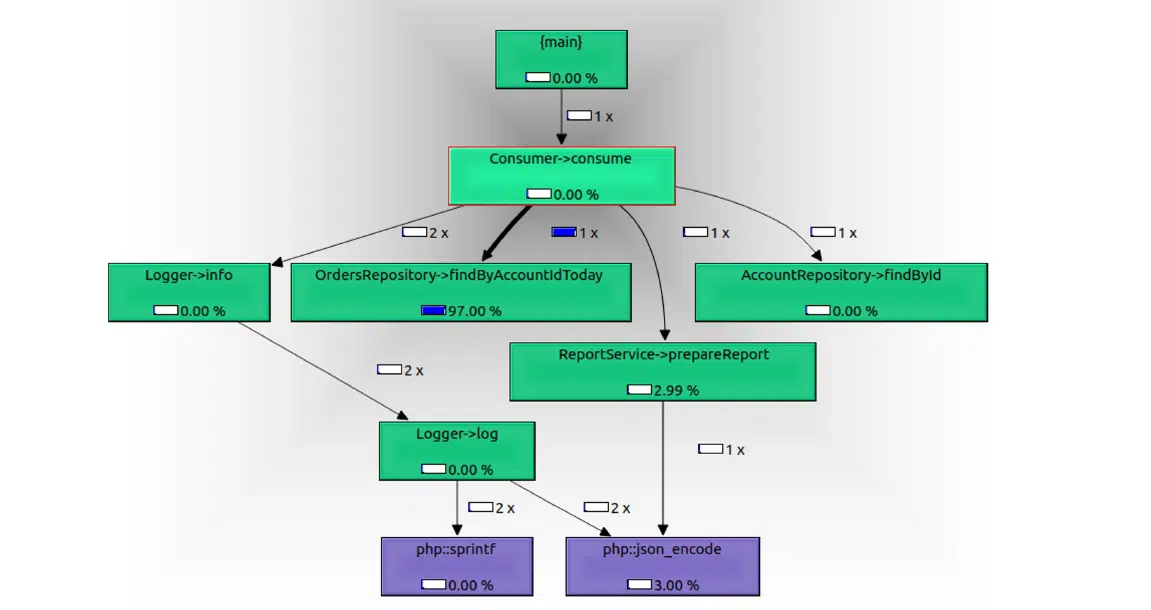
Рисунок 16. Пример дерева вызовов в KCachegrind
Куда двигаться дальше
Инструменты отладки нужно использовать комплексно. Логирование сужает область поиска проблемы, а дебагинг, профилирование и другие способы помогают разобраться в деталях. Их совместное применение даст реальную выгоду и ускорит поиск решения.

Но это еще не все. То, что вы прочитали в этой статье — краткий экскурс в тему отладки. Чтобы уверенно овладеть этим скиллом, советую постепенно изучать и другие инструменты дебагинга, а их немало. Сориентирую вас, куда можно двигаться дальше, и порекомендую обратить внимание на следующие тулзы:
- Sentry — мощный инструмент для трекинга различных эксэпшенов в приложении.
- New Relic — имеет различные возможности для отладки и мониторинга приложения, а также широкую функциональность – вплоть до профилирования кода.
- Xhprof — изменяет профайлер PHP таким образом, чтобы профилировать не весь процесс, а конкретный метод. Это полезно в больших фреймворках с раздутой иерархией и множеством вложенных классов.
- Prometheus и GrafanaLabs — эти инструменты для разных метрик в основном нужны для продакшена. Они могут сохранять и отображать значения разных показателей. Например, количество сообщений в секунду, количество обрабатываемых консюмером из RabbitMQ или Kafka сообщений, величина RPC приложения, бизнес-метрики и т.д. При этом метрики будут иметь хорошую, наглядную визуализацию.
- Blackfire — достаточно популярен в крупных проектах, хотя и платный инструмент дебагинга.
- Graylog может улучшить поиск логов и обладает некоторыми функциями, отсутствующими в Kibana.
- Datadog применяется для мониторинга сервисов, поддерживает работу с разными видами метрик и логов.
- Charles можно использовать как прокси для трекинга всего трафика. Его можно встроить в приложение и наблюдать за отправляемым трафиком. Больше подходит для отладки клиентов и коммуникации фронтенда с бэкендом.
- WireShark — этот снифер напоминает Charles, но имеет больше функций. К примеру, позволяет сканировать локальную сеть в компьютере даже без настройки прокси. Таким образом вы сможете подключиться к настроенной в Docker сети и понять, какие запросы и где именно проходят. То, что нужно в работе с большим количеством межсервисных сообщений, сырыми запросами во взаимодействии с базой и формировании HTTP-протокола. Вы сможете спуститься по всем уровням OSI и посмотреть, что происходит — вплоть до отправляемых пакетов. Впрочем, это нужно при дебагинге сети, и в моей практике понадобилось только раз. Но все это полезно знать тем, кто стремится развиваться как профи.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: