«Хотите жить в современном мире, смиритесь, что конфиденциальности не существует»: познакомьтесь с компанией, которая решает, получите ли вы кредит, и знает, за кого вы голосуете на выборах

Как вы думаете, как банки решают, дать ли вам кредит? 20 лет назад они смотрели кредитную историю. Сейчас — им достаточно ваших комментариев в Facebook. А собирает и анализирует для них эти данные компания Artellence.
Журналистка Highload пообщалась с основателем Artellence Владимиром Лозовым и узнала, что о ней может сказать ее фото в Instagram и можно ли как-то защититься от «всевидящего ока».

Владимир Лозовой, основатель Artellence
Мы создали то, чего на рынке не было
Раньше я работал в стратегическом консалтинге. Катался по разным странам Европы, помогал директорам крупных компаний в решении вопросов. Это была интересная работа, но почти в каждом проекте нам было сложно строить стратегию из-за нехватки данных. Поэтому, когда я захотел создать свою компанию и начал искать идеи, то остановился на сервисе, который помог бы решить эту проблему.
Оригинальная реализация выглядела не совсем так, как сейчас: мы создали быстрые онлайн-опросы, а анализ соцсетей был «дополнительной плюшкой». Но мы поняли, что проводить даже микроопросы сложно и неприбыльно, а клиенты больше интересуются аналитикой соцсетей. Так что мы сконцентрировались на этом. Это было шесть лет назад.
В итоге получилась необычная штука для рынка: если до этого мы едва отличались от соцопросов, то теперь мы создали то, чего на рынке до сих пор не было.
Большинство крупных компаний на рынке кредитования — наши клиенты
Основной бизнес, с которым мы сотрудничаем — микрофинансовые организации (МФО) и банки. Они запрашивают у нас информацию о своих потенциальных заемщиках, а мы говорим, стоит им давать кредит или нет. Строим свой анализ на базе открытой информации о человеке, которая доступна абсолютно каждому и не закрыта настройками приватности: профили и комментарии в соцсетях, объявления на маркетплейсах и данные с сайтов работы.
Для людей без кредитной истории это большой бонус — мало какие банки хотят рисковать своими деньгами и выдавать им кредит. А мы анализируем жизнь человека и говорим: это классный человек, по своему поведению в интернете он похож на тех, кто возвращает кредит, давай дадим ему кредит. Он никогда не брал и не возвращал кредиты, но давай попробуем.
Если наша система скажет, что кредит какому-то конкретному человеку лучше не давать, это тоже хорошо. Большой процент заемщиков — это люди, которые живут на грани своего дохода. Некоторые из них настолько увязли в долгах, что не стоит давать им лишнюю финансовую нагрузку, потому что они и так с ней сейчас не справляются.
Почему ответ позитивный или негативный — мы сказать не можем. Сейчас модели такие сложные, что их невозможно объяснить. На вход подается очень много точек информации о человеке, а на выходе — только финальный результат.
По кредитам мы работаем больше чем с половиной рынка. Большинство крупных компаний на рынке кредитования — наши клиенты.

Масштаб деятельности компании. Скриншот с сайта Artellence
Анализ открытых данных может повлиять даже на то, кто будет следующим президентом Украины
Второе важное направление — это политические проекты. С помощью открытых данных можно повлиять на то, кто будет следующим президентом Украины.
К нам обращаются политики, которые строят свой имидж. У них есть месседжи, которые они хотят донести до населения — но они не знают, к кому им обращаться. Чтобы решить эту проблему, мы анализируем людей и разбиваем их на микросегменты, исходя из их интересов. Затем это накладывается на программу, которая есть у политика.
Допустим, население Киева можно разбить на 50 небольших сегментов. Из них политику, который хочет говорить о повышении субсидий, нет смысла обращаться, например, к айтишникам. Его целевая аудитория — пенсионеры и малообеспеченные люди. Именно с этим сегментом он и будет работать. Этот пример логичный, но во многих задачах решение без глубокого анализа неочевидно.
Имена политических клиентов мы не раскрываем — у нас подписаны соглашения о нераскрытии информации.
Через пять лет еще больше сервисов будут использовать данные для принятия решений
Мы используем три больших куска технологий по обработке данных.
- Обработка изображений: нужно распознавать, кто на них находится.
- Работа с текстами. Например, для политических целей мы анализируем тексты (комментарии и т.д.) и пытаемся сформировать общее настроение общества. Мы создали свой алгоритм, который позволяет понимать суть текста. Не просто по ключевым словам что-то анализировать, а вытаскивать основную идею.
- Все остальные алгоритмы, которые позволяют обрабатывать данные. Например, алгоритм поиска ближайших друзей человека. Мы анализирует плотность связей в графах. Также есть много алгоритмов базового машинного обучения, которые мы используем для поиска людей, анализа их интересов.
Отдельное направление — это ускорение сбора, обработки и анализа данных. Комментарии и изображения мы считаем в миллиардах, так что это очень большие технические задачи. Мы активно работаем над снижением нагрузки: как быстрее это все посчитать, распараллелить на много потоков.
Часть из наших алгоритмов мы написали с нуля. Например, анализ суржика. Но если были открытые готовые решения, мы брали их и подгоняли под свои цели. Так было с алгоритмами обработки изображений.
Сейчас у нас чуть меньше 20 технических специалистов. Они работают в четырех командах:
- Data science — создают финальные продукты и модели.
- Backend — работают над передачей и обработкой данных через API.
- Сбор данных из различных источников.
- Ускорение обработки информации на сервере.
Сейчас мы сфокусированы не на добавлении новых функций, а на расширении экосистемы наших продуктов: то есть того, где еще можно применить анализ данных. Я верю в то, что через пять-семь лет все люди будут еще более оцифрованы, чем сейчас. И все больше сервисов будут нуждаться в открытых данных: кому дать самокат покататься, кому — нет; кому дать в аренду машину, кому — нет.
Большинство людей оставляют о себе хоть какую-то информацию — даже почти пустого профиля достаточно для анализа
Мы не переходим границы приватности и работаем только с данными, которые люди открыли для каждого желающего. Например, если человек закрыл список друзей — мы его не увидим.
О некоторых людях мы ничего не знаем, но процент таких людей небольшой. Большинство оставляют о себе в интернете хоть какую-то информацию — хотя бы в объявлении на OLX. Кроме того, мы можем анализировать человека по страницам его друзей — даже если у него самого профиль пустой. Точность модели будет такая же, как если бы мы анализировали самого человека.
Те данные, которые мы анализируем, не являются персональными по украинскому законодательству и по законам тех стран, на которые мы нацелены, а это Вьетнам (там мы уже запустились) и Юго-Восточная Азия. В Европе и Америке с этим сложнее, но там мы не работаем.
Персональные данные — это полные имя и фамилия, адрес проживания. А мы можем видеть только никнейм человека из соцсетей и город его проживания. Но если человек напрямую попросит удалить его данные из нашей базы, мы это сделаем.
Ваша конфиденциальность заканчивается, как только вы заходите в интернет
Вы должны понимать, что собираем информацию не только мы. Например, Facebook тянет кучу информации и со своих, и с других серверов — всех приложений и сервисов, которыми вы пользуетесь. Посмотрите в настройках. Все это делается в рекламных целях и не только Facebook. Просто они говорят об этом публично, а другие — нет.
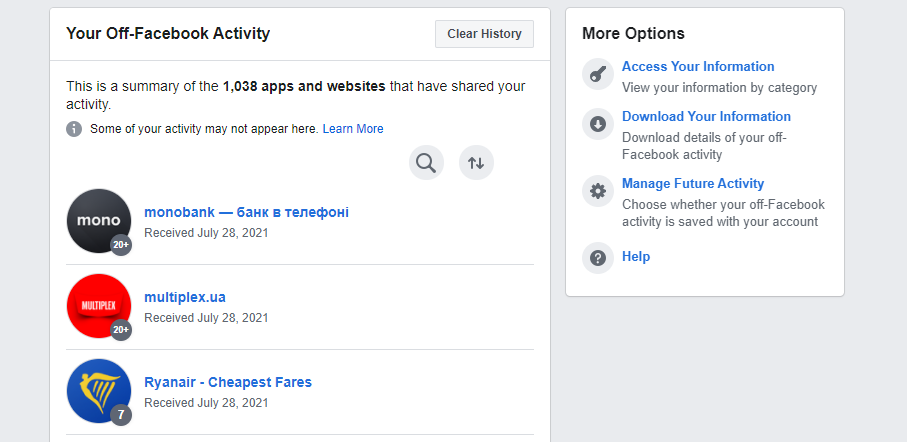
Список, кому Facebook передает информацию о вас, в настройках соцсети. Можно посмотреть по ссылке facebook.com/off_facebook_activity/activity_list
Когда человек регистрируется в интернете, он понимает, что на этом его конфиденциальность закончилась. Каждый должен принять решение: он пользуется интернетом и телефоном или нет. Если да, то он понимает, что про него все будет известно. Если человек хочет жить в современном активном мире, он должен смириться с тем, что конфиденциальности не существует.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: