

Как чемпион мира по игре в го проиграл нейросети и при чем здесь современные видеоигры

Индустрия GameDev начиналась с 8-битного Mario и Sonic. Сейчас же это настоящие экосистемы, которые визуально не уступают кинофильмам. Это виртуальные миры, созданные руками людей.
Чем выше уровень игр, тем больше новых трудностей для разработчиков. О том, что это за трудности и как искусственный интеллект (AI) помогает их решить, рассказал Борис Працюк, CTO в Pawa, в рамках Big Data, AI & Machine Learning Conferences от Projector. А мы сделали для вас конспект его выступления.
Человек VS Машина
Первым шагом, когда машинное обучение всерьез начало врываться в нишу разработки игр, стала известная игра го, суть которой – окружить больше территории, чем противник. В то время чемпионом мира по этой игре был южнокореец Ли Сидол. А компания DeepMind (сейчас принадлежит Google) на протяжении пяти лет тренировала своего агента AlphaGo — алгоритм, который учится играть по тем правилам, что и люди.
В 2016 году произошло очень важное событие — турнир между Ли Сидолом и агентом от DeepMind. В итоге Ли удалось выиграть лишь одну из пяти игр. Сам игрок даже извинялся перед земляками за свое поражение. Но он проиграл не из-за слабости, а потому, что технология стала очень мощной.

Люди начали играть против машин / deepmind.com
После этого была компания OpenAI. Она организовала международный чемпионат OpenAI Five, где люди играли против машин. Первый матч состоялся в 2018 году, и один из чемпионов все же победил алгоритм, мотивируя это тем, что тут более сложная стратегия, чем в го. В 2018-2020 годах агент стал еще лучше. Ему дали правила, гайды для обучения и объяснили, как управлять персонажами. Агенту дали контроль в игре, и он прошел миллиарды сессий.
В результате он научился играть лучше, чем человек. Чем сложнее становилась архитектура, тем лучше нейронная сеть выигрывала у людей более сложные партии.

Агент научился играть лучше, чем человек / openai.com
После победы агента DeepMind в го они сразу же начали работать над агентом AlphaStar для игры StarCraft. А в Южной Корее в StarCraft играют все.
Потому победа AI была бы максимально показательной — тинейджеры не верили, что кто-то может обыграть их суперстар-чемпионов.
Агента представили в 2019 году. Чем больше времени уходило на тренировку, тем лучше он становился и в конце концов тоже победил человека. Детальный разбор того, как тренировался агент, был опубликован в журнале Nature.
Машина VS Машина
Развитие AI на этом не остановилось. В 2019 году появилась Emergent tool use. Этот процесс описать проще. Есть два агента — красные, которые играют против еще двух — синих. Две машины против двух машин. Задание синих агентов — убегать, а красных — поймать синих. Во время миллионов итераций первенство переходило от одной команды к другой. Поначалу синие научились баррикадировать входы в комнату при помощи коробок. Потом красные, изучающие окружение, нашли треугольную рампу, которую они поместили под стенку, смогли попасть внутрь и поймать синих. Потом синие поняли, что каждый раунд начинался с задержкой в 3 секунды, и заносили рампу внутрь комнаты, после чего уже баррикадировались. Еще миллионы повторений — и красные начали использовать физику: они отталкивались от грани, таким образом падали в комнату и ловили синих.

Миллионы повторений — и ИИ научился использовать законы физике в игре / openai.com
Во время обучения использовалась техника reinforcement learning (обучение с подкреплением). При каждом проигрыше алгоритм «наказывали», в случае победы — «вознаграждали». Поэтому агенты делали все ради победы, используя баги программы и решения, которые не могли предвидеть даже авторы алгоритма. Хоть и звучит футуристично, но на самом деле, это просто математическая функция.
В 2020 году компания DeepMind разработала модель MuZero. Они использовали general-алгоритм, который был результатом всех наработок AlphaGo и AlphaStar, его тренировали на 57 разных играх.
Они не давали программе какого-то конкретного направления в обучении, агент учился сам. Тебя поймали — это плохо. Скушал много печенек в PacMan — круто.
Алгоритм стал более общим. То есть мы можем брать алгоритм, очень внимательно прочитать paper и смотреть, как его можно имплементировать в своих играх.
Еще один интересный пример — GameGAN: PacMan 2020 года от Nvidia. Они не просто научили агента играть в PacMan. Они используют двух агентов: один рисует уровни, другой их проходит. В этом случае один — автор левела, а другой — проходит его. Эта идея и гипотеза в перспективе может решать некоторые проблемы в AI.
Трудности при создании игр
В разработке игр есть определенные трудности, с которыми ИИ может помочь справиться. Мы пообщались с несколькими гейм-компаниями и выделили основные челленджи.
Новые уровни
У вас выходит игра и вы рисуете сто уровней. Она вышла на рынок, все в нее играют, и количество уровней, которые нужно сгенерировать, вырастет до астрономических масштабов. А это все делают люди и это нужно автоматизировать.
Новые фичи
Когда у вас на рынке есть игра, то ее нужно поддерживать и добавлять новые фичи. При этом нужно держать regression testing в каких-то рамках. Иначе тестирование может занять больше времени, чем сама разработка. Это тоже необходимо автоматизировать.
Текстуры
Иногда люди делают ошибки. Например, неправильно экспортируют текстуры из редактора. Потом это все сливается в репозиторий, едет в build и на выходе получаем кривую башню у танка, потому что она съехала.
Толпа
Тут речь не о точках на карте, а о толпе, которая должна быть более-менее похожей на живую. С разной внешностью и характеристиками. Это еще один челлендж, который до конца не разрешен, хотя определенные наработки уже существуют и мы поговорим о них чуть позже.
Scene beautification
Вы нарисовали главную сцену, где происходит действие, и вам нужно сделать ее живой: добавить свет, ветер, другие эффекты. Вроде бы, это простое и понятное задание, но оно занимает очень много времени. Поэтому, когда вы набросали скетч сцены, а кто-то должен ее раскрасить, то это как раз задание для AI.
Тестирование
Тестирование уровней на game logic и playability — это тоже очень большая проблема. Несбалансированные игры отпугивают людей, поскольку они не могут их пройти.
Multiplayer
Сейчас все пытаются делать многопользовательские игры. Но если игра новая и нет достаточного количества игроков, то необходимо создавать ботов и прописывать им логику поведения, а это очень сложно, поскольку обычными if/else полноценно нельзя описать логику игры.
Как в их решении помогает ML
Перечисленные выше трудности может помочь разрешить ML. И некоторые из них он уже решает! Одним из последних решений был ML-Agent 2.0 от Unity в 2021 году. Это определенный набор инструментов, встроенных в студию Unity, которые позволяют тренировать поведение и некоторых персонажей или объекты.
Представим себе, что есть трасса, где игроку нужно обгонять автомобили. И вам нужно создать для игрока оппонентов разного уровня сложности: чемпион, середнячок, новичок. И вместо того, чтобы описывать все эти уровни кодом, вы можете взять ML-Agent и натренировать его. По примеру красных и синих агентов, о которых мы говорили ранее. Чем больше итераций — тем выше квалификация. Достаточно детальные туториалы можно найти на YouTube.
Все же, это просто инструмент, который позволяет нам вместо того, чтобы писать код — просто описывать, что должен делать агент. Мы выступаем супервайзером этого процесса, и когда нам достаточно, мы его приостанавливаем.
Еще один момент, который занимает много времени — анимация. При создании персонажа, чтобы удержать хребет, нам нужно указать очень много элементов: повороты головы, кистей рук, глаз. Для этого нужно очень много фреймов. В некоторых студиях уже есть упрощения: вы рисуете только ключевые позиции, а далее все прорисовывается автоматически. Но для определенных небольших и красивых моментов это все равно нужно делать вручную.
Например, ребята из компании Banzai набрасывают позу своего персонажа, базируясь на шести ключевых точках. У них была гипотеза, что позу персонажа можно прорисовать зависимо от траектории движения этих точек. То есть не прорисовывать все элементы, а выставить некоторые точки нейронным сетям. Так и произошло. У них было 115 тысяч семплов поз, и они просто научили нейронные сети их дорисовывать. В данном случае ты просто рисуешь траекторию движения центральных точек, а поведением всех остальных управляет нейронная сеть.
Это очень интересный кейс. Но для того, чтобы натренировать нейросеть, им понадобилось руками нарисовать 115 тысяч кадров. Если же вы делаете свою игру и у вас уже есть материал, то все, что остается, — это сделать из него нейронную сеть.
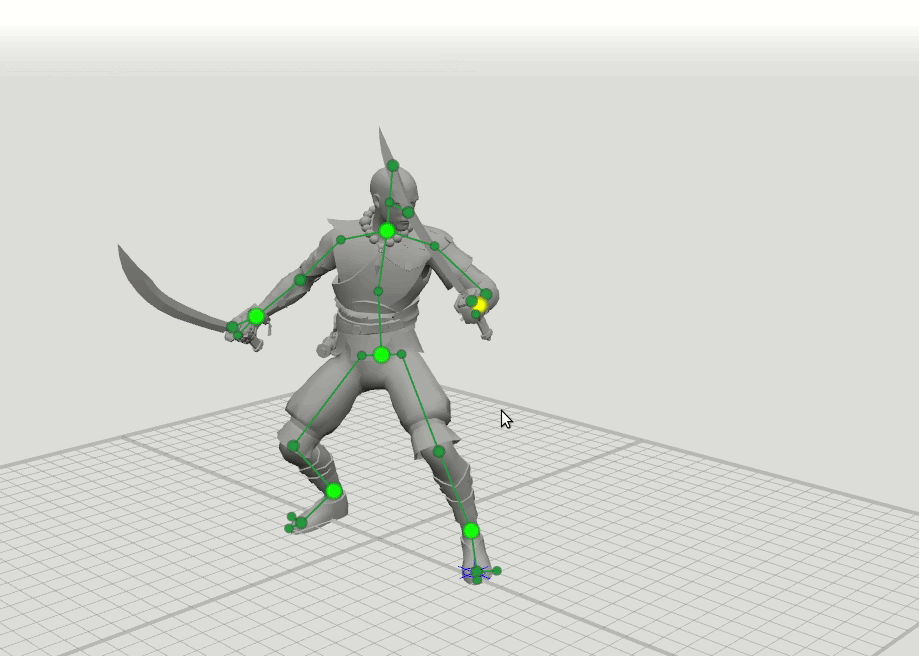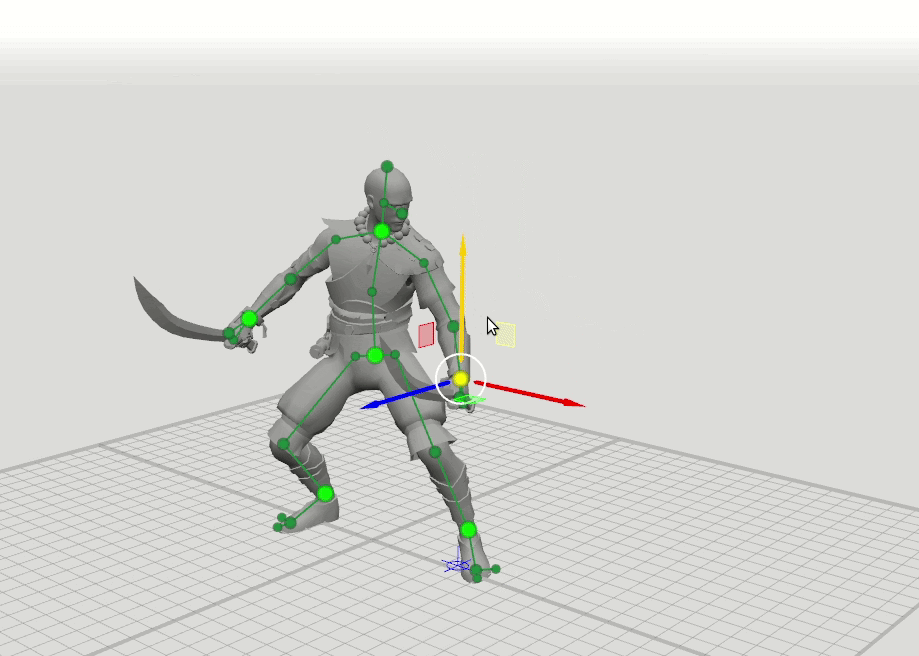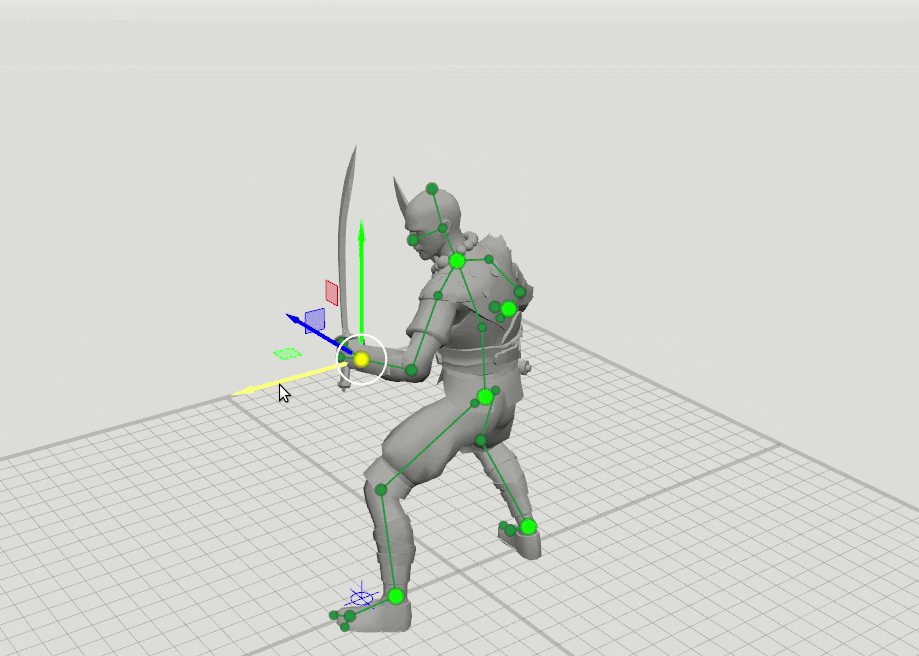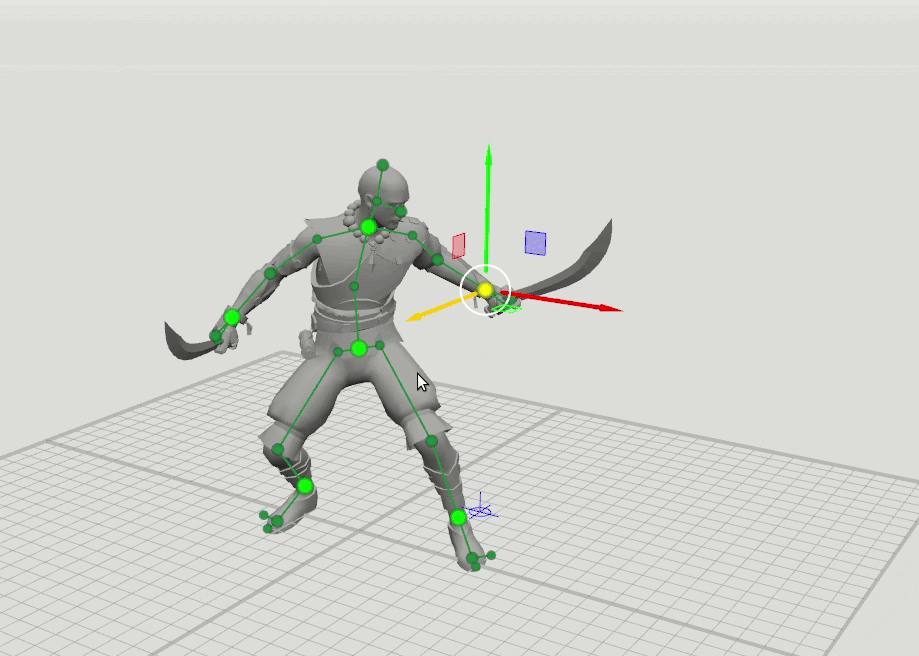
Чтобы натренировать нейросеть, нарисовали около 15 тысяч кадров / habr.com
Еще один пример – Motion Matching от Ubisoft. Технология позволяет задать траекторию движения вашего объекта, а он уже сам учится преодолевать препятствия.
Вы просто рисуете на карте, по которой будет двигаться ваш солдат, а ML берет все остальное на себя.
Если же вы хотите делать атмосферные игры с прикольным поведением (в том числе и в толпе), то тут нужно тренировать определенные модели поведения. Сейчас есть много статей, в которых можно увидеть, как переносить в 3D-объекты позы, скелет и т.д. Вы можете изучать, как двигаются разные типы людей: грузчик, грабитель, полицейский. Имея натренированные сети, можно использовать паттерны для настройки поведения каждого персонажа. Рабочий будет ходить по-своему, солдат — совсем иначе.
Как еще можно облегчить жизнь? Есть одна интересная статья от MIT. Они говорят, что раньше для создания 3D-объекта, похожего на ткань, нужно было много слоев и времени. Теперь представьте себе, что можно сфотографировать любой реальный объект, а нейросеть сгенерирует соответствующие структуру и текстуру. И вам не нужно рисовать все эти материалы руками. Мне эта техника кажется очень мощной, и она может сэкономить много времени.
Общение и вовлеченность в игру
И последнее. Это уже не связано с разработкой игр, но меня — очень удивило. Behavior Impact Analysis от компании Blizzard — это о том, как общение в чатах влияет на вовлеченность в игру. Оказалось, что независимо от времени и уровня игрока, ругань, буллинг или «грязные» высказывания могут привести к тому, что человек перестанет играть. Потому Blizzard разработали NLP-алгоритм, который находит грубиянов среди игроков в чатах и делает им приватные предупреждения. Таким образом учит их общаться так, чтобы в игре не падала общая вовлеченность.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: