


До сих пор в мире нет отработанной стратегии тестирования нейросетей по сравнению с тестированием веб- или мобильных приложений. Направление сложное, иногда непонятное, но заслуживающее внимания и исследования. В этой статье я собрала несколько интересных фактов и подходов к тестированию нейросетей и охотно поделюсь ими с вами.
Тестировать нейросети смогут даже начинающие
Сразу опровергну распространенное мнение: якобы для тестирования нейросетей QA-инженеру требуется мощный опыт или какие-то особые знания по математике и программированию. На самом деле подходы к работе с данными и философия самого тестирования опираются на одну и ту же логику, хорошо знакомую из традиционных проектов. С заточенными на работу с нейросетями Google Collab и TensorFlow справятся специалисты даже с базовыми навыками тестирования.
Как устроены и как работают нейросети
По сути это код со специфическим алгоритмом, созданный подобно биологическим нейронным сетям человеческого мозга. Представьте себе систему, состоящую из слоев. Каждый слой из искусственных нейронов, соединенных между собой десятками или сотнями связей. Таких нейронов, как и слоев, может быть множество: от нескольких до миллионов. Детальнее можете узнать из этого видео:
В отличие от типовой программы искусственная нейросеть не предназначена для выполнения конкретных алгоритмических действий. А что тогда она делает? Рассмотрим на примере по системе Supervised learning (контролируемое обучение).
Предположим, есть нейросеть для работы с изображениями. Первое наше взаимодействие с ней — показываем системе картинку с котом и говорим ей, что это кот. Нейросеть пропускает изображения через свои нейроны, обрабатывает пиксели, определяет реперные точки и делает выводы.
Затем даем ей вторую картинку с котом, третью, десятую — и так далее до нужного предела. Этим условным пределом станет момент, когда нейросеть начнет сама нам «говорить», что на картинке изображен кот. Она будет «узнавать» его по общим для всех изображений критериям. Здесь все работает примерно так же, как у людей. Мы отличаем кошек от других животных по форме тела, головы, ушей, хвоста, усов.
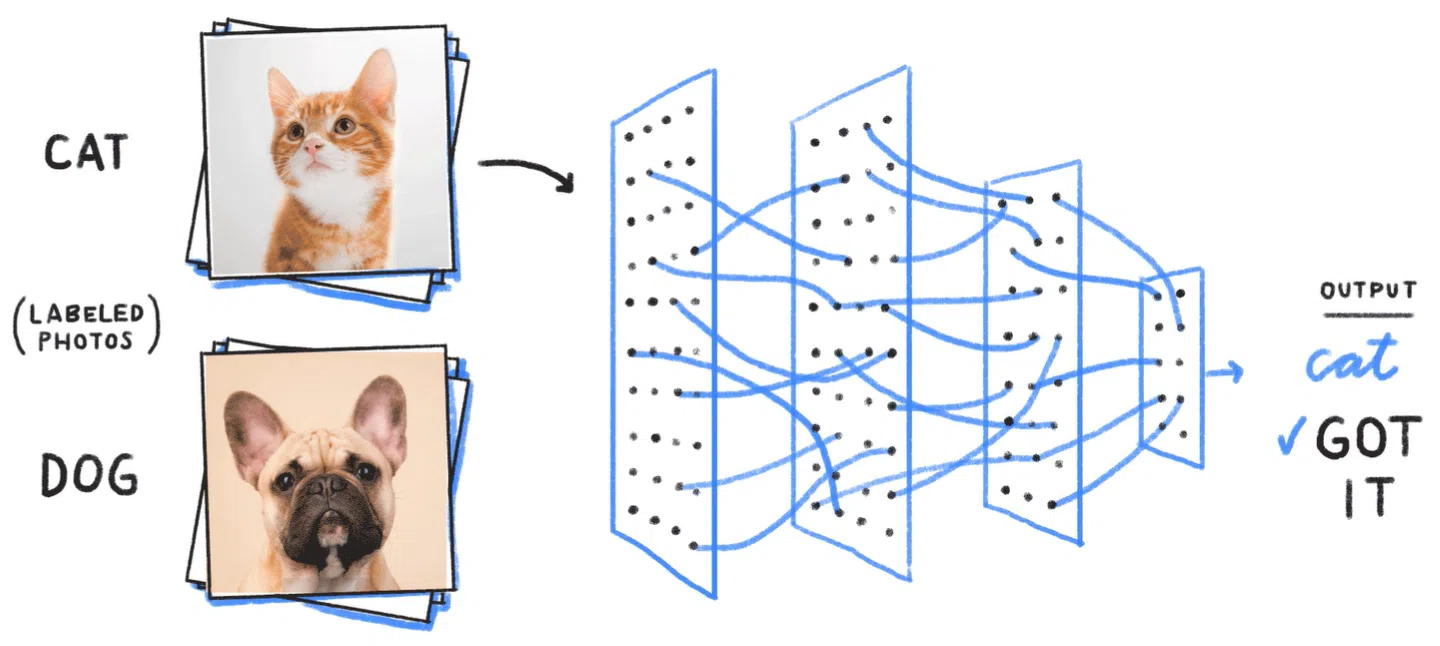 Настройка нейросети заключается не просто в загрузке картинок. Важна наша ответная реакция.
Настройка нейросети заключается не просто в загрузке картинок. Важна наша ответная реакция.
Если система правильно определила кота, мы говорим: ты молодец, хорошо справилась. Так нейросеть подстроит нужные параметры. Если мы дадим ей изображение собаки и система определит ее как кота, следует указать на ошибку. Это также позволит нейросетям адаптировать связи между нейронами и улучшить распознавание изображений. В этом состоит процесс обучения нейросети.
Нейросети могут работать с любыми данными: от изображений и звуков до статистических выкладок. Главное, чтобы данные можно было оцифровать. Сегодня продвинутые нейросети могут не только анализировать и сравнивать данные, но и создавать новые.
Нейросеть «пообщается» с вами в чат-боте, легко напишет произведение на тему, будет следить, чтобы вы не отвлекались за рулем. Теоретически ей по силам задачи любой сложности, здесь все зависит только от эффорта реализации.
Обучение нейросети и программирование — в чем разница?
Классический подход к программированию отличается от машинного обучения. Объясню на простой аналогии. Представим, что нам нужно испечь пирог. Для этого понадобятся определенные ингредиенты и рецепт, придерживаясь которого мы и получим вкусняшку. Так и в классическом программировании. Есть входные данные (ингредиенты), которые обрабатываются определенным кодом (рецепт) для получения определенного результата.
В процессе машинного обучения происходит несколько иначе. Отправная точка — и входные данные, и идеализированный готовый результат. Цель обучения — чтобы нейросеть самостоятельно генерировала алгоритм.
Система должна сама «придумать» способ, позволяющий из заданных входных данных получать желаемый результат.
Упоминая пример с котом, на основе изображения кота и необходимого ответа в виде слова «кот» нейросеть должна понять, как между собой связана картинка и заложенный в нее смысл.

Жизненный цикл нейросети

1 Сбор и подготовка данных
90% успеха работы нейросети зависит от качества данных, на которых она будет учиться или тестироваться. Для QA это самый важный этап. В идеале тестировщик должен начать готовить данные еще до создания самой модели. Конечно, бывают проекты, где на ранних этапах такого эксперта нет. Тогда эта задача ложится на плечи разработчика. Но все же качество обучения и тестирования нейросети зависит именно от QA, поэтому уместно будет приобщить его к делу.
2 Обучение нейросети
Здесь важна итеративность, то есть повторение действий. Это подобно изучению нового материала: чем больше читаем о чем-то, тем лучше это запоминаем, а дальше распознаем и используем для вычислений или создания новых данных. Нейросеть делает так же. Объем данных должен быть достаточно велик. Только так нейросеть с каждой итерацией будет все лучше подстраивать свои параметры под нужный результат.
3 Деплой модели в продакшене
Критически важен не только запуск нейросети, но и мониторинг ее работы.
Согласно этим трем этапам тестировщик должен задаваться вопросами:
- Насколько высоко качество данных для обучения и тестирования?
- Насколько качественно работает сама нейросеть?
- Сохраняется ли качество нейросети после деплоя?
Что означает «эффект перетренированности»
В свое время мне казалось, что поскольку нейросеть учится схожим с нами образом, то количество итераций должно быть максимальным. Ведь чем чаще мы повторяем какую-нибудь информацию, тем надежнее запомним ее. Как результат — качественнее будем работать со связанными данными. Но здесь есть подводный камень, который может полностью испортить нейросеть.
Слишком длительное обучение системы приводит к оверфитингу или овертрейнингу. Это «эффект перетренированности» модели.
Представим двух студентов. Один ходит на пары, все учит и хорошо понимает, как применять теорию на практике. Он, скорее всего, успешно сдаст экзамен. Второй студент зазубривает готовые ответы к билетам, не задумываясь о сути того, что написано. Он тоже может сдать экзамен на отлично. Но если ему дать задачи, отличные от зазубренных, наверное, он не справится. Аналогичная проблема может постичь и нейросеть.
Возьмем для примера задачи, где нейросеть должна определить паттерн поведения точек на графике:
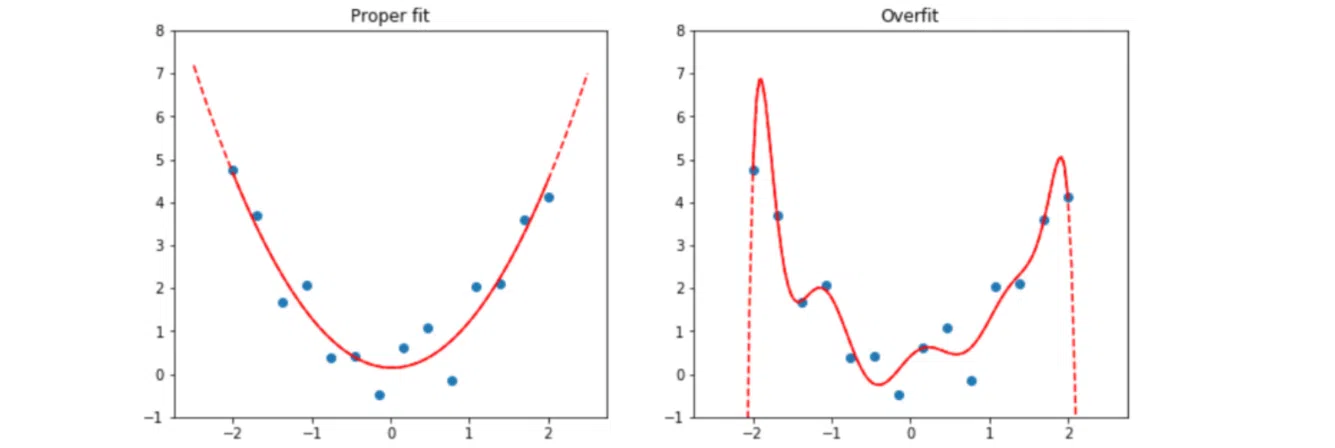
Слева приведена кривая с корректным описанием размещения заданных точек. Справа точки те же, но кривая принципиально другая. Такое ощущение, будто кто-то от руки соединил точки, пытаясь захватить больше.
График выглядит так, словно точнее описывает поведение точек, но он ложный. Это и есть оверфиттинг. Система, грубо говоря, «зазубрила» готовое решение, но оно не применимо к другим данным. Мы же хотим получить от нейросети не слепое следование за точками, а закономерность поведения. То есть нужно то, что изображает кривая на первом графике.
Как бороться с оверфиттингом нейросети
Если вы как тестировщик заметили некорректную работу модели после тренировок, есть два способа, как можно исправить ситуацию.
Удаление параметров
Простое и действенное решение. Если нейросеть «тупит» из-за слишком большого объема запоминаемых данных, частично удалите их. Это заметно встряхнет систему. После удаления параметров она возвращается на более раннюю стадию своего развития и заработает качественнее.
Преждевременная остановка обучения
Удаление данных работает эффективно, но нивелирует время и усилия, затраченные на обучение модели. Проблему лучше предупредить, чем решать радикальными методами. Поэтому советую отслеживать количество тренировочных и тестовых ошибок нейросети на протяжении всех обучающих циклов.
Обратите внимание на этот график. Здесь изображены две кривые с количеством ошибок в хронологическом порядке относительно тренировочных сессий. В какой-то момент тестовых ошибок становится больше, хотя количество тренировочных багов падает.
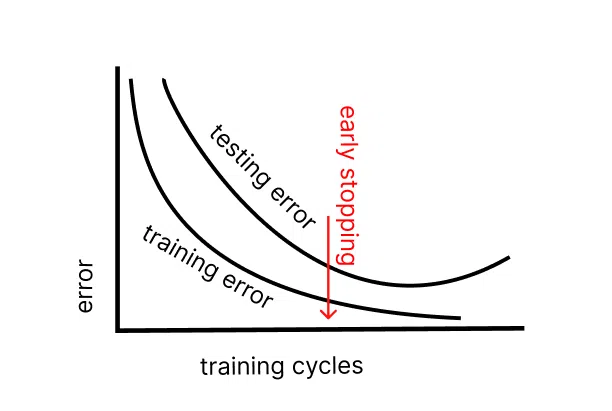
Нейросеть показывает хорошие результаты на знакомых ей данных, но начинает «удивлять» на тестовых. Самое время остановить обучение. Иначе со временем система деградирует. Она будет как студент, который заучил тестовые картинки, но не видит решения в других примерах.
Датасеты для нейросетей
Основа машинного обучения и тестирования моделей — данные. Их можно получить по-разному. Или создавать собственные библиотеки с данными нужного типа, или пользоваться готовыми:
- Google;
- ImageNet;
- Google Open Images;
- Built-In Datasets.
Также можно попробовать специализированные библиотеки для обучения нейросетей:
- MNIST digits classification dataset;
- CIFAR10 small images classification dataset;
- CIFAR100 small images classification dataset;
- IMDB movie review sentiment classification dataset;
- Reuters newswire classification dataset;
- Fashion MNIST dataset, an alternative to MNIST;
- Boston Housing price regression dataset.
Чтобы показать принцип работы с нейросетями и данными, я возьму фрагмент учебного материала из Google Colab. Это платформа для машинного обучения моделей. Перед вами текстовое наполнение, в котором вставлены блоки для компиляции кода:
Здесь можно запустить фрагмент кода, загружающего необходимые библиотеки:
Затем импортировать нужный вам датасет. Выбранный мной пример содержит, как указано в описании, 3670 изображений.
Вы можете просмотреть эти данные — визуализировать рандомные изображения из выбранного датасета:
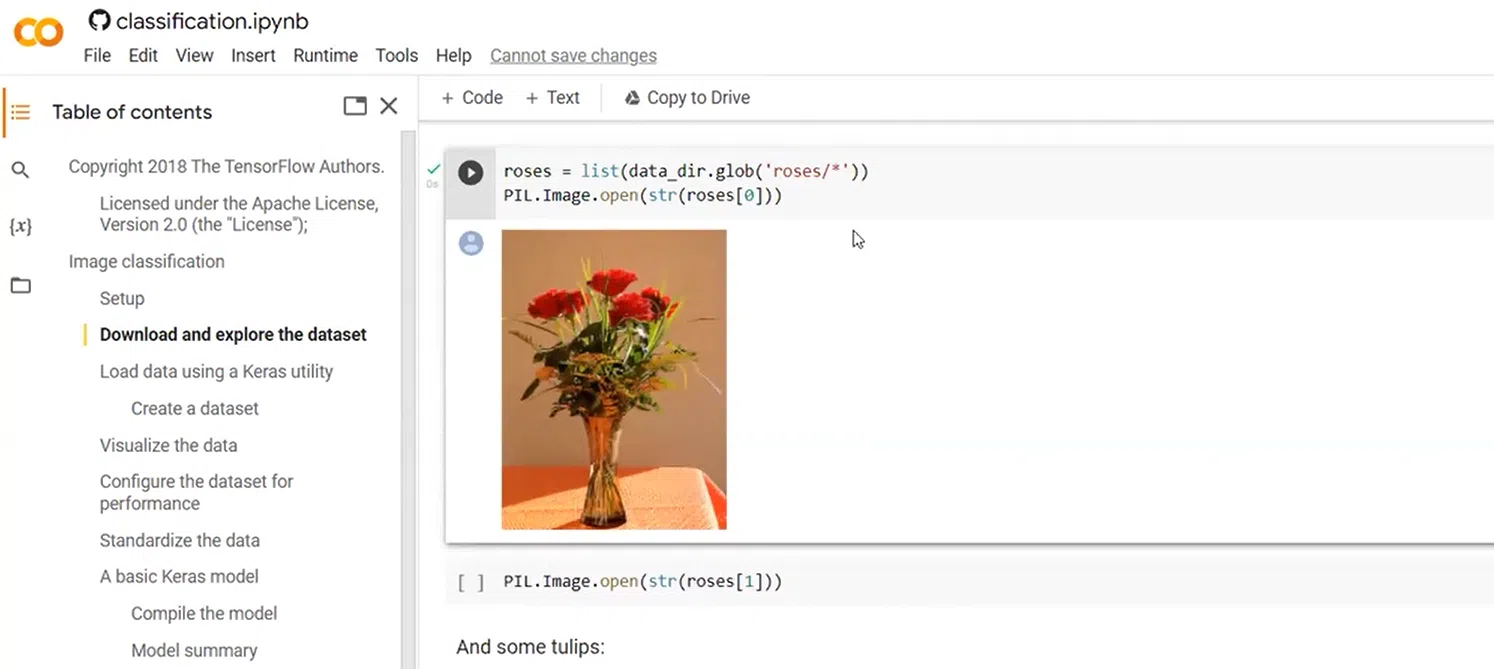
А можно не ограничиваться готовыми данными. Если вам их не хватает, чтобы улучшить качество обучения и тестирования нейросети, то можете сделать свои. Для этого необязательно создавать новые. С помощью простого графического редактора можно отобразить оригинальную картинку, перевернуть ее, изменить цвета, контрастность, вырезать фрагменты и т.д. Таким образом, вы быстро получите подмножество данных, на которых сможете тренировать и тестировать нейросеть. Ведь на изображениях фактически разные кексы.

В процессе нейросеть научится распознавать кексы в разных видах и формах, в другом цвете, с необычным расположением по отдельному фрагменту.
Как тестировать нейросеть: основные шаги
Сбор данных
Предположим, у вас есть пекарня и вы хотели бы использовать в работе искусственный интеллект. Его задача — прогнозировать нужное количество выпечки в зависимости от нескольких факторов. Это может быть день недели, потому что перед выходными посетителей больше. Или погода — ведь когда холодно, клиентов становится меньше. Или развлекательные события в парке вблизи пекарни, из-за чего к вам будет заглядывать больше людей. Нейросеть в своих прогнозах будет ориентироваться на эти разные данные.
Вы можете собрать свой датасет. Он состоит из ряда параметров: дата, температура воздуха на улице, праздничные события, день недели, месяц и т.д. Эти поля называются features. Отдельная колонка в датасете — количество ожидаемой выпечки в определенный день (target):

Что дальше нужно сделать со всеми данными?
- Удалить любые дубликаты.
- Убрать сущности, созданные только для тестирования.
- Избавиться от данных с ошибками.
- Вынести за рамки данных кейсы, с которыми не будет работать нейросеть.
Собранные данные должны быть для вас прозрачными, поскольку от них зависит качество нейросети. Внимательно посмотрите, какие случаи покрыты. К примеру, для таких числовых колонок, как возраст, нужно строить диаграммы. Для колонок с категориями типа образования — перечислить все возможности. Подробно продумайте это все по каждому типу ваших features.
Приоритизация и валидация данных
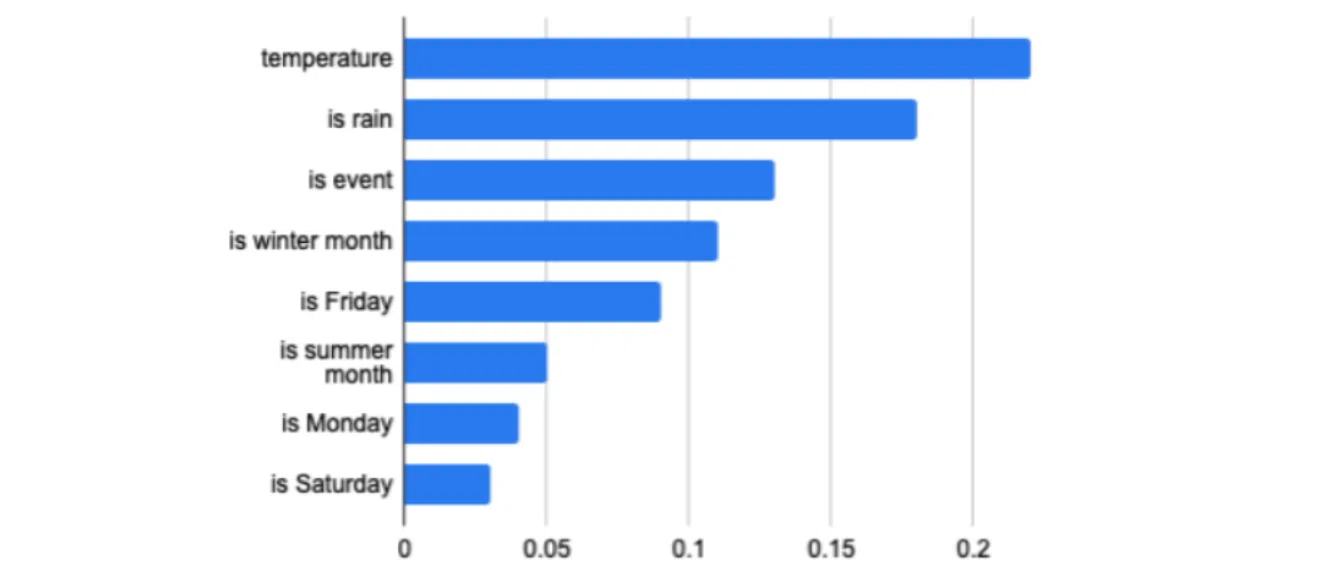
Также понадобится диаграмма, которая будет наглядно отражать важность каждого отдельно взятого пункта из features. Это поможет оценить и расставить приоритеты данных. Так вы можете оперативно исправлять некорректное поведение нейросети. Для этого следует варьировать параметры наиболее приоритетного типа и смотреть на реакцию модели.
На этой схеме предпочтительно выбрана температура воздуха. Если в системе продолжаются сбои после смены, следует повторить эту процедуру со следующим параметром.
Приоритетность параметров зависит не только от заложенных смыслов, но и от формата данных. Например, в работе с изображениями ваши features — это каждый пиксель. Тогда приоритетны контрастные пиксели, ведь именно они формируют рисунок как таковой, делают его считываемым. Подобные нюансы в размещении приоритетов следует учитывать почти в каждом типе данных, с которым будет взаимодействовать нейросеть.
Если вы работаете со специфическими данными, где сложно оценить их корректность, обратитесь к коллегам. Это могут быть разработчики или эксперты в нужной области. Они помогут валидировать ваши данные и создать определенные рамки для дальнейшей работы.
Разделение данных
Речь идет о разделении множества данных на два подмножества. Вам нужно достичь соотношения 80 на 20, где 80% данных предназначены для тренировок нейросети, а 20% для ее тестирования. Причем эти подмножества не должны пересекаться.
«Тестовые» 20% должны быть незнакомы для нейросети, она «увидит» их впервые. К примеру, для обучения модели в пекарне можно выбрать данные с января по октябрь, а для проверок — с ноября по декабрь.
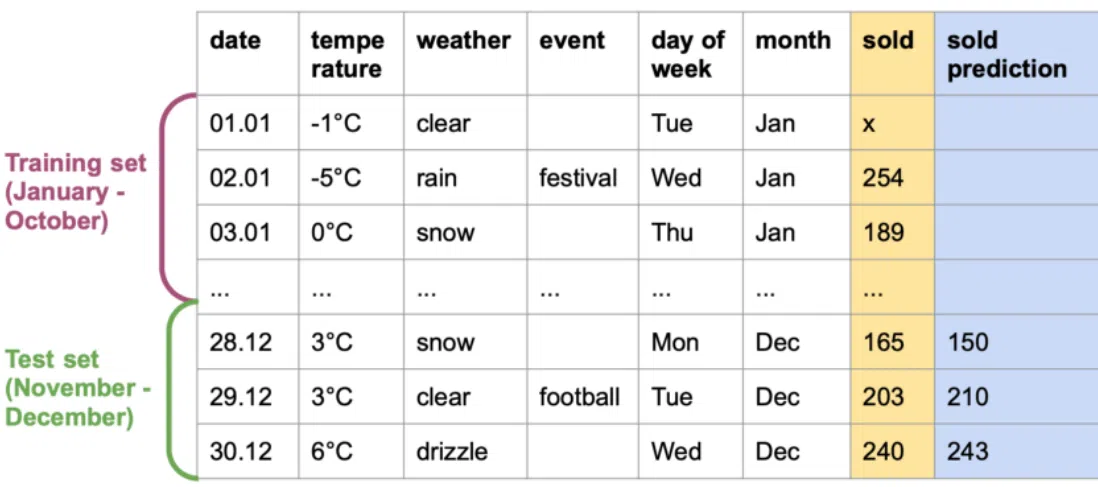
К разделению следует подойти заранее, оценивая все доступные методы. Вы можете выбирать с каждого месяца по несколько дней по тому же соотношению 80/20. В случае с пекарней это наилучший способ, так как вы охватите все сезоны. Так что и данные будут корректными. В некоторых случаях рандомное деление множества на подмножество недопустимо. Например, в ситуациях, когда данные связаны в исторической цепочке. Если одно событие оказывает непосредственное влияние на следующее, то в принципе неправильно выделять такие данные из массива.
Следующий шаг — построение требований. Они могут отличаться в зависимости от типа данных и особенностей проекта. Объясню на том же примере с пекарней. Выброшенная или непроданная булочка — потеря для бизнеса. Но эта потеря гораздо менее значима, чем голодный клиент, для которого в конце дня в пекарне уже не осталось булочек. Такие факторы влияют на построение требований.
Допустим, выброшенная булочка стоит €1, а недовольный клиент – €3. Преимущественно в течение дня потери не должны превышать 100 евро. Это поможет более грамотно оперировать данными и их приоритетами.
Тесты и мониторинг нейросети
На этом этапе уже переходим к тестированию нейросети. Обратите внимание на следующие моменты.
Тестирование нейросети в связи с API
Нельзя проверять модель исключительно как отдельную сущность. Следует провести классическое интеграционное тестирование. Ведь нейросети обязательно взаимодействуют с некоторыми посторонними сервисами. В случае пекарни это может быть сервис прогноза погоды, откуда система будет брать данные на ближайшую неделю. Это позволит опробовать модель в условиях, максимально приближенных к реальности. Следите за взаимодействием всех элементов системы.
Тестируйте нейросеть с некорректными данными
Проверяйте модель на данных, с которыми она не должна работать. Для чего это делать? Допустим, ваша нейросеть в ответ на совершенно некорректные данные выдает вместо валидационного сообщения определенный корректный результат. Это говорит о сбое в ее работе, когда она не до конца понимает суть данных и прогнозов. Также модель может банально зависнуть при вводе некорректных данных, чего тоже лучше избегать.
Помимо проверки качества машинного обучения, тестирование нейросети включает и все другие традиционные подходы: тесты функциональности, погрузки, перфоманса, безопасности. Помните и о черном ящике с подключенным к нему API. Во всех этих тестах обращайте внимание на распространенные проблемы:
- медленную инициализацию модели;
- медленное прогнозирование;
- высокое потребление вычислительных мощностей.
Когда вы все проверили, разработчики исправили баги и модель отправилась в деплой на продакшен, ваша работа как тестировщика еще не заканчивается. На этом этапе вы должны продумать алерты. К примеру, если нейросеть прогнозирует увеличение количества нужной выпечки на 5% в течение 3 дней подряд, следует узнать об этом. Пригодится email-сообщение. Этот алерт позволит быстрее зафиксировать нестандартную ситуацию и разобраться, почему модель ведет себя именно так.
Следить за нейросетью нужно с момента ее запуска. Иногда даже идеально подготовленная модель со временем устаревает и теряет актуальность. К примеру, через полгода рядом с пекарней может открыться детский сад, и это тоже скажется на продажах. Появятся новые условия и данные, и нужно будет провести апдейт нейросети. Если не учесть этот фактор, модель станет невалидной.
Рекомендую регулярно логировать метрики, с которыми работает ваша нейросеть, а именно:
- сколько времени занимает обработка запросов;
- сколько запросов поступает в нейросеть;
- какое процентное соотношение ошибок;
- насколько высоко потребление вычислительных мощностей.
Помните еще одну вещь: нейросети — это всегда черный ящик. Разработчики этих систем знают, из чего состоит модель и какие технологии в ней заложены. Но даже опытные эксперты не могут быть до конца уверены в причинах принятия нейросетью тех или иных решений. Она самостоятельно находит в данных определенные связи, и не всегда они очевидны.
Возможно, вам и не придется сталкиваться с нейросетями. Но по-моему, некоторые приемы тестирования в этой сфере могут вдохновить на интересные решения и в других проектах. Так что изучайте новое и не бойтесь экспериментировать.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: