
Досі у світі не існує відпрацьованої стратегії тестування нейромереж порівняно з тестуванням веб- чи мобільних застосунків. Напрям складний, подекуди незрозумілий, але вартий уваги і дослідження. У цій статті я зібрала кілька цікавих фактів та підходів до тестування нейромереж і залюбки поділюся ними з вами.
Навіть початківці осягнуть тестування нейромереж
Одразу спростую поширену думку: нібито для тестування нейромереж QA-інженеру потрібен потужний досвід чи якісь особливі знання з математики та програмування. Насправді підходи до роботи з даними та філософія самого тестування спираються на одну й ту саму логіку, добре знайому з традиційних проєктів. Із заточеними на роботу з нейромережами Google Collab та TensorFlow дадуть раду фахівці навіть із базовими навичками тестування.
Як влаштовані та як працюють нейромережі
По суті це код зі специфічним алгоритмом, створений подібно до біологічних нейронних мереж людського мозку. Уявіть собі систему, яка складається з шарів. Кожен шар — зі штучних нейронів, з’єднаних між собою десятками або сотнями зв’язків. Таких нейронів, як і шарів, може бути безліч: від кількох до мільйонів. Детальніше можете подивитися у цьому відео:
На відміну від типової програми, штучна нейромережа не призначена для виконання конкретних алгоритмічних дій. А що ж тоді вона робить? Розглянемо на прикладі за системою Supervised learning (контрольоване навчання).
Припустимо, є нейромережа для роботи із зображеннями. Перша наша взаємодія з нею — показуємо системі картинку з котом і кажемо їй, що це кіт. Нейромережа пропускає зображення через свої нейрони, обробляє пікселі, визначає реперні точки та робить висновки.
Потім даємо їй другу картинку з котом, третю, десяту — і так далі до потрібної межі. Цією умовною межею стане момент, коли нейромережа почне сама нам «говорити», що на картинці зображений кіт. Вона «впізнаватиме» його за спільними для всіх зображень критеріями. Тут усе працює приблизно так само, як у людей. Ми відрізняємо котів від інших тварин за формою тіла, голови, вух, хвоста, вусів.
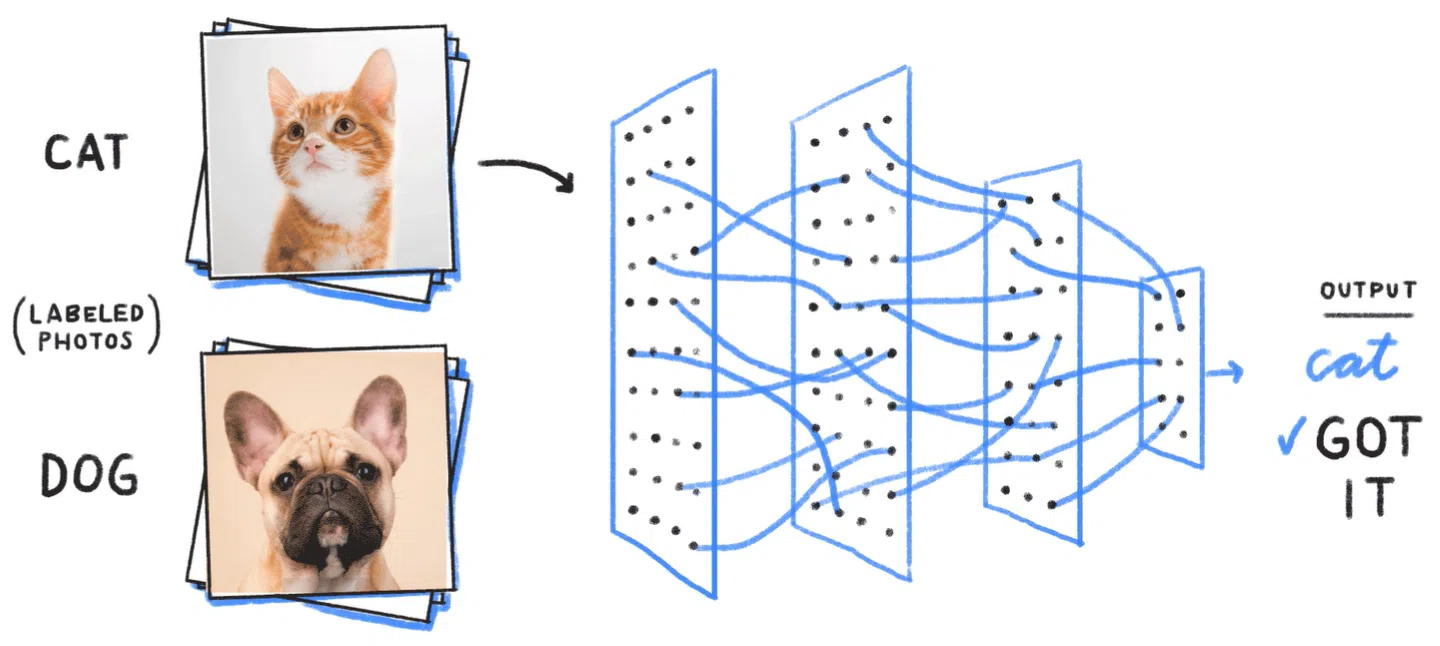 Налаштування нейромережі полягає не просто в завантаженні картинок. Важлива наша реакція у відповідь.
Налаштування нейромережі полягає не просто в завантаженні картинок. Важлива наша реакція у відповідь.
Якщо система правильно визначила кота, ми говоримо їй: ти молодець, добре впоралася. Так нейромережа підлаштує потрібні параметри. Якщо ми дамо їй зображення собаки і система визначить його як кота, варто вказати на помилку. Це також дозволить нейромережі адаптувати зв’язки між нейронами та покращити розпізнавання зображень. У цьому полягає процес навчання нейромережі.
Нейромережі можуть працювати з будь-якими даними: від зображень та звуків до статистичних викладок. Головне, щоб дані можна було оцифрувати. Сьогодні просунуті нейромережі можуть не лише аналізувати та порівнювати дані, а й створювати на їх основі нові:
Нейромережа «поспілкується» з вами в чат-боті, легко напише твір на задану тему, стежитиме, щоб ви не відволікалися за кермом. Теоретично їй під силу завдання будь-якої складності, тут все залежить тільки від ефорту реалізації.
Навчання нейромережі та програмування — в чому різниця?
Класичний підхід до програмування відрізняється від машинного навчання. Поясню на простій аналогії. Уявімо, що нам потрібно спекти пиріг. Для цього знадобляться певні інгредієнти та рецепт, дотримуючись якого ми й отримаємо смаколик. Так і в класичному програмуванні. Маємо вхідні дані (інгредієнти), які обробляються певним кодом (рецепт) для отримання певного результату.
У процесі машинного навчання відбувається трохи інакше. Відправною точкою є і вхідні дані, й ідеалізований готовий результат. Мета навчання — щоб нейромережа самостійно генерувала алгоритм.
Система має сама «вигадати» спосіб, який дозволить із заданих вхідних даних отримувати бажаний результат.
Згадуючи приклад з котом, на основі зображення кота та необхідної відповіді у вигляді слова «кіт» нейромережа повинна зрозуміти, як між собою пов’язані картинка та закладений у неї сенс.

Життєвий цикл нейромережі

1Збір та підготовка даних
90% успіху роботи нейромережі залежить від якості даних, на яких вона навчатиметься або тестуватиметься. Для QA це найважливіший етап. В ідеалі тестувальник повинен розпочати готувати дані ще до створення самої моделі. Звичайно, бувають проєкти, де на ранніх етапах немає такого експерта. Тоді це завдання лягає на плечі розробника. Але все ж таки якість навчання і тестування нейромережі залежить саме від QA, тому буде доречно долучити його до справи.
2Навчання нейромережі
Тут важлива ітеративність, тобто повторення дій. Це подібно до вивчення нового матеріалу: чим більше читаємо про щось, тим краще це запам’ятовуємо, а далі — розпізнаємо та використовуємо для обчислень або створення нових даних. Нейромережа робить так само. Обсяг даних має бути досить великим. Тільки так нейромережа з кожною ітерацією буде все краще підлаштовувати свої параметри під потрібний результат.
3Деплой моделі у продакшн
Критично важливий не лише запуск нейромережі, але й моніторинг її роботи.
Відповідно до цих трьох етапів тестувальник має задаватися питаннями:
- Наскільки висока якість даних для навчання та тестування?
- Наскільки якісно працює сама нейромережа?
- Чи зберігається якість нейромережі після деплою?
Що означає «ефект перетренованості»
Свого часу мені здавалося, що оскільки нейромережа навчається схожим з нами чином, то кількість ітерацій має бути максимальною. Адже що частіше ми повторюємо якусь інформацію, то надійніше запам’ятаємо її. Як результат — якісніше будемо працювати зі зв’язаними даними. Однак тут маємо підводний камінь, який може повністю зіпсувати нейромережу.
Занадто тривале навчання системи призводить до оверфіттингу або овертрейнінгу. Це «ефект перетренованості» моделі.
Уявімо двох студентів. Один — ходить на пари, все вчить і добре розуміє, як застосовувати теорію на практиці. Він імовірніше успішно складе іспит. Другий студент зазубрює готові відповіді до білетів, не задумуючись про суть написаного. Він теж може скласти іспит на відмінно. Та якщо йому дати задачі, які відрізняються від зазубрених, напевно, він не впорається. Аналогічна проблема може спіткати й нейромережу.
Візьмемо для прикладу завдання, де нейромережа має визначити патерн поведінки точок на графіку:
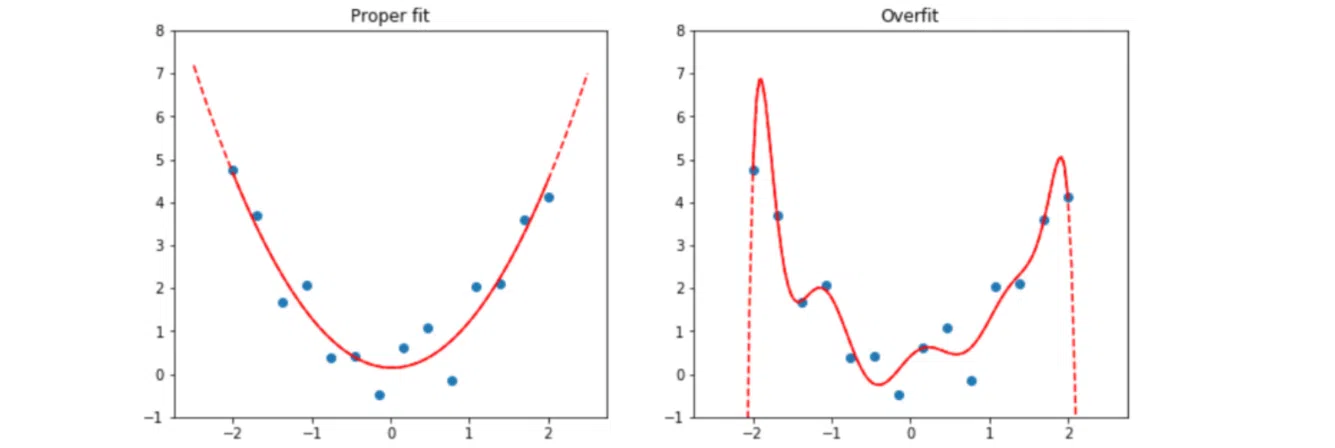
Зліва наведено криву з коректним описом розміщення заданих точок. Праворуч точки ті самі, але крива принципово інша. Таке відчуття, ніби хтось від руки поєднав крапки, намагаючись захопити якнайбільше.
Графік виглядає так, немов точніше описує поведінку точок, але ж він помилковий. Це і є оверфіттинг. Система, грубо кажучи, «зазубрила» готове рішення, але воно не застосовується до інших даних. Ми ж хочемо отримати від нейромережі не сліпе слідування за точками, а закономірність поведінки. Тобто потрібно те, що зображує крива на першому графіку.
Як боротися з оверфіттингом нейромережі
Якщо ви, як тестувальник, помітили некоректну роботу моделі після тренувань, є два способи, як можна виправити ситуацію.
Видалення параметрів
Просте і дієве рішення. Якщо нейромережа «тупить» через занадто великий обсяг запам’ятованих даних, частково видаліть їх. Це помітно струсить систему. Після видалення параметрів вона повертається на більш ранню стадію свого розвитку та почне працювати якісніше.
Передчасна зупинка навчання
Видалення даних працює ефективно, але нівелює час та зусилля, витрачені на навчання моделі. Проблему краще попередити, аніж потім вирішувати радикальними методами. Тому раджу відстежувати кількість тренувальних і тестових помилок нейромережі протягом усіх навчальних циклів.
Зверніть увагу на цей графік. Тут зображено дві криві з кількістю помилок у хронологічному порядку щодо тренувальних сесій. У якийсь момент тестових помилок стає більше, хоча кількість тренувальних багів падає.
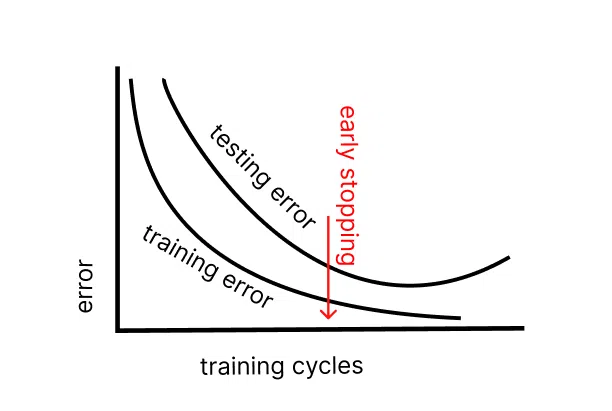
Нейромережа показує хороші результати на знайомих їй даних, але починає «дивувати» на тестових. Саме час зупинити навчання. Інакше згодом система деградує. Вона буде як той студент, який завчив тестові картинки, але не бачить рішення в інших прикладах.
Датасети для нейромереж
Основа машинного навчання і тестування моделей — дані. Їх можна отримати по-різному. Чи то створювати власні бібліотеки з даними потрібного типу, чи то користуватися готовими:
- Google;
- ImageNet;
- Google Open Images;
- Built-In Datasets.
Також можна спробувати спеціалізовані бібліотеки для навчання нейромереж:
- MNIST digits classification dataset;
- CIFAR10 small images classification dataset;
- CIFAR100 small images classification dataset;
- IMDB movie review sentiment classification dataset;
- Reuters newswire classification dataset;
- Fashion MNIST dataset, an alternative to MNIST;
- Boston Housing price regression dataset.
Щоб показати принцип роботи з нейромережами і даними я візьму фрагмент навчального матеріалу з Google Colab. Це платформа для машинного навчання моделей. Перед вами — текстове наповнення, в якому вставлені блоки для компіляції коду:
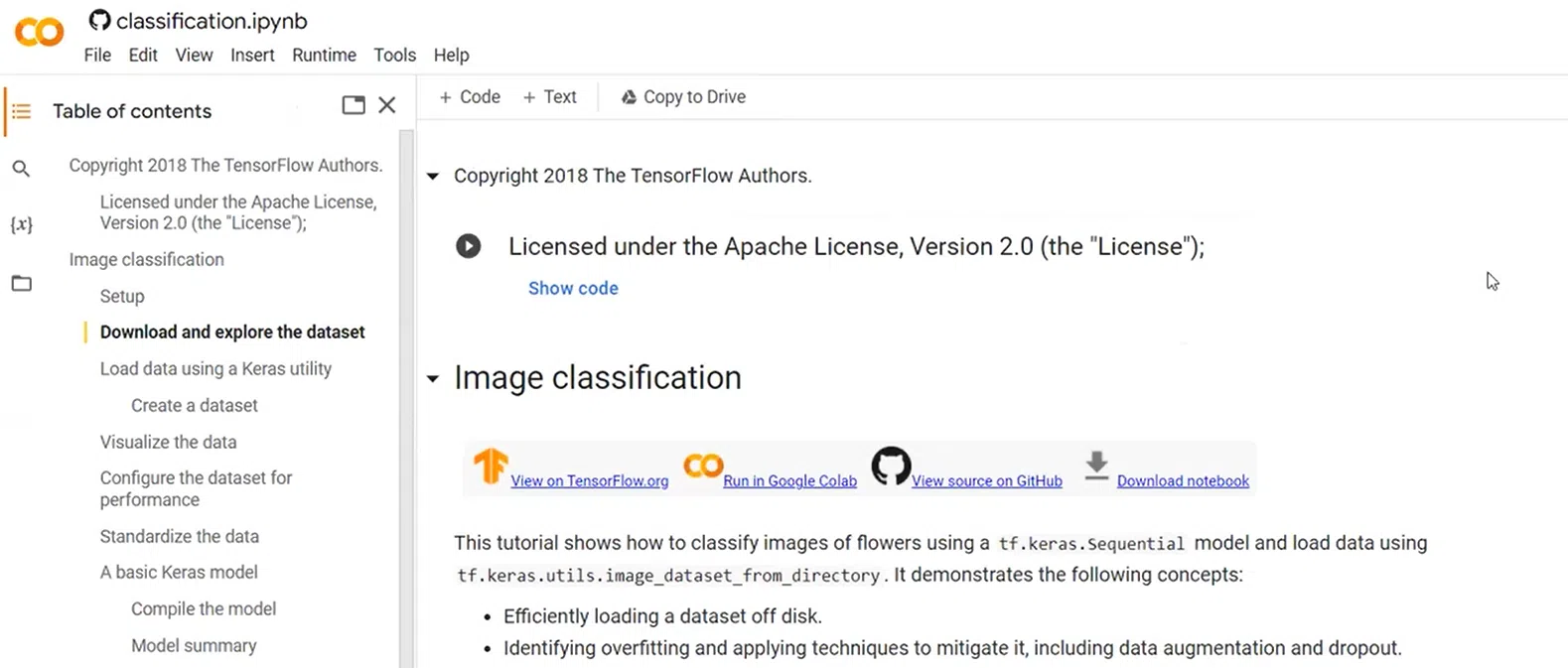
Тут можна запустити фрагмент коду, який завантажує необхідні бібліотеки:
Потім імпортувати потрібний вам датасет. Вибраний мною приклад містить, як зазначено в описі, 3670 зображень.
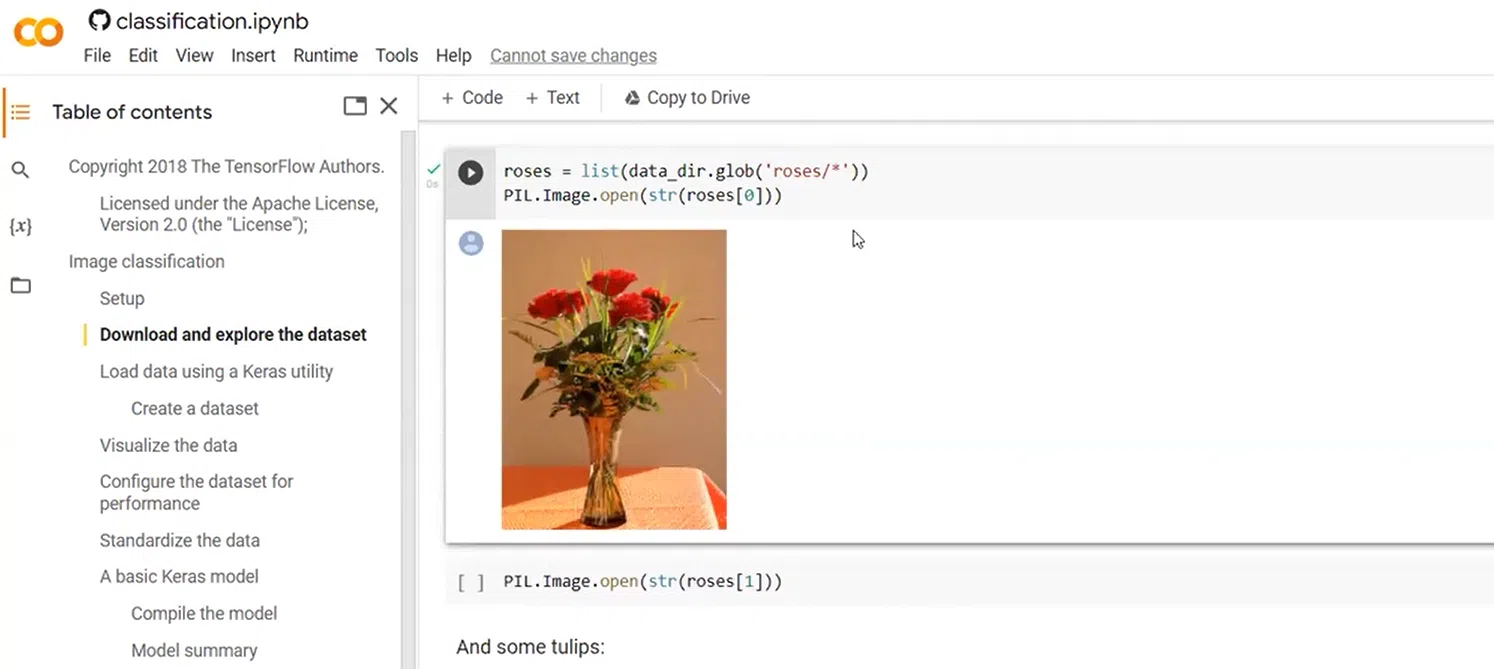
Ви можете переглянути ці дані — візуалізувати рандомні зображення з вибраного датасету:
А можно не обмежуватись готовими даними. Якщо вам їх не вистачає, аби покращити якість навчання нейромережі та її тестування, то можете зробити свої. Для цього не обов’язково створювати нові дані. За допомогою простого графічного редактора ви можете відобразити оригінальну картинку, перевернути її, змінити кольори, контрастність, вирізати фрагменти тощо. Таким чином ви швидко отримаєте підмножину даних, на яких зможете тренувати і тестувати нейромережу. Адже на зображеннях фактично різні кекси.

В процесі нейромережа навчиться розпізнавати кекси в різних видах та формах, в іншому кольорі, з незвичайним розташуванням, за окремим фрагментом.
Як тестувати нейромережу: основні кроки
Збір даних
Припустимо, у вас є пекарня і ви хотіли б використовувати в роботі штучний інтелект. Його завдання — прогнозувати потрібну кількість випічки в залежності від декількох факторів. Це може бути день тижня — бо перед вихідними відвідувачів більше. Або погода — адже коли холодно, клієнтів меншає. Або ж розважальні події у парку поблизу пекарні, через що до вас заглядатимуть більше людей. На ці різноманітні дані у своїх прогнозах орієнтуватиметься нейромережа.
Ви можете зібрати власний датасет. Він складатиметься з низки параметрів: дата, температура повітря на вулиці, святкові події, день тижня, місяць тощо. Ці поля називаються features. Окрема колонка в датасеті — кількість очікуваної випічки у певний день (target):

Що далі необхідно зробити з усіма даними?
- Видалити будь-які дублікати.
- Забрати сутності, створені лише для тестування.
- Позбутися даних із помилками.
- Винести за рамки даних кейси, з якими не працюватиме нейромережа.
Зібрані дані мають бути прозорими для вас, оскільки від них залежить якість нейромережі. Подивіться уважно, які випадки покриті. Наприклад, для таких числових колонок, як вік, треба будувати діаграми. Для колонок з категоріями на кшталт освіти — перерахувати всі можливості. Детально продумайте це все за кожним типом ваших features.
Пріорітизація та валідація даних
Також знадобиться діаграма, яка наочно відображатиме важливість кожного окремо взятого пункту з features. Це допоможе оцінити та розставити пріоритети у даних. Так ви зможете оперативно виправляти некоректну поведінку нейромережі. Для цього треба варіювати параметри найбільш пріоритетного типу та дивитися на реакцію моделі.
На цій схемі пріоритетною обрана температура повітря. Якщо в системі продовжуються збої після зміни, варто повторити цю процедуру з наступним параметром.
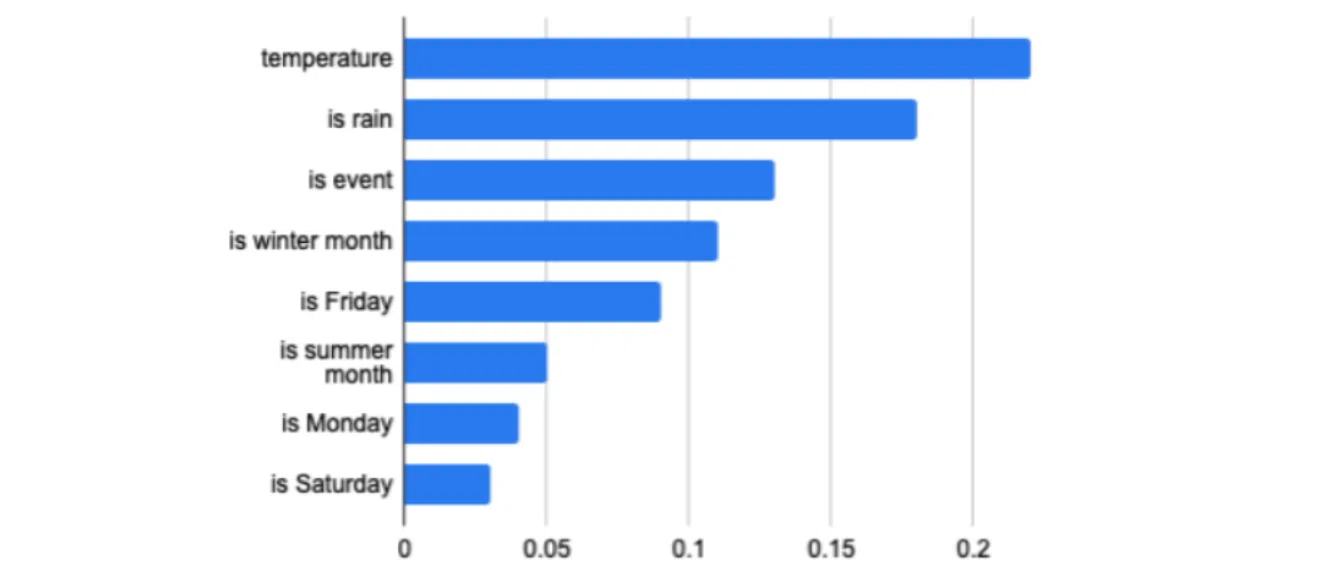
Пріоритетність параметрів залежить не лише від закладених сенсів, а й формату даних. Наприклад, у роботі із зображеннями ваші features — це кожен піксель. Тоді пріоритетними є контрастні пікселі, адже саме вони формують малюнок як такий, роблять його зчитуваним. Подібні нюанси у розміщенні пріоритетів варто враховувати мало не в кожному типі даних, з яким взаємодіятиме нейромережа.
Якщо ви працюєте зі специфічними даними, де складно оцінити їхню коректність, зверніться до колег. Це можуть бути розробники чи експерти у потрібній галузі знань. Вони допоможуть валідувати ваші дані та створити певні оціночні рамки для подальшої роботи.
Поділ даних
Ідеться про поділ множини даних на дві підмножини. Вам потрібно досягти співвідношення 80 на 20, де 80% даних призначені для тренувань нейромережі, а 20% — для її тестування. Причому ці підмножини не повинні перетинатися.
«Тестові» 20% мають бути незнайомими для нейромережі, вона «побачить» їх уперше. Наприклад, для навчання моделі в пекарні можна обрати дані з січня по жовтень, а для перевірок — із листопада по грудень.
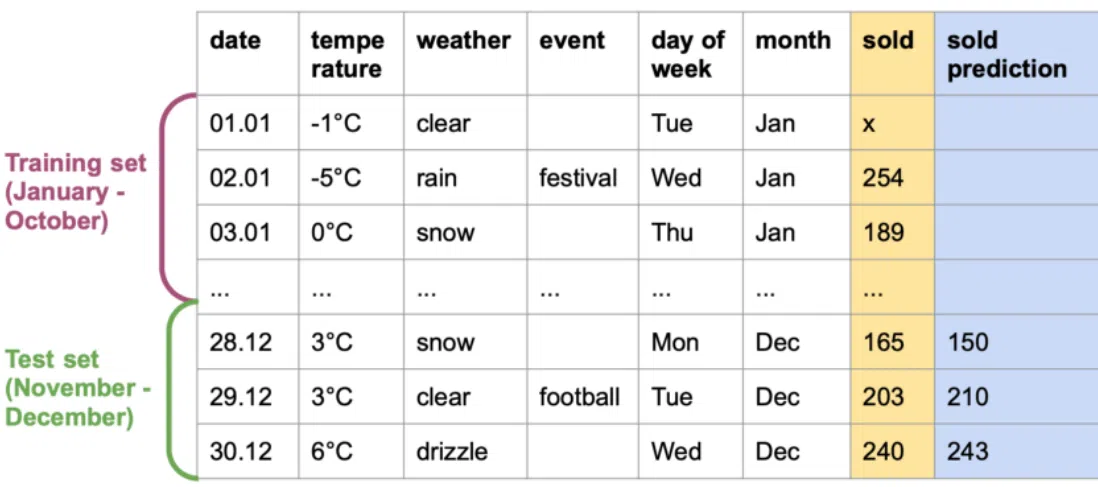
До поділу слід підійти свідомо, оцінюючи всі доступні методи. Ви можете обирати з кожного місяця по кілька днів за тим самим співвідношенням 80/20. У випадку з пекарнею це кращий метод, оскільки ви охопите всі сезони. Тож і дані будуть коректними. У деяких випадках рандомний поділ множини на підмножини неприпустимий. Наприклад, у ситуаціях, коли дані пов’язані в історичному ланцюжку. Якщо одна подія безпосередньо впливає на наступну, то в принципі неправильно виокремлювати такі дані з масиву.
Наступний крок — побудова вимог. Вони можуть відрізнятися в залежності від типу даних та особливостей проєкту. Поясню на тому ж прикладі з пекарнею. Викинута чи непродана булочка є втратою для бізнесу. Одак ця втрата набагато менш значуща, ніж голодний клієнт, для якого наприкінці дня в пекарні вже не лишилося булочок. Такі фактори впливають на побудову вимог.
Припустимо, викинута булочка коштує €1, а незадоволений клієнт — €3. Переважно протягом дня втрати не повинні перевищувати €100. Це допоможе грамотніше оперувати даними та їх пріоритетами.
Тести та моніторинг нейромережі
На цьому етапі вже переходимо до тестування нейромережі. Зверніть увагу на наступні моменти.
Тестуйте нейромережу у зв’язці з API
Не можна перевіряти модель виключно як окрему сутність. Варто провести класичне інтеграційне тестування. Адже нейромережі обов’язково взаємодіють із деякими сторонніми сервісами. У випадку пекарні це може бути сервіс прогнозу погоди, звідки система братиме дані на найближчий тиждень. Це дозволить випробувати модель в умовах, максимально наближених до реальності. Слідкуйте за взаємодією всіх елементів системи.
Тестуйте нейромережу з некоректними даними
Перевіряйте модель на даних, з якими вона не повинна працювати. Навіщо це робити? Припустимо, ваша нейромережа у відповідь на абсолютно некоректні дані видає замість валідаційного повідомлення певний коректний результат. Це каже про збій у її роботі, коли вона не до кінця розуміє суть даних і прогнозів. Також модель може банально зависнути під час введення некоректних даних, чого теж краще уникати.
Крім перевірки якості машинного навчання, тестування нейромережі включає й всі інші традиційні підходи: тести функціональності, навантаження, перфомансу, безпеки. Пам’ятайте і про чорну скриньку з підключеним до неї API. У всіх цих тестах звертайте увагу на розповсюджені проблеми:
- повільну ініціалізацію моделі;
- повільне прогнозування;
- високе споживання обчислювальних потужностей.
Коли ви все перевірили, розробники виправили баги і модель вирушила у деплой на продакшн, ваша робота як тестувальника ще не закінчується. На цьому етапі ви маєте продумати алерти. Наприклад, якщо нейромережа прогнозує збільшення кількості потрібної випічки на 5% протягом 3 днів поспіль, варто дізнатися про це. Стане в пригоді email-повідомлення. Цей алерт дасть змогу швидше зафіксувати нестандартну ситуацію й розібратися, чому модель поводиться саме так.
Слідкувати за нейромережею потрібно з моменту її запуску. Інколи навіть ідеально підготовлена модель з часом застаріває і втрачає актуальність. Наприклад, через півроку поруч із пекарнею може відкритися дитячий садок, і це теж позначиться на продажах. З’являться нові умови і дані, і варто буде провести апдейт нейромережі. Якщо не зважити на цей фактор, модель стане невалідною.
Рекомендую регулярно логувати метрики, з якими працює ваша нейромережа, а саме:
- скільки часу займає обробка запитів;
- скільки запитів надходить у нейромережу;
- яке відсоткове співвідношення помилок;
- наскільки високим є споживання обчислювальних потужностей.
Пам’ятайте ще одну річ: нейромережі — це завжди чорна скринька. Розробники цих систем знають, із чого складається модель та які технології в ній закладено. Однак навіть найдосвідченіші експерти не можуть бути до кінця впевненими у причинах прийняття нейромережею тих чи інших рішень. Вона самостійно знаходить у даних певні зв’язки, і не завжди вони очевидні.
Можливо, вам і не доведеться мати справу з нейромережами. Але як на мне, деякі прийоми тестування у цій сфері можуть надихнути на цікаві рішення і в інших проєктах. Тож вивчайте нове і не бійтесь експериментувати.
Цей матеріал – не редакційний, це – особиста думка його автора. Редакція може не поділяти цю думку.













Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: