


Привіт! Мене звати Настаcія Осідач, я менеджерка команди комп’ютерних лінгвістів Grammarly. Сьогодні ми поділимося з вами, як виникла та реалізувалася ідея створити UA-GEC — перший анотований GEC-корпус української мови для завдання з виправлення граматичних помилок.
Українська мова входить до 50-ти найпоширеніших мов світу, але якісних текстових ресурсів для її дослідження небагато. Тож допомогти з такими ресурсами хотілося давно.
Для завдання з виправлення граматичних помилок раніше був потрібний чималий обсяг проанотованих даних — щонайменше сотні тисяч речень.
Однак за останні роки технології глибинного навчання дуже просунулися вперед, з’явилися претреновані моделі, для навчання яких знадобиться значно менше даних.
Такі моделі почали з’являтися не лише для англійської, а й для багатьох інших мов, зокрема і для української. Стало зрозуміло, що можна підготувати корпус на кілька десятків тисяч речень і з ним уже можна буде досягати якісних результатів.
Тож торік улітку ми з колегами у Grammarly почали працювати над цим проектом. Він уже став постійним і буде частинкою нашого внеску у розвиток галузі обробки природної мови в Україні.
Для чого потрібен UA-GEC?
Передусім корпус UA-GEC можна використовувати, щоб тренувати алгоритми для виправлення граматичних і стилістичних помилок та оцінювати якість цих алгоритмів.
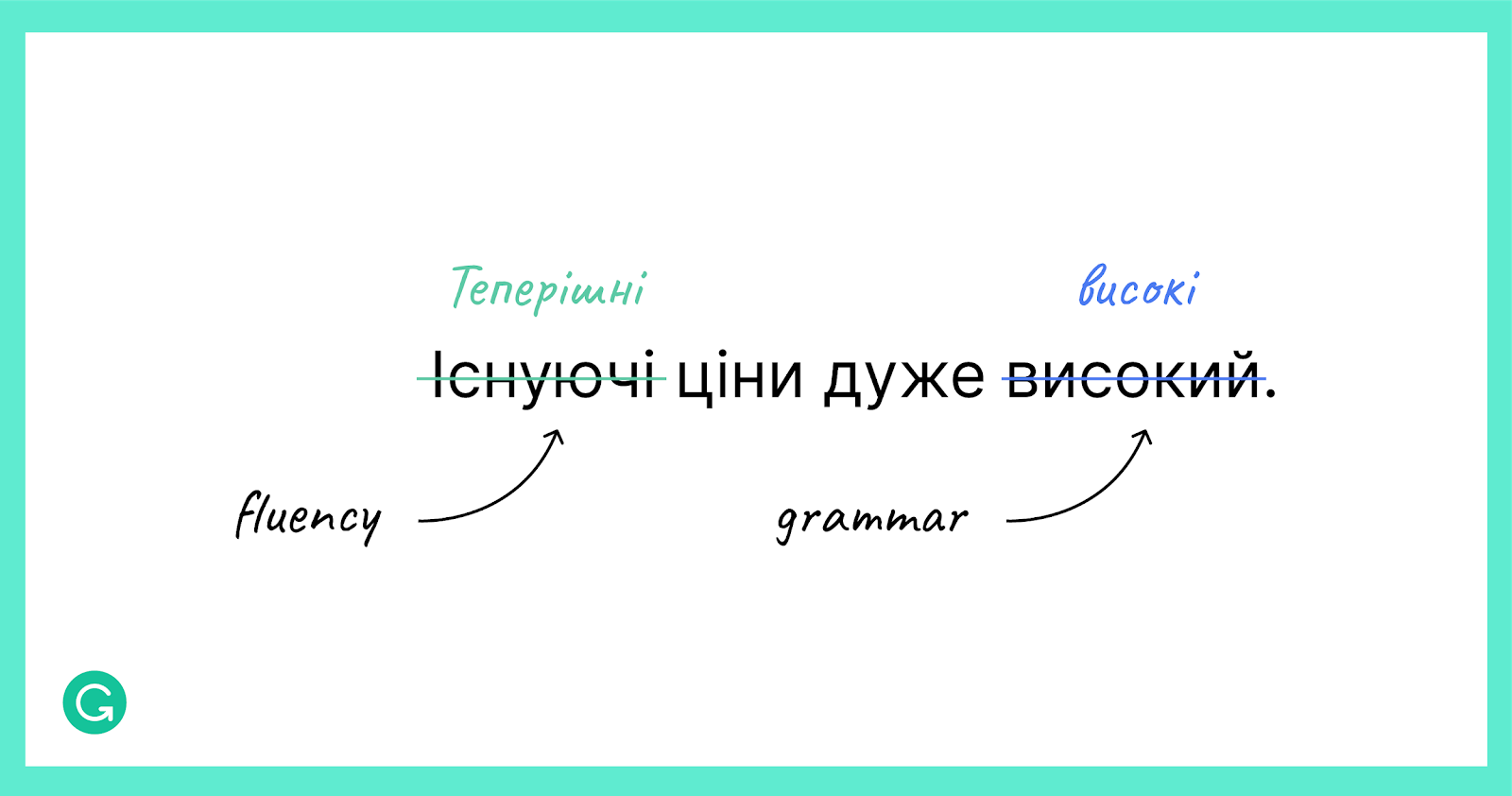
Приклад речення українською мовою, анотованого для виправлення стилістичних і граматичних помилок
Також корпус може бути цікавий лінгвістам для проведення лінгвістичного аналізу і дослідження різних видів помилок. Анотований корпус є у вільному доступі, будь-хто може завантажити його і використостовувати для навчання чи досліджень.
Як все починалося
Ми почали працювати над проектом у серпні 2020 року: запустили збір текстів і майже відразу почали анотувати їх.
Першу версію корпусу — 20 000 речень — ми випустили в січні 2021 року, працювали над нею п’ять місяців.
Зараз ми створюємо другу версію корпусу і продовжуємо збирати текстові дані. Плануємо випустити на початку наступного року, додавши ще 20 000 речень. Що більше даних у корпусі, то більше можливостей для дослідження та тренування програми і, зрештою, то краще вона працюватиме.
Для порівняння: GEC-корпус німецької мови нараховує 25 тис. речень, чеської — близько 47 тис. речень, а англійської — 1 млн 167 тис. речень.
Для збору текстів ми запустили простий сайт, де всі охочі можуть поділитися своїми готовими текстами українською або ж зробити переклад уривка чи написати маленьке есе. Використовували Google Docs, щоб анотувати тексти на помилки. У категоризації помилок (у першій версії корпусу маємо чотири категорії) нам допоміг власний анотаційний інструмент. Загалом керувалися принципом «найпростіший інструмент, яким буде зручно користуватися».
До збору текстів долучилось понад 500 людей з України та з-за кордону.
Складнощі роботи
У самому процесі збору текстових даних особливих складнощів немає. А щодо анотування і категоризації помилок було декілька особливостей:
- Відомою проблемою в Україні є використання суржику, тож тут треба було детальніше розбиратися з текстом.
- Навіть серед мовознавців є багато суперечок щодо питомості певних слів, словосполучень, синтаксичних конструкцій для української мови.
Скажімо, конструкція «більш помітніший» є помилковою, і ми позначаємо її як граматичну помилку (неправильне утворення ступеня порівняння прикметника). А що коли людина вживає форму «більш помітний»? Правопис дозволяє паралельні форми «помітніший» і «більш помітний», але деякі мовознавці зазначають, що для української мови стилістично кращою є форма «помітніший».
Тут багато «сірих зон», і щоб розібратися з анотаціями, треба читати різні стилістичні довідники і порадники. Якщо ми все ж вирішуємо виправляти такі недосконалості текстів, які правопис не подає як граматичні помилки, ми класифікуємо їх як помилки категорії Fluency (стиль).
Крім цього, в текстах нам не раз траплялися діалектизми чи регіональні особливості, які загалом мають повне право на існування в мові. Але ми керувалися літературною нормою (тобто правописом), тож такі особливості текстів виправляли.
Реліз другої версії UA-GEC
Другу версію плануємо випустити на початку 2022 року. У ній буде декілька змін:
- По-перше, подвоїмо кількість текстів.
- По-друге, додамо більш гранулярну класифікацію помилок. Зараз маємо чотири категорії: граматика, орфографія, пунктуація, стиль (а плануємо близько 20).
- По-третє, збираємося створити дві паралельні версії корпусу: повну (всі категорії) і лише GEC (тобто лише граматичні, орфографічні й пунктуаційні помилки).
Причина проста: розробляти алгоритми для виправлення лише граматичних помилок простіше, це завдання більш однозначне, тож у користувачів буде можливість обирати, над яким саме алгоритмом працювати — простішим чи складнішим — залежно від їхніх потреб.
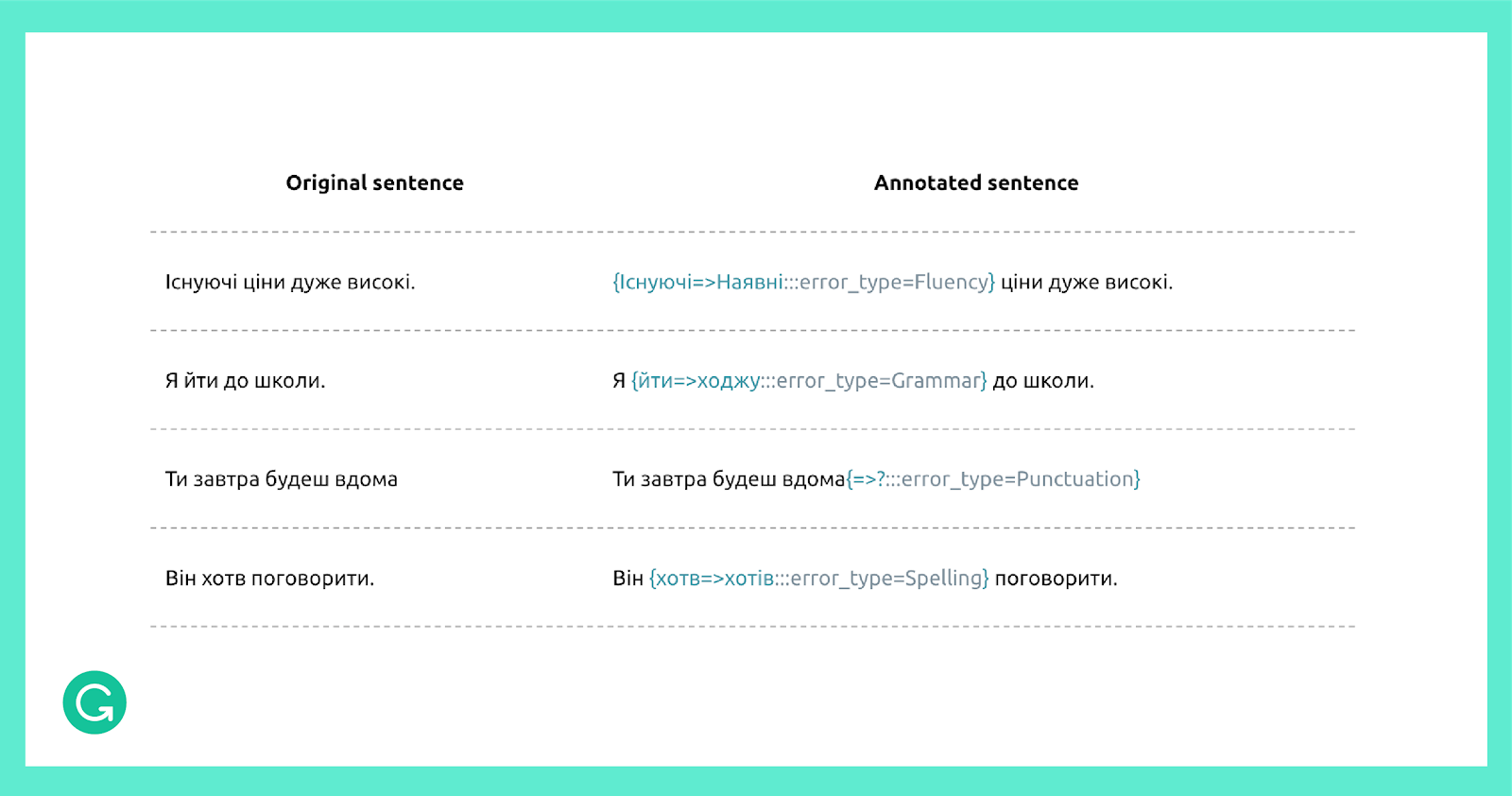
Приклад набору даних, узятий безпосередньо з корпусу UA-GEC
Чесно кажучи, ми не відстежуємо, скільки людей завантажили корпус UA-GEC з репозиторію в GitHub, але зараз він має 151 зірочку (тобто стільки людей відзначили його як корисний ресурс). Створення алгоритмів для виправлення помилок вимагає часу, тож сподіваємося, що скоро почнуть з’являтися і моделі на основі нашого корпусу.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: